<<浏览器工作原理与实践>>读书笔记
1. 进程和线程的区别
概念:
进程:操作系统进行资源分配和调度的基本单位;程序的运行实例;(在我们启动一个程序的时候,操作系统会为该程序创建一块内存空间,用来存放代码,运行数据,和执行任务的主线程,这样的运行环境称为进程)
线程:是程序执行的最小单位;不能单独存在,由进行启动和管理;
区别: 1)进程中任务线程执行出错,都会导致整个进程崩溃;
2)线程共享进程中的数据;
3)当一个进程关闭后,操作系统会回收该进程占用的内存空间;
4)进程间内容相互隔离;
5)一个进程可由一个或多个线程构成,线程是进程中代码不同的代码执行路线;
浏览器进化史:
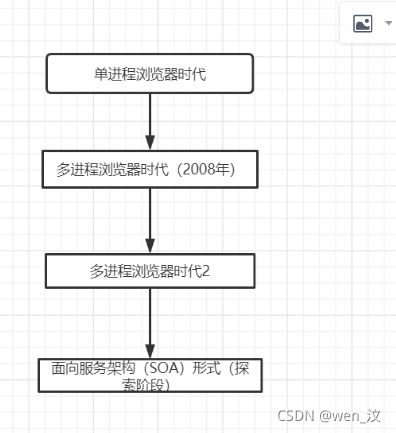
a. 单进程浏览器时代:所有功能允许在同一个进程中,一个进程卡顿,其他进程就得处于等待状态没有执行的机会;一个进程崩溃会引起整个浏览器崩溃;(不流畅,不稳定,不安全)
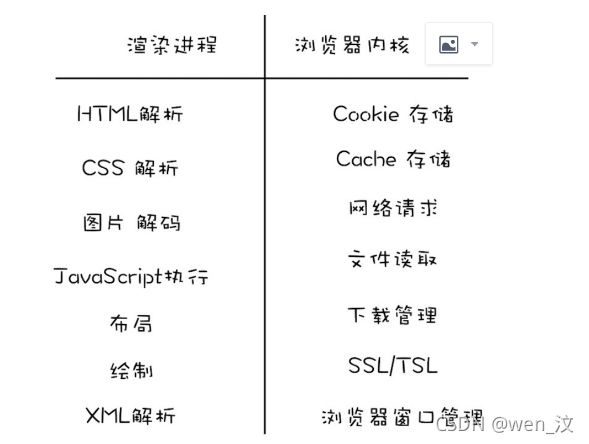
b. 多进程浏览器时代(2008年):由插件进程,渲染进程,浏览器主进程组成
c. 多进程浏览器时代(现今使用):一个网络进程,一个GPU进程;一个浏览器主进程;多个渲染进程;多个插件进程;缺点:进程数变多,则占用的内存资源更多;体系架构更复杂;
浏览器进程: 负责界⾯显⽰、⽤⼾交互、⼦进程管理,同时提供存储等功能。
渲染进程:将 HTML、CSS 和 JavaScript 转换为⽤⼾可以与之交互的⽹⻚,排版引擎Blink和 JavaScript引擎V8都是运⾏在该进程中,渲染进程都是运⾏在沙箱模式下。
GPU进程:起初GPU的使⽤初衷是为了实现3D CSS的 效果,只是随后⽹⻚、Chrome的UI界⾯都选择采⽤GPU来绘制,这使得GPU成为浏览器普遍的需求。最 后,Chrome在其多进程架构上也引⼊了GPU进程。
⽹络进程:负责⻚⾯的⽹络资源加载;
插件进程:负责插件的运⾏,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃 不会对浏览器和⻚⾯造成影响。
2. 如何保证页面文件能被完整的送到浏览器;
IP协议(网络层):通过IP地址将数据包传输到对方电脑;
