二叉树:dfs+回溯
dfs方法如何定义
回溯
- dfs一般会搭配回溯(dfs有返回值),本文中力扣114、226因为dfs返回值是void,所以不涉及回溯;
- 从root根节点出发:dfs递归的最内层是二叉树的最底层;回溯的起点是递归的最内层,root所在这一层的dfs
- 像力扣22题(括号生成),括号成对出现,只要能对应左右子树的,都可以抽象看作二叉树
前中后序遍历
这三种遍历其实都是dfs,只是递归的位置不同,一般二叉树用到dfs的都是这种区别(递归在前还是再后)
- 前序:101对称二叉树、617合并二叉树、98验证二叉树;都是先保证当前节点的事情做完了,再去下一层
- 中序:
- 后序:236二叉树公共祖先;需要先递归深入到最底层,然后从最底层开始找
参数
- dfs的参数如何设置很重要,一般是:节点(如果涉及同时操作多个节点就多个形参) + 限制条件(如果有的话)
- 如果是在原方法上进行操作,方法名 和 形参中的root 很可能会误导思路
- 通常可以通过自定义dfs来实现参数的自由限制(需要的话)
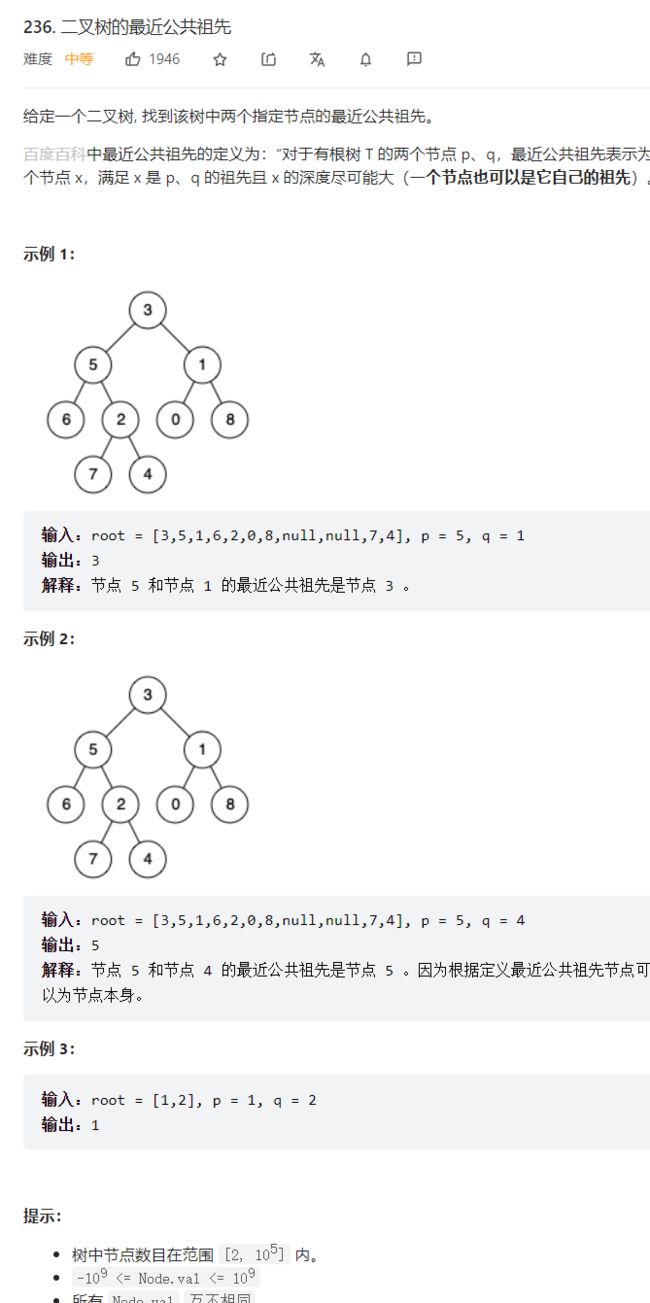
力扣236二叉树公共祖先
这个题就是典型的前序遍历思想了:
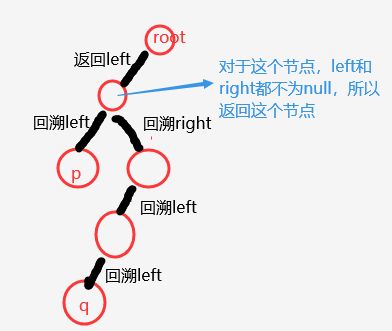
- 先dfs深入到最下层,终止条件是:匹配到p或者q、null到底了
- 然后回溯,把p或者q带出去分别给当前递归的left或right
- 如果left right都不为null,那就返回当前的节点;否则返回不为null的:假设存在场景
题目描述
题解
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//当且仅当递归的底层会成立:此出root理解为:最下面的p或q节点,然后回溯
if(root == null || root == p || root == q){return root;}
/**当不是最底层,就 前序:先深入到最底层 */
//当前的左节点是否能匹配上p或q,匹配不上返回null
TreeNode left = lowestCommonAncestor(root.left, p, q);
//当前的右节点是否能匹配上p或q,匹配不上返回null
TreeNode right = lowestCommonAncestor(root.right, p, q);
/**此时的left和right,如果匹配不上就是null(参考第一行代码),匹配上了因为回溯会返回p或q */
/**此时考虑场景:最顶层、接近底层 一共三个场景*/
//左右都找到了匹配:那最近父节点一定是这个root节点
if(left != null && right != null){return root;}
/**左边or右边匹配:回溯的是p或q的其中一个,
回溯到上面两句left和right那里
例如:left==p,right==q。但是判断时只需要判断左右不为空,那返回root
跟回溯究竟返回的是谁没关系,只要不是null就是匹配到了
*/
if(right == null){return left;}
if(left == null){return right;}
return root;
}
}
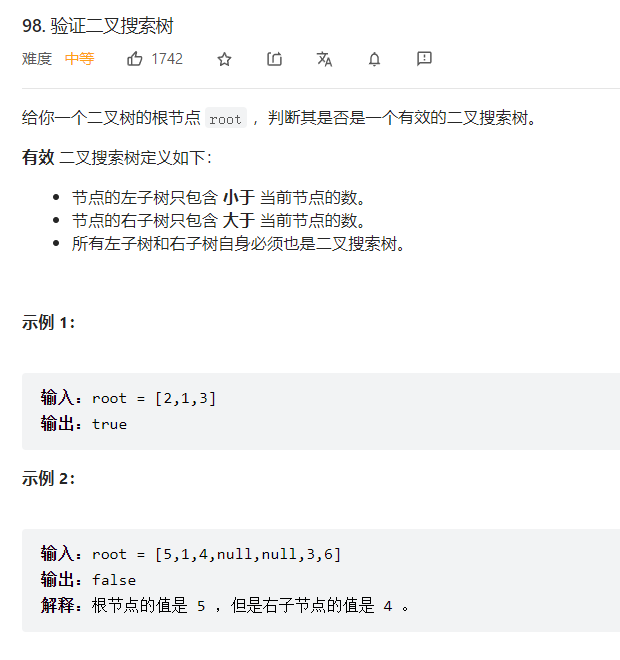
力扣98验证二叉搜索树
普通的二叉树与 二叉搜索树的区别在于:
- 普通二叉树只需要保证节点的左小右大
- 而搜索树需要保证节点整个左子树小,整个右子树大
题目描述
题解
因为需要保证“整个子树更小or更大”,所以需要自定义一个dfs方法,形参中携带max和min;
class Solution {
