分布式锁实现
在分布式系统中,一个应用部署在多台机器中,在某些场景下,为了保证数据一致性,要求在同一时刻,同一任务只在一个节点上运行,即保证某个行为在同一时刻只能被一个线程执行;在单机单进程多线程环境,通过锁很容易做到,比如mutex,spinlock,信号量等;而在多机多进程环境中,此时就需要分布式锁来解决了;
常见的锁有互斥锁,自旋锁,读写锁,信号量,条件变量,原子变量和内存屏障(无锁);
互斥锁和自旋锁是互斥锁类型的锁;
读写锁是应用在多读少些的场景中,数据库中的行锁。读锁对应共享锁,写锁对应排他锁;
信号量和条件变量主要实现同步,是同步类型的锁;但是信号量也可以实现互斥类型的锁,信号量可以用于IPC通信,IPC可以通过pipe,FIFO,信号量,信号,消息队列,共享内存,socket进行通信;
分布式锁和互斥锁,自旋锁的本质是差不多的;是要在分布式场景中实现互斥类型的锁;
在分布式场景中,有多个进程或者是多个进程中有多个线程,每个线程都可能进行数据库访问,但只有一个执行体允许操作某一块数据或者是执行某一个行为;其他的执行体都得等待;
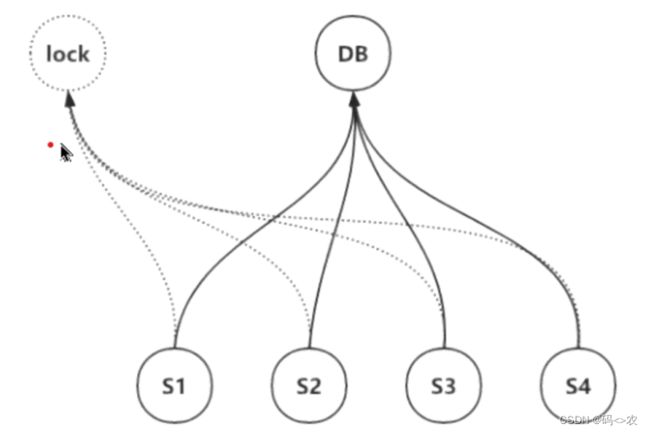
分布式锁需要解决的问题和数据库当中的事务有些类似,分布式锁本质上是解决了分布式事务当中的隔离性;假设lock是专门用来存储锁,多个进程S1,S2,S3,S4都可以访问到lock资源;那么如何访问lock资源呢?我们需要S1,S2,S3,S4进程和含有lock锁的进程建立连接,我们操作lock锁资源都是网络交互进行的,通过发送命令,返回锁是否操作成功的信息;在行为上,通过网络交互说明进程加了锁,其他进程访问lock锁时有标记说明锁已被另外的进程加锁了,并通过网络交互返回获取锁失败的结果;加锁和解锁都需要网络交互进行,加锁对象和解锁对象必须为同一个;
分布式锁的特性:
1)互斥性;
2)锁超时,在分布式场景中,所资源与进程行为是分离的,通过网络交互进行锁操作,这种情况下有lock资源的机器可能宕机,操作锁的进程所在机器也可能会宕机,这就要考虑一种情况,比如S1进程持有锁了,S2,S3,S4都在等待锁的释放,如果此时S1进程持有锁,但是含有S1进程的机器宕机了,由于加锁对象和解锁对象必须为同一个,在这种情况下S1进程就不能主动释放锁了;这个时候我们就需要提供一种机制,让S1持有的锁到达一定时间后自动释放掉,以被其他进程使用,如果没有释放掉,那么其他进程都不能够在获取到锁了;通过设置操作时间的最大值实现;
3)可用性,合理时间内得到合理的回复;如果含有lock锁的机器宕机,可能导致整个系统都处于不可用的状态;实现可用性可通过计算型,所谓计算型是有很多进程不存储数据只完成计算的行为,需要开多个备份点;也可通过存储型实现,所谓存储型是指进程是存储数据的,如果其中一个进程宕机,我们希望有另外的进程来顶替。另外一个进程的数据和原来进程的数据是一致的,存储型需要多个备份点以及数据切换的功能;
4)容错性,比如S1持有锁,但是此时未解锁含有lock锁的机器宕机了,假设有一个备份的lock已经切换过来,但是这个备份没有写入锁被持有这一信息,这就是一种错误的类型,容错性就是这种错误应该如何应对;可用一致性来解决,一个是raft一致性算法,一个是可用redlock来解决;只要半数以上备份lock写成功了,我们就认为成功了;
分布式锁类型:
1)重入锁和非重入锁,对于多线程环境下是递归锁和非递归锁的意思,就是允不允许持锁对象多次进入临界资源;
2)公平和非公平,对应互斥锁和自旋锁,互斥锁引起的线程切换,线程会进入阻塞的状态,然后加入阻塞队列,如果锁释放了,会从队列中取出一个加入就绪队列,下次就会被调用到;自旋锁则直接将线程加入到就绪队列,只要某个核心空闲了,就会从就绪队列中取出一个执行,但是互斥锁则不会那么容易线程就进入就绪队列,需要释放锁之后才从阻塞队列移到就绪队列;
分布式锁实现
1)锁是一种资源,需要存储;要保证可用性,避免全局失效;
2)加锁对象和解锁对象必须为同一个;
3)实现互斥语义,即必须对一个锁进行一个标记;其他进程就可以通过这个标记知道这个锁是否被占用了;
4)加锁和解锁的行为是网络通信;需要考虑锁超时;
5)怎么获取持有锁对象释放锁信息;可以主动通过网络去探测,也可以通过含有锁对象的相关进程被动通知;被动通知可通过广播的方式(非公平锁),也可以通过排队单独通知(公平锁);
6)是否允许同一持锁对象多次加锁?如果允许是重入锁,如果不允许则是非重入锁;
mysql实现分布式锁
mysql需要把lock锁进行存储,并实现互斥性;mysql有不同业务类型的锁,不同业务类型的锁可以用一行存储;

