《分布式服务框架Dubbo》一、Dubbo原理和应用
一、dubbo的架构思路
1.1 dubbo框架设计
dubbo官网的架构设计提供了一张整体的框架图,10个层级看起来挺吓人的。但是其核心总结起来就是:Microkernel + Plugin(微内核+插件)。

微内核+插件机制
官网介绍的架构设计思想是两点:
- 采用 URL 作为配置信息的统一格式,所有扩展点都通过传递 URL 携带配置信息;
- 采用 Microkernel + Plugin 模式,Microkernel 只负责组装 Plugin,Dubbo 自身的功能也是通过扩展点实现的,也就是 Dubbo 的所有功能点都可被用户自定义扩展所替换。
对于第一点比较容易理解,因为是分布式环境,各系统之间的参数传递基于URL来携带配置信息,所有的参数都封装成 Dubbo 自定义的 URL 对象进行传递。URL 对象主要包括以下属性:
String protocol
String host
int port
String path
Map parameters
第二点:系统里抽象的各个模块,往往有很多不同的实现方案,好的设计来说:模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码,例如:
if(参数=="dubbo"){
return new DubboProtocol(); }
else if(参数 == "rmi"){
return new RMIProtocol();
}
SPI的解决方案就呼之欲出了,一个接口对应有多个实现类的时候该怎样指定么?如果采用上述设计是很糟糕的,用if else来写死自己的服务发现,如果新增一种协议则还需要去修改代码,针对此类问题Java本身提供了spi机制,可以做到服务发现和动态扩展,但是弊端就是一初始化就把所有实现类给加载进去,dubbo改进了spi并重新命名为ExtensionLoader(扩展点机制),按照用户配置来指定加载模块,只需要约定一下路径即可:
private static final String SERVICES_DIRECTORY = "META-INF/services/";
private static final String DUBBO_DIRECTORY = "META-INF/dubbo/";
private static final String DUBBO_INTERNAL_DIRECTORY = DUBBO_DIRECTORY + "internal/";
这部分源码可以考察知识点非常多,对使用者来说是透明的,而精华却良多,尤其结合java-spi,jvm以及spring等多方面对比、借鉴,因此理论上可以好好掌握,当然最好的学习方式就是按照极简的思路来实现一个简版RPC工具。
1.2dubbo原理、与Spring融合
dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。既然是分布式那就意味着:一个业务分拆多个子业务,部署在不同的服务器上,既然各服务是部署在不同的服务器上,那服务间的调用就是要通过网络通信。既然涉及到了网络通信,那么服务消费者调用服务之前,都要写各种网络请求,编解码之类的相关代码,明显是很不友好的.dubbo所说的透明,就是指,让调用者对网络请求,编解码之类的细节透明,让我们像调用本地服务一样调用远程服务,甚至感觉不到自己在调用远程服务。
public class ProxyFactory implements InvocationHandler {
private Class interfaceClass;
public ProxyFactory(Class interfaceClass) {
this.interfaceClass = interfaceClass;
}
//返回代理对象,此处用泛型为了调用时不用强转,用Object需要强转
public T getProxyObject(){
return (T) Proxy.newProxyInstance(this.getClass().getClassLoader(),//类加载器
new Class[]{interfaceClass},//为哪些接口做代理(拦截哪些方法)
this);//(把这些方法拦截到哪处理)
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method);
System.out.println("进行编码");
System.out.println("发送网络请求");
System.out.println("将网络请求结果进行解码并返回");
return null;
}
}
项目引入dubbo的方法推荐用XML配置的方式引入,即便是老项目拆分改造,只要是Spring工程,这个都是比较好做的,可以想象自己如果开发一个中间件服务,如果把服务嵌入spring容器当中呢?作为高级开发人员这个也是一个进阶的既能项。XML 配置方式是基于 Spring 的 Schema 和 XML 扩展机制实现的。通过该机制,我们可以编写自己的 Schema,并根据自定义的 Schema 自定义标签来配置 Bean。
使用 Spring 的 XML 扩展机制有以下几个步骤:
- 定义 Schema(编写 .xsd 文件)
- 定义 JavaBean
- 编写 NamespaceHandler 和 BeanDefinitionParser 完成 Schema 解析
- 编写 spring.handlers 和 spring.schemas 文件串联解析部件
- 在 XML 文件中应用配置
最好的学习效果是可以自己按照模板来一样画瓢来创作一个类似的xml配置。可参考《dubbo源码解析-简单原理、与spring融合》
1.3 服务发布
服务的发布总共做了以下几件事,这个也可以从日志log上看出来:
- 暴露本地服务
- 暴露远程服务
- 启动netty
- 连接zookeeper
- 到zookeeper注册
- 监听zookeeper
贴出一张官方文档的服务发布图