UDP / TCP协议(传输层): 通过端口号将收到的数据包交给电脑上对应的程序处理;因为每个程序访问网络时都需要先绑定一个端口号;
UDP协议:无连接的,不可靠的传输层协议;
- 1)不能确认数据包是否到达了 目的地;(不可靠)
- 2)传输过程中,如果数据包丢失,不能触发重传机制;
- 3)对于将大文件拆为小文件传输时,在接收端不能将小文件组装还原成原来的完整文件;
- 4)传输速度较快;(无连接)
TCP协议:面向连接的,可靠的,基于字节流的安全传输协议;
1) 对于传输过程中丢失的数据包,支持重传机制;(安全可靠)
怎样判断是否触发重传:
- a. 发送端发送了 一个data数据包到接收端;接收端在接收到data数据包后,会发送一个ack确认包到发送端;
- b. 发送端在一定时间内,如果没有收到接收端发送的ack确认数据包,则判定为发送的data数据包丢失了,需要重传;
2)三次握手建立连接------------>>>传输数据------------>>四次挥手断开连接;
3)传输速度相比UDP会比较慢;
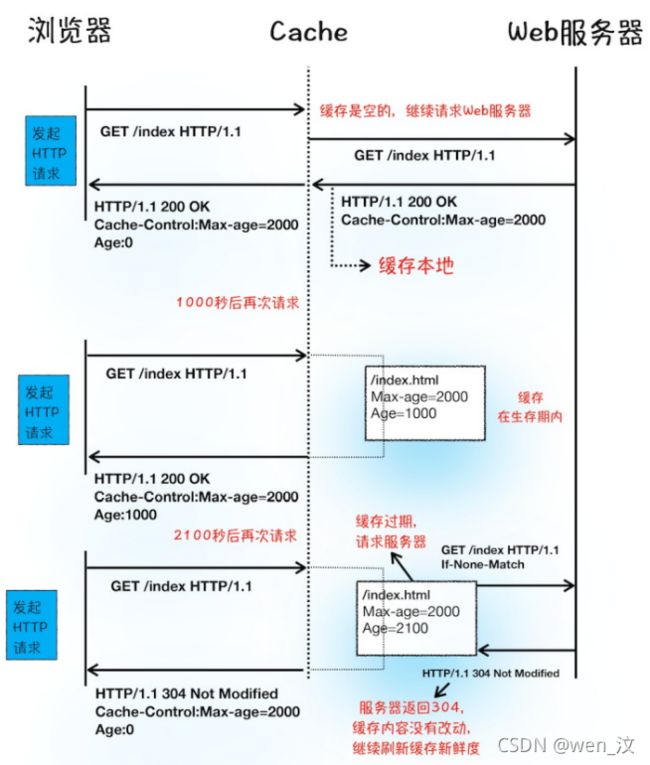
3. 为什么很多站点第二次打开速度会很快?
因为第一次加载页面的过程中,会缓存很多耗时的数据(DNS缓存,页面资源缓存)
4. 用户从输入URL到页面展示的过程?
1. )用户输入: 判断用户输入的内容是搜索关键字,还是请求URL;
如果是搜索关键字,则用默认搜索引擎合成带有搜索关键字的URL;
如果是URL,则地址栏会根据规则拼接上协议合成完整的URL;
2.) URL请求过程
2.1 网络进程会查找本地缓存中是否有该次请求的资源,如果有则直接返回给浏览器进程;如果没有,则进入网络请求流程;
2.2 网络请求的过程?
2.2.1: 进行DNS域名解析;以获取请求域名的服务器IP地址;
2.2.2: 获取端口号,用于目标服务器中哪个应用程序进行数据包的接收;一般URL中没有明确指定端口号的话,http协议默认是80端口;https默认为443端口;
默认chrome浏览器中,同一个域名同时最多只能建立6个TCP连接;超出的请求会进入排队等待状态;
2.2.3 浏览器和服务端建立TCP 连接;(三次握手)
2.2.4 发送HTTP请求: (请求行(请求方法+请求url+请求版本) + 请求头 + 请求体)
2.3 服务器处理http请求的流程?
