并查集,扩展域并查集,带边权并查集详解,OJ练习,详细代码
文章目录
-
- 零、前言
- 一、并查集的概念与原理
-
- 1.1并查集的概念
- 1.2归属关系的表示方法
-
- 1.2.1直接表示法
- 1.2.1树形表示法
- 1.3查询与合并
-
- 1.3.1查询
- 1.3.1合并
- 1.4路径压缩与按秩合并
-
- 1.4.1路径压缩
- 1.4.2按秩合并
- 1.5、两种优化方式的考虑
- 二、并查集的实现
-
- 2.1并查集的存储
- 2.2并查集的初始化
- 2.3并查集的findp操作
- 2.4并查集的Union操作
- 2.5OJ练习
-
- 2.5.1P3367 【模板】并查集
- 2.5.2 P1955 [NOI2015] 程序自动分析
- 2.5.3POJ1456Supermarket
- 三、“扩展域”与“边带权”的并查集
-
- 3.1“边带权”的并查集
-
- 3.1.1P1196 [NOI2002] 银河英雄传说
- 3.1.2P5937 [CEOI1999] Parity Game
- 3.1.3 ACWING240. 食物链
- 3.2“扩展域”的并查集
-
- 3.2.1CEOI1999\] Parity Game
- 3.2.2 ACWING240. 食物链
零、前言
并查集早期文章数据结构–并查集【C++实现】码风偏工程向,今天写一篇偏竞赛向的。
一、并查集的概念与原理
1.1并查集的概念
并查集(Disjoint-Set)是一种可以动态维护若千个不重叠的集合,并支持合并与查询的数据结构。详细地说,并查集包括如下两个基本操作:
- findp(x):查询一个元素x属于哪一个集合。
- Union(x, y):把两个元素x, y所在集合合并成一个大集合。为了具体实现并查集这种数据结构,我们首先需要定义集合的表示方法。在并查集中,我们采用**“代表元”法**,即为每个集合选择一个固定的元素, 作为整个集合的“代表”。
1.2归属关系的表示方法
1.2.1直接表示法
一种朴素的实现方式是维护一个数组p,p[x]表示x所在的集合的”代表“,这种方式我们查询效率是O(1)的,但是如果涉及到合并,我们需要进行大量遍历,效率极其低下。
1.2.1树形表示法
普遍实现方式为使用一棵树形结构存储每个集合,树上的每个节点都是一个元素,树根是集合的代表元素。这样并查集的数据结构实际上是一个森林,由于我们只在乎集合的归属关系,所以仍然可以维护一个数组p来记录这个森林,p[x]来存储节点x的父节点。特别的,对每棵树(即每个集合)树根节点root,有p[root] = root,这样一来,合并两个集合的时候,只需将一个树根连接到另一个树根即可(p[root2] = root1)。
1.3查询与合并
1.3.1查询
对于查询元素x,要查询其所在集合,即查询其所在树的根节点,我们沿着x的祖先不断向上递归查询即可。
1.3.1合并
对于元素x,y,要合并其所在集合,自然要分别找到其所在树的树根,即px,py,令p[py] = p[px]即可
1.4路径压缩与按秩合并
前面1.3.1直接表示法显著特点为查询效率极高,我们尝试将两种思路进行结合:
我们只关心每个集合对应的“树形结构”的根节点是谁,并不关心其具体形态,故下面两棵树是等价的:
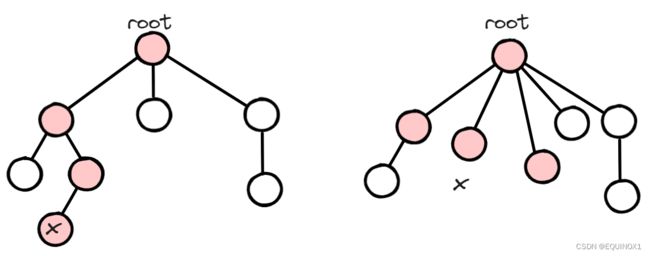
这就有了一种优化策略——路径压缩。
1.4.1路径压缩
朴素查询是从x一路向上找祖先,找到祖先后,要将祖先回溯向下传递,我们传递的时候不妨将路径上的节点全都指向祖先。这样再次查询该路径上节点的祖先时,便只需向上查询一次即可。这样查询的均摊时间复杂度为O(logn)

1.4.2按秩合并
“秩”一般有两种定义,有的资料定义树的深度”秩“,有的资料定义集合大小为“秩”。无论哪种定义,我们都可以将秩记录在树根上,合并时将秩小的树根合并到秩大的树根,这种合并方式我们称为按秩合并,也称为**“启发式合并”**。
“按秩合并”的并查集查询的均摊时间复杂度也为O(logn)。
1.5、两种优化方式的考虑
两种优化方式只使用任意一种的并查集,查询的均摊时间复杂度均为O(logn),如果同时使用两种优化方式,那么查询的均摊时间复杂度可以进一步降到O(α(N)),α(N)为反阿克曼函数,它是一个比“对数函数”logn增长还慢的函数,任意N <= 2(1019729),都有α(N) < 5,故α(N)可以近似看成一个常数,R.E.Tarjan于1975年给出了证明,有兴趣可以查询相关文献。
在实际练习中,不同的题目我们可能要对并查集进行一些扩展或者修改,两种优化方式的选择也有不同,根据实际情况再考虑。
二、并查集的实现
这里的并查集为同时使用了按秩合并和路径压缩优化的版本。
2.1并查集的存储
对于p[x]:
- x为根,则p[x] = -|x所在集合大小|
- x不为根,p[x]为某个祖先节点
const int N = 1e4 + 10;
int p[N];
2.2并查集的初始化
初始时,所有元素都各自为一棵树,即p[x] = -1
int main()
{
memset(p, -1, sizeof(p));
}
2.3并查集的findp操作
如果p[x] < 0,说明是树根,直接返回
否则向上查询,回溯更新
int findp(int x)
{
return p[x] < 0 ? x : p[x] = findp(p[x]);
}
2.4并查集的Union操作
对于待合并两个集合中的点x,y,其根节点分别为px,py
- 如果p[px] > p[py],说明p[py]的秩大,我们交换px,py,这样py就是秩小的集合的树根
- p[px] += p[py], p[py] = px,这样py所在集合就合并到了px所在集合内
bool Union(int x, int y)
{
int px = findp(x), py = findp(y);
