运维监控系列(1):在Linux中运用Docker部署Prometheus+Grafana+Alertmanager企业微信机器人以及邮箱的推送。(全面部署)
一. 前言
这一章节主要是针对那些有Linux以及有Docker基础的小伙伴做的一个比较全面的部署,如果有不会Linux和docker的小伙伴可以先去学一下。花个1周的时间把Linux和docker入门就可以了,不需要精通。部署的步骤也比较简单,我搜索了一些文章,基本都是没有一个全面的部署,要么就是部署了前面监控部分,没有后面的Alertmanager推送机器人或者邮箱。要么就是在Linux中部署,而没有在Docker中部署。不过我还是建议在Docker中部署,它的效率和维护性都非常的高,这也是我学习Docker之后的感悟。趁热打铁,最近刚好部署完这一整套监控系统,在此也分享给大家,希望每个小伙伴都能少走一些弯路!!不过也希望每位小伙伴在部署完成之后,能重新对流程和知识点再整理一遍,毕竟温故而知新嘛!开始进入正题~~~
二.实现的技术
1.部署中你需要用到的东西
在这里我就不做过于详细的讲解各技术的用途和功能了,毕竟要的是快速开发一套能用于工作的监控系统。
(1)Prometheus (数据监控)
Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。Promethus有以下特点:
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
小编:这里给大家配了张Prometheus的架构图,看不懂没关系,学到最后再回来看你就恍然大悟了!!!Prometheus主要就是用来监控各系统的指标。(重点)
(2)Node_Exporter(数据采集)
Node Exporter 是一个开源的 Prometheus 客户端软件,用于收集和导出 Linux 系统的各种指标数据。 它可以提供关于 CPU 使用率、内存占用、网络流量等方面的数据。 而在本文中,我们将重点关注磁盘 I/O 相关的指标。
小编:知道有这个东西就好,主要是用来采集主机数据的,要采集哪个系统的数据,就在哪个系统里部署,下面我们就直接采集阿里云的服务器数据,这个不难,只要安装部署跑通了就可以了。
(3)Grafana(数据显示)
Grafana是一个用Javascript写的开源的(Dashboard)可视化面板,能齐全的度量仪表盘和图形编辑器和漂亮的布局展示,并且支持Graphite、elasticsearch、zabbix等的数据可视化的实现,可以给你的数据换个皮肤,使你的数据展示更加直观和漂亮。
小编:这个主要用于显示prometheus中所有监控的数据,也就是形成监控看板,方便我们查看各个系统的软硬件指标。也是了解即可。
(4)Alertmanager(告警推送)
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
小编:Alertmanager主要是用来完成对Prometheus生产的警告进行推送,我们要把警告消息推送到企业微信,钉钉,邮箱等地方就需要通过Alertmanager来实现。(重点)
梳理一下流程:Prometheus监控来自----Node_Exporter采集到的主机数据----并展示到grafana形成看板-----同时Prometheus又把生产的告警推送给Alertmanager---再通过Alertmanager推送给我们的企业微信和邮箱。(可以结合上面Prometheus的架构图进行理解,现在看不懂也没关系,慢慢来,后面部署完就能看懂这张图了)

2.开始部署
以下都是基于Docker容器来部署的,合适有Linux和docker基础的小伙伴
1.部署Prometheus
第一步:
在Linux系统中新建prometheus目录,编辑配置文件prometheus.yml
(这个prometheus.yml文件至关重要,也是prometheus能不能正常启动,能不能监控到数据的关键,后续如果启动不了prometheus或者监控不到数据,都可以来查看一下这个配置文件是否正确,特别要注意这个配置文件的格式,有可能就因为一个空格的问题导致无法运行。)
mkdir /opt/prometheus cd /opt/prometheus/ vim prometheus.yml在prometheus.yml中编辑下面内容:
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 8.134.34.239:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "rules/*.yml" # - "cpu_over.yml" # - "cpu_over.yml" # - "memory_over.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["8.134.34.239:9090"] - job_name: 'alertmanager' static_configs: - targets: ['8.134.34.239:9093'] - job_name: 'localhost9182' static_configs: - targets: ['localhost:9182'] - job_name: 'cadvisor' static_configs: - targets: ['8.134.34.239:8080'] - job_name: '8.134.34.239' static_configs: - targets: ['8.134.34.239:9100'] labels: instance: "监控本机参数" 这个yml文件中有三个要配置的地方:
注:因为这里我是在阿里云的服务器上监控的,所以第三步的配置主机地址,我把原来的localhost:9090,改为阿里云服务器上的地址。
(重点)这里要注意的是,第二步的配置rules文件夹位置必须位于prometheus.yml文件的同级目录下,这一点我也是我之前踩的坑。
注:这里用的是Xshell和Xftp远程连接Linux,大家也可以用其他的远程连接软件,只是为了方便可视化查看和编辑文件。
第二步:
配置触发告警规则的yml文件,也就是第一步说的存放在rules文件夹中的yml文件。
1.配置CUP告警规则
groups: - name: CPU报警规则 #组名,报警规则组名称 rules: #定义角色 - alert: CPU使用率告警 #告警名称。 expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 85 #表达式,获取cup使用率,大于80%触发 for: 10m #持续时间。表示持续十分钟获取不到信息,则触发警报。0表示不使用持续时间。 labels: #定义当前告警规则级别 severity: warning #指定告警级别 annotations: #注释,告警通知 summary: "报警值持续1分钟。" #调用标签具体值附加通知信息 description: "CPU使用率超过85%(当前值:{{ $value }}%)"2.配置磁盘告警规则
groups: - name: 磁盘使用率报警规则 rules: - alert: 磁盘使用率告警 expr: 100 - node_filesystem_free_bytes / node_filesystem_size_bytes * 100 > 80 for: 20m labels: severity: warning annotations: summary: "硬盘分区使用率过高" description: "分区使用大于80%(当前值:{{ $value }}%)"3.配置
groups: - name: 内存报警规则 rules: - alert: 内存使用率告警 expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80 for: 1m labels: severity: warning annotations: summary: "服务器可用内存不足。" description: "内存使用率已超过80%(当前值:{{ $value }}%)"注:告警规则可以按照上面的代码进行配置即可,参数自行修改。
第三步:
在Docker中运行Prometheus
docker run -d --name prometheus --restart=always -p 9090:9090 -v /opt/prometheus:/etc/prometheus prom/prometheus这里的 -d 表示后台运行,--name 给这个运行的容器命名,--restart 重启,-p 开放端口,宿主机端口:容器端口,-v 挂载点 宿主机路径:容器路径。
注意:这个挂载点一定一定不要写错了,宿主机路径要和第一步创建的路径一致,这里我是挂载到/opt/prometheus 下面,也就是说把这文件下的所有内容同步到容器对应的路径。否则docker容器中没办法同步数据。学过docker的小伙伴也是知道的,如果不知道的话,就跟着我路径来就可以了。
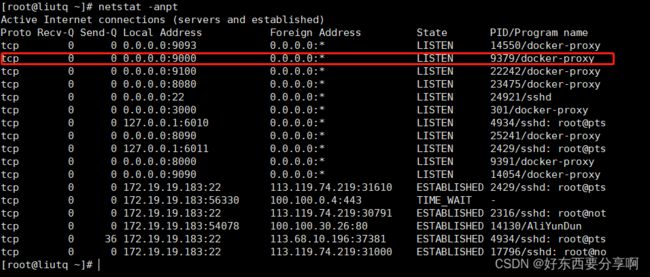
1.以上步骤完成后就可以查看一下Linux的端口状态了,查看是否运行成功。
netstat -anpt
可以看到已经是有9090这个端口了
注意:如果端口别占用可以换个端口,如果是用的阿里云服务器要在阿里云管理控制台中把服务器的端口配置上。
2.网页中请求一下
看到这个页面说明prometheus已经运行成功了!!!
2.部署Node_Exproter
1.安装node_exporter
docker run -d --name node-exporter --restart=always -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter2.查看端口
netstat -anpt
3.网页请求一下
看到这个页面也就说明运行成功了!!!
OK
如果能顺利到达这个步骤,你也就完成了简单的监控主机数据了,我们回来回顾一下这个图:
我们在第四步中把我们配置的地址和端口改为上面已经运行成功的node_exporter地址和端口,这里我打码的是因为怕公网地址泄露,大家可以改成自己配置主机的公网地址,如果是在虚拟机上部署的可以配置本地地址。
配置完成后在网页中访问一下9090这个端口,就可以看到下面prometheus已经对本机的数据进行监控了,也可以看到我们部署prometheus时第二部的配置告警规则了。
完成到这一步的也就基本对prometheus入门了。
3.部署Grafana
docker run -d --name grafana --restart=always -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana同样上述步骤:查看端口状态,网页请求访问是否成功(也可以在Linux主机上curl请求看看能不能获取到网页)
看到上面这个页面也就成功了!!!
