享元模式
文章目录
-
- 享元模式
-
- 1.享元模式的本质
- 2.何时选用享元模式
- 3.优缺点
- 4.享元模式的结构
- 5.实现
-
- 最初实现
- 享元模式初步改造
- 享元模式再改进
- 享元模式再优化
- 5.JVM本地缓存和享元模式区别?
享元模式
享元模式最开始看就是类似缓存,缓存一些信息,节约查询时间,以空间换时间
但是再理解后才发现他的好处,他可以细粒化对象,抽离内部状态和外部状态做共享,减少对象数量,节约内存
1.享元模式的本质
享元模式的本质:分离与共享。
分离的是对象状态中变与不变的部分,共享的是对象中不变的部分。享元模式的关键之处就在于分离变与不变,把不变的部分作为享元对象的内部状态,而变化部分则作为外部状态,由外部来维护,这样享元对象就能够被共享,从而减少对象数量,并节省大量的内存空间。
总而言之,享元模式的本质是通过共享内部状态来降低对象的数量,以达到节省资源和提高性能的目的。它适用于存在大量相似对象的场景,其中对象的内部状态可以共享,而外部状态需要分离。
享元模式一般情况下使用此结构在平时的开发中并不太多,除了一些
线程池、数据库连接池外,再就是游戏场景下的场景渲染。另外这个设计的模式思想是减少内存的使用提升效率,与我们之前使用的原型模式通过克隆对象的方式生成复杂对象,减少rpc的调用,都是此类思想。
2.何时选用享元模式
-
大量相似对象:当系统中存在大量相似的对象,并且这些对象的内部状态可以共享时,可以考虑使用享元模式。通过共享内部状态,可以减少对象的数量,从而节省内存空间和提高系统性能。
-
内部状态与外部状态分离:当对象的状态可以分为内部状态和外部状态,并且内部状态可以共享,而外部状态是变化的,需要在运行时传递给对象时,可以考虑使用享元模式。通过将内部状态共享,可以在不同的外部状态下重复使用对象,避免创建大量相似的对象。
-
需要缓存或对象池:当需要对对象进行缓存或维护对象池时,可以考虑使用享元模式。享元模式提供了一个集中管理对象的机制,可以有效地创建、共享和重用对象,以减少创建和销毁对象的开销。
-
对象创建开销大:当创建对象的开销较大,且创建的对象数量较多时,可以考虑使用享元模式。通过共享内部状态,可以减少对象的创建次数,从而提高系统的性能和效率。
3.优缺点
享元模式的优点是:减少对象数量,节省内存空间。
- 可能有的朋友认为共享对象会浪费空间,但是如果这些对象频繁使用,那么其实是·节省空间的。因为占用空间的大小等于每个对象实例占用的大小再乘以数量,对于享元对象来讲,基本上就只有一个实例,大大减少了享元对象的数量,并节省不少的内存空间。
节省的空间取决于以下几个因素:因为共享而减少的实例数目、每个实例本身所占用的空间。假如每个对象实例占用2个字节,如果不共享数量是100个,而共享后就只有一个了,那么节省的空间约等于(100-1)×2字节。 - 性能提升:共享对象减少了对象的创建和销毁次数,从而提高了系统的性能和效率。对象的复用减少了对内存的频繁访问,加快了程序的执行速度。
享元模式的缺点是:维护共享对象,需要额外开销。
- 如同前面演示的享元工厂,在维护共享对象的时候,如果功能复杂,会有很多额外的开销,比如有一个线程来维护垃圾回收。
4.享元模式的结构

- Flyweight:享元接口,通过这个接口 Flyweight可以接受并作用于外部状态。通过这个接口传入外部的状态,在享元对象的方法处理中可能会使用这些外部的数据。
- ConcreteFlyweight:具体的享元实现对象,必须是可共享的,需要封装 Flyweight的内部状态。
- UnsharedConcreteFlyweight:非共享的享元实现对象,并不是所有的 Flyweight实现对象都需要共享。非共享的享元实现对象通常是对共享享元对象的组合对象。
- FlyweightFactory:享元工厂,主要用来创建并管理共享的享元对象,并对外提供访问共享享元的接口。
- Client:享元客户端,主要的工作是维持一个对Flyweight的引用,计算或存储享元对象的外部状态,当然这里可以访问共享和不共享的Flyweight对象。
5.实现
现有6个客户想各自做一个网站,整体结构相同,但归属不同客户
-
有的客户希望是新闻发布形式的
-
有的客户希望是博客形式的
-
有的客户希望是公众号形式的等等
最初实现
1.网站类
/**
* @description:网站类
*/
@AllArgsConstructor
public class WebSite {
private String name = "";
public void init() {
System.out.println("当前网站分类: " + name);
}
}
2.测试类
public class Test {
