基于Netty实现HTTP请求转换为RPC泛化调用
基于Netty实现HTTP请求转换为RPC泛化调用
- 接口定义
- HTTP 请求携带参数
-
- 方案一:multipart/form-data
- 方案二:application/json
- 字节流 To HTTP报文
-
- HttpRequestDecoder
-
- 场景一:头字段包含Content-Length
- 场景二:分块传输Transfer-Encoding: chunked
- Talent发送分块编码的HTTP请求
- HttpObjectAggregator
-
- StartMessage
- ContentMessage
- 参数解析
-
- 表单数据解析
- json类型数据解析
- 发起泛化调用
本文讨论如何基于 Netty 框架实现 API 网关的协议转换功能,即转换 HTTP 请求为 RPC 泛化调用。文章脉络遵循 API 网关接收到字节流后的处理流程,具体内容分为如下小节:
- HTTP 请求如何携带参数
- 字节流 To HTTP报文
- 泛化调用参数解析
- 发起泛化调用及调用结果展示
接口定义
本文将以一个 RPC 接口IActivityBooth作为示例,讲解如何通过 HTTP 请求调用到该接口。
public interface IActivityBooth {
// 标准 rpc 接口定义, 仅有一个入参,即请求结构体
String enrollGrades(EnrollGradesReq req);
}
public class EnrollGradesReq {
// 课程名称
private String course;
// 任课教师
private User teacher;
// 学生名单
private List<Student> students;
// 成绩指标: 依次为最高分、最低分、平均分
private List<Integer> gradeMetrics;
}
enrollGrades方法:模拟学生成绩登记操作;- 由 Api 网关管理的 rpc 接口统一只使用一个入参,即请求对象。
EnrollGradesReq请求对象包括接口响应所需的所有信息:课程名称、任课老师、班级中的学生名单、成绩指标。 - 为了模拟实际 RPC 参数类型的复杂性,对请求对象的字段设计如下:
cource:简单数据类型java.lang.String,相似的类型还有Integer、Double、Boolean等。teacher:任课教师,DTO 对象User;students:学生名单,DTO 对象Student集合;gradeMetrics:班级成绩统计指标,简单类型(Integer)集合;
为什么 rpc 接口统一只有一个入参?我认为好处有如下几点:
- 简化接口定义:当RPC接口只有一个复杂的入参时,接口定义会变得简洁。接口的签名不会随着参数数量的增加而变得复杂,使得接口更易于理解和维护。
- 灵活性和扩展性:单一的请求结构体作为参数使得在不改变接口签名的情况下,能够轻松地添加、删除或修改参数。
- 清晰的数据结构:所有请求数据封装在一个结构体中,有助于定义清晰、结构化的数据模型。
- 便于序列化和反序列化:在远程调用中,数据需要在网络上传输,涉及到序列化和反序列化过程。单一的请求对象可以简化这个过程,因为只需要对一个对象进行操作,而不是多个散落的参数。
HTTP 请求携带参数
方案一:multipart/form-data
multipart/form-data是一种用于HTTP请求的编码类型,它允许在单个请求中发送多种类型的数据(尤其是文件上传)。在这种编码类型下,消息体被分割成多个部分,每个部分可以包含不同类型的数据。
常用场景:
- 文件上传:在Web表单中上传文件时,通常使用
multipart/form-data。例如,当用户需要上传图片、视频、文档等文件到服务器时。 - 发送复杂的表单数据:当表单数据不仅仅包含简单的键值对,还包含复杂的结构(例如对象),
multipart/form-data提供了灵活的数据组织方式。
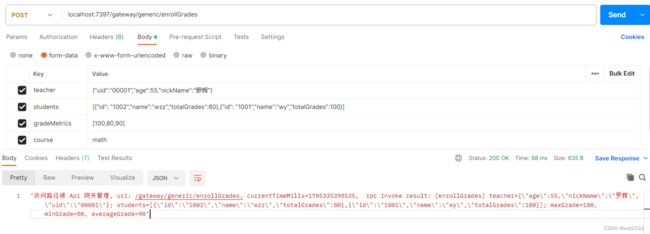
Postman 设置:

注:我选择 json 字符串传递对象类型,如 students 为 json 列表、teacher 则为单个 json 字符串。
为了更清晰的展示 form-data 类型的消息格式,我使用 Netty 编写了简易的 echo 服务器,它会回传原始的 HTTP 请求报文。使用 postman 发送请求后,收到的响应如下:
POST /echo/req HTTP/1.1
User-Agent: PostmanRuntime/7.36.0
Accept: */*
Postman-Token: d0e81eda-2dcd-447e-bc66-1a1cd7b66b0c
Host: localhost:8080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Type: multipart/form-data; boundary=--------------------------062873639731964115386269
content-length: 635
----------------------------062873639731964115386269
Content-Disposition: form-data; name="teacher"
{"uid":"00001","age":55,"nickName":"罗辉"}
----------------------------062873639731964115386269