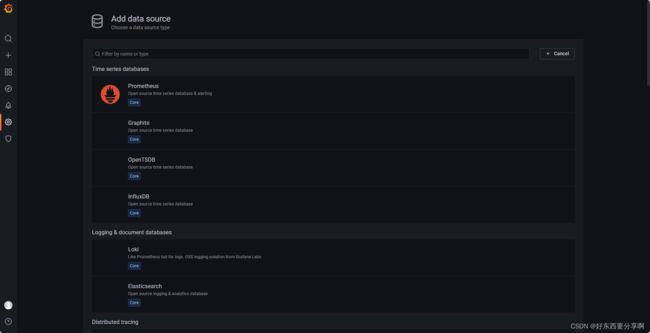
找到Add data source 添加数据源,这里选择prometheus。
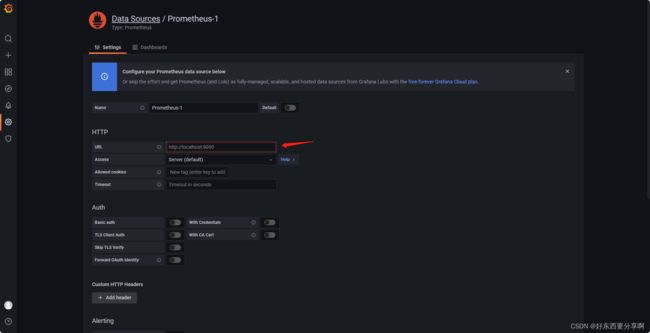
配置prometheus的地址,这一步不能错,错了就显示不了prometheus的数据了。配置好后其他不用改动,点击save&test。
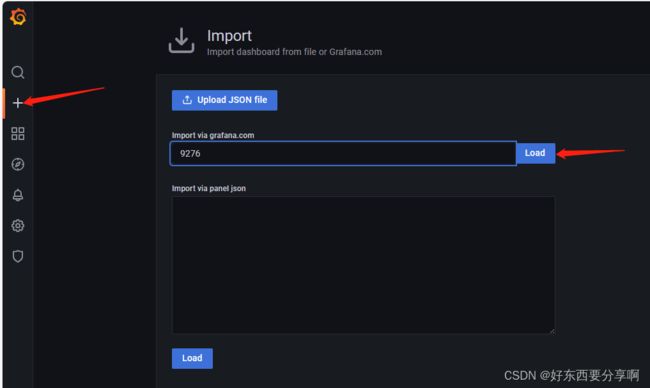
找到Import添加监控显示的面板,这里推荐9276,8919模板,其他模板可以去官网找。
在home页面就可以看到你所配置的看板了,到这一步也就完成了从prometheus+node_exporter+Grafana的一整套配置了,剩下的就是一些完善,如果要继续深入学习可以查看官网文档,这个系列章节主要是教大家快速入门上手!!!接下来就是把这些监控到的数据通过Alertmanager发布到企业微信机器人以及邮箱。
4.部署Alertmanager
第一步:
在Linux系统中新建alertmanager目录,编辑配置文件alertmanager.yml文件
vim /opt/alertmanager/alertmanager.yml这个步骤跟部署Prometheus第一步类似。
在alertmanager.yml文件写入:
global: resolve_timeout: 5m route: #告警如何发送分配 group_by: ['alertname'] #采用哪个标签作为分组的依据 group_wait: 10s #分组等待时间 group_interval: 10s #上下两组发送告警的间隔时间 repeat_interval: 1h #重复发送告警时间。默认1h receiver: 'web.hook' #定义谁来通知告警 receivers: #告警接收者 - name: 'web.hook' #告警来源自定义名称 webhook_configs: #通过webhook发送报警 - url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxx' #要推送的企业微信机器人地址,后面的key填你们创建的机器人key。 send_resolved: true inhibit_rules: #降低告警收敛,减少报警,发送关键报警。 - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
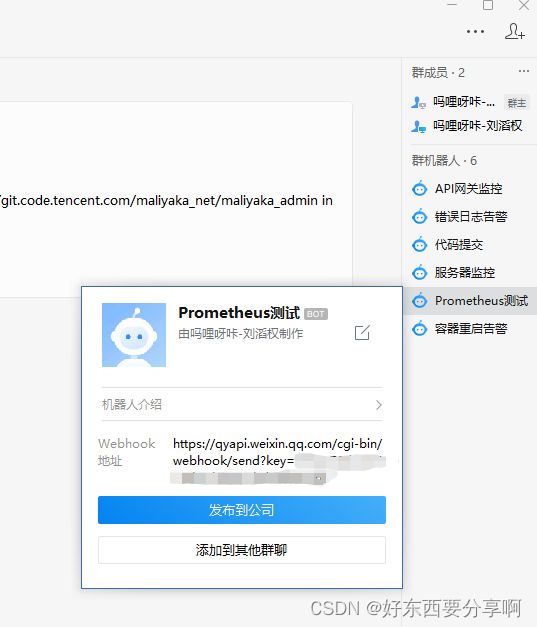
注:在群聊中创建企业微信机器人,然后把机器人的key填入alertmanager.yml文件中。
第二步:
在Docker容器中运行Alertmanager
docker run -d --restart=always \ --name=alertmanager \ -p 9093:9093 \ -v /opt/alertmanager:/etc/alertmanager \ prom/alertmanager:latest这里也要注意 -v 的挂载路径
完成上面步骤后还是查看一下端口,网页请求该地址。
出现这个页面说明成功了!!!
