爬取58二手房并用SVR模型拟合
目录
一、前言
二、爬虫与数据处理
三、模型
一、前言
爬取数据仅用于练习和学习。本文运用二手房规格sepc(如3室2厅1卫)和二手房面积area预测二手房价格price,只是练习和学习,不代表如何实际意义。
二、爬虫与数据处理
import requests
import chardet
import pandas as pd
import time
from lxml import etree
from fake_useragent import UserAgent
ua = UserAgent()
user_agent = ua.random
print(user_agent)
url = 'https://gy.58.com/ershoufang/'
headers = {
'User-Agent':user_agent
}
resp = requests.get(url=url, headers=headers)
encoding = chardet.detect(resp.content)['encoding']
resp.encoding = encoding
page_text = resp.text
tree = etree.HTML(page_text)
page_num_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/ul/li/a/text()')
page_num = [item.strip() for item in page_num_data if item.strip().isdigit()]
last_page = int(page_num[-1])
total_address_title = []
total_BR_LR_B = []
total_area = []
total_price = []
empty_title = 0
empty_address_data = 0
empty_BR_LR_B_data = 0
empty_area_data = 0
empty_price_data = 0
for i in range(1, last_page+1):
url = 'https://gy.58.com/ershoufang/p{}/?PGTID=0d100000-007d-f5b6-2cca-9cae0bcabf83&ClickID=1'.format(i)
headers = {
'User-Agent':user_agent
}
resp = requests.get(url=url, headers=headers)
encoding = chardet.detect(resp.content)['encoding']
resp.encoding = encoding
page_text = resp.text
tree = etree.HTML(page_text)
title = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/div/h3[@class="property-content-title-name"]/text()')
time.sleep(3)
address_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-comm-address"]/span/text()')
address = [''.join(address_data[i:i+3]) for i in range(0, len(address_data), 3)]
time.sleep(3)
title_address = [str(address[i]) + '||' + str(title[i]) for i in range(min(len(address), len(title)))]
total_address_title.extend(title_address)
BR_LR_B_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-text property-content-info-attribute"]/span/text()')
BR_LR_B = [''.join(BR_LR_B_data[i:i+6]) for i in range(0, len(BR_LR_B_data), 6)]
total_BR_LR_B.extend(BR_LR_B)
time.sleep(3)
area_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-text"]/text()')
area = [item.strip() for item in area_data if '㎡' in item.strip()]
total_area.extend(area)
time.sleep(3)
price_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/p/span[@class="property-price-total-num"]/text()')
price = [price + '万' for price in price_data]
total_price.extend(price)
time.sleep(3)
if len(title) == 0:
empty_title += 1
if len(address_data) == 0:
empty_address_data += 1
if len(BR_LR_B_data) == 0:
empty_BR_LR_B_data += 1
if len(area_data) == 0:
empty_area_data += 1
if len(price_data) == 0:
empty_price_data += 1
print('Page{} 爬取成功'.format(i))
df = pd.DataFrame({
'地址': total_address_title,
'规格': total_BR_LR_B,
'面积': total_area,
'价格': total_price
})
print(empty_title, empty_address_data, empty_BR_LR_B_data, empty_area_data, empty_price_data)
df.to_excel('58二手房信息表.xlsx', index=False, engine='openpyxl')
print('58二手房信息表保存成功!')
# 处理表格
df = pd.read_excel('C:\\Users\\sjl\\Desktop\\58Second-hand-house\\58二手房信息表.xlsx')
delete_column = '地址'
df = df.drop(delete_column, axis=1) # 删除地址一列
df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '') # 删除文字和字符,保留数值
df = df.rename(columns={'规格': 'spec', '面积': 'area', '价格': 'price'}) # 重命名列
df = df * 0.001 # 缩小数值, 减少计算量
