mongdb聚合与管道操作符
目录
一、聚合介绍
1、aggregate() 方法
语法
2、聚合表达式
二、管道介绍
常见的管道操作符
多个管道操作符执行示例
三、管道操作符示例
1.$match
2.$project
1. 基本用法
2. 数学表达式
3. 日期表达式
4. 字符串表达式
5. 逻辑表达式
3.$group
1. 基本操作
2. 算术操作符
3. 极值操作符
4.$unwind
5.其他操作符:sort/limit/skip
四、总结
一、聚合介绍
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
有点类似 SQL 语句中的 count(*)。
1、aggregate() 方法
MongoDB中聚合的方法使用aggregate()。
语法
aggregate() 方法的基本语法格式如下所示:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)2、聚合表达式
下表展示了一些聚合的表达式:
| 表达式 |
描述 |
实例 |
| $sum |
以by_user分组,计算每组likes总和。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg |
以by_user分组,计算每组likes平均值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min |
以by_user分组,获取集合中所有文档对应值得最小值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max |
以by_user分组,获取集合中所有文档对应值得最大值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push |
将值加入一个数组中,不会判断是否有重复的值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet |
将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 |
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first |
根据资源文档的排序获取第一个文档数据。 |
db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last |
根据资源文档的排序获取最后一个文档数据 |
db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
二、管道介绍
熟悉Linux操作系统的小伙伴们应该知道Linux中有管道的说法,可以用来方便的处理数据。
MongoDB2.2版本也引入了新的数据聚合框架,一个文档可以经过多个节点组成的管道,每个节点都有自己特殊的功能,比如文档分组、文档过滤等,每一个节点都会接受一连串的文档,对这些文档做一些类型转换,然后将转换后的文档传递给下一个节点,最后一个节点则会将结果返回给客户端。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
常见的管道操作符
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
多个管道操作符执行示例
db.email_message.aggregate(
[
{"$match":{emailAcctId: "00990100402000022032801018411"}},
{"$group":{
_id:{uid:"$uid", emailAcctId:"$emailAcctId", messageId:"$messageId"},
count:{$sum:1}}
},
{"$match":{count: {$gt:1}}}
]
);执行顺序:
- 匹配emailAcctId = 00990100402000022032801018411的文档;
- 以uid、emailAccId、messageId为组,查询出_id和count字段;
- 相当于MySQL语句:select uid,emailAccId,messageId,count(*) from email_message group by uid,emailAccId,messageId
- 对分组后的文档数据,匹配count > 1的文档;
三、管道操作符示例
1.$match
match中都可以使用,比如获取集合中所有author为”杜甫”的文档,如下:
db.sang_collect.aggregate({$match:{author:"杜甫"}})
我们在实际使用时最好将match还可以用索引。
2.$project
1. 基本用法
$project可以用来提取想要的字段,如下:
db.sang_collect.aggregate({$project:{title:1,_id:0}})
1表示要该字段,0表示不要该字段,也可以对返回的字段进行重命名,比如将title改为articleTitle,如下:
db.sang_collect.aggregate({$project:{"articleTitle":"$title"}})
不过这里有一个问题需要注意,如果原字段上有索引,重命名之后的字段上就没有索引了,因此最好在重命名之前使用索引。
2. 数学表达式
数学表达式可以用来对一组数值进行加减乘除取模,比如我的数据结构如下:
{
"_id" : ObjectId("59f841f5b998d8acc7d08863"),
"orderAddressL" : "ShenZhen",
"prodMoney" : 45.0,
"freight" : 13.0,
"discounts" : 3.0,
"orderDate" : ISODate("2017-10-31T09:27:17.342Z"),
"prods" : [
"可乐",
"奶茶"
]
}
订单的总费用为商品费用加上运费,查询如下:
db.sang_collect.aggregate({$project:{totalMoney:{$add:["$prodMoney","$freight"]}}})
实际付款的费用是总费用减去折扣,如下:
db.sang_collect.aggregate({$project:{totalPay:{$subtract:[{$add:["$prodMoney","$freight"]},"$discounts"]}}})
再来三个无厘头运算,比如计算prodMoney和freight和discounts的乘积:
db.sang_collect.aggregate({$project:{test1:{$multiply:["$prodMoney","$freight","$discounts"]}}})
再比如求freight的商,如下:
db.sang_collect.aggregate({$project:{test1:{$divide:["$prodMoney","$freight"]}}})
再比如用prodMoney取模,如下:
db.sang_collect.aggregate({$project:{test1:{$mod:["$prodMoney","$freight"]}}})
加法和乘法都可以接收多个参数,其余的都接收两个参数。
3. 日期表达式
日期表达式可以从一个日期类型中提取出年、月、日、星期、时、分、秒等信息,如下:
db.sang_collect.aggregate({$project:{"年份":{$year:"$orderDate"},"月份":{$month:"$orderDate"},"一年中第几周":{$week:"$orderDate"},"日期":{$dayOfMonth:"$orderDate"},"星期":{$dayOfWeek:"$orderDate"},"一年中第几天":{$dayOfYear:"$orderDate"},"时":{$hour:"$orderDate"},"分":{$minute:"$orderDate"},"秒":{$second:"$orderDate"},"毫秒":{$millisecond:"$orderDate"},"自定义格式化时间":{$dateToString:{format:"%Y年%m月%d %H:%M:%S",date:"$orderDate"}}}})
执行结果如下:
{
"_id" : ObjectId("59f841f5b998d8acc7d08861"),
"年份" : 2017,
"月份" : 10,
"一年中第几周" : 44,
"日期" : 31,
"星期" : 3,
"一年中第几天" : 304,
"时" : 9,
"分" : 27,
"秒" : 17,
"毫秒" : 342,
"自定义格式化时间" : "2017年10月31 09:27:17"
}
week表示本周是本年的第几周,从0开始计。$dateToString是MongoDB3.0+中的功能。格式化的字符还有以下几种: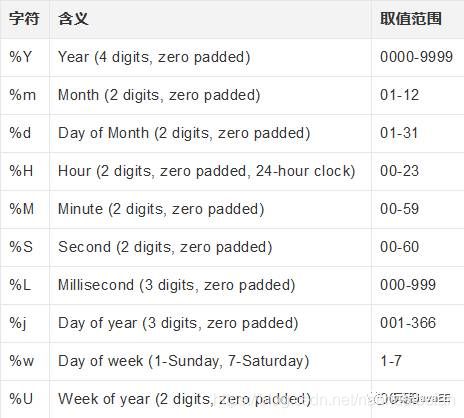
4. 字符串表达式
字符串表达式中有字符串的截取、拼接、转大写、转小写等操作,比如我截取orderAddressL前两个字符返回,如下:
db.sang_collect.aggregate({$project:{addr:{$substr:["$orderAddressL",0,2]}}})
再比如我将orderAddressL和orderDate拼接后返回:
db.sang_collect.aggregate({$project:{addr:{$concat:["$orderAddressL",{$dateToString:{format:"--%Y年%m月%d",date:"$orderDate"}}]}}})
结果如下:
{
"_id" : ObjectId("59f841f5b998d8acc7d08861"),
"addr" : "NanJing--2017年10月31"
}
再比如我将orderAddressL全部转为小写返回:
db.sang_collect.aggregate({$project:{addr:{$toLower:"$orderAddressL"}}})
再比如我将orderAddressL全部转为大写返回:
db.sang_collect.aggregate({$project:{addr:{$toUpper:"$orderAddressL"}}})
5. 逻辑表达式
想要比较两个数字的大小,可以使用$cmp操作符,如下:
db.sang_collect.aggregate({$project:{test:{$cmp:["$freight","$discounts"]}}})
如果第一个参数大于第二个参数返回正数,第一个参数小于第二个则返回负数,也可以利用$strcasecmp来比较字符串(中文无效):
db.sang_collect.aggregate({$project:{test:{$strcasecmp:[{$dateToString:{format:"..%Y年%m月%d",date:"$orderDate"}},"$orderAddressL"]}}})
至于我们之前介绍的ne/gte/lte等操作符在这里一样是适用的。另外还有or、and为例,如下:
db.sang_collect.aggregate({$project:{test:{$and:[{"$eq":["$freight","$prodMoney"]},{"$eq":["$freight","$discounts"]}]}}})
or则表示参数中有一个为true就返回true,$not则会对它的参数的值取反,如下:
db.sang_collect.aggregate({$project:{test:{$not:{"$eq":["$freight","$prodMoney"]}}}})
另外还有两个流程控制语句,如下:
db.sang_collect.aggregate({$project:{test:{$cond:[false,"trueExpr","falseExpr"]}}})
$cond第一个参数如果为true,则返回trueExpr,否则返回falseExpr.