服务发布
首先
ServiceConfig类拿到对外提供服务的实际类 ref(如:HelloWorldImpl),然后通过ProxyFactory类的getInvoker方法使用 ref 生成一个AbstractProxyInvoker实例,到这一步就完成具体服务到Invoker的转化。接下来就是Invoker转换到Exporter的过程。Dubbo 处理服务暴露的关键就在Invoker转换到Exporter的过程,上图中的红色部分。
Dubbo 的实现
Dubbo 协议的Invoker转为Exporter发生在DubboProtocol类的export方法,它主要是打开socket侦听服务,并接收客户端发来的各种请求,通讯细节由 Dubbo 自己实现。
上面摘抄了官方文档(具体链接请戳),可能还是有点抽象,实际上从代码层面进行分析:
此处就是将本地的需要暴漏的方法以url形式作为参数传入 exportLocal()方法,url之前已经提到过包含了ip地址、端口、接口以及配置信息等。
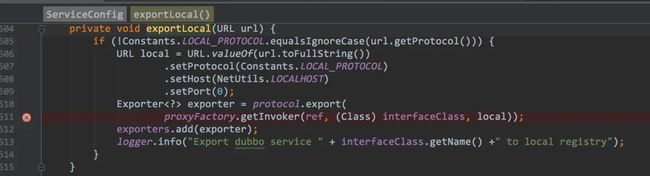
关键步骤1-本地暴露
这时会执行到一个接口方法getInvoker(),这是一个注解了@Adaptive的方法,该方法的具体实现类是运行中生成动态编译的Adaptive类,把java编译出来的动态类贴出来debug如下,恍然大悟,原来他就是几个if判断,来告诉程序我这个url参数配置的是哪种协议,我现在就动态的去调用这个扩展点服务(dubbo-spi),动态编译的好处就是不用将代码写死,在协议会扩展的情况下,我根据你配置的协议来动态的生成我的extensionLoader,再来加载我所需要的Invoker。

关键步骤2-getInvoker()方法
上图引用的是本地服务的暴露执行,若是远程服务的暴露,arg2参数的开头则会是registry://192.168.0.1:2181/com.alibaba.dubbo.** / **。从exporter对象里包含的invoker属性可以看出,invoker包含的携带ip、端口、接口以及配置信息的url。

关键步骤3-invoker信息
现在开始进入到远程服务暴露的过程,一般来说这部分是应用和考察最多的点,通过配置的协议将服务暴露给外部调用。dubbo所支持的协议有多重,默认推荐dubbo协议,于是在动态代理的时候会生成Protocol$Adpative代理类,该代理类实现了RPC 协议接口,再通过扩展机制将服务加载进来。

