pandas操作excel 笔记
目录
环境安装:
读取excel 并添加列
添加sheet,覆盖模式
写入excel文件
多行表头
修改excel,表头重复的会自动加小数点
修改excel,解决表头重复的问题
4、指定读取格式
pandas to_excel 修改excel样式以及格式
实现条件格式:
条件格式测试可以用:
环境安装:
pip install pandas
pip install openpyxl --trusted-host pypi.douban.com
样式:
pip install Jinja2
pip install xlsxwriter
读取excel 并添加列
# -*- coding: gbk -*-
import pandas as pd
if __name__ == '__main__':
dtype_dict = {'order_no': str, 'sbbh': str,'barcode':str,'barcode':str,'id_no':str}
excel_file=r'C:\Users\Administrator\Desktop\1716.xlsx'
df = pd.read_excel(excel_file, dtype=dtype_dict,sheet_name='其他')
datas=df.values.tolist()
header = df.columns.tolist()
order_index=find_index(header,'order')
sbbh_index=find_index(header,'sb')
down_status=[]
for index, data in enumerate(datas):
print(index,data[sbbh_index],data[order_index],data[barcode_index])
down_status.append(0)
df['down_video'] = down_status
save_dir=rf'F:\data\{os.path.basename(excel_file)}'
df.to_excel(save_dir, index=False)
添加sheet,覆盖模式
df = pd.DataFrame({'Column1': [10, 20, 30, 20, 15, 30, 45], 'Column2': [15, 25, 35, 45, 55, 65, 75]})
book = load_workbook(excel_name)
if 'online' in book.sheetnames:
del book['online']
# 创建一个 ExcelWriter 对象,设置为 'append' 模式
writer = pd.ExcelWriter(excel_name, engine='openpyxl', mode='a')
writer.book = book
df.to_excel(writer, sheet_name='online', index=False)
writer.close()写入excel文件
import pandas as pd
# 创建一个 DataFrame,包含列名
df = pd.DataFrame({'Column1': [10, 20, 30, 20, 15, 30, 45],
'Column2': [15, 25, 35, 45, 55, 65, 75]})
# 创建一个 ExcelWriter 对象
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# 将 DataFrame 写入名为 'aaaa' 的 sheet,包括列名
df.to_excel(writer, sheet_name='aaaa', index=False)
# 保存 Excel 文件
writer.save()多行表头
使用pandas导出excel表格的时候表头可能会出现类似下图这种表头

设计表头数据如下即可
colums = [("1", "1.1"), ("1", "1.2"), ("1", "1.3"), ("2", "2.1"), ("2", "2.2"), ("2", "2.3")]
df.columns = pd.MultiIndex.from_tuples(columns)这样ok了
原文链接:https://blog.csdn.net/yixinluobo/article/details/120561765
1、pandas写入excel多级表头,采用笛卡尔积方法#写入header2多级表头
array=[[875,76750,123,12356],[876,67543,124,98765],[877,98076,125,65432]]
header2=pd.DataFrame(array,index=['1','2','3'])
header2.columns=pd.MultiIndex.from_product([['jd','tb'],['销量','销售额']])
header2.index.name='月份'
print(header2)
header2.to_excel('header2.xlsx')
写入excel后表头和内容中间会多出一行,此项还未解决。
2、多级索引方法:采用zip函数
#多级索引
arrays = [["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
["one", "two", "one", "two", "one", "two", "one", "two"]]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples)
print(index)
3、to_excel与ExcelWriter()主要不同之处:
to_excel只能写入一个sheet;
ExcelWriter()可以同时写入多个sheet。
df1=pd.DataFrame({
'日期':[dt.datetime(2021,1,1),dt.datetime(2021,1,2)],
'销量':[23,45]
})
print(df1)
df2=pd.DataFrame({
'日期':[dt.datetime(2021,5,1),dt.datetime(2021,5,2)],
'销量':[145,786]
})
df2.index=['a','b']
df2.index.name='货号' #注意df2的索引顺序不能换,先确定索引值,后确定索引列标题
print(df2)
#ExcelWriter可以写入多个sheet,to_excel只能写入一个sheet
with pd.ExcelWriter('tbb.xlsx',datetime_format='YYYY-MM-DD') as writer:
df1.to_excel(writer,sheet_name='2020年',index=False)
df2.to_excel(writer,sheet_name='2021年')
原文链接:https://blog.csdn.net/weilansky91/article/details/116084236
修改excel,表头重复的会自动加小数点
if __name__ == '__main__':
import pandas as pd
excel_name = r"C:\Users\ThinkPad\Desktop\tmp\你好2!.xlsx"
column_str = 'g'
sheet_name = 'Sheet1'
df_excel= pd.read_excel(excel_name, sheet_name=sheet_name,header=0)
start=time.time()
cls_header = [chr(i) for i in range(97, 123)]
# with pd.ExcelWriter(excel_name, datetime_format='YYYY-MM-DD') as writer:
data2=[]
col_index=cls_header.index(column_str.lower())+1
for index, data in enumerate(df_excel.itertuples()):
data2.append(pd.Series(data[1:], index=df_excel.columns))