2.3.1 返回请求(响应行(http协议版本 + 响应状态码 ) + 响应头 + 响应体)
2.3.2 重定向,如果响应状态码为 301,302,则浏览器会根据响应头中的location字段值重定向到其他的url;然后再发起新的请求,一切从头开始;
如果响应状态码为200,则表示浏览器可继续处理该请求;
2.3.3 响应数据类型处理:根据响应头中的Content-Type字段,判断本次返回的数据类型;
如果为application/octet-stream,则表示数据为字节流类型,交给浏览器的下载管理器,则该URL的导航流程就结束了;
如果为html资源,则浏览器导航流程会继续;
2.3.4 断开连接,(四次挥手)
*但是如果响应头含有Connection: keep-alive;则该TCP连接在响应内容发送后仍保持打开状态,下一次请求可复用;
3. )准备渲染进程;
一般情况下,打开的新页面都会使用单独的渲染进程;但是如果新页面和原来的页面属于同一站点(同一根域名 && 同一协议),则新页面会复用原来的渲染进程;
注意:此时网络请求得到的响应体数据还在网络进程中;
4. )提交文档;将网络进程中的数据传输到渲染进程中;
(文档指URL请求的响应体数据)
提交文档的过程:
4.1 浏览器进程发出体交文档的消息后,渲染进程接收到消息,会和网络进程建立传输数据的管道;
4.2 等文档数据传输完成后,渲染进程会向浏览器进程发送确认提交的消息;
4.3 浏览器进程接收到确认提交的消息后,会更新浏览器的界面状态(前进后退状态,更新地址栏URL,Web页面,安全状态,停止标签图标的加载动画)
================导航流程(网络加载流程和渲染流程间的桥梁)结束=================
5. )渲染流程阶段;
html生成dom树----样式计算----生成布局树---图层树---图层绘制----光栅化----合成显示
5.1 构建dom树, 将html转为浏览器可以理解的dom树;
5.2 样式计算,计算dom节点中每个元素的具体样式;
5.2.1 通过渲染引擎,将CSS转为浏览器可以理解的样式表(styleSheets);
5.2.2 将样式表中的属性值标准化;比如将 red 转为 rgb(255,0,0);em转为px; bold转为700;
5.2.3 计算dom树中每个节点的具体样式,保留在computedStyle 结构内;
计算规则遵循css继承(每个dom节点都含有父节点的样式),样式层叠的规则;
5.3 布局阶段, 计算dom树中可见元素的几何位置,生成布局树;
5.3.1 创建只含有可见元素的布局树;
5.3.2 计算每个元素的几何坐标,将其保存在布局树中;
5.4 分层,生成图层树;
什么条件下渲染引擎会为节点创建新的图层?
a. 有图层上下文属性的元素会被提升为单独的一层;(position: fixed;透明度;z-index属性等;)
b. 需要剪裁的地方(overflow: hidden)
5.5 图层绘制,得到待绘制列表;
将一个图层的绘制拆为很多小的绘制指令,然后再把这些指令按顺序组成待绘制列表;
5.6 栅格化操作, 图层--->> 图块---->> 位图
主线程将绘制列表提交给合成线程,合成线程将图层划分为图块(256*256,512*512),栅格化线程池将图块转换为位图,保存在GPU内存中;
为什么需要生成图快?
因为有时图层很大,需要滚动很久才能到底部,而通过视口(页面上可见的区域),用户只能看到页面很小的一部分,所以这种情况下,一次性绘制出所有图层内容的话,会产生太大的开销,而且也没必要;这时就需要图块了。
5.7 合成显示;
5.7.1当所有图块都被光栅化之后,合成线程会生成绘制图块的命令DrawQuad,并将该命令提交给浏览器进程;
5.7.2 浏览器进程中的viz组件,接收到合成线程发送的DrawQuad命令后,根据命令将页面内容绘制到内存中;最后将内存显示到屏幕上;

5. 重绘和重排
重绘:更新元素的绘制属性,如修改元素的背景色,颜色,没有引起几何位置的变化,
样式计算---图层绘制----光栅化---合成显示;
重排:更新元素的几何属性,触发了重新布局,如宽度,高度,font-size
样式计算---布局树---图层树----图层绘制--光栅化---合成显示