关键步骤4-Protocol$Adpative代理类
加载了实现类后方法会顺着调用链路进入到dubbo协议中的export()方法中来,可以再DubboProtocol类中设置断点观察方法执行,此处完成了一个绑定,将暴露的接口+DubboExporter进行关联放入map中缓存。
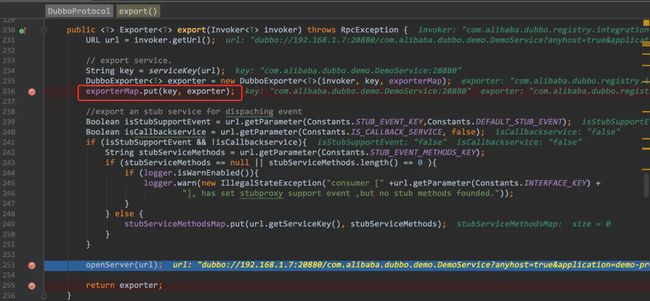
关键步骤5-DubboProtocol
后面的步骤不再一一展开来讲,越来越贴近底层和网络通信,我们在调用dubbo接口的时候dubbo都为了我们做了这样的工作,但是对开发人员来说都是透明无感知的:
- exchange 信息交换层。封装请求响应模式,同步转异步,以 Request, Response 为中心。
- transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心。
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
这里引用一张肥朝博客的总结图,来总结服务暴露所干的事情:
首先是通过动态代理店的方式将暴露的接口组装成url形式的invoker,然后再根据url的配置信息来指定传输协议、交换方式、序列化方式等等,由于dubbo采用了自定义的SPI扩展,各层之间都是相互独立的,只有在调用的时候才知道所调用的具体扩展实现,这里还是以jdk或者javasisit的方式来动态代理实现。
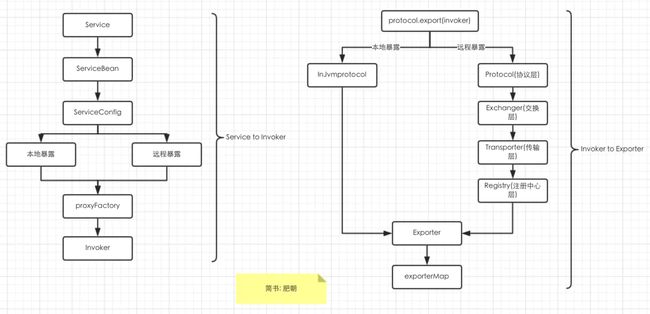
服务暴露流程
1.4 服务引用
首先
ReferenceConfig类的init方法调用 Protocol 的refer方法生成 Invoker 实例(如上图中的红色部分),这是服务消费的关键。接下来把 Invoker 转换为客户端需要的接口(如:HelloWorld)。关于每种协议如RMI/Dubbo/Web service等它们在调用refer方法生成Invoker实例的细节和上一章节所描述的类似。

服务应用流程
上述图和文字是摘自官方文档的原话(地址在这里),总结来说就是干了两件事情:1、将spring的schemas标签信息转换bean,然后通过这个bean的信息,连接、订阅zookeeper节点信息创建一个invoker。2、将invoker的信息创建一个动态代理对象。贴一张服务应用的时序图:

服务引用时序
这里又一次出现了Invoker,这个抽象的概念真是无处不在呀,dubbo中最重要的两种 Invoker:服务提供 Invoker 和服务消费 Invoker。Invoker从类的设计信息上是封装了 Provider和Consumer地址及 Service 接口信息,我们在自己的子系统调用远程接口的时候,会像调用自己的方法一样,比如在消费端这里用注解@Autowirted自动注入一个远程接口进来,这个远程接口就是上图中服务消费端的 proxy,但是远程接口是需要网络通信、编码解码等等一系列工作的,要封装这个通信细节,让用户像以本地调用方式调用远程服务,就必须使用代理,然后说到动态代理,用户代码通过这个 proxy 调用其对应的 Invoker ,而该 Invoker 实现了真正的远程服务调用。