public static void main(String[] args) {
WebSite webSite1 = new WebSite("博客");
webSite1.init();
WebSite webSite2 = new WebSite("博客");
webSite2.init();
WebSite webSite3 = new WebSite("博客");
webSite3.init();
WebSite webSite4 = new WebSite("新闻发布");
webSite4.init();
WebSite webSite5 = new WebSite("公众号");
webSite5.init();
WebSite webSite6 = new WebSite("公众号");
webSite6.init();
}
}
3.结果
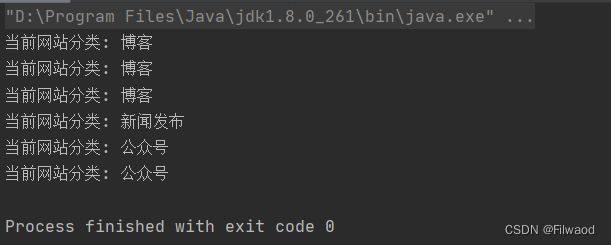
享元模式初步改造
1.网站接口及其实现类(也可不要接口)
/**
* @description:网站接口
*/
public interface WebSite {
/**
* 初始化网站
*/
void init();
}
/**
* @description:网站实现类
*/
@AllArgsConstructor
public class ConcreteWebSite implements WebSite {
/**
* 网站类型
*/
private String type;
@Override
public void init() {
System.out.println("当前网站分类: " + type);
}
}
2.网站工厂类
/**
* @description:网站工厂
*/
public class WebSiteFactory {
/**
* 缓存网站对象
*/
private Map<String, WebSite> map = new HashMap<>();
/**
* 获取网站对象
* @param type 网站类型
* @return
*/
public WebSite getWebSiteCategory(String type) {
//存在这个类型的网站就直接返回,不存在就新建放入map中缓存起来
if (map.get(type) == null) {
map.put(type, new ConcreteWebSite(type));
}
return map.get(type);
}
/**
* 统计缓存的网站对象数量
* @return
*/
public Integer getWebSiteCount() {
return map.size();
}
}
3.测试类
public class Client {
public static void main(String[] args) {
// 创建一个工厂
WebSiteFactory factory = new WebSiteFactory();
// 给客户创建一个博客类型的网站
WebSite webSite1 = factory.getWebSiteCategory("博客");
webSite1.init();
// 给客户创建一个博客类型的网站
WebSite webSite2 = factory.getWebSiteCategory("博客");
webSite2.init();
// 给客户创建一个博客类型的网站
WebSite webSite3 = factory.getWebSiteCategory("博客");
webSite3.init();
// 给客户创建一个新闻发布类型的网站
WebSite webSite4 = factory.getWebSiteCategory("新闻发布");
webSite4.init();
// 给客户创建一个公众号类型的网站
WebSite webSite5 = factory.getWebSiteCategory("公众号");
webSite5.init();
// 给客户创建一个公众号类型的网站
WebSite webSite6 = factory.getWebSiteCategory("公众号");
webSite6.init();
// 查看实例数
System.out.println("实例数:" + factory.getWebSiteCount());
}
}
4.结果
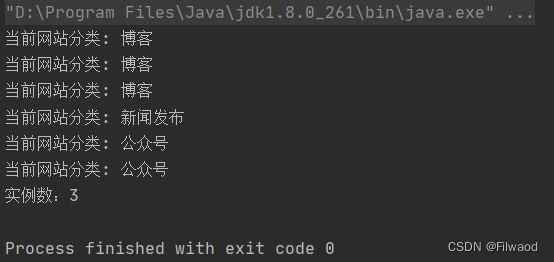
可以看到只创建了3个对象,而最初的写法创建了6个对象,现在看可能提升不明显,但如果是需要创建100个对象,1000个对象呢?
