Revisiting image pyramid structure for high resolution salient object detection
accv2022的技术,在我测评的数据集上确实要明显好于basnet,rembg等一众方法。
1.Introduction
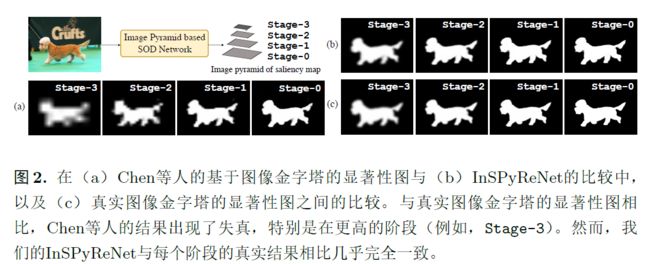
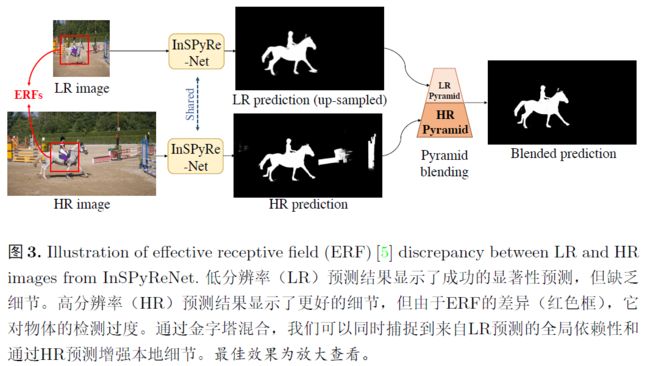
使用LR数据集训练的方法通过调整输入尺寸可以在HR图像上产生不错的结果。本文主要关注仅使用LR数据集进行训练以产生高质量的HR预测。HR的有效感受野ERFs和LR图像不同。设计了逆显著性金字塔重建网络InSPyReNet,InSPyReNet来直接生成Image pyramid of saliency map,在推理时,重新设计了金字塔融合网络,将来自不同尺度的两个显著性地图图像金字塔重叠。

2.related works
高分辨率图像的图像分割。像素级预测任务,如SOD,将输入图像调整为预定义的形状,如384x384,训练数据集的平均分辨率的宽高通常都在300-400之间,例如imagenet的平均分辨率为378x469,DUTS的平均分辨率为322x372,但是对大图像进行下采样会导致严重的信息丢失,特别是对高频细节。Inspyrenet在训练时不需要高分辨率数据集,但能够预测出细节,特别是物体边界上的细节。
3.Methodology
3.1 Model architecture

使用res2net或者swin transformer作为backbone,但对于HR预测,使用swin作为backbone。在多尺度编码器中使用了UACANet中的PAA-e来减少骨干特征图的通道数,并使用PAA-d在最小阶段(即stage3)上预测初始显著图。采用这两个模块是因为它们利用非局部操作捕捉全局上下文,并且效率高。
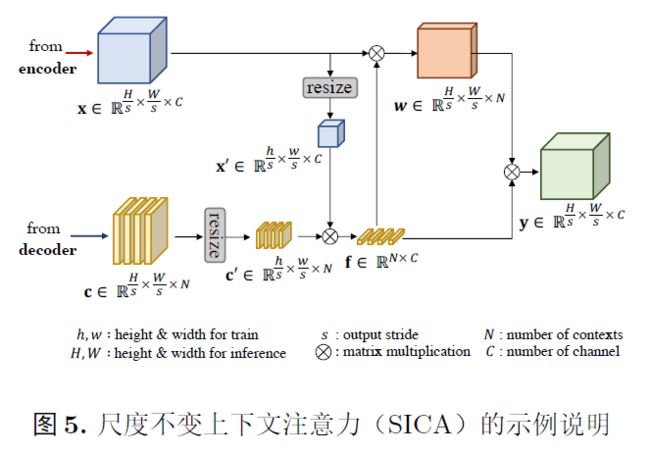
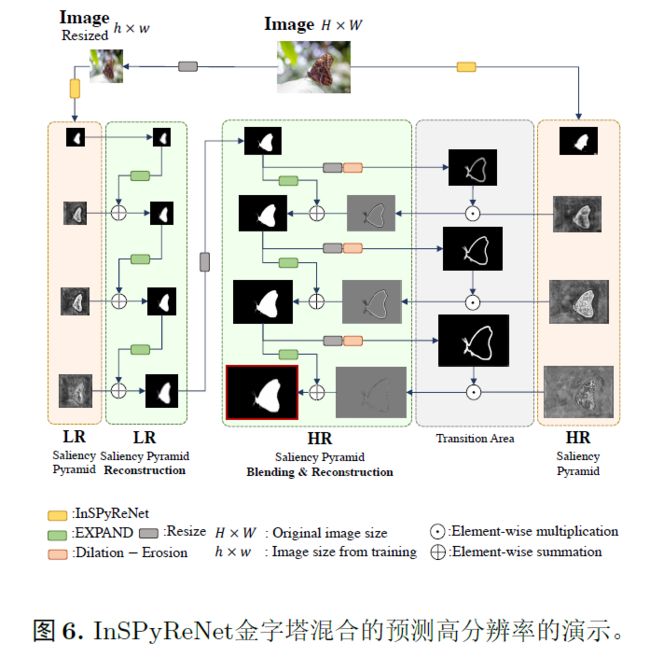
从stage3开始构建图像金字塔已经足够,并应该一直重建直到遇到最低阶段stage-0以获得HR结果,在每个阶段上放置了一种基于自注意力的解码器,Scale Invariant context attention(SICA)用于预测显著图的拉普拉斯图像(Laplacian sailency map)。从预测的拉普拉斯显著图中,我们从较高的阶段向较低的阶段重建显著图。SICA的整体操作遵循OCRNet的方法。