Content-Disposition: form-data; name="students"
[{"id": "1002","name":"wzz","totalGrades":80},{"id": "1001","name":"wy","totalGrades":100}]
----------------------------062873639731964115386269
Content-Disposition: form-data; name="gradeMetrics"
[100,80,90]
----------------------------062873639731964115386269
Content-Disposition: form-data; name="course"
math
----------------------------062873639731964115386269--
Content-Disposition是 HTTP 请求或响应头的一部分,用于指示资源的处理方式,它用于 multipart/form-data类型的请求体中,表示表单数据的一部分。- 每个部分用一个
boundary(边界标识符)来分隔。 Content-Disposition: form-data表明这部分内容是表单数据。紧接着的name="..."属性指定了表单字段的名称。(teacher、gradeMetrics都是 Postman 请求时设置的表单属性)- 文件上传时,
Content-Disposition通常还会包含一个filename属性,指示上传的文件名。
方案二:application/json
application/json表示消息体的内容是JSON(JavaScript Object Notation)格式,json 是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。
常用场景:
- 发送或接收复杂数据结构:JSON格式可以轻松地表示嵌套的数据结构,如对象、数组等。
- 前后端分离的Web应用:现代的Web应用中,前端通常使用JavaScript与后端进行数据交互,而JSON是JavaScript中原生支持的格式,因此使用
application/json非常方便。 - 移动应用和跨平台应用:JSON 由于其跨语言的特性和简洁性,被广泛用于移动应用程序和跨平台应用程序的数据交换。
Postman 设置:
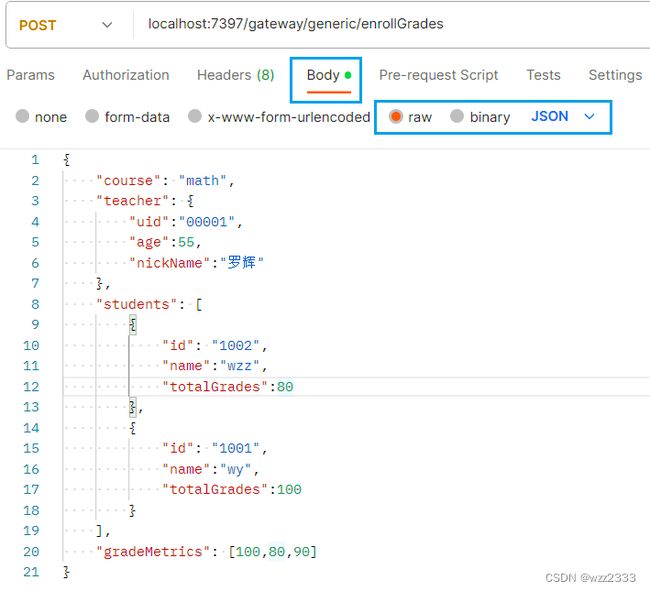
HTTP 完整请求:
POST /echo/req HTTP/1.1
Content-Type: application/json
User-Agent: PostmanRuntime/7.36.0
Accept: */*
Postman-Token: 264730d7-68fd-4a90-9bd8-fac08a14d2a4
Host: localhost:8080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
content-length: 398
{
"course": "math",
"teacher": {
"uid":"00001",
"age":55,
"nickName":"罗辉"
},
"students": [
{
"id": "1002",
"name":"wzz",
"totalGrades":80
},
{
"id": "1001",
"name":"wy",
"totalGrades":100
}
],
"gradeMetrics": [100,80,90]
}
字节流 To HTTP报文
在介绍使用 Netty 转换 TCP 字节流为完整 HTTP 报文前,我先把ChannelInitializer代码贴一下,initChannel方法为每个新建立的连接注册 Inbound 和 Outbound 处理器。
public class GatewayChannelInitializer extends ChannelInitializer<SocketChannel> {
private final Configuration configuration;
public GatewayChannelInitializer(Configuration configuration) {
this.configuration = configuration;
}
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new HttpRequestDecoder());
pipeline.addLast(new HttpResponseEncoder());
pipeline.addLast(new HttpObjectAggregator(1024 * 1024));
/*添加自定义的业务处理器 */
pipeline.addLast();
}
}
我概括下这段代码的关键点:
HttpRequestDecoder用于将 HTTP 请求的字节流解析为一个HttpRequest和多个HttpContent对象;HttpObjectAggregator:聚合HttpRequest和随后的HttpContents为FullHttpRequest或FullHttpResponse;HttpRequest就是不含 Http Body 的 Http 请求;而HttpContent就是保存 Http Body 分块数据的实例。- 为什么 Http Body 会分为多个
HttpContent实例?