public boolean isValidBST(TreeNode root) {
return dfs(root,Long.MAX_VALUE,Long.MIN_VALUE);
}
public boolean dfs(TreeNode curr , long max , long min){
if(curr == null){return true;}
if(curr.val >= max || curr.val <= min){return false;}
return dfs(curr.left, curr.val, min) && dfs(curr.right, max ,curr.val);
}
}
力扣114二叉树展开为链表
这个题如果是用前序遍历(DFS)先存储结果到list中,空间复杂度为O(n),还有一种方法不用DFS空间复杂度为O(1)参考解答
题目描述

题解
既然提到了前序遍历,那直接把前序遍历的结果存储在list中,然后再循环恢复就好
class Solution {
public void flatten(TreeNode root) {
List list = new ArrayList();
preorderTraversal(root,list);
//此时list中有前序遍历的结果了
for(int i = 0 ; i < list.size() - 1 ; i++){
list.get(i).right = list.get(i+1);
list.get(i).left = null;
}
//因为最后一个节点本身left和right都是null,所以不用处理
}
//前序遍历的同时把值存入list
public void preorderTraversal(TreeNode curr,List list){
if(curr == null){return;}
list.add(curr);
preorderTraversal(curr.left,list);
preorderTraversal(curr.right,list);
}
}
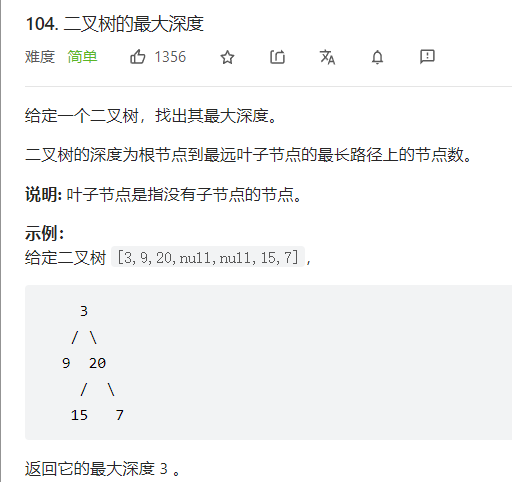
力扣104二叉树最大深度
一个简单题
题目描述
题解
class Solution {
public int maxDepth(TreeNode root) {
if(root == null){return 0;}
//左右子树分别递归,最终结果取Max + 1
return Math.max( maxDepth(root.left) , maxDepth(root.right) ) + 1;
}
}
力扣617合并二叉树
题目描述
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。

题解
class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if(root1 == null && root2 == null){return null;}
int v1 = root1 != null ? root1.val : 0 ;
int v2 = root2 != null ? root2.val : 0 ;
TreeNode curr = new TreeNode(v1+v2);
//这里面还要写三目运算符主要是排除空指针问题
curr.left = mergeTrees(root1 != null ? root1.left : null, root2 != null ? root2.left : null);
curr.right = mergeTrees(root1 != null ? root1.right : null, root2 != null ? root2.right : null);