合成: 更改了一个既不需要布局也不需要绘制的属性;如transform: translate(xxx,xxx)
样式计算---合成显示;
===》》》相交于重排,重绘省去了生成布局树,生成图层树的阶段,所以执行效率高于重排;
1. 变量提升所带来的的问题:
1)变量容易在不被察觉的情况呗覆盖掉;局部的变量可能覆盖了全局的同名变量值;
2)本应销毁的变量没有被销毁;(如for循环中用var定义的变量i,使用完之后还会存在;)
ES6引入了let,const块级作用域,来解决变量提升所带来的的问题,
2. this的类别:
1)全局执行上下文中的this; 指向window对象;
2)函数执行上下文中的this;
a. 可通过call,apply,bind在函数调用时改变函数执行上下文中的this指向;
b. 使用对象来调用其内部的一个方法,该方法的this指向对象本身;
在全局环境中调用一个函数,函数内部的this指向window;
var myObj = {
name : "极客时间",
showThis: function(){
console.log(this);
}
};
myObj.showThis(); // {name: '极客时间', showThis: ƒ}c. 在构造函数中设置this;
function CreateObj(){
this.name = "极客时间"
}
var myObj = new CreateObj()new 关键字会进行如下的操作:
- 1)创建一个空的JS对象x(即{});
- 2)为步骤1新创建的对象x添加属性__proto__,将该属性链接至构造函数的原型对象 ; 即x.proto = CreateObj.prototype;
- 3) 然后执行构造函数,并将步骤1新创建的对象作为this的上下文 ;
- 4)如果该函数没有返回对象,则返回this。
- 如果return的是基本数据类型,new的时候构造器的返回会强制指定为x;
- 如果return的是其他类型,及对象类型,则new的时候会遵循构造函数实际的return语句返回;(译注:关于对象的 constructor,参见 Object.prototype.constructor)
3)eval中的this;
this的设计缺陷和应对方案:
1) 嵌套函数中的this不会从外层函数中继承;
解决方法: 使用self保存this的指向;使用箭头函数;
2)普通函数中非严格模式下,this默认指向全局对象window;严格模式下,this为 undefined;
3、JS的语言类型;
动态语言:在使用之前需要确定变量的类型;
静态语言:在运行过程中需要检查变量的类型;
弱类型语言:在不同数据类型的赋值操作时,会偷偷将变量类型进行转化;(即支持隐式转换)
强类型语言: 不支持隐式类型转化;
》》》JS是弱类型,动态语言;
弱类型:意味着你不需要告诉JavaScript引擎变量是什么数据类型,JavaScript引擎在运行代码的时候会计算出来。
动态:意味着你可以使用同一个变量保存不同类型的数据。
JS分为原始数据类型和引用类型,原始类型存放在栈中,引用类型存放在堆中;
原始类型: String,Number,Boolean,Symbol,bigInt,null,undefined,
引用类型: Object,
引用类型的数据值存放在堆中,堆中的数据通过引用和栈中的变量关联起来;
JS中变量没有数据类型,值才有数据类型;
4. JS中的垃圾回收机制:
1)JS引擎会通过向下移动ESP来销毁该函数保存在栈中的执行上下文;
2)堆中的垃圾数据,需要通过JS中的垃圾回收器进行回收;
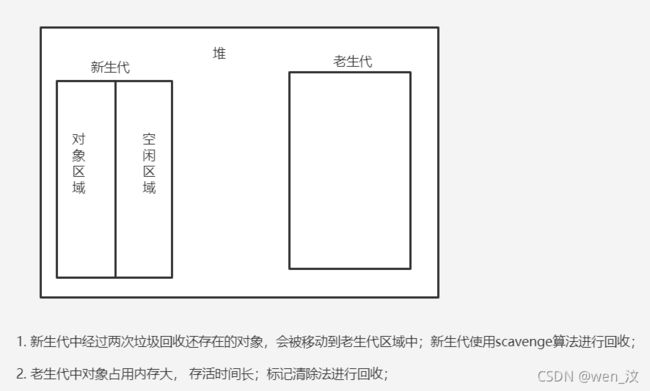
代际假说:a. 大部分对象在内存中存在时间很短;b.是不死的对象,会活的更久;
V8中把堆分成新生代和老生代两个区域,
新生代存放的是存活时间较短的对象,使用副垃圾回收器进行回收;新生代中有对象区域和空闲区域;
老生代存放的是生存周期长的对象,使用主垃圾回收器进行回收;
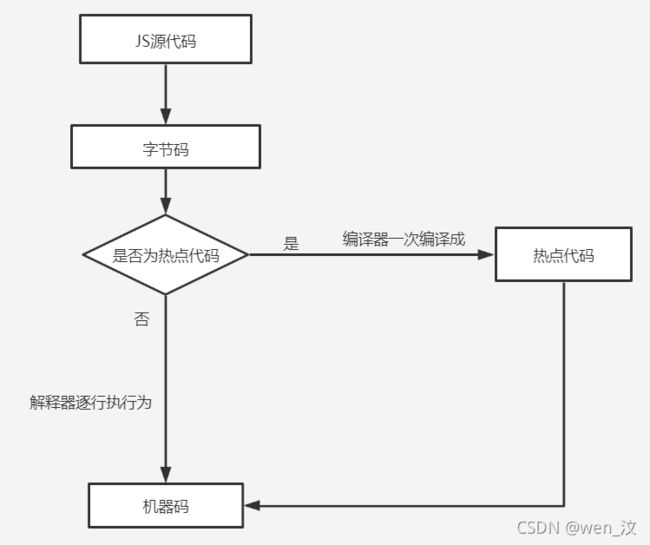
5. 编译器和解释器:
babel工作原理:先将ES6的代码转为ES6的AST,再将ES6的AST转为ES5语法的AST,最后根据ES5的AST生成JS源代码;