if data[col_index]>1:
for i in range(int(data[col_index])):
data2.append(pd.Series(['' for i in range(len(df_excel.columns))], index=df_excel.columns))
print("get file exists time", round(time.time() - start,2),'s')
gdp4 = pd.concat(data2, axis=1)
df_label = gdp4.T
with pd.ExcelWriter(excel_name) as writer:
df_label.to_excel(writer, sheet_name,index=False)修改excel,解决表头重复的问题
解决方法:读取时候不要表头,自动会出现计数表头,保存也不要表头
会丢失格式信息
if __name__ == '__main__':
import pandas as pd
excel_name = r"C:\Users\ThinkPad\Desktop\tmp\你好2!.xlsx"
column_str = 'g'
sheet_name = 'Sheet1'
df_excel= pd.read_excel(excel_name, sheet_name=sheet_name,header=None)
start=time.time()
cls_header = [chr(i) for i in range(97, 123)]
# with pd.ExcelWriter(excel_name, datetime_format='YYYY-MM-DD') as writer:
data2=[]
col_index=cls_header.index(column_str.lower())+1
for index, data in enumerate(df_excel.itertuples()):
data2.append(pd.Series(data[1:], index=df_excel.columns))
if data[col_index]>1:
for i in range(int(data[col_index])):
data2.append(pd.Series(['' for i in range(len(df_excel.columns))], index=df_excel.columns))
print("get file exists time", round(time.time() - start,2),'s')
gdp4 = pd.concat(data2, axis=1)
df_label = gdp4.T
with pd.ExcelWriter(excel_name) as writer:
df_label.to_excel(writer, sheet_name,index=False,header=None)
4、指定读取格式
pd.read_excel('fake2excel.xlsx', index_col=0, dtype={'age': float})在对数据处理精度要求比较高或者速度要求比较快的情况下。
pd.read_excel('fake2excel.xlsx', index_col=0, dtype={'age': float})
# 使用dtype,指定某一列的数据类型。
结果如下图所示:
-
我们添加了一列:年龄,本来是整数,但是指定float类型之后,读取出来成了小书。
-
这种读取,更适合对数据有特殊要求的情况,例如:金融行业。
pandas to_excel 修改excel样式以及格式
转自:
pandas to_excel 修改excel样式以及格式 - 冻雨冷雾 - 博客园
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 11:29:39 2021
@author: tianwz
"""
import pandas as pd
from datetime import datetime,timedelta
import time
time_now=datetime.now()
time_now=time_now.strftime("%Y-%m-%d")
df_excel=pd.read_excel('D平台项目三电售后问题管控表_分类结果_'+time_now+'.xlsx',sheet_name=None)
writer = pd.ExcelWriter('D平台项目三电售后问题管控表_分类结果_'+time_now+'格式处理.xlsx') # 此处engine="xlsxwriter"
for sheet_name in df_excel.keys():
print('正在定制: '+sheet_name)
df=pd.read_excel('D平台项目三电售后问题管控表_分类结果_'+time_now+'.xlsx',sheet_name=sheet_name,index_col=0)
df=df.drop('发生时间',axis=1)
workbook = writer.book
# percent_fmt = workbook.add_format({'num_format': '0.00%'})
# amt_fmt = workbook.add_format({'num_format': '#,##0'})
border_format = workbook.add_format({'border': 1})
# example_fmt = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'red','font_strikeout':True,
# 'align': 'center', 'valign': 'vcenter','underline':True})
# date_fmt = workbook.add_format({'bold': False, 'font_name': u'阿里巴巴普惠体', 'num_format': 'yyyy-mm-dd'})
# date_fmt1 = workbook.add_format({'bold': True, 'font_size': 10, 'font_name': u'阿里巴巴普惠体',
# 'num_format': 'yyyy-mm-dd', 'bg_color': '#9FC3D1',
# 'valign': 'vcenter', 'align': 'center'})
highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2', 'num_format': '0.00%'})
l_end = len(df.index) + 2 # 表格的行数,便于下面设置格式
df.to_excel(writer, sheet_name=sheet_name, encoding='utf8', header=False, index=False,startrow=1)# startcol=0, startrow=2
worksheet1 = writer.sheets[sheet_name]
fmt = workbook.add_format({"font_name": u"阿里巴巴普惠体","font_size":9,'valign': 'vcenter','align': 'center'})
for col_num, value in enumerate(df.columns.values):
worksheet1.write(0, col_num, value, fmt) #列名称写入
# 设置列宽以及格式
worksheet1.set_column('A:T',10, fmt)
worksheet1.set_column('A:A',8, fmt)
worksheet1.set_column('B:B',4, fmt)
worksheet1.set_column('C:C',7, fmt)
worksheet1.set_column('D:D',3, fmt)
worksheet1.set_column('E:E',2, fmt)
worksheet1.set_column('I:I',2, fmt)
