几种分布式锁详解
文章目录
- 一、简介
-
- 1、介绍
- 2、超卖问题简述
- 二、传统锁
-
- 1、JVM锁
-
- 1.1 添加jvm锁
- 1.2 原理
- 1.3 失效场景
- 2、MySQL锁
-
- 2.1 简介
- 2.2 悲观锁+ @Transactional
- 2.3 乐观锁
- 2.4 总结
- 3、Redis乐观锁
- 三、基于Redis实现分布式锁
-
- 1、Redis的Lua脚本
-
- 1.1 介绍
- 1.2 Lua基本使用
- 1.3 redis执行 - EVAL指令
- 1.4 使用lua保证删除原子性
- 2、Redis分布式锁基本实现
-
- 2.1基本实现
- 2.2 防死锁
- 2.3 防误删
- 2.4 可重入锁
-
- 可重入锁原理
- redis模拟可重入锁
- 2.5 自动续期
- 2.6 手写分布式锁小结
- 3、红锁算法
- 四、Redission分布式锁
-
- 1、redission介绍
- 2、Redisson原理介绍
-
- 2.1 介绍
- 2.2 分布式锁原理
- 3、可重入锁(Reentrant Lock)
- 4、公平锁(Fair Lock)
- 5、联锁(MultiLock)
- 6、红锁(RedLock)
- 7、读写锁(ReadWriteLock)
- 8、信号量(Semaphore)
- 9、闭锁(CountDownLatch)
- 五、基于zookeeper实现分布式锁
-
- 1、zk介绍
-
- 1.1 安装启动
- 1.2 相关概念
- 1.3 Java客户端
- 2、ZK分布式锁基本实现
-
- 2.1 思路分析
- 2.2 基本实现
- 2.3 性能优化(阻塞非自旋)
- 2.4 优化:可重入锁
- 2.5 小结
- 3、Curator中的分布式锁
-
- 3.1 简介
- 3.2 依赖引入与配置
- 3.3 可重入锁InterProcessMutex
- 3.4 不可重入锁InterProcessSemaphoreMutex
- 3.5 可重入读写锁InterProcessReadWriteLock
- 3.6 联锁InterProcessMultiLock
- 3.7 信号量InterProcessSemaphoreV2
- 3.8 栅栏barrier
- 3.9 共享计数器
- 六、基于mysql实现分布式锁
-
- 1、介绍
- 2、基本思路
- 3、代码实现
- 4、缺陷和解决方
- 七、总结
一、简介
1、介绍
在应用开发中,特别是web工程开发,通常都是并发编程,不是多进程就是多线程。这种场景下极易出现线程并发性安全问题,此时不得不使用锁来解决问题。在多线程高并发场景下,为了保证资源的线程安全问题,jdk为我们提供了synchronized关键字和ReentrantLock可重入锁,但是它们只能保证一个工程内的线程安全。在分布式集群、微服务、云原生横行的当下,如何保证不同进程、不同服务、不同机器的线程安全问题,jdk并没有给我们提供既有的解决方案。目前主流的实现有以下方式:
-
基于mysql关系型实现
-
基于redis非关系型数据实现
-
基于zookeeper/etcd实现
2、超卖问题简述
多线程并发安全问题最典型的代表就是超卖现象库存在并发量较大情况下很容易发生超卖现象,一旦发生超卖现象,就会出现多成交了订单而发不了货的情况
商品S库存余量为5时,用户A和B同时来购买一个商品,此时查询库存数都为5,库存充足则开始减库存:
用户A:update db_stock set stock = stock - 1 where id = 1;用户B:update db_stock set stock = stock - 1 where id = 1。并发情况下,更新后的结果可能是4,而实际的最终库存量应该是3才对
(可以自己搭建,用JMeter进行压力测试)
二、传统锁
1、JVM锁
1.1 添加jvm锁
使用jvm锁(synchronized关键字或者ReetrantLock),ReetrantLock比较轻量
@Service
public class StockService {
@Autowired
private StockMapper stockMapper;
private ReentrantLock lock = new ReentrantLock();
public synchronized void deduct() {
// lock.lock();
try {
Stock stock = stockMapper.selectOne(new QueryWrapper<Stock>().eq("product_code", "1001"));
if (stock != null && stock.getCount() > 0) {
stock.setCount(stock.getCount() - 1);
stockMapper.updateById(stock);
}
} finally {
// lock.unlock();
}
}
}
1.2 原理
添加synchronized关键字之后,StockService就具备了对象锁,由于添加了独占的排他锁,同一时刻只有一个请求能够获取到锁,并减库存。此时,所有请求只会one-by-one执行下去,也就不会发生超卖现象
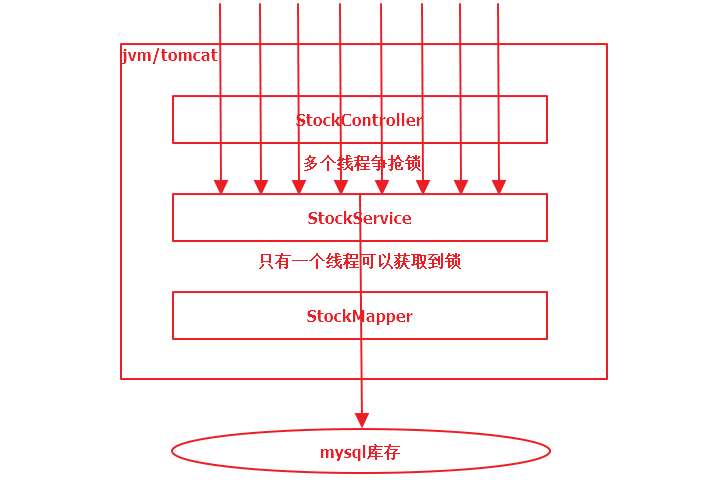
1.3 失效场景
-
当添加为多例模式
@Scope(value = "prototype",proxyMode = ScopedProxyMode.TARGET_CLASS)后,锁会失效(多例模式默认没有代理,如果需要就立刻创建;JDK代理基于接口,需要定义接口;CGLIB代理基于类,SpringBoot2.x后默认CGLIB,不需要写接口,只需要写实现类) -
当用Nginx代理,开启多个JVM也会失效
-
当时有
@Transactional和锁一起存在的时候,因为MySQL的默认隔离级别为RR,并发时前一个请求还未提交,后一个请求查询到未提交的数据,造成并发失效
2、MySQL锁
2.1 简介
除了使用jvm锁之外,还可以使用数据锁:悲观锁 或者 乐观锁
-
sql语句:直接更新时判断,在更新中判断库存是否大于0(比JVM锁快,但是是表级锁,且无法记录前后状态,只能一条语句);
update table set surplus = (surplus - buyQuantity) where id = 1 and (surplus - buyQuantity) > 0 ; -
悲观锁:在读取数据时锁住那几行,其他对这几行的更新需要等到悲观锁结束时才能继续(速度和JVM锁差不多);
select ... for update -
乐观锁:读取数据时不锁,更新时检查是否数据已经被更新过,如果是则取消当前更新进行重试;
version 或者 时间戳(CAS思想)
2.2 悲观锁+ @Transactional
悲观锁使用行级锁条件:
-
锁的查询或更新必须是索引字段
-
查询或更新条件必须是具体值
在SELECT 的读取锁定主要分为两种方式:
-
SELECT ... LOCK IN SHARE MODE(共享锁) -
SELECT ... FOR UPDATE(悲观锁,推荐)
这两种方式在事务(Transaction) 进行当中SELECT 到同一个数据表时,都必须等待其它事务数据被提交(Commit)后才会执行。而主要的不同在于LOCK IN SHARE MODE 在有一方事务要Update 同一个表单时很容易造成死锁。简单的说,如果SELECT 后面若要UPDATE 同一个表单,最好使用SELECT ... FOR UPDATE
注意:使用悲观锁时最好都使用SELECT ... FOR UPDATE,这样可以避免查询数据的不一致性,即脏数据;另外需要注意因为查询顺序不同造成的思死锁问题
2.3 乐观锁
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则重试。
使用数据版本(Version)记录机制实现,这是乐观锁最常用的实现方式。一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录 的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新。
// 这里不用加事务,否则会连接超时,MDL操作update会自动锁
public void checkAndLock() {
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
// 获取版本号
Long version = stock.getVersion();
stock.setCount(stock.getCount() - 1);
// 每次更新 版本号 + 1
stock.setVersion(stock.getVersion() + 1);
// 更新之前先判断是否是之前查询的那个版本,如果不是重试
if (this.stockMapper.update(stock, new UpdateWrapper<Stock>().eq("id", stock.getId()).eq("version", version)) == 0) {
// 可以睡眠一会
checkAndLock();
}
}
}
但是乐观锁在并发量越大的情况下,性能越低(因为需要大量的重试);并发量越小,性能越高;同时会产生ABA问题;读写分离情况下乐观锁不可靠
2.4 总结
性能:sql语句 > 悲观锁 > jvm锁 > 乐观锁。
如果追求极致性能、业务场景简单并且不需要记录数据前后变化的情况下,优先选择一个sql;如果写并发量较低(多读),争抢不是很激烈的情况下优先选择乐观锁;如果写并发量较高,一般会经常冲突,此时选择乐观锁的话,会导致业务代码不间断的重试,优先选择mysql悲观锁;不推荐jvm本地锁。
3、Redis乐观锁
利用redis监听 + 事务;如果执行过程中stock的值没有被其他连接改变,则执行成功;如果执行过程中stock的值被改变,则执行失败(性能较低,不推荐)
# watch可以监控个或者多个key的值,如果在事务(exec)执行之前,key的值发生变化则取消事务执行
watch stock
# 开启事务
multi
set stock 5000
# 执行事务
exec
对应spring代码
public void deduct() {
this.redisTemplate.execute(new SessionCallback() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
operations.watch("stock");
// 1. 查询库存信息
Object stock = operations.opsForValue().get("stock");
// 2. 判断库存是否充足
int st = 0;
if (stock != null && (st = Integer.parseInt(stock.toString())) > 0) {
// 3. 扣减库存
operations.multi();
operations.opsForValue().set("stock", String.valueOf(--st));
List exec = operations.exec();
if (exec == null || exec.size() == 0) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
deduct();
}
return exec;
}
return null;
}
});
}
三、基于Redis实现分布式锁
1、Redis的Lua脚本
1.1 介绍
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
可以参考:Nginx二次开发
Lua 特性
-
轻量级:它用标准C语言编写并以源代码形式开放,编译后仅仅一百余K,可以很方便的嵌入别的程序里。
-
可扩展:Lua提供了非常易于使用的扩展接口和机制:由宿主语言(通常是C或C++)提供这些功能,Lua可以使用它们,就像是本来就内置的功能一样。
