Linux——文件系统
我们的计算机中一定会有文件,我在之前的博客中已经介绍了内存中的文
件,也就是被打开的文件。但是有被打开的,那就有没有被打开的文件,
这一部分文件是在磁盘中的。我们平时用到的无非就是通过路径找到它,然
后对它进行操作,比如加载到内存中。现在我们将从操作系统和硬件的方面
来重新认识一下磁盘中的文件,以及内存中的文件和未打开文件整体构成的
文件系统。
Linux——被打开的文件
1. 磁盘中的文件
就像我上面说的一样,磁盘中的文件它主要是为了加载进内存中,供用户进行对文件内容和属性的操作。既然有这一特点,那么就代表磁盘中的文件首先就要有被找到的功能,那就有了路径,而且啊还得找的速度并不慢。既然有了路径,需要被找到,那就说明磁盘中的文件也是需要被管理起来的。磁盘是一个硬件,而我们的操作系统是一个软件,那么软件是如何能够在硬件中找它想要的文件的呢?磁盘中也有路径这种说法吗?所以要探究文件系统,从硬件磁盘开始是很有必要的。有人这时候就问了,我们现在大部分笔记本上用的都是固态硬盘了,为什么还要说磁盘呢?这是因为磁盘足够经典,并且公司的服务器使用的存储介质大部分也是磁盘。
2. 磁盘


这就是磁盘的大致结构示意图,我们主要介绍它是如何找到目标文件的。
a. 磁盘存储数据原理
磁盘的存储是存储在磁盘上,磁盘的结构如下:

既然是叫磁盘,那就肯定是跟磁有关。我们知道计算机它实际上只认识二进制,所以我们数据的存储也只是存储二进制而已。而二进制只有0和1,所以我们就可以利用磁铁只有NS级的特性来代替01这样就能让磁极也有了另一种意义。而我们的磁盘结构如上图所示,它分为许多环形磁道,而环形磁道又被从圆心到圆周上的线段分为许多小扇形,得到这样的扇形就是磁盘的最小的存储单元,叫做扇区(它还有更细化的结构,这里就不再讲述了)。

每个扇区所能够存储的空间大小比较经典的大小是512B(512个字节),磁盘的每个扇区的存储空间大小都是一致的(现在的科技能做到不一样大小了)。在扇区中,我们的磁头可以对这片区域进行充磁(磁化)相当于进行二进制的写入,通过让磁头感应扇区的磁极转化为电信号实现读取数据,让扇区中能存储不同磁性的更小的块让它具有存储和被读取的功能。而我们上面说的环形区域,这个由在一个同心环中的小扇形组成的区域叫做磁道。
b. 磁盘如何存储数据到目标位置/找到目标文件读取(CHS寻址模式)
磁盘它是一个可以转动的装置,它的圆心有个转轴可以让它顺时针/逆时针转动,而我们的磁头是在磁臂上,可以实现从磁盘圆心到圆周区域的覆盖,大致如下:

大致方式就是由磁盘转轴旋转来锁定扇区在哪个大扇形上,由磁臂来锁定哪个磁道。
这里需要注意,磁盘是两面都能读写数据的,这意味着我们的磁头也有两个。实际上,磁盘(硬件)中也不止一张磁盘(硬件中的零件):