因为解码器的属性maxChunkSize(默认 8192 字节),控制HttpContent携带 Body 数据的最大长度,对于数据超出 8192 字节的 Http Body,解码器会将其分割为多个HttpContent实例。
本章之后的内容,我将详细讲解这一部分的源码,梳理完整的处理流程,不感兴趣的朋友可以直接跳到参数解析章节。
完整的 HTTP 请求结构图由三部分组成:
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用 key-value 形式更详细地说明报文;
- 消息正文(body):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。

HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”,也就是“CRLF”,十六进制的“0D0A”。
HTTP 服务器首先需要将 TCP 字节流转换为上图标准 HTTP 报文,基于 Netty 构建的 HTTP 服务器 ChannelPipeline 的结构如下:
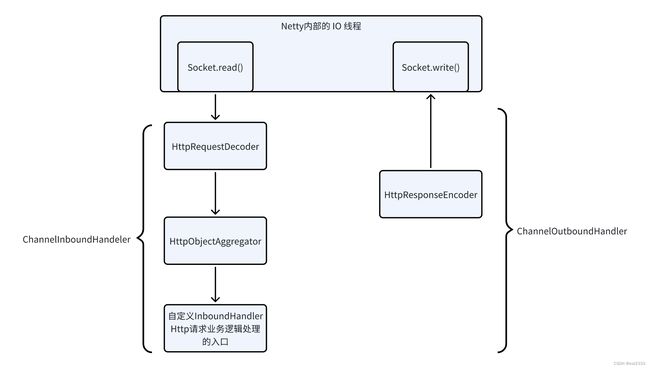
HttpRequestDecoder
HttpRequestDecoder是ChannelInboundHandler接口的实现类,作用是将ByteBuf中的字节流数据解码为一个HttpMessage实例(实际为 DefaultHttpRequest实现类)和多个HttpContent实例。
// io.netty.handler.codec.http.HttpRequestDecoder#createMessage
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(
HttpVersion.valueOf(initialLine[2]),
HttpMethod.valueOf(initialLine[0]), initialLine[1], validateHeaders);
}
DefaultHttpRequest对象就是 HTTP 请求行+ 头部数据,请求行包含 请求方法、请求 URI 和 HTTP 协议版本。
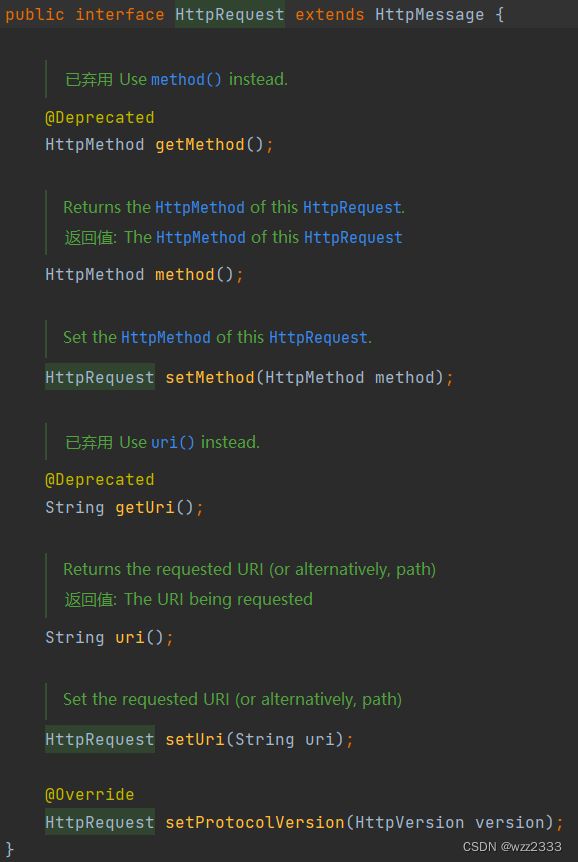
一个HttpContent对象就是 HTTP Body 的一个分块,用于 HTTP 分块传输。
HttpObjectDecoder会在生成HttpMessage后生成HttpContent,当出现如下情况时,解码器将生成多个HttpContent实例。
- Body 数据量很大
maxChunkSize:默认 8192 字节,控制 content 和单个分块的最大长度。当 content 超出该值,则会被分为多个 HttpContent。 - HTTP 包含头字段
Transfer-Encoding: chunked
下面我们来看看源码中针对这两种场景的处理方式,方法io.netty.handler.codec.http.HttpObjectDecoder#decode。
场景一:头字段包含Content-Length
头字段包含 Content-Length 字段,状态机流转为READ_FIXED_LENGTH_CONTENT状态,chunkSize设置为content长度。
long contentLength = contentLength(); // 读取头字段Content-Length的值
// ...
