Python爬取豆瓣Top250电影数据
一、Python爬取目标数据,并写入csv
运用了requests库获取页面、BeautifulSoup库解析页面(方法很多,可自行延伸)
1、引入库
import requests
from bs4 import BeautifulSoup
import csv
import re
2、获取一级页面内容
用"get_one_page()"作为函数,别忘了添加"headers"做反爬
特别注意:
“cookie"值要用自己注册的豆瓣账号登陆后的页面获取的"cookie”
def get_one_page(url):
headDict = {
加入自己的“user_agent:”、“accept“、”cookie“
}
r = requests.get(url,headers = headDict)
r.encoding = r.apparent_encoding
html = r.text
return html
3、解析获取的页面
解析页面时,我爬取的是:
电影排名、片名、评分、评价人数、电影类型、制片国家、上映时间、电影时长
在一级页面爬取了制片国家(二级也可以爬取),其他指标都在二级爬取
运用了find、select,也可以用xpath、re
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
movie = soup.find("ol",class_='grid_view')
erjilianjie = movie.find_all('li')
for lianjie in erjilianjie:
#一级页面制片国家
others = lianjie.find('div', class_='bd').find('p').text.strip('').split('\n')
year_country = others[2].strip('').split('\xa0/\xa0')
pro_country = year_country[1].replace(' ',',')
#链接
a = lianjie.find('a')
erji = a['href']
html = get_one_page(erji)
soup = BeautifulSoup(html,'lxml')
#排名
ranks = soup.select('#content > div.top250 > span.top250-no')[0].getText().strip()
#片名
spans = soup.select('h1 span')
movie_name1 = spans[0].get_text()
movie_name = movie_name1.split(' ')[0]
# print(movie_name)
#评分
score = soup.select('#interest_sectl > div.rating_wrap.clearbox > div.rating_self.clearfix > strong')[0].getText().strip()
#评价人数
sorce_people = soup.select('#interest_sectl > div.rating_wrap.clearbox > div.rating_self.clearfix > div > div.rating_sum > a > span')[0].getText().strip()
#info板块
info = soup.find('div',id='info')
#电影类型
movie_type = ''
movie_types = info.find_all('span',property='v:genre')
for i in movie_types:
movie_type = movie_type + ',' + i.string
movie_type = movie_type.lstrip(',')
#二级页面制片国家
# pro_country = re.findall("制片国家/地区:(.*)
",str(info))
# pro_country = ','.join(pro_country)
# print(pro_country)
#上映日期
up_time = ''
up_times = info.find_all('span',property='v:initialReleaseDate')
for i in up_times:
up_time = up_time + "," + i.string
up_time = up_time.lstrip(',')
#电影时长
movie_time = ''
movie_times = info.find_all('span',property='v:runtime')
for i in movie_times:
movie_time = movie_time + i.string
#将数据写入data,做迭代器储存数据
data = {
'id':ranks,
'name':movie_name,
'score':score,
'votes':sorce_people,
'country':pro_country,
'type':movie_type,
'date':up_time,
'runtime':movie_time,
'link':erji
}
yield data
4、写入csv文件
def write_to_file(content):
file_name = 'movie.csv'
with open(file_name,'a',newline='',encoding='utf-8') as f:
writer = csv.writer(f)
for i in content:
writer.writerow(i.values())
5、调用主函数
特别注意:
一定要调用函数,调试时,只用一页来调试,多页会反爬
if __name__ == "__main__":
for i in range(10):
urls = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter='
html = get_one_page(urls)
parse_one_page(html)
content = parse_one_page(html)
write_to_file(content)
print("写入第"+str(i)+"页数据成功")
# # 调试函数
# url = 'https://movie.douban.com/top250'
# html = get_one_page(url)
# parse_one_page(html)
# content = parse_one_page(html)
二、pymysql数据存储
1.在navicate中创建movie表
特别注意:
创建正确的数据类型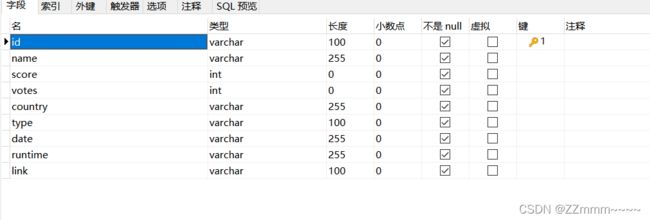
2、将movie.csv里的数据传入movie表
特别注意:
"db"是数据库名称,用自己navicate里的host、user、password
import pymysql
import csv
def write_to_table():
#连接MYSQL数据库(注意:charset参数是utf8m64而不是utf-8)
db = pymysql.connect(host = "localhost",
user = 'root',
password = 'root',
db = "movie",
charset = "utf8m64",)
#创建对象
cursor = db.cursor()
#读取csv文件
with open('movie.csv','r',encoding='utf-8') as f:
read = csv.reader(f)
for each in list(read):
i = tuple(each)
# print(i)
#SQL语句添加数据
sql = "INSERT INTO movie VALUES" + str(i)
#执行SQL语句
cursor.execute(sql)
# 提交数据
db.commit()
# #关闭游标
cursor.close()
# #关闭数据库
db.close()
if __name__ == '__main__':
write_to_table()
三、pandas数据清洗、处理
1、jupyter读取movie.csv中数据并处理
import numpy as np
import pandas as pd
#如果没有header = None,会自动将第一行设置为表头哦
data=pd.read_table('movie.csv',sep=',',header = None)
data
四、pandas、pyecharts、matplotlib数据可视化
1、读取movie1.csv文件数据
import pandas as pd
data = pd.read_csv('movie1.csv')
data
2、绘制电影评价人数前十名(柱状图)
from pyecharts import options as opts
from pyecharts.charts import Bar
df = data.sort_values(by='评价人数', ascending=True)
bar = (
Bar()
.add_xaxis(df['片名'].values.tolist()[-10:])
.add_yaxis('评价人数', df['评价人数'].values.tolist()[-10:])
.set_global_opts(
title_opts=opts.TitleOpts(title='电影评价人数'),
yaxis_opts=opts.AxisOpts(name='人数'),
xaxis_opts=opts.AxisOpts(name='片名'),
datazoom_opts=opts.DataZoomOpts(type_='inside'),
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.render('电影评价人数前十名.html')
)
bar