db.sang_collect.aggregate({$project:{test:{$ifNull:[null,"replacementExpr"]}}})
$ifNull第一个参数如果为null,则返回replacementExpr,否则就返回第一个参数。
3.$group
1. 基本操作
$group可以用来对文档进行分组,比如我想将订单按照城市进行分组,并统计出每个城市的订单数量:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",count:{$sum:1}}})
我们将要分组的字段传递给$group函数的_id字段,然后每当查到一个,就给count加1,这样就可以统计出每个城市的订单数量。
2. 算术操作符
通过算术操作符我们可以对分组后的文档进行求和或者求平均数。比如我想计算每个城市订单运费总和,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",totalFreight:{$sum:"$freight"}}})
先按地址分组,再求和。这里贴出部分查询结果,如下:
{
"_id" : "HaiKou",
"totalFreight" : 20.0
}
{
"_id" : "HangZhou",
"totalFreight" : 10.0
}
也可以计算每个城市运费的平均数,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",avgFreight:{$avg:"$freight"}}})
先按地址分组,然后再计算平均数。
3. 极值操作符
极值操作符用来获取分组后数据集的边缘值,比如获取每个城市最贵的运费,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",maxFreight:{$max:"$freight"}}})
查询每个城市最便宜的运费:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",minFreight:{$min:"$freight"}}})
按城市分组之后,获取该城市第一个运费单:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",firstFreight:{$first:"$freight"}}})
获取分组后的最后一个运费单:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",lastFreight:{$last:"$freight"}}})
数据操作符$addToSet可以将分组后的某一个字段放到一个数组中,但是重复的元素将只出现一次,而且元素加入到数组中的顺序是无规律的,比如将分组后的每个城市的运费放到一个数组中,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",freights:{$addToSet:"$freight"}}})
重复的freight将不会被添加进来。
$push则对重复的数据不做限制,都可以添加进来,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",freights:{$push:"$freight"}}})
4.$unwind
$unwind用来实现对文档的拆分,可以将文档中的值拆分为单独的文档,比如我的数据如下:
{
"_id" : ObjectId("59f93c8b8523cfae4cf4ba86"),
"name" : "鲁迅",
"books" : [
{
"name" : "呐喊",
"publisher" : "花城出版社"
},
{
"name" : "彷徨",
"publisher" : "南海出版出"
}
]
}
使用$unwind命令将其拆分为独立文档,如下:
db.sang_books.aggregate({$unwind:"$books"})
拆分结果如下:
{
"_id" : ObjectId("59f93c8b8523cfae4cf4ba86"),
"name" : "鲁迅",
"books" : {
"name" : "呐喊",
"publisher" : "花城出版社"
}
}
{
"_id" : ObjectId("59f93c8b8523cfae4cf4ba86"),
"name" : "鲁迅",
"books" : {
"name" : "彷徨",
"publisher" : "南海出版出"
}
}
5.其他操作符:sort/limit/skip
$sort操作可以对文档进行排序,如下:
db.sang_collect.aggregate({$sort:{orderAddressL:1}})
用法和我们之前介绍普通搜索中的一致,可以按照存在的字段排序,也可以按照重命名的字段排序,如下:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$sort:{oa:-1}})
1表示升序、-1表示降序。
$limit返回结果中的前n个文档,如下表示返回结果中的前三个文档:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$limit:3})
$skip表示跳过前n个文档,比如跳过前5个文档,如下:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$skip:5})
$skip的效率低,要慎用。
四、总结
在管道开始执行的阶段尽可能过滤掉足够多的数据,这样做有两个好处:
- 只有从集合中直接查询时才会使用索引,尽早执行过滤可以让索引发挥作用;
- 该过滤的数据过滤掉之后,也可以降低后面管道的执行压力。另外,MongoDB不允许一个聚合操作占用过多的内存,如果有一个聚合操作占用了超过20%的内存,则会直接报错。
参考链接:
https://blog.csdn.net/nanhuaibeian/article/details/108201609