JAVA并发十二连招,你能接住吗?(建议收藏!!)
话不多说,干货走起。
1、HashMap

面试第一题必问的 HashMap,挺考验Javaer的基础功底的,别问为啥放在这,因为重要!HashMap具有如下特性:
- HashMap 的存取是没有顺序的。
- KV 均允许为 NULL。
- 多线程情况下该类安全,可以考虑用 HashTable。
- JDk8底层是数组 + 链表 + 红黑树,JDK7底层是数组 + 链表。
- 初始容量和装载因子是决定整个类性能的关键点,轻易不要动。
- HashMap是懒汉式创建的,只有在你put数据时候才会 build。
- 单向链表转换为红黑树的时候会先变化为双向链表最终转换为红黑树,切记双向链表跟红黑树是共存的。
- 对于传入的两个key,会强制性的判别出个高低,目的是为了决定向左还是向右放置数据。
- 链表转红黑树后会努力将红黑树的root节点和链表的头节点 跟table[i]节点融合成一个。
- 在删除的时候是先判断删除节点红黑树个数是否需要转链表,不转链表就跟RBT类似,找个合适的节点来填充已删除的节点。
- 红黑树的root节点不一定跟table[i]也就是链表的头节点是同一个,三者同步是靠MoveRootToFront实现的。而HashIterator.remove()会在调用removeNode的时候movable=false。
常见HashMap考点:
- HashMap原理,内部数据结构。
- HashMap中的put、get、remove大致过程。
- HashMap中 hash函数实现。
- HashMap如何扩容。
- HashMap几个重要参数为什么这样设定。
- HashMap为什么线程不安全,如何替换。
- HashMap在JDK7跟JDK8中的区别。
- HashMap中链表跟红黑树切换思路。
- JDK7中 HashMap环产生原理。
2、ConcurrentHashMap
ConcurrentHashMap 是多线程模式下常用的并发容器,它的实现在JDK7跟JDK8区别挺大的。
2.1 JDK7
JDK7中的 ConcurrentHashMap 使用 Segment + HashEntry 分段锁实现并发,它的缺点是并发程度是由Segment 数组个数来决定的,并发度一旦初始化无法扩容,扩容的话只是HashEntry的扩容。

Segment 继承自 ReentrantLock,在此扮演锁的角色。可以理解为我们的每个Segment都是实现了Lock功能的HashMap。如果我们同时有多个Segment形成了Segment数组那我们就可以实现并发咯。
大致的put流程如下
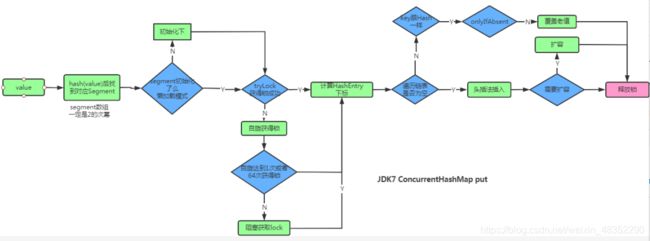
1.ConcurrentHashMap底层大致实现?
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的HashTable,只要多个修改操作发生在不同的段上就可以并发进行。
2.ConcurrentHashMap在并发下的情况下如何保证取得的元素是最新的?
用于存储键值对数据的HashEntry,在设计上它的成员变量value跟next都是volatile类型的,这样就保证别的线程对value值的修改,get方法可以马上看到,并且get的时候是不用加锁的。
3.ConcurrentHashMap的弱一致性体现在clear和get方法,原因在于没有加锁。
比如迭代器在遍历数据的时候是一个Segment一个Segment去遍历的,如果在遍历完一个Segment时正好有一个线程在刚遍历完的Segment上插入数据,就会体现出不一致性。clear也是一样。get方法和containsKey方法都是遍历对应索引位上所有节点,都是不加锁来判断的,如果是修改性质的因为可见性的存在可以直接获得最新值,不过如果是新添加值则无法保持一致性。
4.size 统计个数不准确
size方法比较有趣,先无锁的统计所有的数据量看下前后两次是否数据一样,如果一样则返回数据,如果不一样则要把全部的segment进行加锁,统计,解锁。并且size方法只是返回一个统计性的数字。
2.2 JDK8
ConcurrentHashMap 在JDK8中抛弃了分段锁,转为用 CAS +synchronized,同时将HashEntry改为Node,还加入了红黑树的实现,主要还是看put的流程(如果看了扩容这块,绝对可以好好吹逼一番)。