if (px == py)
return false;
if (p[px] > p[py])
swap(px, py);
p[px] += p[py], p[py] = px;
return true;
}
2.5OJ练习
2.5.1P3367 【模板】并查集
P3367 【模板】并查集 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
板子题没什么说的。
#include
#include
#include
#include
using namespace std;
const int N = 1e4 + 10, M = 2e5 + 10;
int p[N], n, m, a, b, k;
int findp(int x)
{
return p[x] < 0 ? x : p[x] = findp(p[x]);
}
bool Union(int x, int y)
{
int px = findp(x), py = findp(y);
if (px == py)
return false;
if (p[px] > p[py])
swap(px, py);
p[px] += p[py], p[py] = px;
return true;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
memset(p, -1, sizeof(p));
cin >> n >> m;
while (m--)
{
cin >> k >> a >> b;
if (k == 1)
Union(a, b);
else
cout << (findp(a) == findp(b) ? "Y" : "N") << '\n';
}
return 0;
}
2.5.2 P1955 [NOI2015] 程序自动分析
[P1955 NOI2015] 程序自动分析 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
先把相等的数字都放到一个集合里面
然后去检查那些不相等的数字是否在一个集合内,如果在一个集合内就矛盾。
由于数字太大,所以要进行离散化。
时间复杂度O(nlogn)
思路很简单,适合作为并查集练手题目。
#include
#include
#include
#include
using namespace std;
const int N = 1e6 + 10;
using PII = pair;
int p[N], id[N << 1], n, a, b, k, t, i0, i1, idx;
PII query0[N], query1[N];
int findp(int x)
{
return p[x] < 0 ? x : p[x] = findp(p[x]);
}
bool Union(int x, int y)
{
int px = findp(x), py = findp(y);
if (px == py)
return false;
if (p[px] > p[py])
swap(px, py);
p[px] += p[py], p[py] = px;
return true;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
cin >> t;
while (t--)
{
cin >> n, memset(p, -1, sizeof(p)), i0 = i1 = idx = 0;
bool flag = false;
while (n--)
{
cin >> a >> b >> k;
if (k)
query1[i1++] = {a, b};
else
query0[i0++] = {a, b};
id[idx++] = a, id[idx++] = b;
}
sort(id, id + idx);
idx = unique(id, id + idx) - id;
for (int i = 0; i < i1; i++)
{
int x = lower_bound(id, id + idx, query1[i].first) - id, y = lower_bound(id, id + idx, query1[i].second) - id;
Union(x, y);
}
for (int i = 0; i < i0; i++)
{
int x = lower_bound(id, id + idx, query0[i].first) - id, y = lower_bound(id, id + idx, query0[i].second) - id;
if (findp(x) == findp(y))
{
flag = true;
break;
}
}
if (flag)
cout << "NO" << '\n';
else
cout << "YES" << '\n';
}
return 0;
}
2.5.3POJ1456Supermarket
这道题要用贪心来做,有两种贪心思路,不过都需要必要的数据结构来辅助。
F1 贪心+并查集
第一种贪心思路,尽可能卖利润高的,并且尽可能卖的晚一些,不影响其它商品的销售。
那么我们将商品按照价格降序排列。建立一个关于天数的并查集,并查集维护的是每一天(包括这一天)往前最晚没有占用的天。
有点拗口,初始时p[x] = x,那么代表第x天可用,那么我们将第x天用了之后,就将p[x] = p[x] - 1,即此时p[x] = x - 1,如果查询第x天往前的最晚没有占用日期,会返回x - 1
而我们贪心的晚卖商品,对于遍历到的每个商品都去查询其截止期往前最晚可以用的天,然后安排在那一天卖即可。
#include
#include
#include
#include
#include