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
// chunkSize will be decreased as the READ_FIXED_LENGTH_CONTENT state reads data chunk by chunk.
chunkSize = contentLength;
}
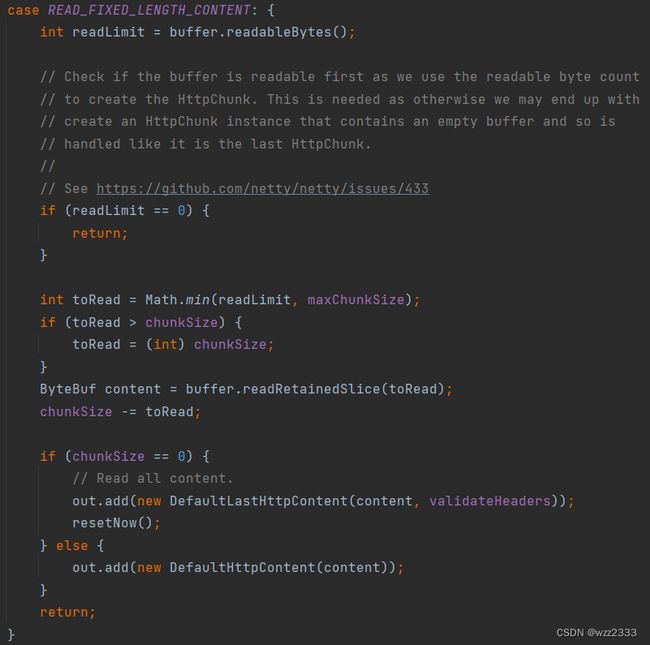
源码截图中,readLimit规定读取的字节数最大为 buffer 中可读字节数、maxChunkSize二者中的最小值。
chunkSize则是 HTTP Body 剩余数据的大小,因此本轮解码器解析的数据toRead应该为chunkSize、readLimit二者的最小值,即单次读取的数据量不能超出maxChunkSize、也不能将多个 HTTP 请求的数据混淆在一个HttpContent中。
如果当前 HTTP body 没有剩余数据(chunkSize等于0),则将消息体包装到DefaultLastHttpContent对象中并添加到out集合(out集合会被传递给下一个InboundHandler)。此外,还会重置currentState为 SKIP_CONTROL_CHARS,表示本轮 Http 请求/响应解析完成。
如果仍有剩余内容,则将内容包装为DefaultHttpContent对象,并将其添加到out集合方法返回,注意此时 currentState仍然为READ_FIXED_LENGTH_CONTENT,且out.size大于 0,这意味 decode方法会再次被调用,从而能解析剩余的 Http 消息体。
场景二:分块传输Transfer-Encoding: chunked
在阅读后续代码前,我先补充下 HTTP 分块编码规则:
- 每个分块包含两个部分,长度头和数据块;
- 长度头是以 CRLF(回车换行,即\r\n)结尾的一行明文,用16 进制数字表示长度;
- 数据块紧跟在长度头后,最后也用 CRLF 结尾,但数据不包含 CRLF;
- 最后用一个长度为 0 的块表示结束,即“0\r\n\r\n”。

当读取到头部存在Transfer-Encoding: chunked时,状态机的状态会流转为READ_CHUNK_SIZE。
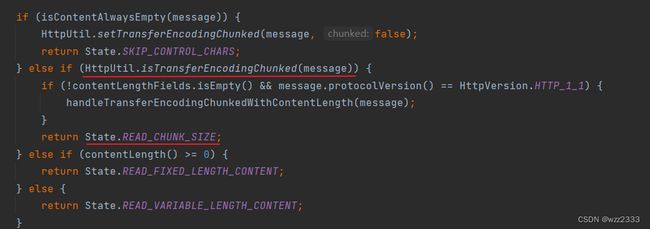
READ_CHUNK_SIZE状态:读取分块长度。

lineParser:LineParser对象,LineParser是ByteProcessor实现类,用于将ByteBuf中的字节流解析为以行(Line)为单位的字符串流。
parse方法在循环内调用LineParser#process方法,逐个读取 buffer 中的字符,当读取到LF 换行符后,process返回 false 退出循环,此时 lineParser 已经读取到了完整的一行(不含CRLF)。
public boolean process(byte value) throws Exception {
char nextByte = (char) (value & 0xFF);
if (nextByte == HttpConstants.LF) {
int len = seq.length();
// Drop CR if we had a CRLF pair
if (len >= 1 && seq.charAtUnsafe(len - 1) == HttpConstants.CR) {
-- size;
seq.setLength(len - 1);
}
// 读取到LF换行符, 返回false
return false;
}
increaseCount();
seq.append(nextByte);
return true;
}
getChunkSize方法解析十六进制分块长度,并设置chunkSize字段为该值。若分块长度大于 0,状态流转为READ_CHUNKED_CONTENT。