-
其它特性:
-
支持面向过程(procedure-oriented)编程和函数式编程(functional programming);
-
自动内存管理;只提供了一种通用类型的表(table),用它可以实现数组,哈希表,集合,对象;
-
语言内置模式匹配;闭包(closure);函数也可以看做一个值;提供多线程(协同进程,并非操作系统所支持的线程)支持;
-
通过闭包和table可以很方便地支持面向对象编程所需要的一些关键机制,比如数据抽象,虚函数,继承和重载等。
-
因为MULTI/ EXEC方法来使用事务功能,将一组命令打包执行,无法进行业务逻辑的操作。这期间有某一条命令执行报错(例如给字符串自增),其他的命令还是会执行,并不会回滚,因此需要Lua脚本来保证原子性
1.2 Lua基本使用
a = 5 -- 全局变量
local b = 5 -- 局部变量, redis只支持局部变量
a, b = 10, 2*x -- 等价于 a=10; b=2*x
if( 布尔表达式 1)
then
--[ 在布尔表达式 1 为 true 时执行该语句块 --]
elseif( 布尔表达式 2)
then
--[ 在布尔表达式 2 为 true 时执行该语句块 --]
else
--[ 如果以上布尔表达式都不为 true 则执行该语句块 --]
end
1.3 redis执行 - EVAL指令
在redis中需要通过eval命令执行lua脚本
EVAL script numkeys key [key ...] arg [arg ...]
script:lua脚本字符串,这段Lua脚本不需要(也不应该)定义函数。
numkeys:lua脚本中KEYS数组的大小
key [key ...]:KEYS数组中的元素
arg [arg ...]:ARGV数组中的元素
案例举例
# 基本案例
EVAL "return 10" 0
# 动态传参,输出:0
EVAL "if KEYS[1] > ARGV[1] then return 1 else return 0 end" 1 10 20
# redis.call()中的redis是redis中提供的lua脚本类库,仅在redis环境中可以使用该类库
# 脚本里使用的所有键都应该由 KEYS 数组来传递,value一般用Args传递
# 通过return把call方法返回给redis客户端,打印:"10"
set aaa 10 # 设置一个aaa值为10
EVAL "return redis.call('get', 'aaa')" 0
EVAL "return redis.call('set', KEYS[1], ARGV[1])" 1 bbb 20
1.4 使用lua保证删除原子性
删除的Lua脚本
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end
代码实现,保证原子性
public void deduct() {
String uuid = UUID.randomUUID().toString();
// 加锁setnx
while (!this.redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS)) {
// 重试:循环
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
// this.redisTemplate.expire("lock", 3, TimeUnit.SECONDS);
// 1. 查询库存信息
String stock = redisTemplate.opsForValue().get("stock").toString();
// 2. 判断库存是否充足
if (stock != null && stock.length() != 0) {
Integer st = Integer.valueOf(stock);
if (st > 0) {
// 3.扣减库存
redisTemplate.opsForValue().set("stock", String.valueOf(--st));
}
}
} finally {
// 先判断是否自己的锁,再解锁
String script = "if redis.call('get', KEYS[1]) == ARGV[1] " +
"then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
this.redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList("lock"), uuid);
}
}
2、Redis分布式锁基本实现
参考:Redis接口限流、分布式锁与幂等
2.1基本实现
借助于redis中的命令setnx(key, value),key不存在就新增,存在就什么都不做。同时有多个客户端发送setnx命令,只有一个客户端可以成功,返回1(true);其他的客户端返回0(false)等待重试;获取锁成功的请求执行业务逻辑,执行完后释放锁
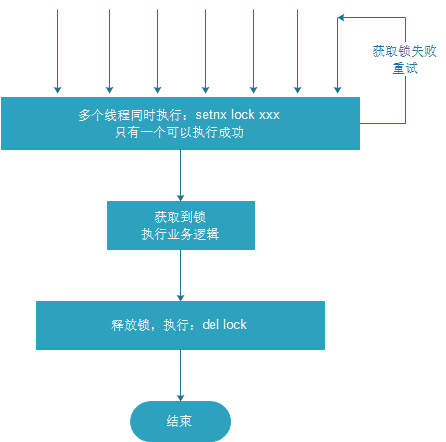
@Service
public class StockService {
@Autowired
private StockMapper stockMapper;
@Autowired
private StringRedisTemplate redisTemplate;
public void deduct() {
// 加锁setnx
Boolean lock = this.redisTemplate.opsForValue().setIfAbsent("lock", "111");
// 重试:递归调用
if (!lock){
try {
Thread.sleep(50);
this.deduct();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
try {
// 1. 查询库存信息
String stock = redisTemplate.opsForValue().get("stock").toString();
// 2. 判断库存是否充足
if (stock != null && stock.length() != 0) {
Integer st = Integer.valueOf(stock);
if (st > 0) {
// 3.扣减库存
redisTemplate.opsForValue().set("stock", String.valueOf(--st));
}
}
} finally {
// 解锁
this.redisTemplate.delete("lock");
}
}
}
}
其中加锁也可以使用循环
// 加锁,获取锁失败重试
while (!this.redisTemplate.opsForValue().setIfAbsent("lock", "111")){
try {
Thread.sleep(40);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
2.2 防死锁
产生原因:setnx刚刚获取到锁,当前服务器宕机,导致del释放锁无法执行,进而导致锁无法锁无法释放(死锁)
解决:给锁设置过期时间,自动释放锁。设置过期时间两种方式:
-
通过expire设置过期时间(缺乏原子性:如果在setnx和expire之间出现异常,锁也无法释放)
-
使用set指令设置过期时间:
set key value ex 3 nx(既达到setnx的效果,又设置了过期时间)
2.3 防误删
产生原因:锁到期可能会释放其他服务器的锁,但其业务逻辑还未处理完成
解决:上锁的时候加入UUID,删除的时候先查询,如果是自己的锁就进行删除,否则不做处理
2.4 可重入锁
可重入锁原理
可重入锁加锁流程:ReentrantLock.lock ()→Nonfairsync.lock()→AQS.acquire(1)→NonfairSync.tryAcquire(1)→Sync.nonfairTryAcquire(1)
-
CAS获取锁,如果没有线程占用锁(state==0),加锁成功并记录当前线程是有锁线程(两次)
-
如果state的值不为0,说明锁已经被占用。则判断当前线程是否是有锁线程,如果是则重入(state + 1)
-
否则加锁失败,入队等侍
可重入锁解锁流程:ReentrantLock.unlock()→Ags.release (1)→Sync.tryRelease(1)
-
判断当前线程是否是有锁线程,不是则抛出异常
-
对state的值减1之后,判断state的值是否为0,为0则解锁成功,返回true
-
如果减1后的值不为0,则返回false
redis模拟可重入锁
加锁脚本
Redis 提供了 Hash (哈希表)这种可以存储键值对数据结构。所以我们可以使用 Redis Hash 存储的锁的重入次数,然后利用 lua 脚本判断逻辑。
假设值为:KEYS:[lock], ARGV[uuid, expire]如果锁不存在或者这是自己的锁,就通过hincrby(不存在就新增并加1,存在就加1)获取锁或者锁次数加1。
if (redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[1], 1);
redis.call('expire', KEYS[1], ARGV[2]);
return 1;
else
return 0;
end
解锁脚本
-- 判断 hash set 可重入 key 的值是否等于 0
-- 如果为 nil 代表 自己的锁已不存在,在尝试解其他线程的锁,解锁失败
-- 如果为 0 代表 可重入次数被减 1
-- 如果为 1 代表 该可重入 key 解锁成功
if(redis.call('hexists', KEYS[1], ARGV[1]) == 0) then
return nil;
elseif(redis.call('hincrby', KEYS[1], ARGV[1], -1) > 0) then
return 0;
else
redis.call('del', KEYS[1]);
return 1;
end;
代码实现
DistributedLockClient工厂类具体实现
@Component
public class DistributedLockClient {
@Autowired
private StringRedisTemplate redisTemplate;
private String uuid;
public DistributedLockClient() {
this.uuid = UUID.randomUUID().toString();
}
public DistributedRedisLock getRedisLock(String lockName){
return new DistributedRedisLock(redisTemplate, lockName, uuid);
}
}
DistributedRedisLock实现
public class DistributedRedisLock implements Lock {
private StringRedisTemplate redisTemplate;
private String lockName;
private String uuid;
private long expire = 30;
public DistributedRedisLock(StringRedisTemplate redisTemplate, String lockName, String uuid) {
this.redisTemplate = redisTemplate;
this.lockName = lockName;
this.uuid = uuid;
}
@Override
public void lock() {
this.tryLock();
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