享元模式再改进
上面创建三个博客类型的网站,但是好像这三个网站就是一模一样的,但是不同的客户,所以加上网站归属用户,再改造
1.接口不变
2.实现类增加客户名属性
/**
* @description:网站实现类
*/
@AllArgsConstructor
public class ConcreteWebSite implements WebSite {
/**
* 网站类型
*/
private String type;
/**
* 网站归属用户
*/
private String userName;
@Override
public void init() {
System.out.println("当前网站分类: " + type + " 【客户】: " + userName);
}
}
3.网站工厂类,现在有两个属性(网站类型、客户名),用他俩一起做键
/**
* @description:网站工厂
*/
public class WebSiteFactory {
/**
* 缓存网站对象
*/
private Map<String, WebSite> map = new HashMap<>();
/**
* 获取网站对象
* @param type 网站类型
* @return
*/
public WebSite getWebSiteCategory(String type, String userName) {
//用"客户:类型"做键
String key = userName + ":" + type;
//存在这个类型的网站就直接返回,不存在就新建放入map中缓存起来
if (map.get(key) == null) {
map.put(key, new ConcreteWebSite(type, userName));
}
return map.get(key);
}
/**
* 统计缓存的网站对象数量
* @return
*/
public Integer getWebSiteCount() {
return map.size();
}
}
4.测试类
public class Client {
public static void main(String[] args) {
// 创建一个工厂
WebSiteFactory factory = new WebSiteFactory();
// 给客户创建一个博客类型的网站
WebSite webSite1 = factory.getWebSiteCategory("博客", "客户A");
webSite1.init();
// 给客户创建一个博客类型的网站
WebSite webSite2 = factory.getWebSiteCategory("博客", "客户B");
webSite2.init();
// 给客户创建一个博客类型的网站
WebSite webSite3 = factory.getWebSiteCategory("博客", "客户C");
webSite3.init();
// 给客户创建一个新闻发布类型的网站
WebSite webSite4 = factory.getWebSiteCategory("新闻发布", "客户A");
webSite4.init();
// 给客户创建一个公众号类型的网站
WebSite webSite5 = factory.getWebSiteCategory("公众号", "客户B");
webSite5.init();
// 给客户创建一个公众号类型的网站
WebSite webSite6 = factory.getWebSiteCategory("公众号", "客户C");
webSite6.init();
// 查看实例数
System.out.println("实例数:" + factory.getWebSiteCount());
}
}
5.结果
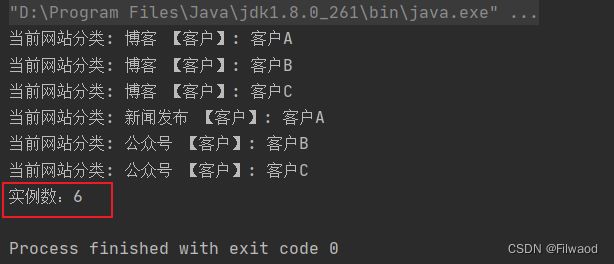
可以看到又是6个对象了,那这样用不用设计模式都一样了
享元模式再优化
从上面结果可以发现,网站其实只有3种类型(博客、新闻发布、公众号),只是归属不同的客户,那么可以拆分,将网站类型作为内部状态,客户作为外部状态,再改造
-
内部状态:对象共享出来的信息,存储在享元对象内部并且不会随环境改变的共享部分–>网站类型
-
外部状态:对象用来标记的一个内容,随环境会改变,不可共享–>客户
1.改造网站接口及其实现类,在调用方法时传入客户名
/**
* @description:网站接口
*/
public interface WebSite {
/**
* 初始化网站传入客户名
