知识点(4)——HashMap中插入数据用的头插法还是尾插法
前言
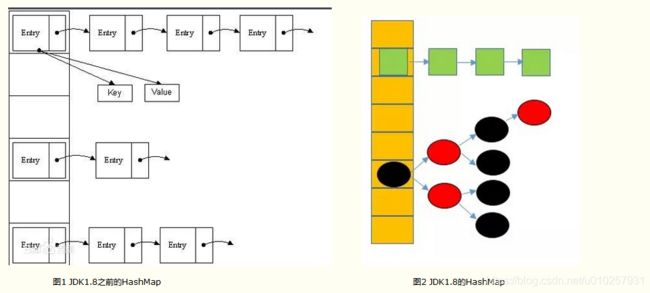
大家都知道,HashMap用到的数据结构,在JDK8之前是数组+单链表。在JDK8用的是数组+单链表+红黑树。
这里说一句题外话,为什么JDK8时候引入了红黑树?
(1)因为当数组中每个元素,都是一个Entry,每一个Entry是一个单链表。
(2)当链表长度过长的时候,查询链表中的一个元素就比较耗时,这时就引入了红黑树。
(3)首先红黑树是一棵二叉树,而且属于二叉树中比较特殊的二叉搜索树。红黑树有一条特性就是从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。这一特性,确保没有一条路径会比其他路径长出两倍,因而,红黑树是接近平衡的二叉树。这就使得红黑树的时间复杂度大大降低,为O(logN)。
(4)所以,用红黑树替代单链表会降低集合中元素的访问速度。(JDK8规定,当链表长度大于8时,且桶的数量大于64时,由单链表转化为红黑树;而当链表长度小于6时,又由红黑树转化为单链表)。
回到正题,那么当往HashMap中插入一个元素是怎么一个流程呢?是怎么把元素插入到链表或者红黑树中的呢?
元素的插入
查看HashMap的源码我们可以发现,put操作:
static final int hash(Object key) {//自定义的hash方法
int h;
//首先判断键是否是null,如果是null则返回0,如果不是null,则返回key的hashCode与key的hashCode值无符号右移16位的异或运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {//往集合添加元素的操作
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//找到数组中对应索引处的链表
if ((p = tab[i = (n - 1) & hash]) == null)//如果数组中对应索引处的元素为空,则新创建一个链表,放到这个索引处
tab[i] = newNode(hash, key, value, null);
else {//如果对应索引处的元素不为空
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//如果要插入的key和 链表中的第一节点的key相同,那么就把第一个节点赋值给e
e = p;
else if (p instanceof TreeNode)//如果节点是红黑树
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {//循环遍历链表中的节点
if ((e = p.next) == null) {//如果在链表中未找到与要插入的节点的key相同的节点,那么插入一个新的节点来存储
//插入链表的尾部
p.next = newNode(hash, key, value, null);
//如果插入后链表长度大于8则转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//如果找到了这个节点,那么跳出循环
break;
p = e;
}
}
//判断找到的相同key处的节点,并覆盖这个节点的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 首先,根据key,经过自定义的hash算法计算,得到一个hash值,再通过这个hash值&(table.length-1)得到在数组中的index。
然后通过索引index获取到数组中对应索引处的链表。拿到链表遍历里面的节点,如果没找到与要插入的节点具有相同key的节点,那么直接在链表中插入一个新的节点。如果找到了与要插入的节点具有相同key的节点,那么就把原有的value进行覆盖。
好了,了解了插入元素的流程,我们来说一下,插入元素的方式。
插入元素的方式
借用某位大神一张图哈:
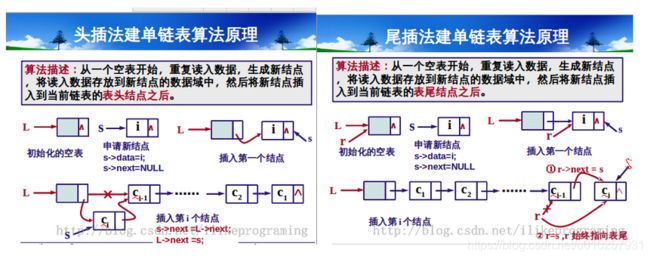
在JDK8中:
p.next = newNode(hash, key, value, null);可以看出新建的节点,放在了当前节点的next(即下一个位置),说明在当前节点的尾部。插入到当前节点的尾部,那当然是尾插法了。
再看JDK6中:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
//如果发现key已经在链表中存在,则修改并返回旧的值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//如果遍历链表没发现这个key,则会调用以下代码
modCount++;
addEntry(hash, key, value, i);
return null;
} 重点关注插入的代码:addEntry(hash, key, value, i);
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
} Entry( int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
} 这里的next=n,说明了一切。意为: 新建节点的next,指向了n。n即为key对应索引处的链表。把之前的链表放到了新建节点的next的位置。说明是在以前链表的头部插入了新节点。故为头插法。
总结:
由上可以看出,
在JDK1.8中采用的是尾插法。
在JDK1.6中采用的是头插法。