try {
return this.tryLock(-1L, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
/**
* 加锁方法
* @param time
* @param unit
* @return
* @throws InterruptedException
*/
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
if (time != -1){
this.expire = unit.toSeconds(time);
}
String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " +
"then " +
" redis.call('hincrby', KEYS[1], ARGV[1], 1) " +
" redis.call('expire', KEYS[1], ARGV[2]) " +
" return 1 " +
"else " +
" return 0 " +
"end";
while (!this.redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), getId(), String.valueOf(expire))){
Thread.sleep(50);
}
return true;
}
/**
* 解锁方法
*/
@Override
public void unlock() {
String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " +
"then " +
" return nil " +
"elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " +
"then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
Long flag = this.redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), getId());
if (flag == null){
throw new IllegalMonitorStateException("this lock doesn't belong to you!");
}
}
@Override
public Condition newCondition() {
return null;
}
/**
* 给线程拼接唯一标识
* @return
*/
String getId(){
return uuid + ":" + Thread.currentThread().getId();
}
}
使用测试
public void deduct() {
DistributedRedisLock redisLock = this.distributedLockClient.getRedisLock("lock");
redisLock.lock();
try {
// 1. 查询库存信息
String stock = redisTemplate.opsForValue().get("stock").toString();
// 2. 判断库存是否充足
if (stock != null && stock.length() != 0) {
Integer st = Integer.valueOf(stock);
if (st > 0) {
// 3.扣减库存
redisTemplate.opsForValue().set("stock", String.valueOf(--st));
}
}
} finally {
redisLock.unlock();
}
}
2.5 自动续期
lua脚本
if(redis.call('hexists', KEYS[1], ARGV[1]) == 1) then
redis.call('expire', KEYS[1], ARGV[2]);
return 1;
else
return 0;
end
在RedisDistributeLock中添加renewExpire方法
public class DistributedRedisLock implements Lock {
private StringRedisTemplate redisTemplate;
private String lockName;
private String uuid;
private long expire = 30;
public DistributedRedisLock(StringRedisTemplate redisTemplate, String lockName, String uuid) {
this.redisTemplate = redisTemplate;
this.lockName = lockName;
this.uuid = uuid + ":" + Thread.currentThread().getId();
}
@Override
public void lock() {
this.tryLock();
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
try {
return this.tryLock(-1L, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
/**
* 加锁方法
* @param time
* @param unit
* @return
* @throws InterruptedException
*/
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
if (time != -1){
this.expire = unit.toSeconds(time);
}
String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " +
"then " +
" redis.call('hincrby', KEYS[1], ARGV[1], 1) " +
" redis.call('expire', KEYS[1], ARGV[2]) " +
" return 1 " +
"else " +
" return 0 " +
"end";
while (!this.redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), uuid, String.valueOf(expire))){
Thread.sleep(50);
}
// 加锁成功,返回之前,开启定时器自动续期
this.renewExpire();
return true;
}
/**
* 解锁方法
*/
@Override
public void unlock() {
String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " +
"then " +
" return nil " +
"elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " +
"then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
Long flag = this.redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), uuid);
if (flag == null){
throw new IllegalMonitorStateException("this lock doesn't belong to you!");
}
}
@Override
public Condition newCondition() {
return null;
}
// String getId(){
// return this.uuid + ":" + Thread.currentThread().getId();
// }
private void renewExpire(){
String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 1 " +
"then " +
" return redis.call('expire', KEYS[1], ARGV[2]) " +
"else " +
" return 0 " +
"end";
new Timer().schedule(new TimerTask() {
@Override
public void run() {
if (redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), uuid, String.valueOf(expire))) {
renewExpire();
}
}
}, this.expire * 1000 / 3);
}
}
2.6 手写分布式锁小结
特征
-
独占排他:
setnx -
防死锁:
redis客户端程序获取到锁之后,立马宕机。给锁添加过期时间
不可重入:可重入
-
防误删:
先判断是否自己的锁才能删除
-
原子性:
加锁和过期时间之间:
set k v ex 3 nx判断和释放锁之间:lua脚本
-
可重入性:
hash(key field value) + lua脚本 -
自动续期:
Timer定时器 + lua脚本 -
在集群情况下,导致锁机制失效:
-
客户端程序10010,从主中获取锁
-
从还没来得及同步数据,主挂了
-
于是从升级为主
-
客户端程序10086就从新主中获取到锁,导致锁机制失效
-
锁操作之加锁
-
setnx:独占排他 死锁、不可重入、原子性
-
set k v ex 30 nx:独占排他、死锁 不可重入
-
hash + lua脚本:可重入锁
-
判断锁是否被占用(exists),如果没有被占用则直接获取锁(hset/hincrby)并设置过期时间(expire)
-
如果锁被占用,则判断是否当前线程占用的(hexists),如果是则重入(hincrby)并重置过期时间(expire)
-
否则获取锁失败,将来代码中重试
-
-
Timer定时器 + lua脚本:实现锁的自动续期
判断锁是否自己的锁(hexists == 1),如果是自己的锁则执行expire重置过期时间
锁操作之解锁
-
del:导致误删
-
先判断再删除同时保证原子性:lua脚本
-
hash + lua脚本:可重入 1. 判断当前线程的锁是否存在,不存在则返回nil,将来抛出异常
-
存在则直接减1(hincrby -1),判断减1后的值是否为0,为0则释放锁(del),并返回1
-
不为0,则返回0
-
重试:递归 循环
3、红锁算法
redis官方网站针对redlock文档:https://redis.io/topics/distlock
在算法的分布式版本中,我们假设有N个Redis服务器,上述分布式锁在集群情况会失效。这些节点是完全独立的,因此我们不使用复制或任何其他隐式协调系统。**前几节已经描述了如何在单个实例中安全地获取和释放锁,在分布式锁算法中,将使用相同的方法在单个实例中获取和释放锁。**将N设置为5是一个合理的值,因此需要在不同的计算机或虚拟机上运行5个Redis主服务器,确保它们以独立的方式发生故障。为了获取锁,客户端执行以下操作:
-
客户端以毫秒为单位获取当前时间的时间戳,作为起始时间
-
客户端尝试在所有N个实例中顺序使用相同的键名、相同的随机值来获取锁定。每个实例尝试获取锁都需要时间,客户端应该设置一个远小于总锁定时间的超时时间。例如,如果自动释放时间为10秒,则尝试获取锁的超时时间可能在5到50毫秒之间。这样可以防止客户端长时间与处于故障状态的Redis节点进行通信:如果某个实例不可用,尽快尝试与下一个实例进行通信
-
客户端获取当前时间 减去在步骤1中获得的起始时间,来计算获取锁所花费的时间。当且仅当客户端能够在大多数实例(至少3个)中获取锁时,并且获取锁所花费的总时间小于锁有效时间,则认为已获取锁