READ_CHUNKED_CONTENT状态:读取分块数据。
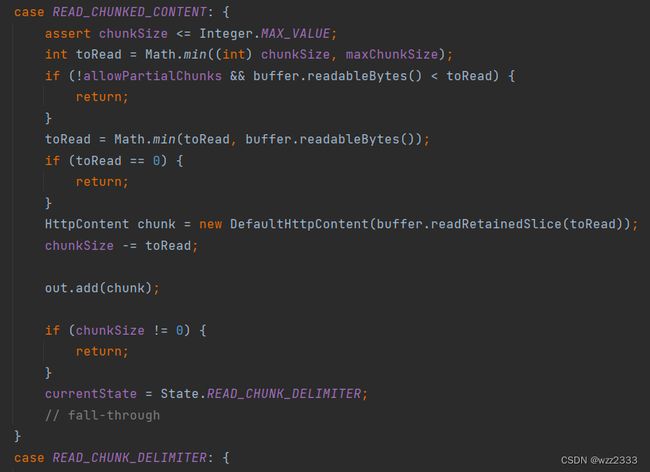
chunkSize初始化为当前分块大小,表示分块剩余可读取大小;toRead变量计算可读取的最大字节数,不得超过maxChunkSize和 ByteBuf 中可读字节数。- 生成
DefaultHttpContent对象,content字段设置为从 buffer 中读取的toRead大小的数据。
注:使用readRetainedSlice方法获取ByteBuf buf某个区间的子切片sub_buf,这个子切片的引用计数独立于buf。即使,buf的引用计数降至0并且被释放,sub_buf仍然是有效的。 - 随后,
chunkSize减少toRead,并将DefaultHttpContent对象添加至out集合传递给下一个 handler。
如果chunkSize等于 0,说明当前分块读取完毕,状态流转为READ_CHUNK_DELIMITER:解码器会逐个读取 buffer 中的字节,直到遇到换行符LF(‘\n’)结束循环,状态流转为READ_CHUNK_SIZE重复分块解析过程。

如果READ_CHUNK_SIZE读取分块大小为 0,会流转到READ_CHUNK_FOOTER状态。该状态表示解码器正在处理 HTTP 消息的块传输编码的尾部(chunk footer)
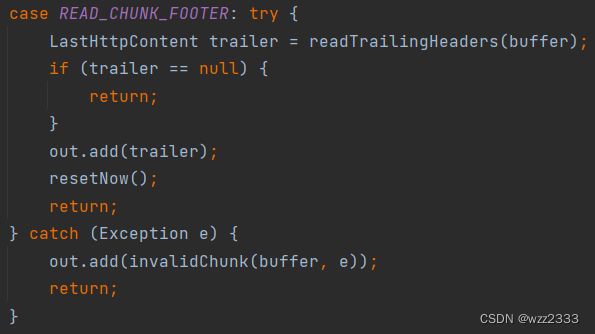
readTrailingHeaders方法:读取和解析块传输编码消息末尾的 trailing headers(尾头部)。
尾部头部是跟在最后一个大小为 0 的块之后的一系列 HTTP 头部。它们提供了关于整个消息体或最后一个块的额外信息,例如摘要或签名。
Talent发送分块编码的HTTP请求
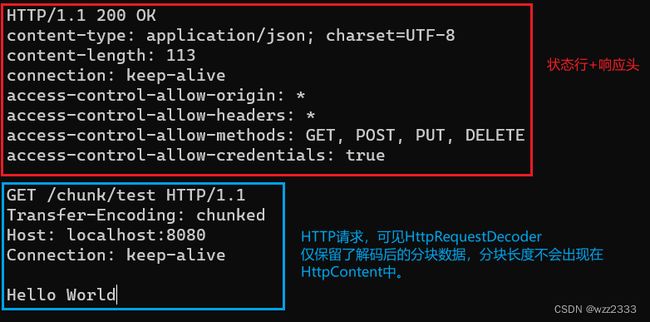
使用 telnet 客户端调试 HTTP 分块数据解析流程:
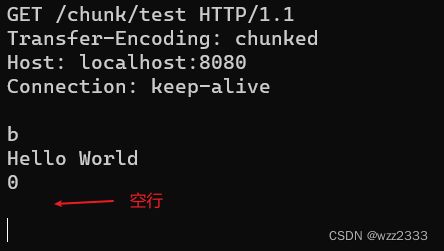
上图中请求体分为 4 行:
- 第一行: b十六进制数,第一个分块长度为 11;
- 第二行:第一个分块数据
Hello World; - 第三行:空分快的长度 0;
- 第四行:空行;
通过断点调试可知,读取到第一行b,chunkSize等于11。
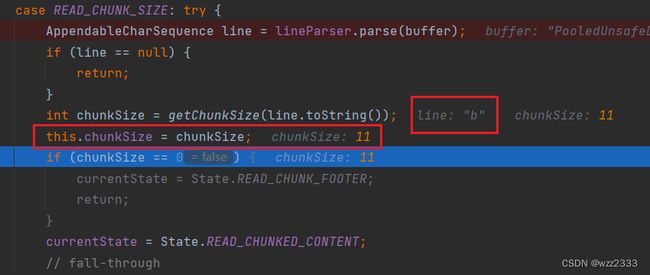
当读取到第三行后,得到chunkSize等于0,随后会跳转到READ_CHUNK_FOOTER分支执行。
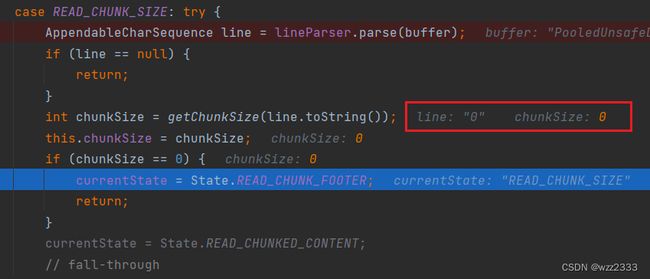
最后一行为空行,因此readTrailingHeaders返回LastHttpContent.EMPTY_LAST_CONTENT。
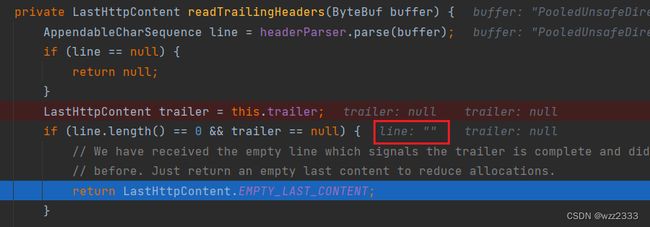
最后,将EMPTY_LAST_CONTENT添加到out集合,重置currentState为SKIP_CONTROL_CHARS状态。

至此,解码器完成了这个分块传输 HTTP 请求的解析工作,等待处理新的 HTTP 请求。Telnet 客户端收到的 HTTP 响应数据:
HttpObjectAggregator
缓存在 ByteBuf 中的字节流经过HttpRequestDecoder处理,解码为包含 请求行 + 请求头信息的HttpRequest对象和多个HttpContent对象。
这些实例将被依次交给HttpObjectAggregator处理,该ChannelHandler用于将来自HTTP消息的多个部分组合成一个完整的HTTP消息,即FullHttpRequest对象。
下面的示意图清晰反映了这一流程:

聚合消息的逻辑主要实现于io.netty.handler.codec.MessageAggregator#decode方法。下面我将依次介绍 聚合器收到HttpMessage和HttpContent对象时的处理逻辑。
StartMessage
如果 Aggregator 接收到的消息为HttpMessage实例,即 Http head + 版本号,则该消息为Http的首个消息,isStartMessage返回 true,代码如下(我对关键代码进行了编号,可以对照着解说阅读):
protected void decode(final ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception {
if (isStartMessage(msg)) { // (1)
// ...
// A streamed message - initialize the cumulative buffer, and wait for incoming chunks.
CompositeByteBuf content = ctx.alloc().compositeBuffer(maxCumulationBufferComponents); // (2)
if (m instanceof ByteBufHolder) { // (3)
appendPartialContent(content, ((ByteBufHolder) m).content());
}
currentMessage = beginAggregation(m, content); // (4)
}
}
isStartMessage:msg 是否为一个 HTTP 请求/响应的开始消息。HttpObjectAggregator中对该方法的实现如下:
protected boolean isStartMessage(HttpObject msg) throws Exception {
return msg instanceof HttpMessage;
}
例如:DefaultHttpRequest为HttpMessage实例。
ctx.alloc()获取当前 Channel 的 ByteBufAllocator,创建了一个CompositeByteBuf实例。maxCumulationBufferComponents是CompositeByteBuf可以持有的最大 ByteBuf 组件数量。这是一个性能优化,用于限制累积缓冲区的大小。if (m instanceof ByteBufHolder)检查m是否为ByteBufHolder的实例,如果是,说明m包含可用的数据内容,需要追加到前面创建的CompositeByteBuf content中。beginAggregation:创建新的聚合消息,入参为开始消息start和指定的ByteBuf实例content用于存放 body 数据。
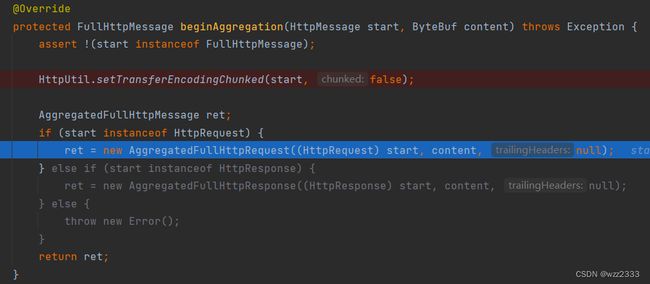
如果 start 为HttpRequest实例,则创建AggregatedFullHttpRequest对象用于存放聚合后的完整 HTTP 请求。
ContentMessage
如果 Aggregator 接收到的消息为HttpContent,即 Http Body 的分块数据,isContentMessage将返回true,这部分代码如下:
else if (isContentMessage(msg)) {
if (currentMessage == null) {
// it is possible that a TooLongFrameException was already thrown but we can still discard data
// until the begging of the next request/response.
return;
}
// Merge the received chunk into the content of the current message.