worksheet1.set_column('H:H',6, fmt)
worksheet1.set_column('K:K',7, fmt)
worksheet1.set_column('L:L',6, fmt)
fmt = workbook.add_format({"font_name": u"阿里巴巴普惠体","font_size":9,'valign': 'vcenter','align': 'left'})
worksheet1.set_column('J:J',40, fmt)
worksheet1.set_column('P:P',30, fmt)
# 设置具体的样式规则
fmt = workbook.add_format({"font_name": u"阿里巴巴普惠体","font_size":9,'bg_color': '#C5D9F1'})
worksheet1.conditional_format('A1:B1', {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
fmt = workbook.add_format({"font_name": u"阿里巴巴普惠体","font_size":9,'bg_color': '#DAEEF3'})
worksheet1.conditional_format('C1:I1', {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
worksheet1.conditional_format('K1:O1', {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
worksheet1.conditional_format('Q1:S1', {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
fmt = workbook.add_format({"font_name": u"阿里巴巴普惠体","font_size":9,'bg_color': '#FAF0E7'})
worksheet1.conditional_format('J1:J%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
worksheet1.conditional_format('P1:P%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '', 'format': fmt})
note_fmt = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'red','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':True})
note_fmt1 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'orange','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False})
note_fmt2 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'gray','font_strikeout':True,
'align': 'center', 'valign': 'vcenter','underline':False})
note_fmt3 = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'#a7324a','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':2})
# worksheet1.conditional_format('H2:H%d' % l_end, {'type': 'formula', 'criteria': '', 'format': note_fmt})
# worksheet1.conditional_format('A2:A%d' % l_end, {'type': 'cell', 'criteria': '=', 'value': 38, 'format': note_fmt})
worksheet1.conditional_format('A2:A%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '新发问题', 'format': note_fmt})
worksheet1.conditional_format('A2:A%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '历史问题', 'format': note_fmt1})
worksheet1.conditional_format('A2:A%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '外部因素', 'format': note_fmt2})
worksheet1.conditional_format('A2:A%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '首发问题', 'format': note_fmt3})
note_fmt = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'white','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#FF0000'})
note_fmt1 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'yellow'})
note_fmt2 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#92D050'})
note_fmt3 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#00B050'})
worksheet1.conditional_format('C2:C%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '原因分析', 'format': note_fmt})
worksheet1.conditional_format('C2:C%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '对策实施', 'format': note_fmt1})
worksheet1.conditional_format('C2:C%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '预关闭', 'format': note_fmt2})
worksheet1.conditional_format('C2:C%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '关闭', 'format': note_fmt3})
note_fmt = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#FCD5B4'})
worksheet1.conditional_format('G2:G%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '电池', 'format': note_fmt})
note_fmt1 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#C5D9F1'})
worksheet1.conditional_format('G2:G%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '电驱', 'format': note_fmt1})