V8执行JS代码的过程
1)生成抽象语法树(AST)和执行上下文;
生成AST的过程:
a. 分词,即词法分析,拆分成一个个的token;
b. 解析,即语法分析,将上一步生成的token,根据语法规则转为AST;
2)生成字节码,
3)执行代码:解释器会逐条执行第一次执行的字节码为机器码,如果是热点代码(一段代码被重复执行多次),则编译器将该段热点代码编译成机器码,下次执行这段代码时直接执行机器码即可,提高了代码的执行效率;
JS代码----->>字节码----->>机器码
JS性能优化时,可关注的点:
1)提升单次脚本的执行速度,使页面快速响应交互,避免JS的长任务霸占主线程;
2)避免大的内联脚本;
3)减少JS文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存;
6. 消息队列和事件循环:
以浏览器中渲染进程中各个线程进行任务处理为案例:
1)主线程如果要接收其他线程发送的任务并执行时,其他线程会先将任务添加到消息队列尾部,然后主线程从消息队列首部拿出任务进行执行;
2)如果其他进程想要发送任务给页面主线程,则先通过IPC把任务发送给渲染进程的IO线程,IO线程再把任务发送给页面主线程;
3)消息队列并不太灵活,为了适应效率和实时性,引入了微任务;
7. JS面向对象的知识: 封装,继承,多态;
1)封装:限制对对象内部组件直接访问;将数据和方法绑定起来,对外提供方法,从而改变对象状态;
2)继承:一个对象或者类能够自动保持另一个对象/类的实现的一种机制;
继承的类型:ES5中常用的继承_zw_wen的博客-CSDN博客
ES6之前是没有继承关键字的,
a. 原型继承, 子类的原型指向父类的实例, child.prototype = new parent()
缺点:无法继承父类构造函数中的参数;无法实现多继承;
b. 构造继承,在child函数中,调用parent构造方法;
有点:可以继承父类函数中的参数,可实现多继承;
缺点:子类实例对象不是parent实例对象, 无法继承父类原型上的属性和方法;
3)多态:同名方法在不同类中有不同的实现;
8. setTimeout
使用setTimeout时需注意的坑:
1)如果当前任务执行时间过久,则会延迟到期定时任务的执行;
2)如果setTimeout存在嵌套调用,则系统会设置最短时间间隔为4ms;
===>> ⼀些实时性较⾼的需求就不太适合使⽤setTimeout了
9、 XmlHttpRequest
回调函数:将一个函数作为参数传递到另一个函数中,那作为参数的这个函数就称为回调函数;
xmlHttpRequest工作流程:
1)创建一个xhr对象,var xhr = new XmlHttpRequest()
2) 为xhr对象注册回调函数; (ontimeout,onerror,onreadyStateChange);
3) xhr.open()打开请求;
4)配置超时时间,响应类型等信息;
5)xhr.send()发送请求;
xhr使用过程中由于浏览器的安全策略可能会遇到的问题;
1)跨域问题;
2)https混合内容问题;(指https页面中包含了不符合https安全要求的内容)
10 MVC框架:
Angular:
React + Redux;
redux:操作时根据handle方法,dispatch调用redux中对应的action.type的方法;在redux中更改store中的数据;数据是单向流动的;Store中数据状态的改变只有一个来源,就是Reducer的操作;
11.页面开发时的交互设计:
1)单页面应用:
优点:用户体验上:更加桌面化,操作迅速,切换无缝,省去了页面跳转时的等待时间;软件架构上:页面聚合搬到前端完成,有利于前后端分离;
缺点:页面状态改变时很难被搜索引擎捕捉到,不利于SEO的搜索;
2)渐进式增强;侧重于可访问性,允许不同能力的设备都能访问网页,使用网页的基本功能,但是设备越先进,给用户带来的功能更强大,体验更好;
3)优雅降级:当高级特性和增强内容无法在用户的设备上展现的时候,依然可以通过其他的方案给用户提供一个具备基本功能,可工作的应用版本;
4)回归增强,
======》》照顾了更多的设备和浏览器,给用户尽量好的体验;
网页设计方法:
1)响应式布局(即自适应性网页设计)