-
如果获取了锁,则将锁有效时间减去 获取锁所花费的时间,如步骤3中所计算
-
如果客户端由于某种原因(无法锁定N / 2 + 1个实例或有效时间为负)而未能获得该锁,它将尝试解锁所有实例(即使没有锁定成功的实例)
每台计算机都有一个本地时钟,我们通常可以依靠不同的计算机来产生很小的时钟漂移。只有在拥有锁的客户端将在锁有效时间内(如步骤3中获得的)减去一段时间(仅几毫秒)的情况下终止工作,才能保证这一点。以补偿进程之间的时钟漂移
当客户端无法获取锁时,它应该在随机延迟后重试,以避免同时获取同一资源的多个客户端之间不同步(这可能会导致脑裂的情况:没人胜)。同样,客户端在大多数Redis实例中尝试获取锁的速度越快,出现裂脑情况(以及需要重试)的窗口就越小,因此理想情况下,客户端应尝试将SET命令发送到N个实例同时使用多路复用。
值得强调的是,对于未能获得大多数锁的客户端,尽快释放(部分)获得的锁有多么重要,这样就不必等待锁定期满才能再次获得锁(但是,如果发生了网络分区,并且客户端不再能够与Redis实例进行通信,则在等待密钥到期时需要付出可用性损失)
四、Redission分布式锁
1、redission介绍
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
官方文档地址:https://github.com/redisson/redisson/wiki
2、Redisson原理介绍
2.1 介绍
Redisson锁有两种模式:
-
固定有效期的锁:超过有效期leaseTime后,自动释放锁
-
没有有效期的锁:默认30秒,然后采用Watchdog进行续期,直到业务逻辑执行完毕(一般用这个)
基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
RLock对象完全符合Java的Lock规范。也就是说只有拥有锁的进程才能解锁,其他进程解锁则会抛出IllegalMonitorStateException错误。另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
使用redisson实现分布式锁的操作步骤,三部曲
-
第一步: 获取锁 RLock redissonLock = redisson.getLock(lockKey);
-
第二步: 加锁,实现锁续命功能 redissonLock.lock();
-
第三步:释放锁 redissonLock.unlock();
RLock lock = redisson.getLock("anyLock");
// 最常见的使用方法
lock.lock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
2.2 分布式锁原理

Redisson分布式锁源码分析
redisson.getLock(lockKey) 的逻辑
-
super(commandExecutor, name); 父类name赋值,后续通过getName()获取
-
commandExecutor: 执行lua脚本的executor
-
id 是个UUID, 后面被用来当做 和threadId组成 value值,用作判断加锁和释放锁是否是同一个线程的校验。
-
internalLockLeaseTime : 取自 Config#lockWatchdogTimeout,默认30秒,这个参数还有另外一个作用,锁续命的执行周期 internalLockLeaseTime/3 = 10秒
@Override
public RLock getLock(String name) {
return new RedissonLock(connectionManager.getCommandExecutor(), name);
}
public RedissonLock(CommandAsyncExecutor commandExecutor, String name) {
super(commandExecutor, name);
this.commandExecutor = commandExecutor;
this.id = commandExecutor.getConnectionManager().getId();
this.internalLockLeaseTime = commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout();
}
redissonLock.lock()的逻辑
这里讲解的是使用默认看门狗的lock方法,解锁方法类似。在调用lock方法时,会最终调用到tryAcquireAsync。调用链为:lock()->tryAcquire->tryAcquireAsync
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
//如果指定了加锁时间,会直接去加锁
if (leaseTime != -1) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
//没有指定加锁时间 会先进行加锁,并且默认时间就是 LockWatchdogTimeout的时间
//这个是异步操作 返回RFuture 类似netty中的future
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
//这里也是类似netty Future 的addListener,在future内容执行完成后执行
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
// leaseTime不为-1时,不会自动延期
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
//这里是定时执行 当前锁自动延期的动作,leaseTime为-1时,才会自动延期
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
scheduleExpirationRenewal 中会调用renewExpiration。 这里我们可以看到是,启用了一个timeout定时,去执行延期动作
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getRawName() + " expiration", e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
//如果 没有报错,就再次定时延期
// reschedule itself
renewExpiration();
} else {
cancelExpirationRenewal(null);
}
});
}
// 这里我们可以看到定时任务 是 lockWatchdogTimeout 的1/3时间去执行 renewExpirationAsync
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
最终 scheduleExpirationRenewal会调用到 renewExpirationAsync,执行下面这段 lua脚本。他主要判断就是 这个锁是否在redis中存在,如果存在就进行 pexpire 延期
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
-
watch dog 在当前节点存活时每10s给分布式锁的key续期 30s;
-
watch dog 机制启动,且代码中没有释放锁操作时,watch dog 会不断的给锁续期;
-
如果程序释放锁操作时因为异常没有被执行,那么锁无法被释放,所以释放锁操作一定要放到 finally {} 中;
-
要使 watchLog机制生效 ,lock时 不要设置 过期时间
-
watchlog的延时时间 可以由 lockWatchdogTimeout指定默认延时时间,但是不要设置太小。如100
-
watchdog 会每 lockWatchdogTimeout/3时间,去延时。
-
watchdog 通过 类似netty的 Future功能来实现异步延时
-
watchdog 最终还是通过 lua脚本来进行延时
3、可重入锁(Reentrant Lock)
引入依赖
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.17.7version>
dependency>
添加配置
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
// 可以用"rediss://"来启用SSL连接,也可以设置集群模式
config.useSingleServer()
.setAddress("redis://172.16.116.100:6379"); // 指定服务器地址
// .setDatabase(0) // 指定数据库编号
// .setUsername("").setPassword("") // 用户名密码
// .setConnectionMinimumIdleSize(10) // 连接池最小空闲连接数
// .setConnectionPoolSize(50) // 连接池最大连接数
// .setIdleConnectionTimeout(60000) //线程超时时间
// .setConnectTimeout(60000) // 客户端获取redis超时时间
// .setTimeout(3000) // 相应超时时间
return Redisson.create(config);
}
}
代码使用
@Autowired
private RedissonClient redissonClient;
public void checkAndLock() {
// 加锁,获取锁失败重试
RLock lock = this.redissonClient.getLock("lock");
lock.lock();
try {
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// 重入锁
test();
} finally {
// 释放锁
lock.unlock();
}
}
public void test(){
RLock lock = this.redissonClient.getLock("lock");
lock.lock();
// 业务
lock.unlock();
}
4、公平锁(Fair Lock)
基于Redis的Redisson分布式可重入公平锁也是实现了java.util.concurrent.locks.Lock接口的一种RLock对象。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。它保证了当多个Redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。所有请求线程会在一个队列中排队,当某个线程出现宕机时,Redisson会等待5秒后继续下一个线程,也就是说如果前面有5个线程都处于等待状态,那么后面的线程会等待至少25秒。
RLock fairLock = redisson.getFairLock("anyLock");
// 最常见的使用方法
fairLock.lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
fairLock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS);
fairLock.unlock();
5、联锁(MultiLock)
基于Redis的Redisson分布式联锁RedissonMultiLock对象可以将多个RLock对象关联为一个联锁,每个RLock对象实例可以来自于不同的Redisson实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 所有的锁都上锁成功才算成功。
lock.lock();
...