return curr;
}
}
力扣226反转二叉树
题目描述

题解
class Solution {
public TreeNode invertTree(TreeNode root) {
TreeNode res = root;
reverse(root);
return res;
}
public void reverse(TreeNode curr){
if(curr == null) return;
TreeNode temp = curr.left;
curr.left = curr.right;
curr.right = temp;
reverse(curr.left);
reverse(curr.right);
}
}
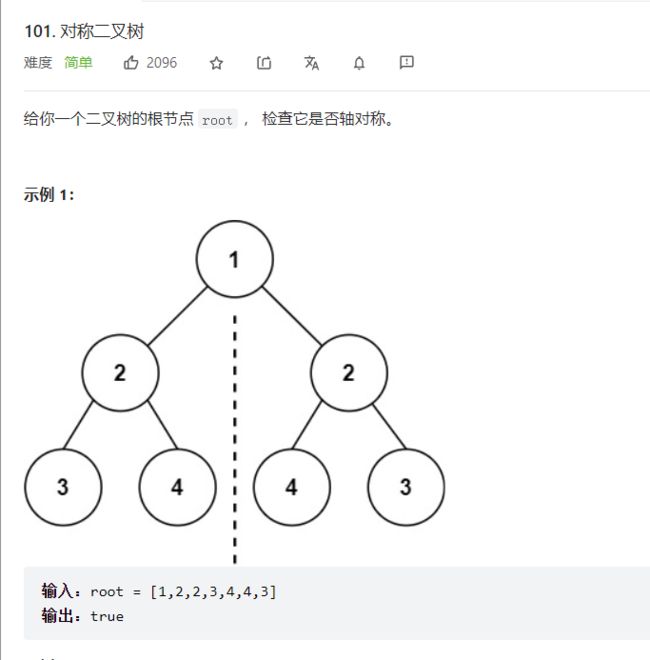
力扣101对称二叉树
题目描述
题解
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root == null){return false;}
return check(root.left, root.right);
}
public boolean check(TreeNode left , TreeNode right){
if(left == null && right == null){return true;}
if(left == null || right == null){return false;}
if(left.val != right.val){return false;}
//这里一定是左左 比 右右 && 右右 比 左左
return check(left.left, right.right) && check(right.left, left.right);
}
}
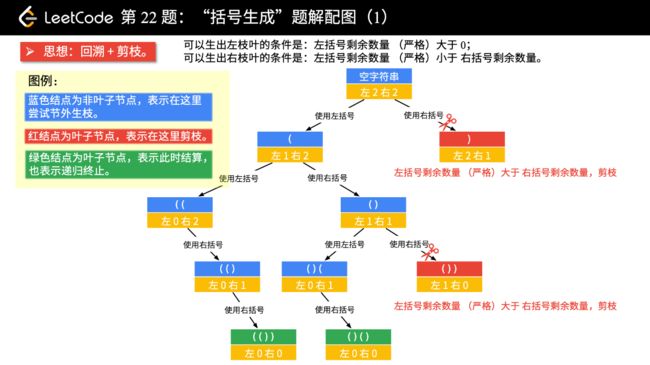
力扣22括号生成
这看起来是一个字符串问题,但实际上可以用二叉树dfs,因为很明显**()可以分别对应左子树、右子树**
题目描述

题解
参考解答
public class Solution {
// 做减法
public List generateParenthesis(int n) {
List res = new ArrayList<>();
// 特判
if (n == 0) {
return res;
}
// 执行深度优先遍历,搜索可能的结果
dfs("", n, n, res);
return res;
}
/**
* @param curStr 当前递归得到的结果
* @param left 左括号还有几个可以使用
* @param right 右括号还有几个可以使用
* @param res 结果集
*/
private void dfs(String curStr, int left, int right, List res) {
// 因为每一次尝试,都使用新的字符串变量,所以无需回溯
// 在递归终止的时候,直接把它添加到结果集即可,注意与「力扣」第 46 题、第 39 题区分
if (left == 0 && right == 0) {
res.add(curStr);
return;
}
// 剪枝(如图,左括号可以使用的个数严格大于右括号可以使用的个数,才剪枝,注意这个细节)
if (left > right) {
return;
}
if (left > 0) {
dfs(curStr + "(", left - 1, right, res);
}
if (right > 0) {
dfs(curStr + ")", left, right - 1, res);
}
}
}