/* 根据不同的屏幕大小设置对应的样式 */
@media screen and (min-width: 640px){
}12. 根据Chrome开发者工具分析性能;
1)Network面板中Timing:
排队(Queuing)时间过久:可能是由于浏览器为每个域名最多维护6个tcp链接导致的, 解决方法:采用域名分片技术,将一个站点的资源放到多个域名下面;将站点升级到HTTP2;因为http2没有每个域名最多维护6个TCP链接的限制;
TTFB(接收服务器第一个字节数据所用的时间)时间过久,说明服务器响应速度过慢; 原因有:服务器生成页面数据时间过久;网络原因;发送的请求头上带上了多余的用户信息;
Content Download时间过久:可能是字节数太多导致的,需要减少文件大小,比如压缩,去掉源码中多余的注释等方法;
13. DOM树
HTML解析器:将HTML字节流转为DOM结构;网络进程加载了多少数据,HTML解析器就解析多少数据;
字节流转为DOM结构的过程
1)分词阶段:通过分词器将字节流转为一个个的token,分为Tag Token和文本token;Tag token又分为startTag和endTag;
2)将Token解析成dom节点,并将dom节点添加到dom树上;
HTML解析器维护了⼀个 Token栈结构,该Token栈主要⽤来计算节点之间的⽗⼦关系,在第⼀个阶段中⽣成的Token会被按照顺序压到这个栈中。具体的处理规则如下所⽰:
a. 如果压⼊到栈中的是 startTag Token,HTML解析器会为该Token创建⼀个DOM节点,然后将该节点加⼊到DOM树中,它的⽗节点就是栈中相邻的那个元素⽣成的节点。
b. 如果分词器解析出来是文本Token,那么会⽣成⼀个⽂本节点,然后将该节点加⼊到DOM树中,⽂本
Token是不需要压⼊到栈中,它的⽗节点就是当前栈顶Token所对应的DOM节点
c、如果分词器解析出来的是EndTag Token,⽐如是EndTag div,HTML解析器会查看Token栈顶的元素是否是StarTag div,如果是,就将StartTag div从栈中弹出,表⽰该div元素解析完成。
通过分词器产⽣的新Token就这样不停地压栈和出栈,整个解析过程就这样⼀直持续下去,直到分词器将所有字节流分词完成。
* HTML解析器开始工作前,会默认先创建一个根为document的空DOM结构;并且会将startTag document 的Token压入栈中;
* HTML解析器在解析生成DOM的过程中,如果遇到了script脚本标签,则会暂停DOM的解析,因为接下来的JS脚本有可能会修改当前已经生成的DOM 结构;(渲染引擎)
HTML解析器暂停工作后,JS引擎介入执行脚本,JS脚本执行完毕后,HTML解析器恢复解析工作继续解析,直至生成最终的DOM
* JS文件的下载过程会阻塞DOM解析;JS脚本执行之前,会先进行CSS文件的下载,解析生成CSSOM对象;
==>> CSS阻塞JS的执行;JS阻塞DOM的生成;
JS脚本异步加载的方式:
详细可参考MDN文档:https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/script
async和defer的详细区别可参考博客: 浅谈script标签中的async和defer - 贾顺名 - 博客园
1)async:
脚本文件一旦加载完成会立即执行 (H5新出的)
2) defer;
脚本文件需等到文档完成解析后,DOMContentLoaded 事件触发前执行;当src属性为空时,会不生效;
DOMContentLoaded事件触发的时机:当初始的 HTML 文档被完全加载和解析完成之后,被触发,而无需等待样式表、图像和子框架的完全加载;
14. 渲染流水线,CSS是如果影响首次加载的白屏时间;
CSSOM的作用:
1)提供JS操作样式表的能力;
2)给布局树的合成提供基础的样式信息;
从发起URL请求开始,到首次显示页面的阶段:
1)等请求发出之后,到提交数据阶段(网络进程将数据提交到渲染进程);
2)提交数据之后,渲染进程会创建一个空白页面,(解析白屏),等待CSS文件和JS文件加载完成,生成CSSOM和DOM,然后合成布局树,准备首次渲染;
3)绘制页面;
分层--分块--合成
为什么CSS动画比JS动画高效?