lock.unlock();
6、红锁(RedLock)
基于Redis的Redisson红锁RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock对象关联为一个红锁,每个RLock对象实例可以来自于不同的Redisson实例
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
...
lock.unlock();
7、读写锁(ReadWriteLock)
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
8、信号量(Semaphore)
基于Redis的Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.trySetPermits(3);
semaphore.acquire();
semaphore.release();
9、闭锁(CountDownLatch)
基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
五、基于zookeeper实现分布式锁
1、zk介绍
1.1 安装启动
Centos7安装zookeeper和Web UI
安装:把zk安装包上传到/opt目录下,并切换到/opt目录下,执行以下指令
# 解压
tar -zxvf zookeeper-3.7.0-bin.tar.gz
# 重命名
mv apache-zookeeper-3.7.0-bin/ zookeeper
# 打开zookeeper根目录
cd /opt/zookeeper
# 创建一个数据目录,备用
mkdir data
# 打开zk的配置目录
cd /opt/zookeeper/conf
# copy配置文件,zk启动时会加载zoo.cfg文件
cp zoo_sample.cfg zoo.cfg
# 编辑配置文件
vim zoo.cfg
# 修改dataDir参数为之前创建的数据目录:/opt/zookeeper/data
# 切换到bin目录
cd /opt/zookeeper/bin
# 启动
./zkServer.sh start
./zkServer.sh status # 查看启动状态
./zkServer.sh stop # 停止
./zkServer.sh restart # 重启
./zkCli.sh # 查看zk客户端
1.2 相关概念
Zookeeper提供一个多层级的节点命名空间(节点称为znode),每个节点都用一个以斜杠(/)分隔的路径表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。并且每个节点都是唯一的。znode节点有四种类型:
-
PERSISTENT:永久节点。客户端与zookeeper断开连接后,该节点依旧存在
-
EPHEMERAL:临时节点。客户端与zookeeper断开连接后,该节点被删除
-
PERSISTENT_SEQUENTIAL:永久节点、序列化。客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL_SEQUENTIAL:临时节点、序列化。客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
[zk: localhost:2181(CONNECTED) 0] create /aa test # 创建持久化节点
Created /aa
[zk: localhost:2181(CONNECTED) 1] create -s /bb test # 创建持久序列化节点
Created /bb0000000001
[zk: localhost:2181(CONNECTED) 2] create -e /cc test # 创建临时节点
Created /cc
[zk: localhost:2181(CONNECTED) 3] create -e -s /dd test # 创建临时序列化节点
Created /dd0000000003
[zk: localhost:2181(CONNECTED) 4] ls / # 查看某个节点下的子节点
[aa, bb0000000001, cc, dd0000000003, zookeeper]
[zk: localhost:2181(CONNECTED) 5] stat / # 查看某个节点的状态
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x5
cversion = 3
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 5
[zk: localhost:2181(CONNECTED) 6] get /aa # 查看某个节点的内容
test
[zk: localhost:2181(CONNECTED) 11] delete /aa # 删除某个节点
[zk: localhost:2181(CONNECTED) 7] ls / # 再次查看
[bb0000000001, cc, dd0000000003, zookeeper]
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端(一次性)。当前zookeeper针对节点的监听有如下四种事件:
-
节点创建:stat -w /xx
当/xx节点创建时:NodeCreated
-
节点删除:stat -w /xx
当/xx节点删除时:NodeDeleted
-
节点数据修改:get -w /xx
当/xx节点数据发生变化时:NodeDataChanged
-
子节点变更:ls -w /xx
当/xx节点的子节点创建或者删除时:NodeChildChanged
1.3 Java客户端
ZooKeeper的java客户端有:原生客户端、ZkClient、Curator框架(类似于redisson,有很多功能性封装),这里先用原生客户端
首先引入依赖
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.7.0version>
dependency>
常用api及其方法
public class ZkTest {
public static void main(String[] args) throws KeeperException, InterruptedException {
// 获取zookeeper链接
CountDownLatch countDownLatch = new CountDownLatch(1);
ZooKeeper zooKeeper = null;
try {
zooKeeper = new ZooKeeper("172.16.116.100:2181", 30000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (Event.KeeperState.SyncConnected.equals(event.getState())
&& Event.EventType.None.equals(event.getType())) {
System.out.println("获取链接成功。。。。。。" + event);
countDownLatch.countDown();
}
}
});
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// 创建一个节点,1-节点路径 2-节点内容 3-节点的访问权限 4-节点类型
// OPEN_ACL_UNSAFE:任何人可以操作该节点
// CREATOR_ALL_ACL:创建者拥有所有访问权限
// READ_ACL_UNSAFE: 任何人都可以读取该节点
// zooKeeper.create("/atguigu/aa", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
zooKeeper.create("/test", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
// zooKeeper.create("/atguigu/cc", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断节点是否存在
Stat stat = zooKeeper.exists("/test", true);
if (stat != null){
System.out.println("当前节点存在!" + stat.getVersion());
} else {
System.out.println("当前节点不存在!");
}
// 判断节点是否存在,同时添加监听
zooKeeper.exists("/test", event -> {
});
// 获取一个节点的数据
byte[] data = zooKeeper.getData("/atguigu/ss0000000001", false, null);
System.out.println(new String(data));
// 查询一个节点的所有子节点
List<String> children = zooKeeper.getChildren("/test", false);
System.out.println(children);
// 更新
zooKeeper.setData("/test", "wawa...".getBytes(), stat.getVersion());
// 删除一个节点
//zooKeeper.delete("/test", -1);
if (zooKeeper != null){
zooKeeper.close();
}
}
}
2、ZK分布式锁基本实现
2.1 思路分析
分布式锁的步骤:
-
获取锁:create一个节点
-
删除锁:delete一个节点
-
重试:没有获取到锁的请求重试
参照redis分布式锁的特点:
-
互斥 排他
-
防死锁:
-
可自动释放锁(临时节点) :获得锁之后客户端所在机器宕机了,客户端没有主动删除子节点;如果创建的是永久的节点,那么这个锁永远不会释放,导致死锁;由于创建的是临时节点,客户端宕机后,过了一定时间zookeeper没有收到客户端的心跳包判断会话失效,将临时节点删除从而释放锁。
-
可重入锁:借助于ThreadLocal
-
-
防误删:宕机自动释放临时节点,不需要设置过期时间,也就不存在误删问题。
-
加锁/解锁要具备原子性
-
单点问题:使用Zookeeper可以有效的解决单点问题,ZK一般是集群部署的。
-
集群问题:zookeeper集群是强一致性的,只要集群中有半数以上的机器存活,就可以对外提供服务。
2.2 基本实现
实现思路:
-
多个请求同时添加一个相同的临时节点,只有一个可以添加成功。添加成功的获取到锁
-
执行业务逻辑
-
完成业务流程后,删除节点释放锁。
由于zookeeper获取链接是一个耗时过程,这里可以在项目启动时,初始化链接,并且只初始化一次。借助于spring特性,代码实现如下(下面只完成了lock(),trylock()方法可以按照redis仿写)
@Component
public class ZkClient {
private static final String connectString = "172.16.116.100:2181";
private static final String ROOT_PATH = "/distributed";
private ZooKeeper zooKeeper;
@PostConstruct
public void init(){
try {
// 连接zookeeper服务器
this.zooKeeper = new ZooKeeper(connectString, 30000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("获取链接成功!!");
}
});
// 创建分布式锁根节点
if (this.zooKeeper.exists(ROOT_PATH, false) == null){
this.zooKeeper.create(ROOT_PATH, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (Exception e) {
System.out.println("获取链接失败!");
e.printStackTrace();
}
}
@PreDestroy
