Elasticsearch 通信模块的分析
Elasticsearch 通信模块的分析 - 知乎
Elasticsearch是一个基于Lucene的分布式实时搜索框架,它本身能够接受用户发来的http 请求, 集群节点之间也会有相关的通信。
通信模块的简介
Elasticsearch 中的通信相关的配置都是由NetworkModule 这个类完成的。 NetworkModule 里面的配置主要分三大部分:
- HttpServerTransport: 这个主要负责接受用户发来的请求,然后分发请求
- Transport: 这个主要负责集群间的通信,应该是Elasticsearch 的RPC
- TransportInterceptor 是对连接之间的拦截,在连接发送之前 或是接到之后先做一些相关处理,这个在Elasticseach 使用的并不多,目前只是提供了这功能的接口,可以让之后更容扩展.
由于3在Elasticseach 使用的并不多,我在这里面不多讲,主要讲1 和2
Elasticsearch是一个非常扩展性非常强的系统,每个功能都模块化,服务化。而且它提供了插件(Plugin)的接口,让每一个功能都很容易可以扩展,实现了可插拔。对于网络相关的的插件是NetworkPlugin
NetworkPlugin 提供了三个函数来分别获得和配置HttpServerTransport, Transport, TransportInterceptor.
public interface NetworkPlugin {
/**
* Returns a list of {@link TransportInterceptor} instances that are used to intercept incoming and outgoing
* transport (inter-node) requests. This must not return null
*
* @param namedWriteableRegistry registry of all named writeables registered
* @param threadContext a {@link ThreadContext} of the current nodes or clients {@link ThreadPool} that can be used to set additional
* headers in the interceptors
*/
default List getTransportInterceptors(NamedWriteableRegistry namedWriteableRegistry,
ThreadContext threadContext) {
return Collections.emptyList();
}
/**
* Returns a map of {@link Transport} suppliers.
* See {@link org.elasticsearch.common.network.NetworkModule#TRANSPORT_TYPE_KEY} to configure a specific implementation.
*/
default Map> getTransports(Settings settings, ThreadPool threadPool, BigArrays bigArrays,
PageCacheRecycler pageCacheRecycler,
CircuitBreakerService circuitBreakerService,
NamedWriteableRegistry namedWriteableRegistry,
NetworkService networkService) {
return Collections.emptyMap();
}
/**
* Returns a map of {@link HttpServerTransport} suppliers.
* See {@link org.elasticsearch.common.network.NetworkModule#HTTP_TYPE_SETTING} to configure a specific implementation.
*/
default Map> getHttpTransports(Settings settings, ThreadPool threadPool, BigArrays bigArrays,
CircuitBreakerService circuitBreakerService,
NamedWriteableRegistry namedWriteableRegistry,
NamedXContentRegistry xContentRegistry,
NetworkService networkService,
HttpServerTransport.Dispatcher dispatcher) {
return Collections.emptyMap();
}
}
NetworkModule 会在它的构造函数里面遍历所有的network plugin 然后缓存到内存里面。
public NetworkModule(Settings settings, boolean transportClient, List plugins, ThreadPool threadPool,
BigArrays bigArrays,
PageCacheRecycler pageCacheRecycler,
CircuitBreakerService circuitBreakerService,
NamedWriteableRegistry namedWriteableRegistry,
NamedXContentRegistry xContentRegistry,
NetworkService networkService, HttpServerTransport.Dispatcher dispatcher) {
this.settings = settings;
this.transportClient = transportClient;
for (NetworkPlugin plugin : plugins) {
// HttpServerTransport
if (transportClient == false && HTTP_ENABLED.get(settings)) {
Map> httpTransportFactory = plugin.getHttpTransports(settings, threadPool, bigArrays,
circuitBreakerService, namedWriteableRegistry, xContentRegistry, networkService, dispatcher);
for (Map.Entry> entry : httpTransportFactory.entrySet()) {
registerHttpTransport(entry.getKey(), entry.getValue());
}
}
// Transport
Map> transportFactory = plugin.getTransports(settings, threadPool, bigArrays, pageCacheRecycler,
circuitBreakerService, namedWriteableRegistry, networkService);
for (Map.Entry> entry : transportFactory.entrySet()) {
registerTransport(entry.getKey(), entry.getValue());