image.png
二、Dubbo实战应用
实战应用主要是从应用层面讲引入dubbo框架后如何做一些关键配置
2.1 Dubbo 支持四种配置方式:
XML 配置:基于 Spring 的 Schema 和 XML 扩展机制实现(推荐)
属性配置:加载 classpath 根目录下的 dubbo.properties
API 配置:通过硬编码方式配置(不推荐使用,可学习加深源码理解)
注解配置:通过注解方式配置(Dubbo-2.5.7及以上版本支持,不推荐使用)
2.2 集群容错
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
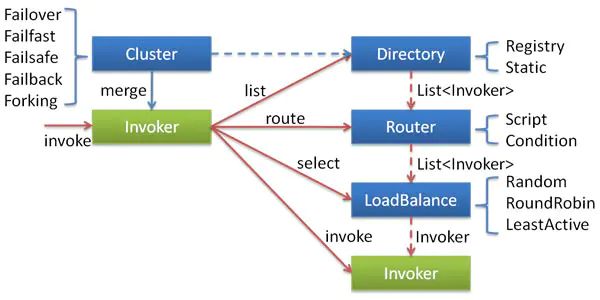
集群容错
- Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
- Directory 代表多个 Invoker,可以把它看成 List
,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更 - Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个
- Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等
- LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
集群调用的配置可从如下列表中选择:
| 集群模式 | 说明 |
|---|---|
| Failfast Cluster | 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。 |
| Failsafe Cluster | 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。 |
| Failback Cluster | 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。 |
| Forking Cluster | 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。 |
| Broadcast Cluster | 广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。 |
2.3 负载均衡
Random LoadBalance
- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin LoadBalance
- 轮询,按公约后的权重设置轮询比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
- 一致性 Hash,相同参数的请求总是发到同一提供者。
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
- 缺省用 160 份虚拟节点,如果要修改,请配置
三、dubbo面经
SPI
1、你是否了解SPI,讲一讲什么是SPI,为什么要使用SPI?
SPI具体约定:当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入(从使用层面来说,就是运行时,动态给接口添加实现类)。 基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定(不需要在代码里写死)。
这样做的好处:java设计出SPI目的是为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。这样程序运行的时候,该机制就会为某个接口寻找服务的实现,有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。例如,JDBC驱动,可以加载MySQL、Oracle、或者SQL Server等,目前有不少框架用它来做服务的扩张发现。回答这个问题可以延伸一下和API的对比,API是将方法封装起来给调用者使用的,SPI是给扩展者使用的。
2、对类加载机制了解吗,说一下什么是双亲委托模式,他有什么弊端,这个弊端有没有什么我们熟悉的案例,解决这个弊端的原理又是怎么样的?
扩展延生的一道题。
3、Dubbo的SPI和JDK的SPI有区别吗?有的话,究竟有什么区别?
Dubbo 的扩展点加载是基于JDK 标准的 SPI 扩展点发现机制增强而来的,Dubbo 改进了 JDK 标准的 SPI 的以下问题:
- JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
- 增加了对扩展点 IoC 和 AOP 的支持,一个扩展点可以直接 setter 注入其它扩展点。
上文已提供。另外在博客中也单独对此写了一篇《Dubbo内核之SPI机制》、《跟我学Dubbo系列之Java SPI机制简介》
4、Dubbo中SPI也增加了IoC,先讲讲Spring的IoC,然后再讲讲Dubbo里面又是怎么做的
5、Dubbo中SPI也增加了AOP,那你讲讲这用到了什么设计模式,Dubbo又是如何做的.
Dubbo原理
1、Dubbo角色和设计是怎么样的,原理是怎么样的?请简单谈谈?