public void destroy(){
try {
if (zooKeeper != null){
zooKeeper.close();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 初始化zk分布式锁对象方法
* @param lockName
* @return
*/
public ZkDistributedLock getZkDistributedLock(String lockName){
return new ZkDistributedLock(zooKeeper, lockName);
}
}
zk分布式锁具体实现
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
this.zooKeeper = zooKeeper;
this.path = ROOT_PATH + "/" + lockName;
}
public void lock(){
try {
zooKeeper.create(path, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
// 重试
try {
Thread.sleep(200);
lock();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
public void unlock(){
try {
this.zooKeeper.delete(path, 0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
改造StockService的checkAndLock方法
@Autowired
private ZkClient client;
public void checkAndLock() {
// 加锁,获取锁失败重试
ZkDistributedLock lock = this.client.getZkDistributedLock("lock");
lock.lock();
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// 释放锁
lock.unlock();
}
基本实现存在的问题,由于无限自旋影响性能
-
性能一般(比mysql分布式锁略好)
-
不可重入
2.3 性能优化(阻塞非自旋)
由于无限自旋影响性能,当每个请求要想正常的执行完成,最终都是要创建节点,如果能够避免争抢必然可以提高性能。这里借助于zk的临时序列化节点,实现分布式锁
对于这个算法有个极大的优化点:假如当前有1000个节点在等待锁,如果获得锁的客户端释放锁时,这1000个客户端都会被唤醒,这种情况称为“羊群效应”;在这种羊群效应中,zookeeper需要通知1000个客户端,这会阻塞其他的操作,最好的情况应该只唤醒新的最小节点对应的客户端。应该怎么做呢?在设置事件监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,例如子节点列表为/locks/lock-0000000000、/locks/lock-0000000001、/locks/lock-0000000002,序号为1的客户端监听序号为0的子节点删除消息,序号为2的监听序号为1的子节点删除消息。
所以调整后的分布式锁算法流程如下:
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/locks/lock-0000000000,第二个为/locks/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
try {
this.zooKeeper = zooKeeper;
// 这里只是测试,正式的时候要放在lock方法里
this.path = zooKeeper.create(ROOT_PATH + "/" + lockName + "-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 这样性能接近于redis的分布式锁
public void lock(){
try {
String preNode = getPreNode(path);
// 如果该节点没有前一个节点,说明该节点时最小节点,放行执行业务逻辑
if (StringUtils.isEmpty(preNode)){
return ;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, new Watcher(){
@Override
public void process(WatchedEvent event) {
countDownLatch.countDown();
}
}) == null) {
return;
}
// 阻塞。。。。
countDownLatch.await();
return;
}
} catch (Exception e) {
e.printStackTrace();
// 重新检查。是否获取到锁
try {
Thread.sleep(200);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
lock();
}
}
public void unlock(){
try {
this.zooKeeper.delete(path, 0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
/**
* 获取指定节点的前节点
* @param path
* @return
*/
private String getPreNode(String path){
try {
// 获取当前节点的序列化号
Long curSerial = Long.valueOf(StringUtils.substringAfterLast(path, "-"));
// 获取根路径下的所有序列化子节点
List<String> nodes = this.zooKeeper.getChildren(ROOT_PATH, false);
// 判空
if (CollectionUtils.isEmpty(nodes)){
return null;
}
// 获取前一个节点
Long flag = 0L;
String preNode = null;
for (String node : nodes) {
// 获取每个节点的序列化号
Long serial = Long.valueOf(StringUtils.substringAfterLast(node, "-"));
if (serial < curSerial && serial > flag){
flag = serial;
preNode = node;
}
}
return preNode;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
}
2.4 优化:可重入锁
引入ThreadLocal线程局部变量保证zk分布式锁的可重入性
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private static final ThreadLocal<Integer> THREAD_LOCAL = new ThreadLocal<>();
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
try {
this.zooKeeper = zooKeeper;
if (THREAD_LOCAL.get() == null || THREAD_LOCAL.get() == 0){
// 这里只是测试,正式的时候要放在lock方法里
this.path = zooKeeper.create(ROOT_PATH + "/" + lockName + "-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void lock(){
Integer flag = THREAD_LOCAL.get();
if (flag != null && flag > 0) {
THREAD_LOCAL.set(flag + 1);
return;
}
try {
String preNode = getPreNode(path);
// 如果该节点没有前一个节点,说明该节点时最小节点,放行执行业务逻辑
if (StringUtils.isEmpty(preNode)){
THREAD_LOCAL.set(1);
return ;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, new Watcher(){
@Override
public void process(WatchedEvent event) {
countDownLatch.countDown();
}
}) == null) {
THREAD_LOCAL.set(1);
return;
}
// 阻塞。。。。
countDownLatch.await();
THREAD_LOCAL.set(1);
return;
}
} catch (Exception e) {
e.printStackTrace();
// 重新检查。是否获取到锁
try {
Thread.sleep(200);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
lock();
}
}
public void unlock(){
try {
THREAD_LOCAL.set(THREAD_LOCAL.get() - 1);
if (THREAD_LOCAL.get() == 0) {
this.zooKeeper.delete(path, 0);
THREAD_LOCAL.remove();
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
/**
* 获取指定节点的前节点
* @param path
* @return
*/
private String getPreNode(String path){
try {
// 获取当前节点的序列化号
Long curSerial = Long.valueOf(StringUtils.substringAfterLast(path, "-"));
// 获取根路径下的所有序列化子节点
List<String> nodes = this.zooKeeper.getChildren(ROOT_PATH, false);
// 判空
if (CollectionUtils.isEmpty(nodes)){
return null;
}
// 获取前一个节点
Long flag = 0L;
String preNode = null;
for (String node : nodes) {
// 获取每个节点的序列化号
Long serial = Long.valueOf(StringUtils.substringAfterLast(node, "-"));
if (serial < curSerial && serial > flag){
flag = serial;
preNode = node;
}
}
return preNode;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
}
2.5 小结
参照redis分布式锁的特点:
-
互斥 排他:zk节点的不可重复性,以及序列化节点的有序性
-
防死锁:
-
可自动释放锁:临时节点
-
可重入锁:借助于ThreadLocal
-
-
防误删:临时节点
-
加锁/解锁要具备原子性
-
单点问题:使用Zookeeper可以有效的解决单点问题,ZK一般是集群部署的。
-
集群问题:zookeeper集群是强一致性的,只要集群中有半数以上的机器存活,就可以对外提供服务。
-
公平锁:有序性节点
3、Curator中的分布式锁
3.1 简介
Curator是netflix公司开源的一套zookeeper客户端,目前是Apache的顶级项目。与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量。Curator解决了很多zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册wathcer和NodeExistsException 异常等。