CSS动画是运行在合成线程中的,不会影响主线程的任务,提高了渲染的效率(合成线程中的任务不会触发重绘和重排);可以用wll-change属性提前告诉渲染引擎,让它为该元素准备单独的层,等这些变化发生时,渲染引擎通过合成线程直接处理变换,不涉及主线程,提高了渲染效率;运行在GPU;
JS动画是运行在浏览器主线程中,因而可能会导致线程阻塞,从而丢帧;而且我们一般是通过JS去改变元素的位置信息,这些操作会触发重排和重绘,渲染开销会比较大;运行在CPU;
14. 页面性能优化
关键资源: 阻止网页首次渲染的资源;
影响网页首次渲染的核心因素有:
1)关键资源的个数;
2)关键资源的大小;
3)请求关键资源需要多少个RTT(Round Trip Time);
RTT: 指从发送端发送数据开始,到发送端接收到来自接收端的确认,总共经历的时延;通常一个HTTP的数据包是14KB左右;所以0.1M 的页面需要拆成 0.1*1000 / 14 = 8 个数据包进行传输;
优化原则和方案
1)减少关键资源的个数和大小;
JS标签加上了defer,async;cssLink 添加了媒体阻止显现的标志,就变成了非关键资源了;从而减少关键资源的个数;
压缩CSS和JS资源,移除HTML,CSS,JS文件中的注释内容;从而减少关键资源的大小;
交互阶段的优化:
1)减少JS脚本的执行时间;
将以此执行的函数分解成多个任务;
可以将和DOM操作无关且耗时的任务放到webwork中,因为webwork中是没有DOM,CSSOM环境的;
2)避免强制同步布局,即添加dom节点后立马通过获取offsetHeight等信息强制让渲染引擎执行一次布局操作;
3)避免布局抖动;尽量不要在修改DOM结构时再去查询⼀些相关值
4)合理利用CSS合成动画;如果已经提前确定对某个元素执行动画操作,则最好将其标记为will-change
5) 避免频繁的垃圾回收;避免在函数中频繁的创建临时对象,尽可能的优化存储结构;
15. 虚拟DOM
本质是一个JS对象,用对象中相关的属性标识dom节点;
为什么会出现虚拟DOM?
1)JS直接操作DOM,会引起重排,重绘等操作,从而引起性能问题,
2)可以批量更新DOM的变化;
3)可以进行跨端应用开发;
React中虚拟DOM运行流程:
1)创建阶段:依据JSX和基础数据创建虚拟DOM树,由虚拟DOM树再创建出真实DOM树,真实DOM树生成完成后,再触发渲染流水线输出页面;
2)更新阶段:如果数据发生了变化,则根据新数据创建一个虚拟DOM树,比较两个虚拟DOM树,将变化的地方一次性更新到真实DOM树上,最后渲染引擎更新渲染流水线生成新页面;
两个虚拟DOM 节点进行比对时的算法,新算法称为Fiber reconciler;老的算法为:Stack reconciler
虚拟DOM的优点:
1)双缓存区:在完成一次完整的操作之后,再把结果应用到DOM上,减少不必要的更新,保证DOM的稳定输出;(可解决无效的刷新和闪屏问题)
2)MVC模式中,可以把虚拟DOM看成是MVC的视图部分,其控制器和模型都是由Redux提供的
16. http的发展史
http0.9:主要用于学术交流,传输html超文本内容;
缺点: 可传输的文件类型单一;
http1.0:
a. 支持JS,CSS,Img,音频,视频等多种文件类型的传输;为此引入了请求头,响应头,状态码等信息;
b. 引入了缓存机制,
c. 请求头中加入了用户代理字段;
此时TCP还是短连接,即每次请求前都需要先建立TCP连接,请求得到响应后,断开连接;
http1.1: a. 持久连接, 即一个TCP连接可以传输多个http请求;(默认是开启的)
b. 管道化传输;可以将一批请求发送到服务器端,服务器会按照请求的顺序进行处理;
c. 提供虚拟主机的支持;即一台物理主机上可以有多个虚拟主机, 每个虚拟主机的域名不同,但是这些域名共用一个IP地址;
d. 数据的分块传输,服务器会将数据分割成若干个任意大小的数据块,每个数据块发送时都会附带上上一个数据块的长度,最后使用一个0长度的数据块作为发送数据完成的标志; 即对动态内容提供了支持;( 页面内容是动态生成的);
e. 客户端Cookie,安全机制;
缺点:a. 对带宽的利用率不高;(带宽:每秒指能接收或发送的字节数)因为TCP是慢启动的;同时开启多条TCP连接,那么这些连接会竞争固定的带宽;http1.1队头阻塞(当前请求没有结束,后面的请求只能处于阻塞状态);
http2.0: 2015年5月发布;
a. 多路复用;解决http1.1队头阻塞的问题;(二进制分帧层,即每个请求都有唯一的id,根据响应头,响应体上的id,拼接成对应请求的响应数据;服务器端也可以根据有相同id的帧合成为一个完整的请求信息;)
