Scikit-learn-04.决策树算法
本系列文章介绍人工智能的基础概念和常用公式。由于协及内容所需的数学知识要求,建议初二以上同学学习。 运行本系统程序,请在电脑安装好Python、matplotlib和scikit-learn库。相关安装方法可自行在百度查找。
这节我们来说机器学习中常用的一个功能-决策树。决策树是分类器中的一种,属于有监督学习方法。简单来说,分类器就是根据样本的特征或属性,划分到已有的类别中。也就是说,这些类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类。因此他需要大量的历史数据。数据越多,运算结果就越接近正确值。
决策树是一个类似于流程图的树结构,分支节点表示对一个特征进行测试,根据测试结果进行分类,树叶节点代表一个类别。
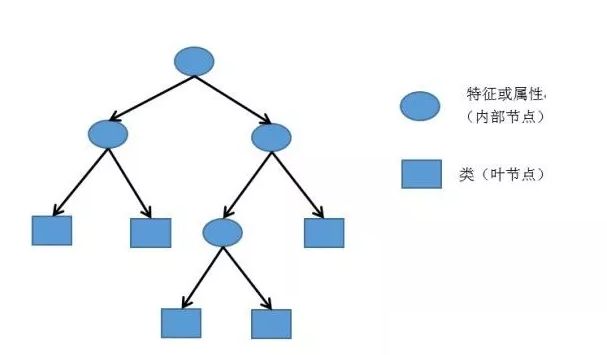
示例说明
下面我们以考试成绩来进行一个分类例子。某班学生语、数、英三科考试成绩。每科都在80分以上的就算优秀。优秀用1表示。假设我并不知道优秀的标准计算方式,只有一堆学生成绩和评定结果。我如何根据这些数据推算出新学生的成绩评定呢?
示例程序
from sklearn import tree
#语数英三科成绩
data_set = [[80,90,70],[60,90,87],[98,85,97],[40,70,50],[89,90,87],[67,85,74],[87,82,80],[100,76,79]]
#三科成绩对应是澡优秀,1为优秀
labels = [0,0,1,0,1,0,1,0]
#生成决策树分类器
clf = tree.DecisionTreeClassifier()
#分类器训练数据
clf = clf.fit(data_set,labels)
#分类器预测新成绩数据
print(clf.predict([[80,45,76],[90,97,84]]))运行结果
[0,1]
#第一个成绩是0,第二个成绩是1,优秀。这里要注意一点,输入的样本数据一定要多。这样才能保证预测值的准确度。