C++——const、指针和引用,深度理解
const修饰符
const修饰符可以定义常量,相比define,const修饰的常量的类型更为确定,而不是文本替换。在 C++ 中,const 也可以修饰对象。且一旦将对象定义为常对象之后,就只能调用类的 const 成员(包括 const 成员变量和 const 成员函数),因为const对象的非const成员可能修改对象的数据,这是不安全的,我们希望const对象的数据无论如何都不被修改,因此会被限定访问权限。
const和指针
const int类型的指针
int num1 = 10;
int num2 = 20;
int* pNum1 = &num1;
// 这是一个指针,指向的数据类型是int
// 这个的权限没有变化,因此可以正常读写和修改指向。
*pNum1 = 20;
pNum1 = &num2;
const int* pNum2 = &num1;
// 这是一个指针,指向的数据类型是const int。
// 把数据的int权限限定为const。
// 因此无法修改指针的内容,但是可以修改指向。
*pNum2 = 20;//error
pNum2 = &num2;
常量指针
const int num1 = 10;
const int num2 = 20;
int num3 = 30;
const int* pNum1 = &num1;
// 这是一个指针,指向的数据类型是const int。
// 数据类型没有变化,因此访问权限跟num1本身一样。
// 无法修改值,但是可以修改指针的指向。
pNum1 = &num2;
pNum1 = &num3;// 这里涉及权限的缩小,把原来num3的权限缩小为const。
num1 = 20;//error
*pNum1 = 20;//error
int* pNum2 = &num1;//error
// 这是一个指向int的指针,但是指向了const int类型的num1
// 涉及权限的放大,这是不允许的。
指针常量
int num1 = 10;
int num2 = 20;
int* const pNum1 = &num1;
// 这是一个const指针pNum1,指向的数据类型是int*。
// 因此这个指针的内容因为是int所以可以修改,
// 但是指向不能修改,因为这是一个指针常量。
pNum1 = &num2;//error
*pNum1 = 30;
这块内容比较晦涩,需要反复记忆和理解,不然及其容易遗忘。写这篇文章的原因就是因为这个知识点遗忘太多次了,以我为戒!
引用
对于像 char、bool、int、float 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组、结构体、对象是一系列数据的集合,数据的数量可能成千上万,频繁的内存拷贝会消耗很多时间,降低程序的效率。
C和C++ 禁止在函数调用时直接传递数组的内容,而是强制传递数组指针。而对于结构体和对象没有这种限制,调用函数时既可以传递指针,也可以直接传递内容;为了提高效率,传递指针少去了结构体和对象内容拷贝的时间。
但在 C++ 中,我们有了一种比指针更加便捷的传递聚合类型数据的方式,那就是引用(Reference)。引用是C++对C语言的重要扩充。引用就是某一变量(目标)的别名,对引用的操作与对变量直接操作完全一样。通过这个别名和原来的名字都能够找到这份数据。引用类似于 Windows 中的快捷方式和Linux中的软链接,一个可执行程序可以有多个快捷方式,但是一个快捷方式不能改变指向的可执行程序。
我们知道,参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
引用必须在定义的同时初始化,并且以后不能再引用其它对象,这有点类似于常量(const 变量)。
int num1 = 10;
int& ref0; //error
int& ref1 = 20;//error
int&& ref2 = 20;// 右值引用
int& ref3 = num1;// 左值引用
// num1 和 ref3 地址相同,是同一个对象
int num2 = 30;
ref3 = num2; // 等价于 num1 = 30;
// 实际是修改了ref3引用的num1的值,而不是把num3重定向为num4的引用
string str1 = "Hello";
string& str2 = str1;
// str1和str2地址相同
指针和引用
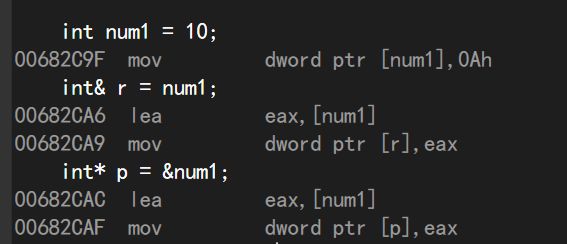
指针是一个变量,能够在监视窗口中获取到指针的地址。而获取引用的地址实际是获取被引用对象的地址。

这样看起来好像引用并不占内存空间,实际上,在编译时,编译器会把引用视作一个const指针,即是一个指向不可变的指针。引用实际上与指针同样占用内存空间!这点可以在程序的汇编代码中看出。