using namespace std;
const int N = 1e4 + 10;
typedef pair PII;
int p[N], n;
PII a[N];
int findp(int x)
{
return p[x] == x ? x : p[x] = findp(p[x]);
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
while (cin >> n)
{
int ans = 0, ma = 0;
for (int i = 0; i < n; i++)
cin >> a[i].first >> a[i].second, ma = max(ma, a[i].second);
for (int i = 1; i <= ma; i++)
p[i] = i;
sort(a, a + n);
for (int i = n - 1; i >= 0; i--)
{
int pd = findp(a[i].second);
if (pd)
ans += a[i].first, p[pd]--;
}
cout << ans << '\n';
}
return 0;
}
F2 贪心+堆
第二种贪心思路为,我们能卖就卖,如果遇到冲突的,能用高价换就用高价换。
什么意思?
我们按照日期排序,那么日期早的商品卖的日期,日期晚的也能卖。我们开一个小根堆pq存储当前计划卖掉的商品,商品数目即为卖的天数。
我们遍历商品,如果截止日期大于当前计划卖的商品数目,即没有冲突,我们就加入堆
否则,我们将堆顶即价格最小的商品和该商品比较,如果该商品比堆顶贵,我们就弹出堆顶,加入这个高价商品。
#include
#include
#include
#include
#include
using namespace std;
const int N = 1e4 + 10;
typedef pair PII;
int n;
PII a[N];
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
while (cin >> n)
{
int ans = 0;
for (int i = 0; i < n; i++)
cin >> a[i].second >> a[i].first;
sort(a, a + n);
priority_queue, greater> pq;
for (int i = 0; i < n; i++)
{
if (a[i].first > pq.size())
pq.push(a[i].second), ans += a[i].second;
else if (a[i].second > pq.top())
ans += a[i].second - pq.top(), pq.pop(), pq.push(a[i].second);
}
cout << ans << '\n';
}
return 0;
}
三、“扩展域”与“边带权”的并查集
3.1“边带权”的并查集
并查集实际上是由若干棵树构成的森林,我们可以在树中的每条边上记录一个权值,即维护一个数组d,用d[x]保存节点x到父节点fa[x]之间的边权。在每次路径压缩后,每个访问过的节点都会直接指向树根,如果我们同时更新这些节点的d值,就可以利用路径压缩过程来统计每个节点到树根之间的路径上的一些信息。这就是所谓**“边带权”的并查集**。
3.1.1P1196 [NOI2002] 银河英雄传说
[P1196 NOI2002] 银河英雄传说 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
对于题中两种操作的模拟,我们可以用并查集轻松实现,不过对于C i j操作要求我们计算i和j之间的战舰数目,我们仅靠朴素的并查集模板是无法解决的,自然要维护额外的信息。
数组d[x]记录x到根节点的距离,即边的数目。
那么对于C i j,如果i、j在同一列,我们就应该输出abs(d[i] - d[j]) - 1
那么只要维护好d[]即可
我们采用路径压缩优化并查集,对于根节点root,d[root]存储的是树内节点数目的负数
对于findp(x),如果p[x] < 0,直接返回x,否则先保存px = p[x],然后路径压缩p[x] = findp(p[x]),d[x] += d[px],这样就完成了d[]的维护
由于题目指定了合并顺序,所以不能同时使用按秩合并
#include
#include
#include
#include
#include
using namespace std;
const int N = 3e4 + 10;
typedef pair PII;
int p[N], d[N]{0}, t, a, b;
char k;
int findp(int x)
{
if (p[x] < 0)
return x;
int px = p[x];
p[x] = findp(p[x]);
d[x] += d[px];
return p[x];
}
void Union(int x, int y)
{
int px = findp(x), py = findp(y);
if (px == py)
return;
d[px] = -p[py], p[py] += p[px], p[px] = py;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
cin >> t, memset(p, -1, sizeof p);
while (t--)
{
cin >> k >> a >> b;
if (k == 'M')
Union(a, b);
else if (findp(a) == findp(b))
cout << abs(d[a] - d[b]) - 1 << '\n';
else
