数据结构大作业-DBLP科学文献管理系统(一) XML解析,文件哈希,C++线程
在程序中,需要解析的DBLB文件大小为3G-4G的。因此每次启动程序前都读取一遍DBLP并全部写入内存的方法是不现实的,这需要我们提前在磁盘中建立对应的数据库文件,在第一次打开程序时进行建立数据库的操作,将需要的数据写入磁盘。之后对DBLP的数据查询只需要打开已经建立好的数据库进行IO操作即可。
由于数据在磁盘和内存中的读取速度差距极大,在磁盘中删改添加数据效率是很低的,因此如何建立对应数据的索引,以及在选择一个在磁盘文件中容易维护的数据结构是非常重要的。在保证查找效率时,还需要做到方便在磁盘中维护。最后,我们选择了文件哈希+线性遍历的方法,将需要的数据通过一个哈希函数映射到一个文件中,之后查询时只需要根据搜索内容的哈希值打开对应的数据文件进行查询即可。
XML解析
我们先来观察XML文件的格式:
可以看出,XML的主要特征是以<>为头节点,<\>为尾节点,头尾节点中间就是该节点的内容。(格式和html比较类似)。
对于一篇文献,它以
bool check_TailElem(string tempstr)//尾节点判定
{
if ((tempstr.find("") != string::npos) || (tempstr.find("") != string::npos) ||
(tempstr.find("") != string::npos) || (tempstr.find("") != string::npos) ||
(tempstr.find("") != string::npos) || (tempstr.find("") != string::npos) ||
(tempstr.find("") != string::npos) || (tempstr.find("") != string::npos))
return true;
else return false;
};对于一篇文献,我们无需从中提出所有的数据写入文件保存,选择其中我们需要的数据保存即可,比如title,author等节点,然后记录该title的偏移量。在后面需要找到该文献的所有信息时,只需要得到对应的偏移量打开dblp获取即可。
文件哈希
如何存储数据文件,这里用到了最简单的结构:哈希表。先通过一个函数将文章的title转换成一个哈希值。使用该哈希值命名文件并存储。当需要找到这篇文章时,只需要将title转换成哈希值,找到并打开对应文件,在文件中找到文章标题对应的偏移量即可。
程序中使用的哈希函数,是一个0-4095的映射
DWORD Hash4(const string& tar)
{
DWORD64 ans = 0;
for (int i = 0; i < tar.length(); i++) {
ans = ((ans >> 8) & 0xf) ^ ((ans << 4) ^ tar[i]);
}
return ans & 0xfff;
} 磁盘中的存储样例
同理,关于合作作者和作者名,也可以用过一个作者名的哈希文件,将该作者的名字,合作人,文章名保存起来(这里的存储文件中,一行为一个文章,用¥划分字符串,每行最后一个为标题名,前面为发表这个标题的作者们)
下面C++中通过文章名称搜索数据的行动逻辑


///
/// 输入文章名,返回文章的所有相关信息
///
/// 文章名
/// 文件保存路径
/// 对外输出结果
/// 当前函数执行状态
void articleInfo(char* _articleName, char* _saveUrl, char* pt, char* state)
{
string articleName = _articleName;
string saveUrl = _saveUrl;
string ret = ""; //返回值
string flag = articleName.substr(0, 3); //截取文章的前三个字符
transformer_Filename(flag);
ifstream infile(saveUrl + "publication\\" + flag + ".txt", ios::in); //打开对应文档
//路径错误,返回报错提示
if (!infile)
{
Strcpy(state, "Failed to locate the corresponding data file. Please check whether the file path or article title is correct");
return;
}
//Strcpy(state, "成功打开文件,正在查找数据...");
Strcpy(state, "File opened successfully, searching for data...");
//找到哈希文件中文章对应的偏移量
size_t urlpt = 0;
string tempstr;
getline(infile, tempstr);
while (!infile.eof()) {
if (tempstr.find(articleName) != string::npos)
{
size_t startPos = tempstr.find_last_of("=") + 1;//urlpt="中,获取=的位置后+1,即“位置
size_t endPos = tempstr.find_last_of("\"");//最后的”位置
urlpt = stringToLonglong(tempstr.substr(startPos + 1, endPos - (startPos + 1)));
break;
}
getline(infile, tempstr);
}