# worksheet1.conditional_format('N2:N%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': 'SQE电驱', 'format': note_fmt1})
note_fmt2 = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'#D8E4BC'})
worksheet1.conditional_format('G2:G%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '系统集成', 'format': note_fmt2})
# worksheet1.conditional_format('N2:N%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': 'SQE系统集成', 'format': note_fmt2})
note_fmt = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'orange','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'white'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '充电异常', 'format': note_fmt})
note_fmt = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'#C00000','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'white'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '限功率', 'format': note_fmt})
note_fmt = workbook.add_format({'bold':False,'font_name':u'阿里巴巴普惠体','font_color':'#C00000','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':True,'bg_color':'white'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '上电失败', 'format': note_fmt})
note_fmt = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'#C00000','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':2,'bg_color':'white'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '行车失去动力', 'format': note_fmt})
note_fmt = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':False,'bg_color':'red'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '电池热失控', 'format': note_fmt})
note_fmt = workbook.add_format({'bold':True,'font_name':u'阿里巴巴普惠体','font_color':'black','font_strikeout':False,
'align': 'center', 'valign': 'vcenter','underline':2,'bg_color':'white'})
worksheet1.conditional_format('Q2:Q%d' % l_end, {'type': 'text', 'criteria': 'containing', 'value': '碰撞', 'format': note_fmt})
writer.save()实现条件格式:
转自:https://www.jianshu.com/p/44b8dee3cdb0
df.style.format('{:.1f}',subset='均值').set_caption('高三(5)班期末考试成绩').\
hide_index().hide_columns(['索引']).bar('语文',vmin=0).highlight_max('均值').\
background_gradient('Greens',subset='数学').highlight_null()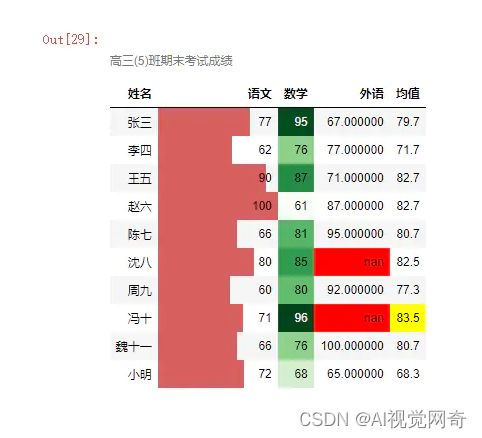
条件格式测试可以用:
if __name__ == '__main__':
import pandas as pd
import numpy as np
df =pd.read_excel(r'C:\Users\Administrator\Desktop\tmp\你好2!.xlsx')
df.style.highlight_null().render().split('\n')[:10]
df.style.background_gradient("Greens", subset="aa")
df.style.bar("Fare", vmin=0).background_gradient("Greens", subset="bb").highlight_null()
# df.to_excel("aaa.xlsx", "aaa", index=False)
# df.to_excel("aaa.xlxs")
writer = pd.ExcelWriter("log_1.xlsx", engine='xlsxwriter')
# 保存到本地excel
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
fmt = workbook.add_format({"font_name": u"微软雅黑"})
worksheet.set_column('A:E', 15, fmt)
border_format = workbook.add_format({'border': 1})
l_end = len(df.index) + 2
# highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2', 'num_format': '0.00%'})
highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2', 'num_format': '0.0'})
# 有条件设定表格格式:高亮百分比
worksheet.conditional_format('A2:A%d' % l_end,
{'type': 'cell', 'criteria': '>', 'value': 0.1, 'format': highlight_fmt})
worksheet.conditional_format('A1:E%d' % l_end, {'type': 'no_blanks', 'format': border_format})
# 3.设置格式
header_format = workbook.add_format({'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
})
header_format1 = workbook.add_format({'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
'text_wrap': True})
worksheet.set_column("A:A", 15, header_format)
worksheet.set_column("B:C", 10, header_format1)
worksheet.set_column("D:D", 15, header_format)
worksheet.set_default_row(20) # 设置所有行高
worksheet.set_row(0, 15, header_format) # 设置指定行
writer.save()
writer.close()