}
List transportInterceptors = plugin.getTransportInterceptors(namedWriteableRegistry,
threadPool.getThreadContext());
// TransportInteceptor
for (TransportInterceptor interceptor : transportInterceptors) {
registerTransportInterceptor(interceptor);
}
}
} Netty Network Plugin
Elasticsearch 的底层通信是用了高性能异步io 框架Netty。
Netty 的性能非常优秀,底层使用了kqueue or epoll 来时实现对io 的高复用,然后使用的zero copy buffer 技术来提高了cpu 的效率。
Elasticsearch 是以插件的模式把Netty 的实现插入它本身的系统里面
public class Netty4Plugin extends Plugin implements NetworkPlugin {
static {
Netty4Utils.setup();
}
public static final String NETTY_TRANSPORT_NAME = "netty4";
public static final String NETTY_HTTP_TRANSPORT_NAME = "netty4";
@Override
public Map> getTransports(Settings settings, ThreadPool threadPool, BigArrays bigArrays,
PageCacheRecycler pageCacheRecycler,
CircuitBreakerService circuitBreakerService,
NamedWriteableRegistry namedWriteableRegistry,
NetworkService networkService) {
return Collections.singletonMap(NETTY_TRANSPORT_NAME, () -> new Netty4Transport(settings, threadPool, networkService, bigArrays,
namedWriteableRegistry, circuitBreakerService));
}
@Override
public Map> getHttpTransports(Settings settings, ThreadPool threadPool, BigArrays bigArrays,
CircuitBreakerService circuitBreakerService,
NamedWriteableRegistry namedWriteableRegistry,
NamedXContentRegistry xContentRegistry,
NetworkService networkService,
HttpServerTransport.Dispatcher dispatcher) {
return Collections.singletonMap(NETTY_HTTP_TRANSPORT_NAME,
() -> new Netty4HttpServerTransport(settings, networkService, bigArrays, threadPool, xContentRegistry, dispatcher));
}
} 从上面代码来看。 Netty 主要 ️两个重要的部分组成:
1 Netty4HttpServerTransport。
2 Netty4Transport。
Netty4HttpServerTransport
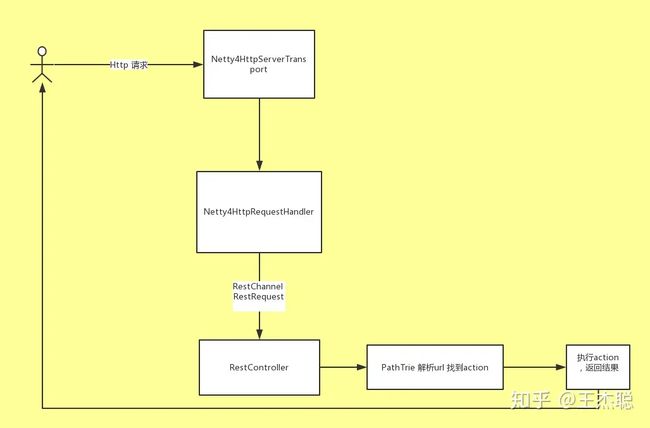
Netty4HttpServerTransport 内部流程图
Netty4HttpServerTransport 是插件里面对HttpServerTransport 的实现,它继承了AbstractLifecycleComponent 实现了HttpServerTransport 的接口,这样Netty4HttpServerTransport 就拥有了和整个系统一样的一样的生命周期。它会在系统启动的时候被启动, 在系统结束的时候被关闭。
public class Netty4HttpServerTransport extends AbstractLifecycleComponent implements HttpServerTransport {
@Override
protected void doStart() {
boolean success = false;
try {
this.serverOpenChannels = new Netty4OpenChannelsHandler(logger);
serverBootstrap = new ServerBootstrap();
serverBootstrap.group(new NioEventLoopGroup(workerCount, daemonThreadFactory(settings,
HTTP_SERVER_WORKER_THREAD_NAME_PREFIX)));
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.childHandler(configureServerChannelHandler());
....
this.boundAddress = createBoundHttpAddress();
if (logger.isInfoEnabled()) {
logger.info("{}", boundAddress);
}
success = true;
} finally {
if (success == false) {
doStop(); // otherwise we leak threads since we never moved to started
}
}
}
}
public ChannelHandler configureServerChannelHandler() {
return new HttpChannelHandler(this, detailedErrorsEnabled, threadPool.getThreadContext());
}
protected static class HttpChannelHandler extends ChannelInitializer {
private final Netty4HttpServerTransport transport;
private final Netty4HttpRequestHandler requestHandler;
protected HttpChannelHandler(
final Netty4HttpServerTransport transport,
final boolean detailedErrorsEnabled,
final ThreadContext threadContext) {
this.transport = transport;
this.requestHandler = new Netty4HttpRequestHandler(transport, detailedErrorsEnabled, threadContext);
}
@Override
protected void initChannel(Channel ch) throws Exception {
.....
