爬取boss直聘“数据分析”工作
爬取boss直聘数据分析【1、获取数据】
1、背景:面临工作,需要数据支持,看到各大数据源(天池、和鲸社区…),萌生一种自己爬取数据分析工作的信息,将数分融入进找工作的环节中,利用数据分析来分析当前数据分析就业环境,就业前景,以及提高找工作的效率。
2、使用工具:python3.10,sublimeText3
3、工作任务:
A:获取数据
B:保存数据
C:清理数据集
4、开始任务:
4.1 安装python3,sublimeText3环境,安装所需pip插件和类库
4.2 新建boss.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'Zym'
import requests
import bs4
4.3 打开boss找到网络network部分,相应头请求头,复制headers
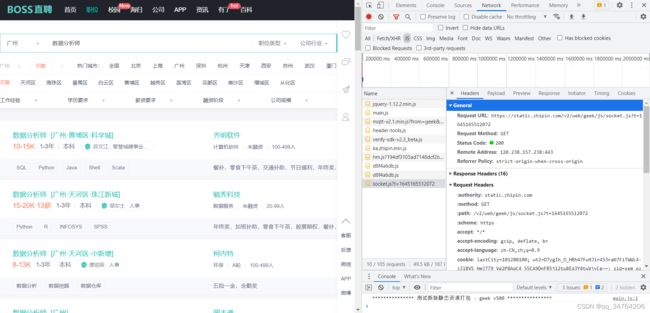
4.4 为什么设置headers,原因在于我早上11点用powerBI爬取时,次数频繁被boss直接屏蔽了,无法继续爬取,所以转用代码实现爬取此内容,设置headers反boss反爬取
4.5 修改代码后如下:
#反boss反爬取
headers = {
'authority': 'static.zhipin.com',
'method':'GET',
'path': '/v2/web/geek/js/socket.js?t=1645165512072',
'scheme': 'https',
'accept':'*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'lastCity=101280100; wt2=D7ygIh_O_HBh47Fw9Jir453raN7FiTWWL4-z3lBVS_HmJ779_Vg2P8AqC4_55CA9DnFB5j12tw8Ed3Y4twVjvCg~~; sid=sem_pz_bdpc_dasou_title; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1644806812,1644895841,1645156038; __zp_seo_uuid__=d4d69471-932d-43aa-b2a6-7e1431585b25; __g=sem_pz_bdpc_dasou_title; __l=r=https%3A%2F%2Fwww.zhipin.com%2Fweb%2Fcommon%2Fsecurity-check.html%3Fseed%3DDdotkXgSF0cbZF%252FKCCn%252B4lbWrfZK%252B7xsqLc6hMfKssY%253D%26name%3Dd8f4a6db%26ts%3D1645156037510%26callbackUrl%3Dhttps%253A%252F%252Fwww.zhipin.com%252Fguangzhou%252F%253Fsid%253Dsem_pz_bdpc_dasou_title&l=%2Fwww.zhipin.com%2Fc101280100%2F%3Fquery%3D%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%26page%3D7%26ka%3Dpage-7&s=3&friend_source=0&s=3&friend_source=0; __c=1645156037; __a=77042217.1640531733.1644895841.1645156037.146.6.71.71; __zp_stoken__=47a0dWyJWFXdfTxAPdTtuRFsYF04nUx8QAUcpGmE3Jm4uGW9CLXx%2FPlJAdhJhNXYqHkwJSEJdfn4JXQQmPwByECRJMmtcYABdMRdXaQtlB1RKKxN%2FJTBxCCM2HhYqKlw%2FXHU7PEd9fANBR3Q%3D; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1645165512',
'referer': 'https://www.zhipin.com/',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': "Windows",
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
4.6 设置url
#抓取页码内容,返回响应对象
# response = requests.get(url)
url = "https://www.zhipin.com/c101280100/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&page=8&ka=page-8";
response = requests.get(url,headers=headers)
4.7 查看相应码,能够看出网页是否正常连接
#查看响应状态码
status_code = response.status_code
4.8 用bs4完成代码抓取
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(class_="job-primary")
print(status_code)
print(element)
4.9 效果图展示:

5 设计数据库:
5.1 字段设计:
| 字段 | 字段名 |
|---|---|
| 工作名 | jobName |
| 公司 | company |
| 公司类型 | companyType |
| 公司规模 | companySize |
| 公司人口 | companyPopulation |
| 公司福利 | info_append |
| 薪资 | salary |
| 地点 | place |
| 工作时间 | jjobTime |
| 技能标签 | tag |
5.2 数据库创建:
mysql> create table company(
-> id int not null primary key auto_increment,
-> jobName varchar(255),
-> company varchar(255),
-> companyType varchar(255),
-> companySize varchar(255),
-> companyPopulation varchar(255),
-> info_append varchar(255),
-> salary decimal(65,2),
-> place varchar(255),
-> jobTime varchar(255),
-> tag varchar(255));
Query OK, 0 rows affected (0.06 sec)
本来金额想设置成decimal,但是他是个价格区间,非正常金额,所以改回来varchar即可
alter table company modify salary varchar(255);
5.3 重新回头看看python的爬取,用bs4来实现爬取
#职位名称
job_title = content.find_all('span',class_="job-name")
for item in job_title:
name=item.find('a')
print(name.text.strip())
#薪资
salary = content.find_all('span',class_="red")
for item in salary:
print(item.text.strip())
#岗位要求 年份+本专科
job_limit = content.find_all('div',class_="job-limit clearfix")
for item in job_limit:
name=item.find('p')
print(name.text.strip())
#招聘人
info_publis = content.find_all('div',class_="info-publis")
for item in info_publis:
name=item.find('h3')
print(name.text.strip())
#地区信息
job_area = content.find_all('span',class_="job-area")
for item in job_area:
print(item.text.strip())
#公司详情
company_text = content.find_all('div',class_="company-text")
#公司名
for item in company_text:
name=item.find('h3')
print(name.text.strip())
# 领域
for item in company_text:
name=item.find('p').find('a')
print(name.text.strip())
#融资
for item in company_text:
name=item.find('p')
name=name.next_element.next_element.next_element.next_element
print(name)
# print(name.text.strip())
#人数
for item in company_text:
name=item.find('p')
name=name.next_element.next_element.next_element.next_element.next_element.next_element
print(name)
#福利info-desc
info_desc = content.find_all('div',class_="info-desc")
for item in info_desc:
print(item.text.strip())
#专业技能tags
tags = content.find_all('div',class_="tags")
for item in tags:
#print(tags) #此处记住要断点
name=item.find('span')
print(item.text.strip())
利用bs4来实现爬取,这还没有做完,但是我先去吃饭了,太晚了
此处效果图展示