CompositeByteBuf content = (CompositeByteBuf) currentMessage.content(); // (1)
@SuppressWarnings("unchecked")
final C m = (C) msg;
// Append the content of the chunk.
appendPartialContent(content, m.content()); // (2)
// Give the subtypes a chance to merge additional information such as trailing headers.
aggregate(currentMessage, m);
final boolean last;
if (m instanceof DecoderResultProvider) {
DecoderResult decoderResult = ((DecoderResultProvider) m).decoderResult();
if (!decoderResult.isSuccess()) {
if (currentMessage instanceof DecoderResultProvider) {
((DecoderResultProvider) currentMessage).setDecoderResult(
DecoderResult.failure(decoderResult.cause()));
}
last = true;
} else {
last = isLastContentMessage(m); // (3)
}
} else {
last = isLastContentMessage(m); // (3)
}
if (last) { // (4)
finishAggregation0(currentMessage);
// All done
out.add(currentMessage);
currentMessage = null;
}
}
// ...
- currrentMessage 就是通过
beginAggregation方法创建的AggregatedFullHttpRequest实例;content 就是用于缓存合并后 Http Body 数据的ByteBuf。 appendPartialContent方法将HttpContent对象 msg 中的分块数据,追加到 content 中,即将HttpRequestDecoder解码生成的多个HttpContent对象的数据合并到 currentMessage 中。isLastContentMessage判断是否对象为LastContentMessage实例,即一个完整 Http 请求/响应 的最后一个分块数据。- 如果 msg 为
LastContentMessage实例,执行if(last)代码块。finishAggregation0会针对头部不含Content-Length字段的请求,补上这一头字段。(注:Transfer-Encoding: chunked 和 Content-Length 是互斥的)out.add(currentMessage)将聚合完成后的FullHttpRequest实例加入 out 集合,从而传递给下一个 InboundHandler,通常这个处理器由用户定义,用于实现业务逻辑。
注:即使 Http 请求没有 Body,HttpObjectDecoder#decode方法也会在解码完成前,添加一个空的 LastHttpContent对象。因此,任何合法的 Http 请求/响应,必然以一个LastHttpContent实例标识该 Http 请求/响应完成解码。
参数解析
在上一章节中,我介绍了使用 Netty 框架处理字节流,得到完整的 Http 报文的全过程。这一章,我将介绍如何从聚合的FullHttpRequest中,解析出泛化调用入参。
前面我们介绍了 Http 传递 RPC 请求结构体的两种方式:multipart/form-data、application/json,下面我将分别介绍如何介绍这两种方式传递的请求结构体。
表单数据解析
Netty 处理普通的 post 请求,典型的处理方式是使用io.netty.handler.codec.http.multipart.HttpPostRequestDecoder解析 Post 请求:
FullHttpRequest requst = ... // HttpObjectAggregator聚合后的Http请求
HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(request); // HttpRequest
decoder.offer(request); // HttpContent
-
HttpPostRequestDecoder:Netty 中用于处理 HTTP POST 请求的解码器,该解码器能解析 POST 请求体。Post 协议又可以分为普通 post 请求和 Multipart 请求:
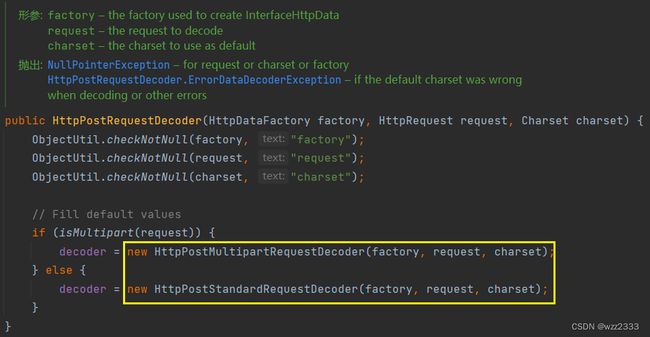
-
HttpPostRequestDecoder#offer:用于提供HttpContent对象给解码器。处理完成后,可以通过getBodyHttpDatas()获取所有表单数据,或者通过getBodyHttpDatas(String name)获取特定名字的表单字段。
随后,通过getBodyHttpDatas方法获取所有表单数据并进行解析,完整代码如下:
case "multipart/form-data":
// ...