指针数组和引用数组
当我们拥有一批指针,可以用一个这种指针类型的数组来存储这批指针。
int num1 = 10;
int* p1 = &num1;
int* p2 = &num1;
int* p3 = &num1;
int* p4 = &num1;
int* parr[4] = { p1,p2,p3,p4 };
但是如果引用按照同样的方式会报错
int& r1 = num1;
int& r2 = num1;
int& r3 = num1;
int& r4 = num1;
int& ref[4] = { r1,r2,r3,r4 };//error
因为数组是一个由若干个元素所组成的集合,所以无法建立一个由引用组成的集合。但是可以建立数组的引用。
const int (&ref)[4] = { r1,r2,r3,r4 };
为什么要加上const ?因为 { r1, r2 , r3 , r4 } 此时是个字面值数组,是保存在代码段里的只读内容,如果不加,编译会报错。而且也不能修改数组的内容。
string str1 = "Hello";
string& sr1 = str1;
string& sr2 = str1;
string& sr3 = str1;
const string(&ref1)[] = { sr1,sr2,sr3 };
指针和引用的区别
- 引用定义时必须初始化,指针不需要。没有空引用,但有空指针。
- 引用指定一个对象后,不能再引用其他对象;指针可以指向任意同类型对象。
- sizeof:引用的结果为被引用类型的大小,而不是对象的大小;指针始终是地址空间所占字节个数(32位平台下占4个字节)。
- 引用自增相当于被引用对象执行加一操作;指针自增是向后偏移一个该类型大小的字节。
- 有多级指针,但是没有多级引用。
- 访问数据时指针要解引用,引用不需要。
- 引用更为安全,不存在野引用。
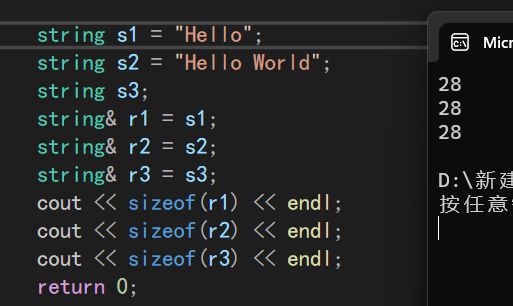
对于第三点的补充。
引用的使用场景
普通值传递参数和返回值时,不会传递实参本身,而是传递实参的一份内存中的临时拷贝,所以当遇到数据量非常大的结构时,效率会很低下,引用作为函数参数和返回值会有很大的改善(假设返回的是堆上的对象,如果是栈上的对象涉及右值引用)。
引用作函数参数
在定义或声明函数时,我们可以将函数的形参指定为引用,这样在调用函数时就会将实参和形参绑定在一起,让它们都指代同一份数据。如果修改了形参的数据,那么实参的数据也会被修改。从而和指针传参一样实现在函数内部修改函数和外部参数的效果。
template<typename T>
void swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
引用作返回值
引用除了可以作为函数形参,还可以作为函数返回值,在将引用作为函数返回值时应该注意不能返回局部数据的引用(例如局部变量、局部对象、局部数组等),因为当函数调用完成后局部数据就会被销毁,有可能在下次使用时数据就不存在或被覆盖了。返回的数据必须是被static修饰的静态变量、或全局变量、或动态开辟的内存数据等不会随着函数调用的结束而被销毁的数据。
int& test(int num)
{
int newNum = num + num;
return newNum; //返回局部数据的引用
}
这样的结果在不同的编译器下会不可预料。
int& add(int a, int b)
{
int c = 0;
c = a + b;
return c;
}
int main()
{
int& ref = add(10, 20);
cout << ref << endl;
add(20, 30);
cout << ref << endl;
cout << ref << endl;
cout << ref << endl;
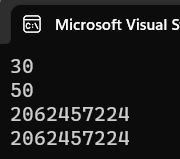
因为调用函数会创建函数栈帧,之后再调用函数,创建的栈帧可能将之前的覆盖了,但是ref还是之前内存内容的引用,因此可能会被覆盖和修改!
const和引用
const和引用的情况相比const和指针简单很多,因为少去了指向修改的问题。
int num1 = 10;
const int& ref1 = num1;
ref1 = 20;//error 常引用不可修改
const int num2 = 20;
const int& ref2 = 20;
const int& ref3 = num2;
int& ref4 = num2;//error 涉及权限放大
右值引用
右值引用是C++11引入的用于补齐C++在内存效率上的短板的,在某些场景,例如STL中string的operator + 操作,push_back操作如果没有右值引用,都会产生深拷贝,避免不了效率的问题。
我将会写一篇文章详细讲解C++11的新特性,如右值引用,移动语义等!