cout << -1 << '\n';
}
return 0;
}
3.1.2P5937 [CEOI1999] Parity Game
[P5937 CEOI1999] Parity Game - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
F1 边带权并查集
不难推出如下结论
对于i……j为奇数=>1……i - 1和1……j奇偶性不同
对于i……j为偶数数=>1……i - 1和1……j奇偶性相同
0……a和0……b相同,0……b和0……c相同=>0……a和0……c相同
0……a和0……b相同,0……b和0……c不同=>0……a和0……c不同
0……a和0……b不同,0……b和0……c不同=>0……a和0……c相同
那么我们可以用并查集存储已经询问过的数字,权数组d[x]存储0……x和0……px奇偶性是否相同,0为相同,1为不同
那么我们可以在查询祖先时回溯更新d
对于给出的序列[a, b],令x=a - 1,如果px == pb并且d[px] ^ d[pb] != str[0] == ‘0’ ? 0 : 1,那么矛盾,直接输出答案
否则我们就进行合并,d[px] = d[x] ^ d[b] ^ str[0] == ‘0’ ? 0 : 1,p[pb] += p[px], p[px] = pb;
F2扩展域并查集
见3.2.1
#include
#include
#include
#include
#include
using namespace std;
const int N = 1e4 + 10;
typedef pair PII;
typedef pair PPI;
int p[N << 1], id[N << 1], n, t, a, b, tot = 0, idx = 0, ans = 0;
bool d[N << 1]{0};
PPI query[N];
char str[5];
int findp(int x)
{
if (p[x] < 0)
return x;
int px = p[x];
p[x] = findp(p[x]);
d[x] ^= d[px];
return p[x];
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
cin >> n, memset(p, -1, sizeof p);
cin >> t;
while (t--)
{
cin >> a >> b >> str;
id[idx++] = a - 1, id[idx++] = b;
query[tot++] = {{a - 1, b}, str[0] == 'o' ? 1 : 0};
}
sort(id, id + idx);
idx = unique(id, id + idx) - id;
for (int i = 0; i < tot; i++)
{
int a = lower_bound(id, id + idx, query[i].first.first) - id, b = lower_bound(id, id + idx, query[i].first.second) - id;
int pa = findp(a), pb = findp(b);
if (pa == pb)
{
if (d[a] ^ d[b] != query[i].second)
{
cout << i;
return 0;
}
}
else
d[pa] = d[a] ^ d[b] ^ query[i].second, p[pb] += p[pa], p[pa] = pb;
}
cout << tot;
return 0;
}
3.1.3 ACWING240. 食物链
240. 食物链 - AcWing题库
F1 边带权并查集
对于动物x,y,它们之间有三种关系:
- x是y的同类
- x是y的天敌,x吃y
- y是x的天敌,y吃x
那么我们维护边权d[x]为x到px的距离,距离%3=0说明是px同类,=1为天敌,2为食物
那么对于x,z,px = pz = y,那么我们可以根据d[x] 和 d[z]来推断其关系
如果给出的是x和z是同类,x和z和y的关系是相同的,即d[x] % 3 = d[y] % 3,=>d[x] - d[y]) % 3 = 0
如果给出的是x吃z,那么d[x] - d[y] - 1 % 3 = 0,这个可以思考一下
则有代码
#include
#include
#include
#include
using namespace std;
const int N = 50005;
int p[N], d[N]{0}, n , k;
int findp(int x){
if(p[x] == x) return x;
int u = findp(p[x]);
d[x] += d[p[x]];
return p[x] = u;
}
int main(){
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> n >> k;
for(int i = 1; i <= n; i++) p[i] = i;
int a, x, y, ans = 0;
while(k--){
cin >> a >> x >> y;
if(x > n || y > n) {ans++;continue;}
int px = findp(x), py = findp(y);
if(a == 1){
if(px == py && (d[x] - d[y]) % 3) ans++;
else if(px != py){
p[px] = py;
d[px] = d[y] - d[x];
}
}
else{
if(px == py && (d[x] - d[y] - 1) % 3) ans++;
else if(px != py){