b. 可设置请求优先级, 服务器会优先处理优先级高的请求;
c. 服务器推送;
d. 头部压缩;支持请求头和响应头的压缩;
缺点:
a. TCP的队头阻塞;
b. 建立TCP连接时的延迟;
c. TCP协议僵化;
http3.0; QUIC协议(基于UDP + TLS)
改动了底层协议,和http2.0有着本质的区别;
17 浏览器的同源策略;
同源:指两个URL的协议,域名,端口号都相同,则将这两个URL称为同源;
浏览器同源策略的限制的表现:
a. DOM层面;限制不同源的JS脚本对当前DOM对象的读写操作;
b. 数据层面, 限制不同源的站点不能读取当前站点的Cookie, indexDB, LocalStorage等数据信息;
c. 网络层面;限制通过XMLHttpRequest 等方式不能访问不同源站点的数据, 即不能访问跨域的资源;
18. 跨站脚本攻击(XSS):Cross Site Scrpting
概念:攻击者在html或Dom中注入JS脚本,在用户浏览页面时利用注入的脚本对用户进行攻击;
分为三种类别:
a. 存储型XSS;恶意脚本存储在服务器上,影响范围最广,危害最大;
b. 反射型XSS; 用户将含有恶意脚本的请求提交给服务器, 服务器接收到请求时,又将恶意脚本反射给浏览器;(服务器不会存储XSS攻击的恶意脚本;)
c. 基于DOM的XSS;攻击者直接将恶意脚本代码注入到用户的页面中;
产生的后果:
a. 窃取用户的cookie,在用户不知情的情况下进行一些转账操作;
b. 监听用户键盘的录入事件,获取输入信息;
c. 修改dom,伪造假的登录页;
d. 生成浮窗广告;
预防手段:主要是阻止恶意的JS脚本插入;
a. 服务器对输入的脚本进行过滤和转码;
b. 充分利用CSP;CSP的使用参考:内容安全策略( CSP ) - HTTP | MDN
c. 使用httponly属性,限制JS脚本对cookie的操作;
19. CSRF: 跨站点请求伪造, Cross Site request forgery;
概念:利用服务器的漏洞,在用户已登录的状态下,通过第三方网站调用原服务器的接口,从而达到攻击的目的;
产生危害:
a. 自动发起转账请求;(get请求方式)
b. 构建自动提交表单,从而触发post方式的转账请求;
预防手段:
a. 利用cookie的sameSite属性;
strict: 严格禁止第三方cookie;
lax:在跨站点的情况下,从第三⽅站点的链接打开和从第三⽅站点提交Get⽅式的表单这 两种⽅式都会携带Cookie;其他场景禁止;
none: 任何场合都会带cookie;
b,服务器验证请求来源的站点;
服务器会优先判断请求头中的origin字段,如果请求头中没有origin(含有协议+域名)字段 ,再根据实际情况判断是否需要判断referer(协议+域名+羽绒棉完整路径)属性;
c. 服务器端生成CSRF Token,然后客户端请求时在请求参数中将这个token值传递到服务器端,服务器验证这个token是否是合法的;
20. 安全沙箱;

安全沙箱保护了系统中的资源免受网络上恶意程序的攻击;浏览器会默认网络下载的资源是不可信的,所以网络上的资源都是在安全沙箱中运行的,如果在执行的过程中,恶意代码即使触发了,但是它也不会对系统资源进行操作,保护了系统安全;
21. HTTPS
在TCP和Http层间引入了安全层,进行数据的加解密操作;
采用混合加密算法,非对称加密传递公钥,对称加密算法传递数据,在保证安全的同时也保证了传输的效率;
目录
1. 进程和线程的区别
2. 如何保证页面文件能被完整的送到浏览器;
3. 为什么很多站点第二次打开速度会很快?
4. 用户从输入URL到页面展示的过程?
5. 重绘和重排
1. 变量提升所带来的的问题:
2. this的类别:
3、JS的语言类型;
4. JS中的垃圾回收机制:
5. 编译器和解释器:
6. 消息队列和事件循环:
7. JS面向对象的知识: 封装,继承,多态;
8. setTimeout
9、 XmlHttpRequest
10 MVC框架:
11.页面开发时的交互设计:
12. 根据Chrome开发者工具分析性能;
13. DOM树
14. 渲染流水线,CSS是如果影响首次加载的白屏时间;
14. 页面性能优化
15. 虚拟DOM
16. http的发展史
17 浏览器的同源策略;
18. 跨站脚本攻击(XSS):Cross Site Scrpting
19. CSRF: 跨站点请求伪造, Cross Site request forgery;
20. 安全沙箱;
21. HTTPS
全文参考: 浏览器工作原理与实践_浏览器_V8原理-极客时间