6.Linux虚拟机下的Hadoop集群搭建之完全分布式配置
Hadoop及相关组件搭建指导WeChat:h19396218469
hadoop-3.1.3
jdk-8u162-linux-x64
本案例软件包:链接:https://pan.baidu.com/s/1ighxbTNAWqobGpsX0qkD8w
提取码:lkjh(若链接失效在下面评论,我会及时更新)
一、配置Hadoop集群主节点
1.进入目标文件夹。
cd /usr/local/hadoop/etc/hadoop
2.修改hadoop-env.sh配置文件
修改hadoop-env.sh文件找到其中JAVA_HOME参数位置添加JDK路径。
sudo vi hadoop-env.sh

3.配置core-site.xml文件
core-site.xml是Hadoop集群的核心配置文件,包含了HDFS地址,端口号,临时文件目录。
打开core-site.xml配置文件
sudo vi core-site.xml
编辑core-site.xml文件内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
其中配置了HDFS的主进程NameNode运行主机(Hadoop集群主节点),还有Hadoop集群运行时生成数据的临时目录。
4.配置hdfs-site.xml文件
该文件配置了HDFS的NameNode和DataNode两大进程。
打开hdfs-site.xml文件夹
sudo vi hdfs-site.xml
编辑hdfs-site.xml文件内容
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name> dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
其中配置了Secondarynamenode,namenode所在的主机IP和端口,HDFS块的副本数和临时文件存放的目录。
5.配置mapred-site.xml文件
该文件用于指定MapReduce运行框架。
打开mapred-site.xml文件夹
sudo vi mapred-site.xml
编辑mapred-site.xml文件内容
<configuration>
<property>
<name> mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name> yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
其中指定了MapReduce的运行框架。
6.配置yarn-site.xml文件
该文件用于指定YARN集群的管理者
打开yarn-site.xml文件夹
sudo vi yarn-site.xml
编辑yarn-site.xml文件内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
其中指定了ResourceManager运行主机为master,将NodeManager运行时的附属服务配置为mapreduce_shuffle才能正常运行MapReduce默认程序。
7.设置从节点,即修改workers文件
该文件记录Hadoop集群的所有从节点,以配合脚本一键启动从节点
打开workers文件
sudo vi workers
添加内容,每个主机名各占一行
master
slave01
slave02
二、将集群主节点的配置文件分发到其他节点
执行以下命令
sudo scp /etc/profile slave01:/etc/profile
sudo scp /etc/profile slave02:/etc/profile
sudo scp -r /usr/local/hadoop slave01:/usr/local
sudo scp -r /usr/local/hadoop slave02:/usr/local
sudo scp -r /usr/local/jdk slave01:/usr/local
sudo scp -r /usr/local/jdk slave02:/usr/local
scp ~/.bashrc slave01:~/
scp ~/.bashrc slave02:~/
上述命令执行完成后还需要在slave01和slave02上分别执行
source /etc/profile
source ~/.bashrc
在slave01和slave02分别执行以下命令修改文件夹权限
cd /usr/local
sudo chown -R hadoop ./hadoop
三、格式化文件系统
执行以下命令
hdfs namenode -format
出现下图所示即为格式化成功

四、启动Hadoop集群
在前面我们已经配置了环境变量,所以我们在任何一个文件夹都可以启动Hadoop集群
使用以下命令启动Hadoop集群
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
使用以下命令对Hadoop进程进行检查
jps
三台虚拟机分别显示如下进程,说明Hadoop集群搭建成功

五、查看Web界面
1.关闭防火墙
在三台虚拟机分别执行以下命令关闭防火墙和防火墙自启动
sudo service iptables stop
sudo chkconfig iptables off
2.在Windows主机添加集群服务的IP映射
Windows10和Windows7操作系统的路径为C:\Windows\System32\drivers\etc\hosts
添加内容如下:

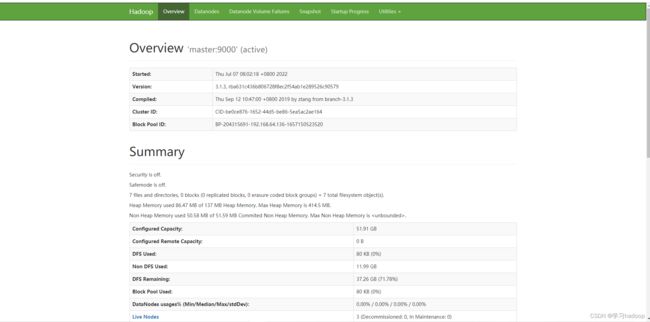
执行完上述操作后,可通过宿主机或者三台虚拟机的浏览器分别访问http://master:50070和http://master:8088查看HDFS集群和YARN集群状态,效果如下图:

六、简单使用Hadoop集群
1.在集群主节点的~目录下使用vi命令创建一个文件夹
cd ~
vi word.txt
在其中编辑内容:hello Hadoop
2.将文件夹上传到HDFS的 / 目录下
hdfs dfs -put word.txt /
3.查看上传的文件夹
hdfs dfs -cat /word.txt
4.查看本地文件夹
cat word.txt
输出内容一致,表明Hadoop集群搭建成功!