ConcurrentHashMap 是如果来做到高效并发安全?
1.读操作
get方法中根本没有使用同步机制,也没有使用unsafe方法,所以读操作是支持并发操作的。
2.写操作
基本思路跟HashMap的写操作类似,只不过用到了CAS + syn实现加锁,同时还涉及到扩容的操作。JDK8中锁已经细化到table[i] 了,数组位置不同可并发,位置相同则去帮忙扩容。
3.同步处理主要是通过syn和unsafe的硬件级别原子性这两种方式完成
1.当我们对某个table[i]操作时候是用syn加锁的。
2.取数据的时候用的是unsafe硬件级别指令,直接获取指定内存的最新数据。
3 、并发基础知识
并发编程的出发点:充分利用CPU计算资源,多线程并不是一定比单线程快,要不为什么Redis6.0版本的核心操作指令仍然是单线程呢?对吧!
多线程跟单线程的性能都要具体任务具体分析,talk is cheap, show me the picture。
3.1 进程跟线程
进程:
进程是操作系统调用的最小单位,是系统进行资源分配和调度的独立单位。
线程:
- 因为进程的创建、销毁、切换产生大量的时间和空间的开销,进程的数量不能太多,而线程是比进程更小的能独立运行的基本单位,他是进程的一个实体,是CPU调度的最小单位。线程可以减少程序并发执行时的时间和空间开销,使得操作系统具有更好的并发性。
2.线程基本不拥有系统资源,只有一些运行时必不可少的资源,比如程序计数器、寄存器和栈,进程则占有堆、栈。线程,Java默认有两个线程 main跟GC。Java是没有权限开线程的,无法操作硬件,都是调用的 native 的 start0 方法 由 C++ 实现
3.2 并行跟并发
并发:
concurrency : 多线程操作同一个资源,单核CPU极速的切换运行多个任务
并行:
parallelism :多个CPU同时使用,CPU多核 真正的同时执行
3.3 线程几个状态

Java中线程的状态分为6种:
1.初始(New):
新创建了一个线程对象,但还没有调用start()方法。
2.可运行(Runnable):
1.调用线程的start()方法,此线程进入就绪状态。就绪状态只是说你资格运行,调度程序没有给你CPU资源,你就永远是就绪状态。
2.当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。
3.当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。
4.锁池里的线程拿到对象锁后,进入就绪状态。
3.运行中(Running)
就绪状态的线程在获得CPU时间片后变为运行中状态(running)。这也是线程进入运行状态的唯一的一种方式。
4.阻塞(Blocked):
阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
5.等待(Waiting) 跟 超时等待(Timed_Waiting):
1.处于这种状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒(通知或中断),否则会处于无限期等待的状态。
2.处于这种状态的线程不会被分配CPU执行时间,不过无须无限期等待被其他线程显示地唤醒,在达到一定时间后它们会自动唤醒。
6.终止(Terminated):
当线程正常运行结束或者被异常中断后就会被终止。线程一旦终止了,就不能复生。
PS:
1.调用 obj.wait 的线程需要先获取 obj 的 monitor,wait会释放 obj 的monitor 并进入等待态。所以 wait()/notify() 都要与 synchronized联用。
2.其实线程从阻塞/等待状态 到 可运行状态都涉及到同步队列跟等待队列的,这点在 AQS 有讲。
3.4. 阻塞与等待的区别
阻塞:
当一个线程试图获取对象锁(非JUC库中的锁,即synchronized),而该锁被其他线程持有,则该线程进入阻塞状态。它的特点是使用简单,由JVM调度器来决定唤醒自己,而不需要由另一个线程来显式唤醒自己,不响应中断。
等待:
当一个线程等待另一个线程通知调度器一个条件时,该线程进入等待状态。它的特点是需要等待另一个线程显式地唤醒自己,实现灵活,语义更丰富,可响应中断。例如调用:Object.wait()、**Thread.join()**以及等待Lock 或 Condition。
虽然 synchronized 和 JUC 里的 Lock 都实现锁的功能,但线程进入的状态是不一样的。synchronized 会让线程进入阻塞态,而 JUC 里的 Lock是用park()/unpark() 来实现阻塞/唤醒 的,会让线程进入等待状态。虽然等锁时进入的状态不一样,但被唤醒后又都进入Runnable状态,从行为效果来看又是一样的。
3.5 yield 跟 sleep 区别
- yield 跟 sleep 都能暂停当前线程,都不会释放锁资源,sleep 可以指定具体休眠的时间,而 yield 则依赖 CPU的时间片划分。
- sleep方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会。yield方法只会给相同优先级或更高优先级的线程以运行的机会。
- 调用 sleep 方法使线程进入等待状态,等待休眠时间达到,而调用我们的yield方法,线程会进入就绪状态,也就是sleep需要等待设置的时间后才会进行就绪状态,而yield会立即进入就绪状态。
- sleep方法声明会抛出 InterruptedException,而 yield 方法没有声明任何异常
- yield 不能被中断,而sleep 则可以接受中断。
- sleep方法比yield方法具有更好的移植性(跟操作系统CPU调度相关)
3.6 wait 跟 sleep 区别
1.来源不同
wait 来自Object,sleep 来自 Thread
2.是否释放锁
wait 释放锁,sleep 不释放
3.使用范围
wait 必须在同步代码块中,sleep 可以任意使用
4.捕捉异常
wait 不需要捕获异常,sleep 需捕获异常
3.7 多线程实现方式
- 继承 Thread,实现run方法
- 实现 Runnable接口中的run方法,然后用Thread包装下。Thread是线程对象,Runnable 是任务,线程启动的时候一定是对象。
- 实现 Callable接口,FutureTask包装实现接口&