拉普拉斯金字塔存储了每个尺度中低通滤波图像与原始图像之间的差异,可以将拉普拉斯图像解释为低通滤波信号的余项,即高频细节,我们重新设计我们的网络,通过构建拉普拉斯金字塔,集中于边界细节并从最小的阶段到其原始大小重新构建显著图,从最上层的阶段stage-3开始,将初始显著性图作为输入,并从拉普拉斯显著图中聚合高频细节。那么拉普拉斯是在什么时候添加的呢?是在SICA之后添加的。
3.2 supervision strategy and loss functions
在每个尺度上都用bce去监督。
3.3 推理
4.代码
下面主要来看看他的代码,主要还是在代码中实现的,inspyrenet
def forward_inspyre(self, x):
B, _, H, W = x.shape
x1, x2, x3, x4, x5 = self.backbone(x)
x1 = self.context1(x1) #4
x2 = self.context2(x2) #4
x3 = self.context3(x3) #8
x4 = self.context4(x4) #16
x5 = self.context5(x5) #32
f3, d3 = self.decoder([x3, x4, x5]) #16
f3 = self.res(f3, (H // 4, W // 4 ))
f2, p2 = self.attention2(torch.cat([x2, f3], dim=1), d3.detach())
d2 = self.image_pyramid.reconstruct(d3.detach(), p2) #4
x1 = self.res(x1, (H // 2, W // 2))
f2 = self.res(f2, (H // 2, W // 2))
f1, p1 = self.attention1(torch.cat([x1, f2], dim=1), d2.detach(), p2.detach()) #2
d1 = self.image_pyramid.reconstruct(d2.detach(), p1) #2
f1 = self.res(f1, (H, W))
_, p0 = self.attention0(f1, d1.detach(), p1.detach()) #2
d0 = self.image_pyramid.reconstruct(d1.detach(), p0) #2
out = dict()
out['saliency'] = [d3, d2, d1, d0]
out['laplacian'] = [p2, p1, p0]
return out可以看到imagenet_pyramid的添加,为什么第一次输出总是拉普拉斯显著图就在这里。