可以看到它有许多个磁头和磁盘。
所以磁盘读写数据的大致流程如下:
1. 先确定数据在哪一面从而选择好磁头(Head)
2. 选择好盘面上的磁道(Cylinder)
3. 确定磁道上的哪个扇区(Sector)
这就是磁盘所使用的CHS寻址模式。
这样就可以实现磁盘进行指定位置读写数据了。
c. 磁盘的其他小知识
经过上面的认识,我们知道了磁盘是如何读写数据的,这也对里面的机械结构有着高精度的要求,并且磁盘盘面上是不能沾有灰尘的,一旦沾上灰尘,要知道当磁盘在运作时会以每秒几千甚至上万以至于更快的旋转速度,这样的旋转速度运作,假如盘面上有灰尘,则会瞬间就会将磁盘损坏。所以磁盘一旦被普通人员拆开,也就意味着这个磁盘是报废了。
但是这个磁盘是真的报废了吗?其实不然,它上面是以磁的特性来存储数据的,当磁盘暴露在空气中沾上灰尘,它只是不能运作了,但是它上面的数并没有消失,这也是为什么磁盘能够恢复数据的原因,而恢复数据一般是由厂家来进行操作的。而我们知道磁性物质遇高温就会失去磁性,所以让磁盘经过高温之后就能让磁盘真正的报废了。
我们也知道大企业中一般都有自己的服务器,而服务器的存储数据一般都是使用的磁盘,而磁盘又是一种机械结构,它是肯定会老化的直到不能使用。这个时候就需要迁移数据更换新磁盘,这时候企业敢直接扔掉老化的磁盘吗?答案是肯定不敢,因为里面的数据还在,而磁盘这种硬件一般又是国外掌握着核心技术,所以更加不敢随意丢掉不能使用的磁盘了,这也是为了安全考虑。所以当磁盘不能使用时,企业一般会对这个磁盘进行数据的销毁,也就是对磁盘写入全一或者全零,而磁盘出厂商也会配备这样的功能,他会通过二进制指令来直接对磁盘进行刷盘,从而真正的销毁磁盘。
3. 操作系统与磁盘
我们上面介绍的是磁盘寻找文件的方式,这样找的的文件的物理位置。而我们的操作系统是软件,我们的操作系统是如何控制磁盘找到指定文件的呢?
a. LBA寻址模式
在Linux的文件系统中,使用的是LBA寻址模式,它将磁盘的所有扇区有序的抽象成一个线性的空间,固定范围是在哪个扇面,哪个磁道,哪个扇区:

这样我们就将物理的位置转换成寻找数组下标的逻辑位置,这就是LBA寻址模式。
我上面也说了一个扇区的大小是512个字节,但是这对于操作系统来说,一次只读512字节太小了,所以操作系统又将八个扇区组成一个数据块,作为文件系统的最小存储单元,大小为4KB(一般是4KB,用户可以自己修改源代码定义)。从现在开始,对磁盘的存储管理,由操作系统转化为了对数组的增删查改,但是这样就完了吗?还没有。
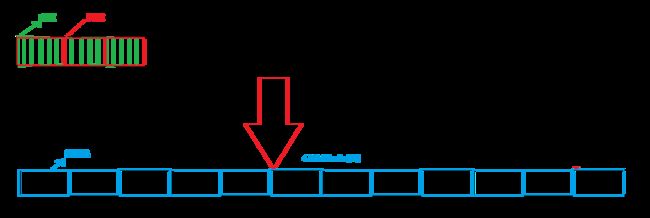
b. ext2文件系统
Windows中磁盘一般是有分区的,这里的分区不可能把磁盘分开,虽然它们分了区,但它们本质上还是在一起,但是每个分区就有了自己的文件系统:

这样的话,我们只要能将一个分区给管理好,那么其他分区自然也就能管理好,而在分区下有着更加细致的划分,每个分区都有更小的块组构成,这里块组大小暂且为2GB,这样的话我们管理好一个块组的话,其他块组也能被管理好,整个分区就管理好了,这种思想叫做分治:

而块组又由以下分配:

简单介绍一下Boot Block,这个模块中记录的是一个计算器启动所需要的文件。放在磁盘的开始,相当于我们Windows中C盘的系统文件。
我们磁盘中的的文件需要被管理,而管理我们磁盘的内容数据需不需要存储?答案也是肯定的。所以我们磁盘中存储的内容,大致分为以下几种:

而不管用户有没有文件,管理文件的内容数据都已经存在了。
用户文件的内容和属性也是分开存储的
1). inode Table和data blocks
我们首先来认识块组中的inode。
Linux系统中每个文件都有自己的inode,而且这个inode是区唯一的,区唯一的意思就是,在这个分区中每个文件的inode都是独一无二的。但是我们在使用Linux的时候从来没有见过inode啊,这需要我们使用一条命令:
ls: -i选项