infile.close();
if (urlpt == 0)
{
//Strcpy(state, "该文献不存在!");
Strcpy(state, "The document does not exist!");
return;
}
//打开dblp文件,通过偏移量移动指针,然后返回该书的所有内容
//Strcpy(state, "已确定文章标题及对应偏移量,解析dblp数据中...");
Strcpy(state, "The article title and corresponding offset have been determined, parsing DBLP data...");
int tot = 0;
if (urlpt != 0)
{
ifstream indblp(saveUrl + "dblp.xml", ios::in | ios::binary);
indblp.seekg(urlpt, ios::beg);
getline(indblp, tempstr);
string closeKey = "";
//直到找到文章结尾才跳出循环
//while ((tempstr.find("") == string::npos && tempstr.find(closeKey) == string::npos) || tot == 0)
while (tempstr.find(closeKey) == string::npos || tot == 0)
{
if (tot + 1 % 100 == 0)
{
//Strcpy(state, "当前文章:" + articleName +"\n解析dblp数据中...CloseKey:" + closeKey + " 计数器:" + to_string(tot));
Strcpy(state, "Current article is " + articleName +"\nParsing DBLP data...CloseKey " + closeKey + " current index " + to_string(tot));
}
if (tempstr.find("mdate") != string::npos) //如果该行有mdate
{
if (closeKey == "")
{
int index = tempstr.find("mdate");
while (index > 0)
{
if (tempstr[index] == '<')
break;
index--;
}
//出来时index下标对的是<,让index+1这样可以给closeKey最前面赋值上"";
//cout << tempstr<< "更新了closeKey" << closeKey << endl << index << " " << tempstr.find("mdate") - 1 << endl;
cout << "[DLL] 更新了closeKey" << closeKey << endl;
}
else
{
cout << "[DLL] 重复的closeKey,已经删去剩余内容" << closeKey << endl;
int index = tempstr.find("mdate");
while (index > 0)
{
if (tempstr[index] == '<')
break;
index--;
}
//出来时index下标对的是<,substr对应左闭合右开区间,可以用tempstr = tempstr.substr(0, index)删除剩余内容
//index--;
tempstr = tempstr.substr(0, index);
}
}
tot++;
if (tot > 1000) //防止特例造成死循环
{
//Strcpy(state, "该文献已超过1000行,已忽略剩下内容");
Strcpy(state, "The document has more than 1000 lines and the rest has been ignored");
break;
}
ret += tempstr;
getline(indblp, tempstr);
}
ret += tempstr;
}
//将结果与c#对接
if (ret.length() > 0)
{
strcpy_s(pt, ret.length() + 1, ret.c_str()); //拷贝数据输出
if (tot <= 1000)
{
Strcpy(state, "Search Completed!");
}
}
else
{
Strcpy(state, "The document does not exist!");
Strcpy(pt,"");
}
return;
} 线程优化
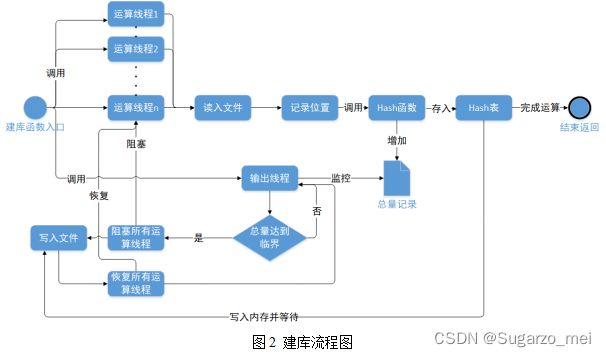
为了优化建库函数的速度,这里用到线程思想。线程是cpu调度的最小单位,可以将一项任务分成多个小任务,在宏观上有计算机同时运行。合理使用会提高程序并行执行的速度。
在建库中,程序将创建多个运算线程和一个输出线程。运算线程会不断地执行读入文件,并在查找到文章后记录文章所在DBLP的指针位置,之后Hash文章名和作者名,并将所有相关信息放在其对应的Hash表的位置中。在Hash表中储存的信息达到一定量后,程序将阻塞运算线程,并由输出线程把Hash表中的文件放入数据库的对应Hash文件中。
每个线程都有一个独立的数组储存数据以避免线程冲突,最后由输出线程统一输出。其中,每个数组储存的是一个链表的起始地址,同一个Hash值的数据用链表连接,这样,插入的复杂度为O(1),顺序输出时输出所有数据的复杂度为O(n)。
具体的线程思想等后面讲C#的时候在详细补充