Dubbo角色和设计
2、有没有考虑过自己实现一个类似dubbo的RPC框架,如果有,请问你会如果着手实现?(面试高频题,区分度高)
可从两个方面去入手,考虑接口扩展性,改造JDK的SPI机制来实现自己的扩展SPI机制。另外就是从动态代理入手,从网络通信、编码解码这些步骤以动态代理的方式植入远程调用方法中,实现透明化的调用。
3、用过mybatis是否知道Mapper接口的原理吗?(如果回答得不错,并且提到动态代理这个关键词会继续往下问,那这个动态代理又是如何通过依赖注入到Mapper接口的呢?)
4、服务发布过程中做了哪些事?
暴露本地服务、暴露远程服务、启动netty、连接zookeeper、到zookeeper注册、监听zookeeper
5、dubbo都有哪些协议,他们之间有什么特点,缺省值是什么?
dubbo支持多种协议,默认使用的是dubbo协议,具体介绍官方文档写得很清楚,传送地址:相关协议介绍,重点是掌握好推荐dubbo协议。Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
6、什么是本地暴露和远程暴露,他们的区别?
在dubbo中我们一个服务可能既是Provider,又是Consumer,因此就存在他自己调用自己服务的情况,如果再通过网络去访问,那自然是舍近求远,因此他是有本地暴露服务的这个设计.从这里我们就知道这个两者的区别
- 本地暴露是暴露在JVM中,不需要网络通信.
- 远程暴露是将ip,端口等信息暴露给远程客户端,调用时需要网络通信.
7、服务暴露中远程暴露的总体过程,画图和文字方式说明
详见上述说明
zookeeper
1、一般选择什么注册中心,还有别的选择吗?
zk为默认推荐,其余还有Multicast、redis、Simple等注册中心。
2、dubbo中zookeeper做注册中心,如果注册中心集群都挂掉,那发布者和订阅者还能通信吗?(面试高频题)
zookeeper的信息会缓存到服务器本地作为一个cache缓存文件,并且转换成properties对象方便使用,每次调用时,按照本地存储的地址进行调用,但是无法从注册中心去同步最新的服务列表,短期的注册中心挂掉是不要紧的,但一定要尽快修复。所以挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。
3、项目中有使用过多线程吗?有的话讲讲你在哪里用到了多线程?(面试高频题)
以dubbo为例,这里的做法是:建立线程池,定时的检测并连接注册中心,如果失败了就重连,其实也就是一个定时任务执行器。可能做了两三年java还没真正在项目中开启过线程,问到这个问题时菊花一紧,但是定时任务执行器这种需求在项目中还是很常见的,比如失败重连、轮询执行任务等等,可以参考这个例子,把你们的定时任务场景和这里的多线程用法套在一起。

dubbo检测zk链接
4、zookeeper的java客户端你使用过哪些?
zookeeper是支持ZkClient和Curator两种,关于zk的使用场景,除了以dubbo作为注册中心以外,zk在分布式环境作为协调服务器有许多应用场景,可以尝试用java来调用zk服务做一些协调服务,如负载均衡、数据订阅与发布等等。SnailClimb写了一篇优秀的博客《可能是全网把ZK概念讲的最清楚的一篇文章》

zookeeper知识点一览图
5、服务提供者能实现失效踢出是什么原理(高频题)
在分布式系统中,我们常常需要知道某个机器是否可用,传统的开发中,可以通过Ping某个主机来实现,Ping得通说明对方是可用的,相反是不可用的,ZK 中我们让所有的机器都注册一个临时节点,我们判断一个机器是否可用,我们只需要判断这个节点在ZK中是否存在就可以了,不需要直接去连接需要检查的机器,降低系统的复杂度。
6、zookeeper的有哪些节点,他们有什么区别?讲一下应用场景
zookeeper中节点是有生命周期的.具体的生命周期取决于节点的类型.节点主要分为持久节点(Persistent)和临时节点(Ephemeral),但是更详细的话还可以加上时序节点(Sequential),创建节点中往往组合使用,因此也就是4种:持久节点、持久顺序节点、临时节点、临时顺序节点。
- 所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点,也就是说不会因为创建该节点的客户端会话失效而消失。
- 临时节点的生命周期和客户端会话绑定,也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。
7、在dubbo中,什么时候更新本地的zookeeper信息缓存文件?订阅zookeeper信息的整体过程是怎么样的?
dubbo向zk发送了订阅请求以后,会去监听zk的回调,(如果zk有回调就回去调用notify方法),接着会去创建接口配置信息的持久化节点,同时dubbo也设置了对该节点的监听,zk节点如果发生了变化那么会触发回调方法,去更新zk信息的缓存文件,同时注册服务在调用的时候会去对比最新的配置信息节点,有差别的话会以最新信息为准重新暴露。《dubbo源码解析-zookeeper订阅》

