Zeppelin结合Flink查询hudi数据
关于Zeppelin

Zeppelin是基于 Web 的notebook,是支持使用 SQL、Scala、Python、R 等进行数据驱动的交互式数据分析和协作的Notebook。
Zeppelin支持多种语言后端,Apache Zeppelin 解释器允许将任何语言/数据处理后端插入 Zeppelin。 目前 Apache Zeppelin 支持 Apache Spark、Apache Flink、Python、R、JDBC、Markdown 和 Shell 等多种解释器。
简单来说就是,让你通过Web UI去实现很多本来需要登录服务器,通过终端才能实现的功能。
(关于Flink和Hudi介绍,可参考本博主其他文章,或 search by yourself)
下面今日正题。
本文涉及组件及其版本
| 组件名称 | 版本号 |
|---|---|
| hadoop | 3.2.0 |
| hudi | 0.10.0-SNAPSHOT |
| zeppelin | 0.10.0 |
| flink | 1.13.1 |
在执行以下操作之前,请先将数据导入hudi,如果还未导入,可参考:
使用FLINK SQL从savepoint恢复hudi作业 (flink 1.13)
相关博客文章将数据导入hudi
zeppelin安装包下载
mkdir /data && cd /data
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0-bin-all.tgz
tar zxvf zeppelin-0.10.0-bin-all.tgz
ln -s /data/zeppelin-0.10.0-bin-all /data/zeppelin
zeppelin配置文件修改
cd /data/zeppelin/conf
cp zeppelin-site.xml.template zeppelin-site.xml
将zeppelin.server.addr配置项修改为0.0.0.0
zeppelin默认端口使用8080,如果和你本地端口冲突可将其改为别的端口,本文档将端口修改为8008,也就是将zeppelin.server.port配置项修改为8008
cp zeppelin-env.sh.template zeppelin-env.sh
填入以下变量:
export JAVA_HOME=/data/jdk
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
export FLINK_HOME=/data/flink
各变量请根据自己环境进行设置。
本文后续使用默认的local模式启动Flink。
启动zeppelin
bin/zeppelin-daemon.sh start
此时如果你们没有创建logs文件夹以及run文件夹,那么会在zeppelin目录下自动创建,如下所示:
[root@hadoop zeppelin]# bin/zeppelin-daemon.sh start
Log dir doesn't exist, create /data/zeppelin/logs
Pid dir doesn't exist, create /data/zeppelin/run
Zeppelin start [ OK ]
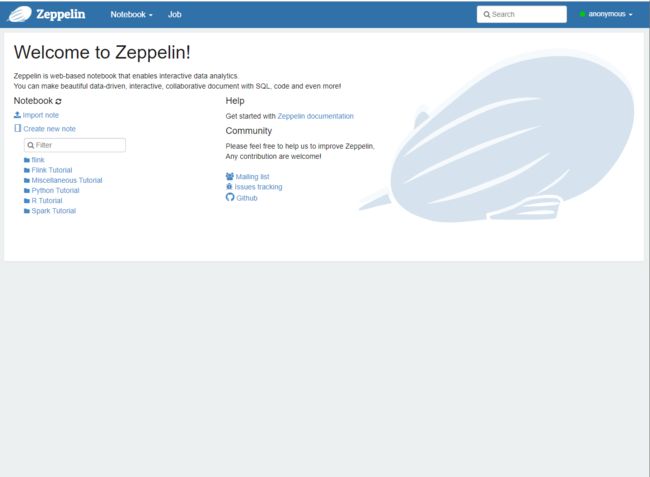
此时浏览器输入zeppelin服务器ip:8008或者hostname:8008即可进入如下页面:
基本使用
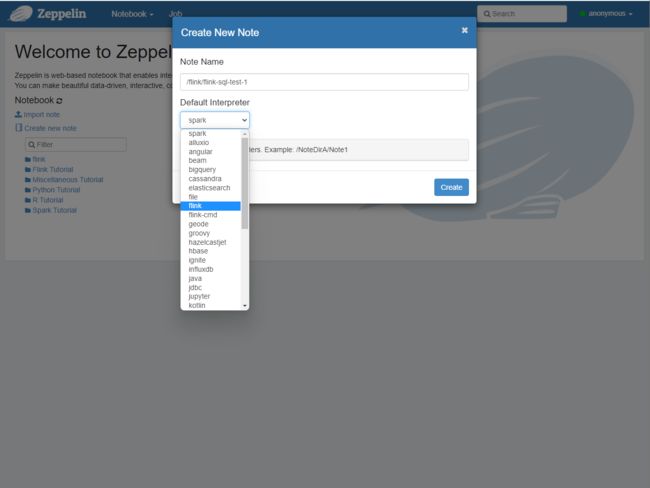
点击Notebook,点击Create new note,填写文本名称以及选定flink interpreter,如下所示:
新建完之后进入如下页面:
根据前面说到的,我们已经通过文章
使用FLINK SQL从savepoint恢复hudi作业(flink 1.13)
所述将数据导入hudi,那么此时我们就可以进行查询:
我们选择
%flink.ssql
首先定义hudi表:
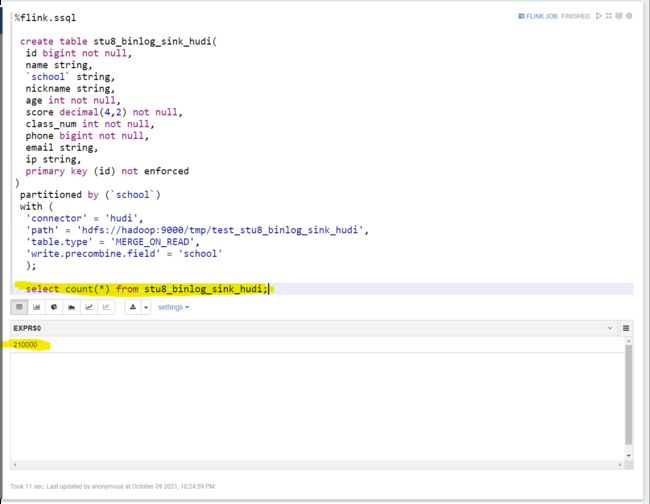
create table stu8_binlog_sink_hudi(
id bigint not null,
name string,
`school` string,
nickname string,
age int not null,
score decimal(4,2) not null,
class_num int not null,
phone bigint not null,
email string,
ip string,
primary key (id) not enforced
)
partitioned by (`school`)
with (
'connector' = 'hudi',
'path' = 'hdfs://hadoop:9000/tmp/test_stu8_binlog_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.precombine.field' = 'school'
);
对hudi表进行统计:
select * from stu8_binlog_sink_hudi;
得到如下结果:
接着进行order by查询
select * from stu8_binlog_sink_hudi order by age desc limit 100;

总结
本文基于给定hudi数据,使用zeppelin结合flink引擎对其进行查询统计。但是呢,我们之前在Flink SQL Client里面能做的其实,在zeppelin里面都能做,我们完全可以用其替换之前文章所述的Flink SQL Client。
了解更多
本文关于hudi的实践是hudi专题中的一个例子,更多内容请参考如下:
https://lrting.top/special/hudi/