通过查看官方文档,可以发现Curator主要解决了三类问题:
-
封装ZooKeeper client与ZooKeeper server之间的连接处理
-
提供了一套Fluent风格的操作API
-
提供ZooKeeper各种应用场景(recipe, 比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等)的抽象封装,这些实现都遵循了zk的最佳实践,并考虑了各种极端情况
Curator由一系列的模块构成,对于一般开发者而言,常用的是curator-framework和curator-recipes:
-
curator-framework:提供了常见的zk相关的底层操作
-
curator-recipes:提供了一些zk的典型使用场景的参考。本节重点关注的分布式锁就是该包提供的
3.2 依赖引入与配置
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>4.3.0version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.3.0version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.14version>
dependency>
添加curator客户端配置
@Configuration
public class CuratorConfig {
@Bean
public CuratorFramework curatorFramework(){
// 重试策略,这里使用的是指数补偿重试策略,重试3次,初始重试间隔1000ms,每次重试之后重试间隔递增。
RetryPolicy retry = new ExponentialBackoffRetry(1000, 3);
// 初始化Curator客户端:指定链接信息 及 重试策略
CuratorFramework client = CuratorFrameworkFactory.newClient("172.16.116.100:2181", retry);
client.start(); // 开始链接,如果不调用该方法,很多方法无法工作
return client;
}
}
3.3 可重入锁InterProcessMutex
Reentrant和JDK的ReentrantLock类似, 意味着同一个客户端在拥有锁的同时,可以多次获取,不会被阻塞。它是由类InterProcessMutex来实现
// 常用构造方法
public InterProcessMutex(CuratorFramework client, String path)
// 获取锁
public void acquire();
// 带超时时间的可重入锁
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public void release();
改造,如想重入,则需要使用同一个InterProcessMutex对象
@Autowired
private CuratorFramework curatorFramework;
public void checkAndLock() {
InterProcessMutex mutex = new InterProcessMutex(curatorFramework, "/curator/lock");
try {
// 加锁
mutex.acquire();
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// this.testSub(mutex);
// 释放锁
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testSub(InterProcessMutex mutex) {
try {
mutex.acquire();
System.out.println("测试可重入锁。。。。");
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
加锁解锁原理可以参考:Curator - 分布式锁的实现原理 & 如何使用
Curator实现分布式锁的基本原理
3.4 不可重入锁InterProcessSemaphoreMutex
具体实现:InterProcessSemaphoreMutex。与InterProcessMutex调用方法类似,区别在于该锁是不可重入的,在同一个线程中不可重入
public InterProcessSemaphoreMutex(CuratorFramework client, String path);
public void acquire();
public boolean acquire(long time, TimeUnit unit);
public void release();
代码举例
@Autowired
private CuratorFramework curatorFramework;
public void deduct() {
InterProcessSemaphoreMutex mutex = new InterProcessSemaphoreMutex(curatorFramework, "/curator/lock");
try {
mutex.acquire();
// 1. 查询库存信息
String stock = redisTemplate.opsForValue().get("stock").toString();
// 2. 判断库存是否充足
if (stock != null && stock.length() != 0) {
Integer st = Integer.valueOf(stock);
if (st > 0) {
// 3.扣减库存
redisTemplate.opsForValue().set("stock", String.valueOf(--st));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.5 可重入读写锁InterProcessReadWriteLock
类似JDK的ReentrantReadWriteLock。一个拥有写锁的线程可重入读锁,但是读锁却不能进入写锁。这也意味着写锁可以降级成读锁。从读锁升级成写锁是不成的。主要实现类InterProcessReadWriteLock
// 构造方法
public InterProcessReadWriteLock(CuratorFramework client, String basePath);
// 获取读锁对象
InterProcessMutex readLock();
// 获取写锁对象
InterProcessMutex writeLock();
注意:写锁在释放之前会一直阻塞请求线程,而读锁不会
public void testZkReadLock() {
try {
InterProcessReadWriteLock rwlock = new InterProcessReadWriteLock(curatorFramework, "/curator/rwlock");
rwlock.readLock().acquire(10, TimeUnit.SECONDS);
// TODO:一顿读的操作。。。。
//rwlock.readLock().unlock();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testZkWriteLock() {
try {
InterProcessReadWriteLock rwlock = new InterProcessReadWriteLock(curatorFramework, "/curator/rwlock");
rwlock.writeLock().acquire(10, TimeUnit.SECONDS);
// TODO:一顿写的操作。。。。
//rwlock.writeLock().unlock();
} catch (Exception e) {
e.printStackTrace();
}
}
3.6 联锁InterProcessMultiLock
Multi Shared Lock是一个锁的容器。当调用acquire, 所有的锁都会被acquire,如果请求失败,所有的锁都会被release。同样调用release时所有的锁都被release(失败被忽略)。基本上,它就是组锁的代表,在它上面的请求释放操作都会传递给它包含的所有的锁。实现类InterProcessMultiLock(不常用)
// 构造函数需要包含的锁的集合,或者一组ZooKeeper的path
public InterProcessMultiLock(List<InterProcessLock> locks);
public InterProcessMultiLock(CuratorFramework client, List<String> paths);
// 获取锁
public void acquire();
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public synchronized void release();
3.7 信号量InterProcessSemaphoreV2
一个计数的信号量类似JDK的Semaphore。JDK中Semaphore维护的一组许可(permits),而Cubator中称之为租约(Lease)。注意,所有的实例必须使用相同的numberOfLeases值。调用acquire会返回一个租约对象。客户端必须在finally中close这些租约对象,否则这些租约会丢失掉。但是,如果客户端session由于某种原因比如crash丢掉, 那么这些客户端持有的租约会自动close, 这样其它客户端可以继续使用这些租约。主要实现类InterProcessSemaphoreV2
// 构造方法
public InterProcessSemaphoreV2(CuratorFramework client, String path, int maxLeases);
// 注意一次你可以请求多个租约,如果Semaphore当前的租约不够,则请求线程会被阻塞。
// 同时还提供了超时的重载方法
public Lease acquire();
public Collection<Lease> acquire(int qty);
public Lease acquire(long time, TimeUnit unit);
public Collection<Lease> acquire(int qty, long time, TimeUnit unit)
// 租约还可以通过下面的方式返还
public void returnAll(Collection<Lease> leases);
public void returnLease(Lease lease);
代码举例
public void testSemaphore() {
// 设置资源量 限流的线程数
InterProcessSemaphoreV2 semaphoreV2 = new InterProcessSemaphoreV2(curatorFramework, "/locks/semaphore", 5);
try {
Lease acquire = semaphoreV2.acquire();// 获取资源,获取资源成功的线程可以继续处理业务操作。否则会被阻塞住
this.redisTemplate.opsForList().rightPush("log", "10010获取了资源,开始处理业务逻辑。" + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(10 + new Random().nextInt(10));
this.redisTemplate.opsForList().rightPush("log", "10010处理完业务逻辑,释放资源=====================" + Thread.currentThread().getName());
semaphoreV2.returnLease(acquire); // 手动释放资源,后续请求线程就可以获取该资源
} catch (Exception e) {
e.printStackTrace();
}
}
3.8 栅栏barrier
DistributedBarrier构造函数中barrierPath参数用来确定一个栅栏,只要barrierPath参数相同(路径相同)就是同一个栅栏。通常情况下栅栏的使用如下:
-
主client设置一个栅栏
-
其他客户端就会调用waitOnBarrier()等待栅栏移除,程序处理线程阻塞
-
主client移除栅栏,其他客户端的处理程序就会同时继续运行
DistributedBarrier类的主要方法如下:
setBarrier() - 设置栅栏
waitOnBarrier() - 等待栅栏移除
removeBarrier() - 移除栅栏
DistributedDoubleBarrier双栅栏,允许客户端在计算的开始和结束时同步。当足够的进程加入到双栅栏时,进程开始计算,当计算完成时,离开栅栏。DistributedDoubleBarrier实现了双栅栏的功能
// client - the client
// barrierPath - path to use
// memberQty - the number of members in the barrier
public DistributedDoubleBarrier(CuratorFramework client, String barrierPath, int memberQty);
enter()、enter(long maxWait, TimeUnit unit) - 等待同时进入栅栏
leave()、leave(long maxWait, TimeUnit unit) - 等待同时离开栅栏
memberQty是成员数量,当enter方法被调用时,成员被阻塞,直到所有的成员都调用了enter。当leave方法被调用时,它也阻塞调用线程,直到所有的成员都调用了leave。注意:参数memberQty的值只是一个阈值,而不是一个限制值。当等待栅栏的数量大于或等于这个值栅栏就会打开!与栅栏(DistributedBarrier)一样,双栅栏的barrierPath参数也是用来确定是否是同一个栅栏的,双栅栏的使用情况如下:
-
从多个客户端在同一个路径上创建双栅栏(DistributedDoubleBarrier),然后调用enter()方法,等待栅栏数量达到memberQty时就可以进入栅栏。
-
栅栏数量达到memberQty,多个客户端同时停止阻塞继续运行,直到执行leave()方法,等待memberQty个数量的栅栏同时阻塞到leave()方法中。
-
memberQty个数量的栅栏同时阻塞到leave()方法中,多个客户端的leave()方法停止阻塞,继续运行。
3.9 共享计数器
利用ZooKeeper可以实现一个集群共享的计数器。只要使用相同的path就可以得到最新的计数器值, 这是由ZooKeeper的一致性保证的。Curator有两个计数器, 一个是用int来计数,一个用long来计数
// 构造方法
public SharedCount(CuratorFramework client, String path, int seedValue);
// 获取共享计数的值
public int getCount();
// 设置共享计数的值
public void setCount(int newCount) throws Exception;
// 当版本号没有变化时,才会更新共享变量的值
public boolean trySetCount(VersionedValue<Integer> previous, int newCount);
// 通过监听器监听共享计数的变化
public void addListener(SharedCountListener listener);
public void addListener(final SharedCountListener listener, Executor executor);
// 共享计数在使用之前必须开启
public void start() throws Exception;
// 关闭共享计数
public void close() throws IOException;
使用案例
public void testZkShareCount() {
try {
// 第三个参数是共享计数的初始值
SharedCount sharedCount = new SharedCount(curatorFramework, "/curator/count", 0);
// 启动共享计数器
sharedCount.start();
// 获取共享计数的值
int count = sharedCount.getCount();
// 修改共享计数的值
int random = new Random().nextInt(1000);
sharedCount.setCount(random);
System.out.println("我获取了共享计数的初始值:" + count + ",并把计数器的值改为:" + random);
sharedCount.close();
} catch (Exception e) {
e.printStackTrace();
}
}
DistributedAtomicNumber
DistributedAtomicNumber接口是分布式原子数值类型的抽象,定义了分布式原子数值类型需要提供的方法。DistributedAtomicNumber接口有两个实现:DistributedAtomicLong 和 DistributedAtomicInteger
DistributedAtomicLong除了计数的范围比SharedCount大了之外,比SharedCount更简单易用。它首先尝试使用乐观锁的方式设置计数器, 如果不成功(比如期间计数器已经被其它client更新了), 它使用InterProcessMutex方式来更新计数值。此计数器有一系列的操作:
-
get(): 获取当前值
-
increment():加一
-
decrement(): 减一
-
add():增加特定的值
-
subtract(): 减去特定的值
-
trySet(): 尝试设置计数值
-
forceSet(): 强制设置计数值
你必须检查返回结果的succeeded(), 它代表此操作是否成功。如果操作成功, preValue()代表操作前的值, postValue()代表操作后的值。
六、基于mysql实现分布式锁
1、介绍
不管是jvm锁还是mysql锁,为了保证线程的并发安全,都提供了悲观独占排他锁。所以独占排他也是分布式锁的基本要求
对于Mysql可以利用唯一键索引不能重复插入的特点实现
CREATE TABLE `tb_lock` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`lock_name` varchar(50) NOT NULL COMMENT '锁名',
`class_name` varchar(100) DEFAULT NULL COMMENT '类名',
`method_name` varchar(50) DEFAULT NULL COMMENT '方法名',
`server_name` varchar(50) DEFAULT NULL COMMENT '服务器ip',
`thread_name` varchar(50) DEFAULT NULL COMMENT '线程名',
`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '获取锁时间',
`desc` varchar(100) DEFAULT NULL COMMENT '描述',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_unique` (`lock_name`)
) ENGINE=InnoDB AUTO_INCREMENT=1332899824461455363 DEFAULT CHARSET=utf8;
2、基本思路
synchronized关键字和ReetrantLock锁都是独占排他锁,即多个线程争抢一个资源时,同一时刻只有一个线程可以抢占该资源,其他线程只能阻塞等待,直到占有资源的线程释放该资源
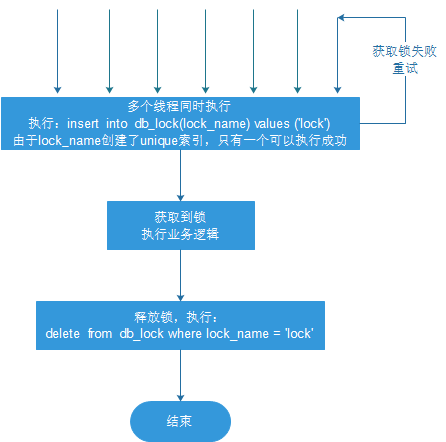
-
线程同时获取锁(insert)
-
获取成功,执行业务逻辑,执行完成释放锁(delete)
-
其他线程等待重试
3、代码实现
最后测试发现其性能非常差
@Service
public class StockService {
@Autowired
private StockMapper stockMapper;
@Autowired
private LockMapper lockMapper;
/**
* 数据库分布式锁
*/
public void checkAndLock() {
// 加锁
Lock lock = new Lock(null, "lock", this.getClass().getName(), new Date(), null);
try {
this.lockMapper.insert(lock);
} catch (Exception ex) {
// 获取锁失败,则重试
try {
Thread.sleep(50);
this.checkAndLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// 释放锁
this.lockMapper.deleteById(lock.getId());
}
}
4、缺陷和解决方
-
这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
解决方案:给 锁数据库 搭建主备
-
这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
解决方案:只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
-
这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决方案:记录获取锁的主机信息和线程信息,如果相同线程要获取锁,直接重入。
-
受制于数据库性能,并发能力有限。
解决方案:无法解决。
七、总结
-
实现的复杂性或者难度角度:Zookeeper > redis > 数据库
-
实际性能角度:redis > Zookeeper > 数据库
-
可靠性角度:Zookeeper > redis = 数据库
这三种方式都不是尽善尽美,我们可以根据实际业务情况选择最适合的方案:如果追求极致性能可以选择reds方案;如果追求可靠性可以选择zk
常见锁分类:
-
悲观锁:具有强烈的独占和排他特性,在整个数据处理过程中,将数据处于锁定状态。适合于写比较多,会阻塞读操作。 乐观锁:采取了更加宽松的加锁机制,大多是基于数据版本( Version )及时间戳来实现。。适合于读比较多,不会阻塞读
-
独占锁、互斥锁、排他锁:保证在任一时刻,只能被一个线程独占排他持有。synchronized、ReentrantLock 共享锁:可同时被多个线程共享持有。CountDownLatch到计数器、Semaphore信号量
-
可重入锁:又名递归锁。同一个线程在外层方法获取锁的时候,在进入内层方法时会自动获取锁。 不可重入锁:例如早期的synchronized
-
公平锁:有优先级的锁,先来先得,谁先申请锁就先获取到锁 非公平锁:无优先级的锁,后来者也有机会先获取到锁
-
自旋锁:当线程尝试获取锁失败时(锁已经被其它线程占用了),无限循环重试尝试获取锁; 阻塞锁:当线程尝试获取锁失败时,线程进入阻塞状态,直到接收信号后被唤醒。在竞争激烈情况下,性能较高
-
读锁:共享锁 写锁:独占排他锁
-
偏向锁:一直被一个线程所访问,那么该线程会自动获取锁 轻量级锁(CAS):当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。 重量级锁:当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候(10次),还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让他申请的线程进入阻塞,性能降低。 以上其实是synchronized的锁升级过程
-
表级锁:对整张表加锁,加锁快开销小,不会出现死锁,但并发度低,会增加锁冲突的概率 行级锁:是mysql粒度最小的锁,只针对操作行,可大大减少锁冲突概率,并发度高,但加锁慢,开销大,会出现死锁
参考文章
Redis进阶- Redisson分布式锁实现原理及源码解析
https://www.bilibili.com/video/BV1kd4y1G7dM