final HttpRequestDecoder decoder = new HttpRequestDecoder(
Math.toIntExact(transport.maxInitialLineLength.getBytes()),
Math.toIntExact(transport.maxHeaderSize.getBytes()),
Math.toIntExact(transport.maxChunkSize.getBytes()));
decoder.setCumulator(ByteToMessageDecoder.COMPOSITE_CUMULATOR);
ch.pipeline().addLast("decoder", decoder);
ch.pipeline().addLast("decoder_compress", new HttpContentDecompressor());
ch.pipeline().addLast("encoder", new HttpResponseEncoder());
....
ch.pipeline().addLast("handler", requestHandler);
}
}
Netty4HttpServerTransport 会在自己启动的时候的中创建一个Netty服务器然后去监听9200端口。 服务器收到请求后会去回调HttpChannelHandler这个回调函数。 HttpChannelHandler主要做的对接收到的请求进行解码然后分发给不同的模块去执行。因为Netty的通信层面是在TCP/IP 层面而不是Http 层面,所以对于接受来的请求,必须要先解析成Http请求然后再交给个Netty4HttpRequestHandler 去处理。Netty4HttpRequestHandler 本身做的是对Netty 的请求再一次包装,把它包装成Elasticseach 自己定义的RestRequest 还有RestChannel然后用Dispatcher 去进行分发解析好的请求。
对Netty Http 请求的再包装的作用主要是实现对Netty 解耦,如果以后有新的更好的通信架构,对通信模块的重构会更加容易
Dispatcher(RestController.java)
RestController 属于ActionModule 里面的功能, ActionModule 主要的任务就是注册各种操作(action) 需要执行的函数,建立起action 的名字和 函数的对应关系。
actions.register(SearchAction.INSTANCE, TransportSearchAction.class);
例如搜索这个的action,它回去调用TransportSearchAction 去做搜索的操作。
RestController(Dispatcher) 主要的任务是根据Netty4HttpRequestHandler 转过来的请求的url进行解析,然后寻求相对应的action 然后执行。
RestController 对与path 的解析的时候也做了一些优化, 它使用了trie (字典树) 这个数据结构来提升性能查找的性能
例如:
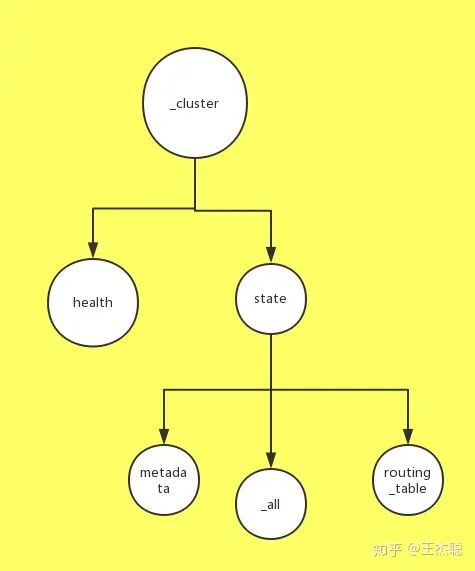
GET /_cluster/state/metadata这个uri 对应的action 函数。在内存里面存储的情况应该是类似这样的
public class TrieNode {
private transient String key;
private transient T value; (回调函数)
private boolean isWildcard;
private final String wildcard;
private transient String namedWildcard;
private Map children;
public TrieNode(String key, T value, String wildcard) {
this.key = key;
this.wildcard = wildcard;
this.isWildcard = (key.equals(wildcard));
this.value = value;
this.children = emptyMap();
if (isNamedWildcard(key)) {
namedWildcard = key.substring(key.indexOf('{') + 1, key.indexOf('}'));
} else {
namedWildcard = null;
}
}
} 每一个节点都是一个key 和一个value (回调函数) ,还有一个hashmap 来保存他的子节点, wildcard 是用来判断这个key 是不是{*} , 也就是这段路径可能是任意值。
PathTrie 会先对请求的url 对‘/’符号进行分割,然后一层一层的找下去,直到找到相匹配的函数。 PathTrie的优势在众多注册的url 的中以最快的速度找到相匹配的函数。
GET /_cluster/state/metadata这个url 的查找的次数是[_cluster, state, metadata].size() 也就是3次。 其实有很多优秀的url router 都是利用字典树实现的,例如这个go 的high performnace router
julienschmidt/httproutergithub.com/julienschmidt/httprouter
Netty4Transport:

Netty4Transport 相当于Elasticsearch 的RPC (remote procedure call)。 它在Elasticsearch启动的时候也去会启动一个的Netty Server 然后去监听另外一个9300端口来处理其他Node 发来的请求。 同时自己也会初始化一个Netty Client 来给别的Node发请求。
创建一个新的Netty Server 的好处是可以实现与HttpServerTransport的解耦,把RPC 接受的逻辑和HttpServerTransport分开, 同时也可以对RPC 信息的序列化可以进一步优化。对于RPC信息序列化, Elasticsearch 并没有用Http 还有Json,而是自己设定一套规则。所有的发送和接受都是在TCP/IP 层面,这样减少了Http 层面的解析 , 对于发送的消息也进一步的压缩来提高传输效率。
@Override
protected void doStart() {
boolean success = false;
try {
// 启动client 端
bootstrap = createBootstrap();
if (NetworkService.NETWORK_SERVER.get(settings)) {
for (ProfileSettings profileSettings : profileSettings) {