这就是我们的inode编号,而块组中的inode Table又是什么呢?
你可以将inode理解为一个结构体这个结构体中大致存储了以下数据:
struct inode
{
//文件大小、权限、拥有者、所属组、ACM时间、inode编号。。。
int blocks[15]
}
这其中inode结构体的大小一般是128字节,而其中blocks数组的大小是15个int,这其中存储着块组中该文件内容所占用的数据块的位置。
其中Data Blocks中有许多的数据块,来存储文件的内容。
而计算机识别文件也不是识别文件名,而是inode编号。
我们知道普通文件存储的是用户需要的数据,那么目录里存储的是什么呢?
上面说了计算机不认识文件名,他只认识inode编号,**所以目录里存的是该目录下文件与inode编号的相互映射。这就是目录文件的文件内容。**这样也便于文件的查找。
所以这就是为什么删除新建该目录下文件需要的是该目录的w权限了。
而在Linux中,文件名不属于文件属性
2). inode Bitmap和block Bitmap
这两个就是位图,用来记录块组中的inode和数据块中有无数据,至此文件的删除就只需要更改两个位图中的数据就可以。
3). Group Descriptor Table
组描述符表(Group Descriptor Table),简称GDT,是用来描述块组的使用情况,和描述信息。比如该块组下inode编号的开始编号,以便于文件查找。
4). Super Block
存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,
未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
超级块并不是每一个块组中都有,而是在一个分区中的某几个块组中,目的就是防止一个超级块损坏后,文件系统直接损坏。
5). 文件的新建与查找
现在我们要新建一个文件的步骤就明了了:
1. 利用位图查找块组中未使用的inode和数据块
2. 将属性和内容分别填入inode表和数据块中
3. 在该目录下建立inode编号和文件名的映射
这时候就有人有疑问了,你怎么知道该目录的inode编号的?你不知道编号怎么建立映射?
这不就是吗。而定位inode编号也很简单,每个块组都记录了自己的开始的inode编号可以很快地跳跃性的定位到目标块组中查找。
那如何使用路径查找一个文件呢?
我们查找一个文件,一般是绝对路径查找。这时候从家目录开始一直查找映射就可以了。
那我们在程序中打开一个文件的时候可是直接填写的文件名,可没有使用绝对路径啊?
这是因为我们进程中有着cwd当前工作路径,系统会根据这个路径找到目的地。
最后一个问题:磁盘分区后,每个分区都有自己唯一的inode编号,而计算机只认inode编号,那假如两个分区中inode编号一样的话,是不是就会冲突?
这个显然不是的。这是因为Linux中关于磁盘的分区会使用挂载的方式来实现分区。大致介绍就是,Linux中会将分区挂在在一个目录下,如果你访问了这个目录,那就代表着你已经锁定了一个分区了。所以不会出现冲突。
以上就是ext2文件系统。
6). 一些知识扩展
inode结构体中block数组才十五个大小,总共也就60KB,那我要存储大文件的时候怎么办呢?
其实block数组中后两位元素存储的是二级寻址和三级寻址
二级寻址的意思就是,该数组中对应的数据块中存储的不再是文件的内容,而是其他数
据块的位置,那些数据块再存储文件的内容,而三级存储就是在二级存储存储内容的数
据块上再加一层的其他数据块位置的记录,而这些数据块可能不在本块组中,进行跨组
存储,而跨组存储也很方便,因为每个块组的中GDT存储着块组中inode编号的开始编号
当我们删除文件的时候,就需要更改分区的两个位图就可以,那么格式化是什么意思?它还是我们所认识的清空磁盘数据吗?
其实不是的,格式化磁盘他只是把用户的数据删除了,而对于管理文件的配置它并没有删除只是重置了,这叫做格式化磁盘。
4. 软硬链接
在了解过文件系统后,我们再来认识一下Linux中的链接文件,链接文件分为软链接和硬链接:

其中建立链接使用ln命令(link)软链接加-s选项。
我们发现硬链接文件与test.c的inode一样,而软链接文件与test.c的inode不一样。
这首先就说明了软链接文件是一个新的文件,这个文件中会存储目标文件的绝对路径。它的作用就类似于Windows的快捷方式。
而硬链接它与test.c的inode编号一样,说明它不是一个独立的文件,其实它只是该目录下,硬链接文件名与inode编号的映射,也就是存在目录中了。

而这就是文件的硬链接数。而这也意味着当我们删除test.c文件之后这个文件并没有真正被删除,真正删除一个文件就是该文件的硬链接数变成0。而这个硬链接数不难想到它使用了引用计数,而存储这个信息的地方就是该文件的inode结构体中。
现在我们建立一个空目录:

我们发现这个目录的硬链接数是2,这是为什么呢?
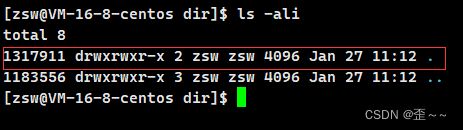
我们看到这是因为在该目录下建立了一个该目录的硬链接。而且这个硬链接只能操作系统搞,用户是无法对目录建立硬链接的。
这是因为我们的目录系统是树状的,当我们建立硬连接后就会形成环,导致递归查找文件时会出现死递归现象。而操作系统能够识别自己的硬链接不会死递归。