df.to_excel('58Second-hand-house.xlsx', index=False, engine='openpyxl')
print('数据处理成功!')1. 运用chardet库自动获取网页编码
import chardet
resp = requests.get(url=url, headers=headers)encoding = chardet.detect(resp.content)['encoding']
resp.encoding = encoding
2. 运用fake_useragent库,生成随机的用户代理字符串,获取一个随机的用户代理来使用
from fake_useragent import UserAgent
ua = UserAgent()
user_agent = ua.random
print(user_agent)
3. 使用列表推导,去除每个元素的空白字符,并保留那些只包含数字的元素,以获取网站页数
page_num = [item.strip() for item in page_num_data if item.strip().isdigit()]
首先使用strip()方法去除其两端的空白字符(包括换行符\n、空格等),接着使用isdigit()方法检查处理后的字符串是否只包含数字。如果条件成立,即字符串只包含数字,那么这个处理后的字符串就会被包含在page_num列表中。
4. 使用列表推导来遍历列表,并将每三个元素组合成一个元素,获取大致地址
address = [''.join(address_data[i:i+3]) for i in range(0, len(address_data), 3)]
首先通过range(0, len(address_data) 3)生成一个从0开始,address_data最后一位长度结束,步长为3的序列。然后,对于序列中的每个i,使用''.join(address_data[i, i+3])连接从i到i+3(不包括i+3)的元素。这样,每三个元素就被拼接成了一个元素,并存储在address中。
5. 考虑到大致地址会有重复,在地址后附加上标题,作为每个二手房独一无二的标志
title_address = [str(address[i]) + '||' + str(title[i]) for i in range(min(len(address), len(title)))]
6. 同样合并'3','室','2','厅','1','卫'
BR_LR_B = [''.join(BR_LR_B_data[i:i+6]) for i in range(0, len(BR_LR_B_data), 6)]
7. 使用列表推导结合字符串处理方法获得只包含面积部分
area = [item.strip() for item in area_data if '㎡' in item.strip()]
遍历列表,对于每个元素,使用strip()方法去除前后的空格和换行符。检查处理过的字符串是否包含 "㎡" 字符,如果包含,则认为这个字符串表示面积信息。将这些面积信息添加到一个area列表中。
8. 在价格后加上 "万"
price = [price + '万' for price in price_data]
9. 监控得到有9页数据爬取失败
if len(title) == 0:
empty_title += 1
if len(address_data) == 0:
empty_address_data += 1
if len(BR_LR_B_data) == 0:
empty_BR_LR_B_data += 1
if len(area_data) == 0:
empty_area_data += 1
if len(price_data) == 0:
empty_price_data += 1
10. 删除表中的文字
df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '')
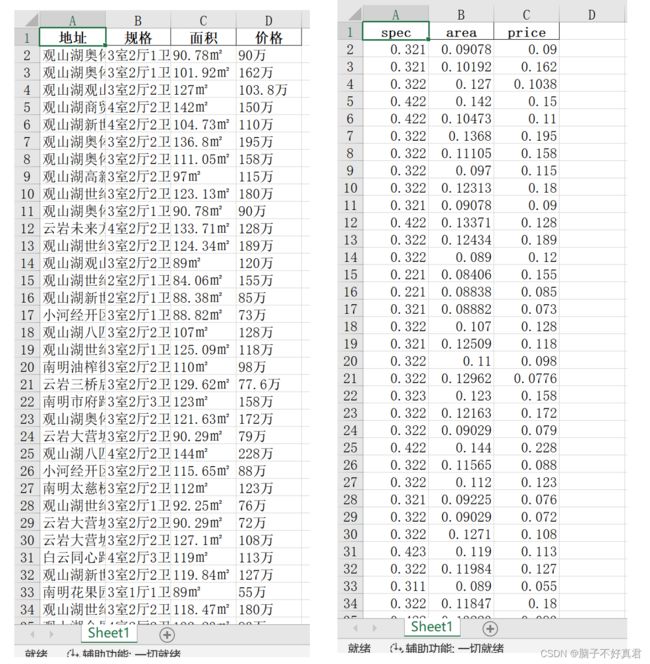
11.部分数据展示(处理前后)
delete_column = '地址'
df = df.drop(delete_column, axis=1) # 删除地址一列
df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '') # 删除文字和字符,保留数值
df = df.rename(columns={'规格': 'spec', '面积': 'area', '价格': 'price'}) # 重命名列
df = df * 0.001 # 缩小数值, 减少计算量
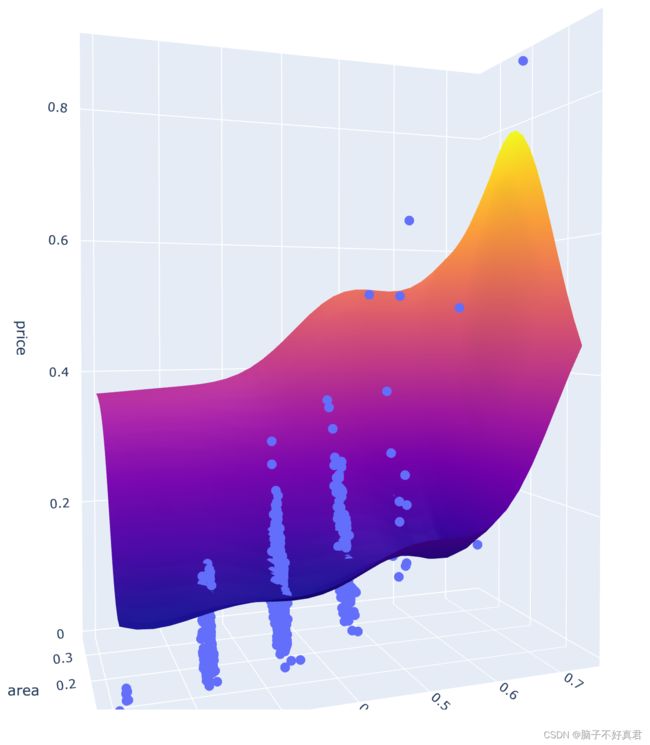
三、模型
模型官网:Ml regression in PythonOver 13 examples of ML Regression including changing color, size, log axes, and more in Python. https://plotly.com/python/ml-regression/
https://plotly.com/python/ml-regression/
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from sklearn.svm import SVR
mesh_size = .02
margin = 0
df = pd.read_excel('C:\\Users\\sjl\\Desktop\\58Second-hand-house\\58Second-hand-house.xlsx')
X = df[['spec', 'area']]
y = df['price']
# Condition the model on sepal width and length, predict the petal width
model = SVR(C=1.)
model.fit(X, y)
# Create a mesh grid on which we will run our model
x_min, x_max = X.spec.min() - margin, X.spec.max() + margin
y_min, y_max = X.area.min() - margin, X.area.max() + margin
xrange = np.arange(x_min, x_max, mesh_size)
yrange = np.arange(y_min, y_max, mesh_size)
xx, yy = np.meshgrid(xrange, yrange)
# Run model
pred = model.predict(np.c_[xx.ravel(), yy.ravel()])
pred = pred.reshape(xx.shape)
# Generate the plot
fig = px.scatter_3d(df, x='spec', y='area', z='price')
fig.update_traces(marker=dict(size=5))
fig.add_traces(go.Surface(x=xrange, y=yrange, z=pred, name='pred_surface'))
fig.show()