* @param userName 客户名
*/
void init(String userName);
}
/**
* @description:网站实现类
*/
@AllArgsConstructor
public class ConcreteWebSite implements WebSite {
/**
* 网站类型
*/
private String type;
@Override
public void init(String userName) {
System.out.println("当前网站分类: " + type + " 【客户】: " + userName);
}
}
2.网站工厂类不变
/**
* @description:网站工厂
*/
public class WebSiteFactory {
/**
* 缓存网站对象
*/
private Map<String, WebSite> map = new HashMap<>();
/**
* 获取网站对象
* @param type 网站类型
* @return
*/
public WebSite getWebSiteCategory(String type) {
//存在这个类型的网站就直接返回,不存在就新建放入map中缓存起来
if (map.get(type) == null) {
map.put(type, new ConcreteWebSite(type));
}
return map.get(type);
}
/**
* 统计缓存的网站对象数量
* @return
*/
public Integer getWebSiteCount() {
return map.size();
}
}
3.测试类
public class Client {
public static void main(String[] args) {
// 创建一个工厂
WebSiteFactory factory = new WebSiteFactory();
// 给客户创建一个博客类型的网站
WebSite webSite1 = factory.getWebSiteCategory("博客");
webSite1.init("客户A");
// 给客户创建一个博客类型的网站
WebSite webSite2 = factory.getWebSiteCategory("博客");
webSite2.init("客户B");
// 给客户创建一个博客类型的网站
WebSite webSite3 = factory.getWebSiteCategory("博客");
webSite3.init("客户C");
// 给客户创建一个新闻发布类型的网站
WebSite webSite4 = factory.getWebSiteCategory("新闻发布");
webSite4.init("客户A");
// 给客户创建一个公众号类型的网站
WebSite webSite5 = factory.getWebSiteCategory("公众号");
webSite5.init("客户B");
// 给客户创建一个公众号类型的网站
WebSite webSite6 = factory.getWebSiteCategory("公众号");
webSite6.init("客户C");
// 查看实例数
System.out.println("实例数:" + factory.getWebSiteCount());
}
}
4.结果
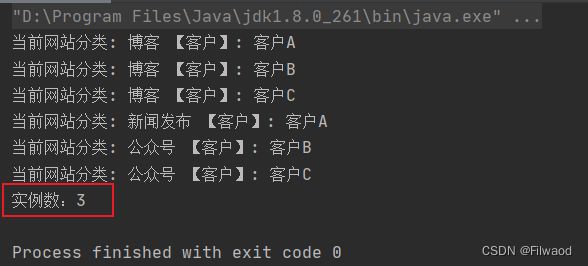
这样将不变的信息作为内部状态,将不确定的信息作为外部状态,这就是享元模式的最终模式
5.JVM本地缓存和享元模式区别?
JVM本地缓存和享元模式有一些区别,主要体现在以下几个方面:
-
关注点不同:JVM本地缓存主要关注数据的缓存和高效访问,旨在减少对于远程数据源的访问次数,提高系统的性能和响应速度。享元模式主要关注对象的共享和内存的节省,通过共享相同的状态来减少对象的数量。
-
缓存粒度不同:JVM本地缓存通常以数据为粒度进行缓存,以便在需要时快速访问数据。而享元模式以对象为粒度进行共享,将对象的内部状态共享,而外部状态则在需要时传递给享元对象。
-
数据来源不同:JVM本地缓存是为了避免频繁访问远程数据源(如数据库、网络接口等),将数据存储在本地内存中。而享元模式不关注数据的来源,它主要是通过共享对象的内部状态来减少对象的数量。
-
生命周期管理不同:JVM本地缓存通常需要考虑缓存的生命周期管理,包括缓存的更新、过期策略和淘汰机制等。而享元模式在对象的共享方面更加关注对象的管理和共享池的维护。