redis实现分布式锁
redis是内存数据库,数据结构数据库,kv数据库;
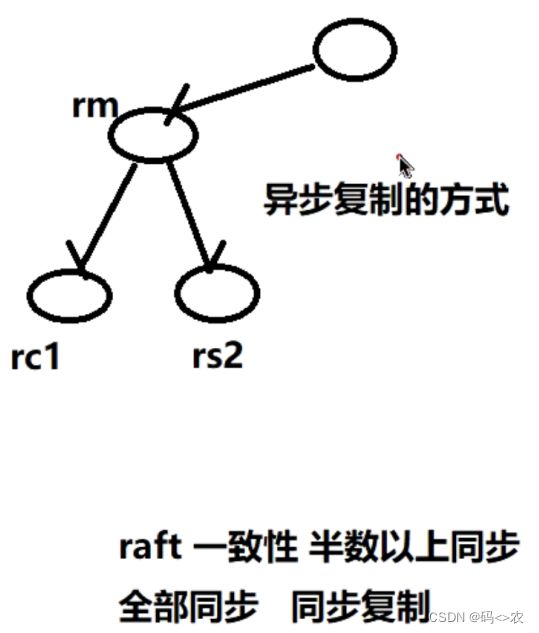
假设这里含有lock锁的是redis,并且其它持锁对象能够访问得到;要保证redis是可访问,并且保证可用性,可用性可通过哨兵模式,cluster模式实现;但是容错性是有问题的,因为redis中不管是哨兵模式,还是cluster模式都涉及到备份节点,备份是通过异步复制的方式实现,异步复制的意思是服务去操作redis的时候,只要主存储写成功了,就立刻返回,然后master存储会立刻同步到其他数据库当中,而同步复制的意思则是server去操作redis,去操作master存储,需要等待master存储同步到其他存储中只要在半数以上才返回;也有同步到其他存储中都同意才返回;
分布式中的原子性问题:几条语句的执行不会受其他语句的干扰,redis的lua脚本可以做到这一点;

什么是redlock
这里假设有五个redis进程,R1,R2,R3,R4,R5分别分布在不同机器中;那么如何解决容错性的问题呢?因为主从复制最终都是异步复制,这种情况下会造成主从复制不一致,这是就会出现主存储锁的机器宕机了 ,然后解锁是发现没有对应锁可解;

redis集群,都是采用主从复制来备份节点,因为主从复制都是异步复制的方式,会导致数据容易丢失,导致锁可能丢失,从而导致锁根本解不了;要解决这个问题的话,这里准备了R1,R2,R3,R4,R5独立进程,而且都是主进程,没有备份数据;我们加锁时所有的进程一般超时多久,是和网络交互时间有关系的,要远远大于网络交互时间;这五个进程每一次加锁,一定要往每一个进程执行set加锁语句,比如S1要往R1,R2,R3,R4,R5进程加锁,至少要半数以上加锁成功,才说明加锁成功了;解锁则需要对每个进程执行解锁操作,也是需要半数以上成功;
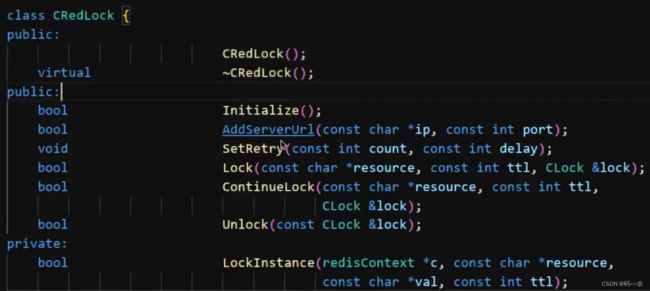
这里源码中Lock是加锁,ContinueLock是续锁;什么是续锁:假设S1进程加锁成功了,然后S1操作临界资源,操作临界资源的过程中可能超过了锁过期时间,这个时候想续时间;不续锁可能超过时间锁就被释放掉了,这时其他进程已经去获取锁了,这是S1还傻乎乎的去解锁;Unlock函数时释放锁的意思;