又回到这张图了
图中的第一步也就是当prometheus触发告警之后,会把告警信息发送到配置的这个地址。
这里可以查看到prometheus触发的告警规则是否发送过来了。
第三步:(这一步是为第一步推送企业微信机器人做补充的)
因为这个alertmanager的企业微信机器人推送是基于webhook的,所以有的docker可能需要自己手动配置。
docker run -d --name wechat \ --restart always -p 8080:80 \ guyongquan/webhook-adapter \ --adapter=/app/prometheusalert/wx.js=/wx=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxx(自己的微信机器人key)完成以上的步骤之后建议把所有的容器都重启一遍。
docker restart #容器ID
可以看到所有的容器运行状态和端口都没有问题。
最后一步
最后一步也就是来测试一下整个部署流程能不能跑通。
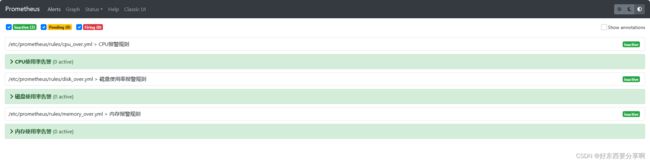
我们先把prometheus中的rules目录下的.yml文件的监控规则把它调低了,这里我们就把它调到大于1就触发cup使用率告警。
注意:修改配置后,记得在docker容器中重启prometheus,修改哪个容器的配置就重启哪个容器。
可以看到已经触发告警规则了,只要cup使用率>1%而且超过我们设置的10分钟就会把告警推送到alertmanager。(这里为了测试方便,我就把监控时间for改为1m,即1分钟)
Prometheus告警规则触发后,在Alertmanager页面中是可以看到从普罗米修斯发送过来的告警,Alertmanager再把告警通过沉默,抑制,聚集等方式发送到我们所配置的企业微信机器人。
来到这里也就完成Prometheus+Grafana+Alertmanager+企业微信机器人推送了。我这里是通过推送到.net core api接口进行二次开发和整理之后再推送到企业微信机器人的,所以大家看到的消息跟我会不一样。
附加:邮箱推送
虽然现在基本都是选择钉钉或者企业微信推送监控消息,但不排除有一些小伙伴可能要推送到邮箱,在这里也给大家讲一下推送到邮箱的教程。以网易163邮箱为例:
第一步:
配置alertmanager.yml文件:
global: resolve_timeout: 5m smtp_from: '[email protected]' #填写邮箱地址 smtp_smarthost: 'smtp.163.com:465' smtp_auth_username: '[email protected]' #填写邮箱地址 smtp_auth_password: 'XXXXXX' #填写POP3/SMTP服务的密码 smtp_require_tls: false smtp_hello: '163.com' route: group_by: ['alertname'] group_wait: 5s group_interval: 5s repeat_interval: 5m receiver: 'email' receivers: - name: 'email' email_configs: - to: '[email protected]' #填写邮箱地址 send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']这个POP3/SMTP服务的密码是什么,在那里查看,第二步会讲解。
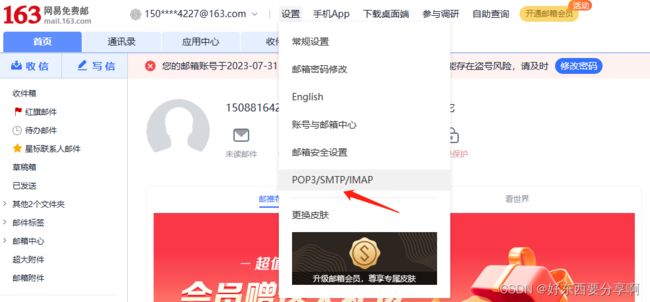
第二步:
登录网易邮箱开通SMTP服务,查看服务密码
根据上述步骤开启SMTP服务即可。
当Prometheus触发告警之后,Alertmanager就会把数据推送到你所配置的邮箱中。
到这里也就完成所有的配置和部署了。

















结语
到这里我们也就完成了从Prometheus+Grafana+Alertmanager+企业微信机器人以及邮箱的告警推送了。希望我这花了几天写出来的文章可以帮助到大家,这也是我在全网搜索之后,发现没有一篇文章是全部一整套流程的,多多少少都是有欠缺。也就有了写这篇文章的想法,能帮助到大家少走弯路和入坑,这就是我写这篇文章的目的!!!
大家有什么问题,或者部署过程中有什么难题,都可以私信留言,后续会创作更多的技术文章,大家也可以点个关注!!!
如果这篇文章对你有所帮助,点赞关注+收藏哦!谢谢大家!!!