createServerBootstrap(profileSettings);
bindServer(profileSettings);
// server 端
}
}
super.doStart();
success = true;
} finally {
if (success == false) {
doStop();
}
}
}Netty4Transport 在Client 和Server 中共同使用了这个Netty4MessageChannelHandler 回调函数。Client 在发送请求给远方的Node 的时候会把在信息的header里面标注为request 这个状态,所以这个回调函数判断到底是远方Node 发来的请求还是返回执行的结果是就是根据这个 TransportStatus.isRequest(status) 状态
if (TransportStatus.isRequest(status)) {
handleRequest(channel, profileName, streamIn, requestId, messageLengthBytes, version, remoteAddress, status);
} else {
final TransportResponseHandler handler;
if (isHandshake) {
handler = pendingHandshakes.remove(requestId);
} else {
TransportResponseHandler theHandler = transportService.onResponseReceived(requestId);
if (theHandler == null && TransportStatus.isError(status)) {
handler = pendingHandshakes.remove(requestId);
} else {
handler = theHandler;
}
}Transport 有两种定义好的回调函数, 一个是TransportRequestHandler, 一个是TransportResponseHandler。
public interface TransportRequestHandler {
/**
* Override this method if access to the Task parameter is needed
*/
default void messageReceived(final T request, final TransportChannel channel, Task task) throws Exception {
messageReceived(request, channel);
}
void messageReceived(T request, TransportChannel channel) throws Exception;
}
public interface TransportResponseHandler extends Writeable.Reader {
/**
* @deprecated Implement {@link #read(StreamInput)} instead.
*/
@Deprecated
default T newInstance() {
throw new UnsupportedOperationException();
}
/**
* deserializes a new instance of the return type from the stream.
* called by the infra when de-serializing the response.
*
* @return the deserialized response.
*/
@SuppressWarnings("deprecation")
@Override
default T read(StreamInput in) throws IOException {
T instance = newInstance();
instance.readFrom(in);
return instance;
}
void handleResponse(T response);
void handleException(TransportException exp);
String executor();
} TransportRequestHandler 是处理远方节点发来请求的回调函数,它会根据发来请求做出对应的操作
TransportResponseHandler 就是发给远方节点执行后返回的结果的回调函数,主要功能是整合这些返回信息,返回给用户或是再分发到其他节点上。
下面我举个例子,来讲述get 一个文档的整个流程。
例如用户想直接get 一个ID 是123 博客。 他发了一个这样的请求 GET /website/blog/123 给ElasticSearch 节点1

请求在节点1 (node1)接收到之后,这个请求会被HttpServerTransport 处理,HttpServerTransport 里面的回调函数 HttpChannelHandler 会通过PathTrie解析到这个请求对应的action应该是TransportGetAction 。
这个action 是专门执行取 一个文档的操作,这个action 会先在clusterstate 里面找到/website/blog/123 的index shard 是在哪个节点里面。 如果它发现shard 是在本地, 它会异步的方式去lucence 里面读取这个文档,然后返回结果。 如果它发现shard 不在本地而在远方的节点2(node2), 它会用Transport 发到节点2 (node2)的9300,然后node2 9300 接收到这个请求之后调用用注册的ShardTransportHandler 这个回调函数会去本地lucence 里面搜索结果,然后把结果返回给node1。 node1 会把得到的结果序列化成json 返回给用户。
通过Elasticseach 来看对netty 的用法
Elasticsearch 利用Netty 的思路还是相当棒的,由于Netty 是单线程Event loop 的模式,所以Elasticsearch 在对回调函数上面尽可能用线程池来异步处理。但是它又不会盲目都去使用格外线程执行这这些回调函数。例如对于读取clusterstate 这种存内存操作,它都是用当时线程来执行,这样减少对线程池的压力和格外资源的开销,还会使得代码复杂性降低。而且它也还会根据不同的操作来分配大小不同的线程池例如 search 的线程池里面的线程数量非常多,而且可以自动扩展。Elasticsearch对线程使用的控制也是属于fine-grained。不会傻瓜的使用一个线程走到底,而是尽可能分步骤执行。