zk订阅流程
服务引用
1、描述一下dubbo服务引用的过程,原理
上文已提供。
2、既然你提到了dubbo的服务引用中封装通信细节是用到了动态代理,那请问创建动态代理常用的方式有哪些,他们又有什么区别?dubbo中用的是哪一种?(高频题)
jdk、cglib还有javasisit,JDK的动态代理代理的对象必须要实现一个接口,而针对于没有接口的类,则可用CGLIB。要明白两者区别必须要了解原理,明白了原理自然一通百通,CGLIB其原理也很简单,对指定的目标类生成一个子类,并覆盖其中方法实现增强,但由于采用的是继承,所以不能对final修饰的类进行代理。除了以上两种大家都很熟悉的方式外,其实还有一种方式,就是javassist生成字节码来实现代理(dubbo多处用到了javassist)。
集群容错
1、dubbo提供了集中集群容错模式?
2、谈谈dubbo中的负载均衡算法及特点?最小活跃数算法中是如何统计活跃数的?简单谈谈一致性哈希算法
这部分可以多结合官方文档进行学习,而且涉及到了负载均衡的多个重要算法,也是高频的考察热点。
3、怎么通过dubbo实现服务降级的,降级的方式有哪些,又有什么区别?
当网站处于高峰期时,并发量大,服务能力有限,那么我们只能暂时屏蔽边缘业务,这里面就要采用服务降级策略了。首先dubbo中的服务降级分成两个:屏蔽(mock=force)、容错(mock=fail)。
mock=force:return+null表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。mock=fail:return+null表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
要生效需要在dubbo后台进行配置的修改:
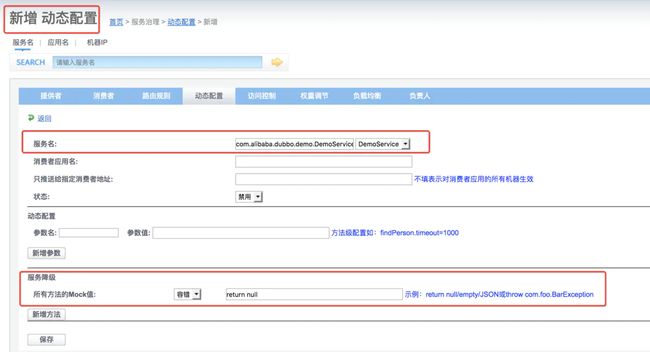
服务降级策略
4、dubbo监控平台能够动态改变接口的一些设置,其原理是怎样的?
改变注册在zookeeper上的节点信息,从而zookeeper通知重新生成invoker(这些具体细节在zookeeper创建节点,zookeeper连接,zookeeper订阅中都详细讲了,这里不再重复)。
学习框架三部曲:
- 掌握基本使用
- 看过源码,知道其中原理
- 临摹源码,自己仿写一个简易的框架
临摹源码的这个过程,也需要分为三个过程,分别是入门版(用最简单的代码表达出框架原理),进阶版(加入设计模式等思想,在入门版的基础上优化代码),高级版(和框架代码基本一致)。
《dubbo源码解析》
《cyfonly-DUBBO源码系列文章》
作者:千淘萬漉
链接:https://www.jianshu.com/p/292fcdcfe41e
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。