Map<String, Object> parameters = new HashMap<>();
// 返回 Http 消息体中所有数据的列表(先通过 offer 方法提供完整的 Http 消息体)
decoder.getBodyHttpDatas().forEach(data->{
Attribute attr = (Attribute) data;
try {
String val = attr.getValue();
if(isJsonObject(val)) { // (1)
Object paramVal = parameters.get(attr.getName());
Map<?, ?> newVal = JSON.parseObject(val);
if(paramVal == null) {
parameters.put(attr.getName(), newVal);
} else if(paramVal instanceof List) {
((List)paramVal).add(newVal);
} else {
List<Object> objList = new ArrayList<>();
objList.add(paramVal); // old
objList.add(newVal); // new
parameters.put(attr.getName(), objList);
}
} else if(isJsonArray(val)) { // (2)
List<?> jsonObjs = null;
try {
jsonObjs = JSON.parseArray(val, JSONObject.class); // (2.1)
} catch (Exception e) {
// 尝试解析为字符串列表
jsonObjs = JSON.parseArray(val, String.class); // (2.2)
}
parameters.put(attr.getName(), jsonObjs);
} else { // (3)
parameters.put(attr.getName(), val);
}
} catch (Exception e) {}
});
isJsonObject判断 val 是否为 JSON 对象,例如{"uid":"00001","age":55,"nickName":"罗辉"}。如果是,则使用 fastjson 工具包的JSON.parseObject完成解析;
private boolean isJsonObject(String str) {
if(str == null || str.isEmpty()) {
return false;
}
return str.startsWith("{") && str.endsWith("}");
}
表单中可以传递多个名称相同的value(见下图),所以代码中针对【使用多个相同 key 的方式发送对象数组】的方式进行了支持。
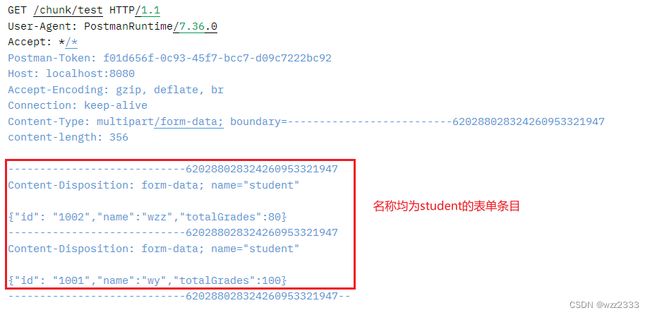
isJsonArray判断 val 是否为 JSON 数组,JSON 数组又可以细分为对象数组 和 简单类型数组。使用JSON.parseArray解析,第二个入参表示目标类型。- 对象数组:目标类型为 JSONObject(Map实现类),k-v结构天然适合存放对象的属性值。
如果解析过程抛出异常,说明 val 并不是对象数组,尝试将其作为简单类型数组解析。[{"uid":"00001","age":24,"nickName":"wzz"},{"uid":"00002","age":23,"nickName":"wy"}]- 简单类型数组:目标类型为 String。
[\"hello\", \"world\"] [2.45,5,64]- 如果 val 为简单类型(例如:Integer、Double、String),则直接放入 parameters 中。
json类型数据解析
解析 application/json 类型的请求结构体非常方便,因为rpc 接口入参规定为对象,因此直接使用 fastjson 的JSON.parseObject即可。
case "application/json":
ByteBuf content = request.content().copy();
if(content.isReadable()) {
String contentStr = content.toString(StandardCharsets.UTF_8);
// parseObject 将 json 字符串转换为 JSONObject, 该类型实现 Map 接口
// 如果 JSONObject 中某个条目的值也是 json 字符串, 该字符串也会被解析为 JSONObject
return JSON.parseObject(contentStr);
}
发起泛化调用
使用 Dubbo RPC 框架 + Zookeeper 注册中心发起泛化调用,详细的配置、使用教程以及入参处理本文不再赘述,笔者在另一篇文章已经给出了案例说明:一看就会!Dubbo 泛化调用简明教程——含不同类型入参处理
总而言之,API网关发起泛化调用,需要如下几个条件:
- HTTP 请求 uri:
/gateway/generic/enrollGrades; - rpc 接口全限定名:
cn.wzz.gateway.rpc.IActivityBooth。 - rpc 方法名:
enrollGrades。 - rpc 方法的入参全限定名:
cn.wzz.gateway.rpc.req.EnrollGradesReq; - rpc 方法的入参值,Dubbo 支持简单类型的值以及使用 Map 类型表示的对象。
【rpc 接口全限定名】、【方法名】以及【方法入参全限定名】需要服务主动上报给 API 网关;请求 uri 唯一确定一个 RPC 方法;rpc 方法的入参值通过解析 HTTP 携带的载荷(HTTP Body)获取。
调用结果展示:
- RPC方法实现
public String enrollGrades(EnrollGradesReq req) {
return String.format("[enrollGrades] teacher=%s; ", JSON.toJSONString(req.getTeacher())) +
String.format("students=%s; ", JSON.toJSONString(req.getStudents())) +
String.format("maxGrade=%d, minGrade=%d, averageGrade=%d",
req.getGradeMetrics().get(0),
req.getGradeMetrics().get(1),
req.getGradeMetrics().get(2));
}
- Postman 发起请求及接收到的响应