p[px] = py;
d[px] = d[y] - d[x] + 1;
}
}
}
cout << ans;
return 0;
}
3.2“扩展域”的并查集
边带权并查集是通过记录权值来进行关系的传递,我们也可以通过扩展多个域来进行关系的传递。
3.2.1CEOI1999] Parity Game
[P5937 CEOI1999] Parity Game - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
扩展域的并查集
不同于边带权的解法,我们这样解决关系传递:
我们能够通过已知询问推断出0……a - 1和0……b的奇偶性是否相同,但具体是奇还是偶我们不清楚,那么我们不妨进行扩展,对于a我们扩展为aodd和aeven,分别代表0……a为奇和0……a为偶
那么对于a, b , even(a是已经-1后的值),那么我们合并aeven, beven 和 aodd, bodd
那么对于a, b , odd(a是已经-1后的值),那么我们合并aeven, bodd和 aeven, bodd
这样思考不需要考虑权值间如何传递,比较简单粗暴。
#include
#include
#include
#include
#include
using namespace std;
const int N = 1e4 + 10;
typedef pair PII;
typedef pair PPI;
int p[N << 1], id[N << 1], n, t, a, b, tot = 0, idx = 0, ans = 0;
PPI query[N];
char str[5];
int findp(int x)
{
return p[x] < 0 ? x : p[x] = findp(p[x]);
}
void Union(int x, int y)
{
int px = findp(x), py = findp(y);
if (px == py)
return;
if (p[px] > p[py])
swap(px, py);
p[px] += p[py], p[py] = px;
return;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
cin >> n, memset(p, -1, sizeof p);
cin >> t;
while (t--)
{
cin >> a >> b >> str;
id[idx++] = a - 1, id[idx++] = b;
query[tot++] = {{a - 1, b}, str[0] == 'o' ? 1 : 0};
}
sort(id, id + idx);
idx = unique(id, id + idx) - id;
for (int i = 0; i < tot; i++)
{
int a = lower_bound(id, id + idx, query[i].first.first) - id, b = lower_bound(id, id + idx, query[i].first.second) - id;
int ae = a + idx, be = b + idx;
if (!query[i].second)
{
if (findp(a) == findp(be))
{
cout << i;
return 0;
}
Union(a, b), Union(ae, be);
}
else
{
if (findp(a) == findp(b))
{
cout << i;
return 0;
}
Union(a, be), Union(ae, b);
}
}
cout << tot;
return 0;
}
3.2.2 ACWING240. 食物链
240. 食物链 - AcWing题库
扩展域并查集
对于每个点x可以扩展为x为A,x为B,x为C,分别对应x、x+n、x+2n,我们发现+n会变成食物,那么我们就可以根据给定条件判断矛盾了。
直接看代码:
#include
#include
#include
#include
using namespace std;
const int N = 50005, M = N * 3;
int p[N * 3], n , k;
int findp(int x){
return p[x] == x ? x : p[x] = findp(p[x]);
}
int main(){
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> n >> k;
for(int i = 0; i < M; i++) p[i] = i;
int a, x, y, ans = 0;
while(k--){
cin >> a >> x >> y;
if(x > n || y > n) {ans++;continue;}
if(a == 1){
if(findp(x + n) == findp(y) || findp(x) == findp(y + n)){
ans++;continue;
}
p[findp(x)] = findp(y);
p[findp(x + n)] = findp(y + n);
p[findp(x + 2 * n)] = findp(y + 2 * n);
}
else{
if(findp(x) == findp(y) || findp(x) == findp(y + n)){
ans++;continue;
}
p[findp(x)] = findp(y + n * 2);
p[findp(x + n)] = findp(y);
p[findp(x + 2 * n)] = findp(y + n);
}
}
cout << ans;
return 0;
}