FLUME-NG 使用总结
FLUME-NG 使用总结
- 1、Flume-NG 概述
- 2、Flume-NG 架构设计要点
- 3、Flow Pipeline
- 4、Flume NG 三个组件概要
-
- 4.1、FlumeSource
- 4.2、FlumeChannel
- 4.3、FlumeSink
- 5、入门应用
-
- 5.1、flume-ng 通过网络端口采集数据
- 5.2、flume-ng 通过Exec tail采集数据
- 5.3、可能遇到的问题
1、Flume-NG 概述
Flume-NG 是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的 Flume OG 到现在的 Flume NG,进行了架构重构,并且现在 NG 版本完全不兼容原来的 OG 版本。经过架构重构后,Flume NG 更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持 failover 和负载均衡。
2、Flume-NG 架构设计要点
Flume 的架构主要有以下几个核心概念:
(1)Event:一个数据单元,带有一个可选的消息头;
(2)Flow:Event 从源点到达目的点的迁移的抽象;
(3)Client:操作位于源点处的 Event,将其发送到 Flume Agent;
(4)Agent:一个独立的 Flume 进程,包含组件 Source、Channel、Sink;
(5)Source:用来消费传递到该组件的 Event;
(6)Channel:中转 Event 的一个临时存储,保存有 Source 组件传递过来的 Event;
(7)Sink:从 Channel 中读取并移除 Event,将 Event 传递到 Flow Pipeline 中的下一个 Agent(如果有的话)。
Flume NG架构,如图所示:

外部系统产生日志,直接通过 Flume 的 Agent 的 Source 组件将事件(如日志行)发送到中间临时的 channel 组件,最后传递给 Sink 组件,HDFS Sink 组件可以直接把数据存储到 HDFS 集群上。
一个最基本Flow的配置,格式如下:
# 定义这个 agent 中各个组件的名字(此 agent 别名为 a1)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = ...
a1.sources.r1.bind = ...
a1.sources.r1.port = ...
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = ...
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = ...
a1.channels.c1.capacity = ...
a1.channels.c1.transactionCapacity = ...
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们可以根据实际需求或业务来修改各组件名称(a1,r1,k1,c1)。
下面详细说明:
a1 表示配置一个 Agent 的名称,一个 Agent 肯定有一个名称。r1 是 Agent的 Source 组件的名称,消费传递过来的 Event。c1 是 Agent 的Channel 组件的名称。k1 是 Agent 的 Sink 组件的名称,从 Channel 中消费(移除)Event。
上面配置内容中,第一组中配置 Source、Sink、Channel,它们的值可以有1个或者多个;
第二组中配置 Source 将把数据存储(Put)到哪一个 Channel 中,可以存储到 1 个或多个 Channel 中,同一个 Source 将数据存储到多个Channel 中,实际上是 Replication;
第三组中配置 Sink 从哪一个 Channel中取(Task)数据,一个 Sink 只能从一个 Channel 中取数据。
第四组中配置 Channel 中数据存储方式。
第五组中描述和配置 source channel sink 之间的连接关系。
3、Flow Pipeline
下面,根据官网文档,我们展示几种Flow Pipeline,各自适应于什么样的应用场景:
(1)多个Agent顺序连接:
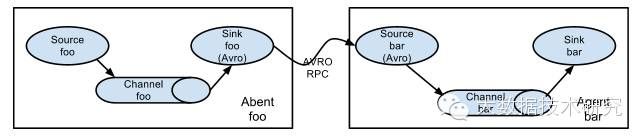
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
(2)多个Agent的数据汇聚到同一个Agent:
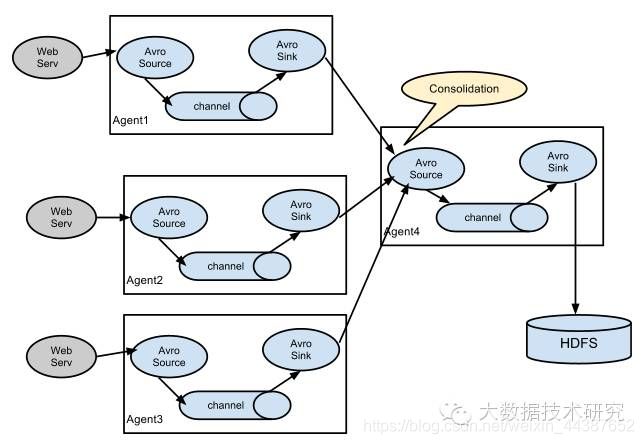
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志,Web网站为了可用性使用的负载均衡的集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
(3)多路(Multiplexing)Agent:
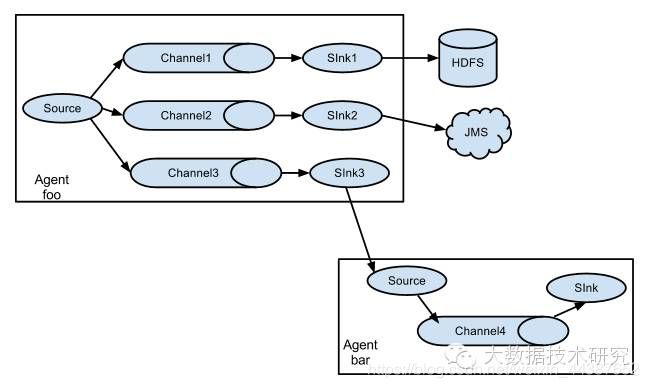
这种模式,有两种方式,一种是用来复制(Replication),另一种是用来分流(Multiplexing)。
Replication方式,可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的,配置格式,如下所示:
# Listthe sources, sinks and channels for the agent
.sources=
.sinks=
.channels=
# setlist of channels for source (separated by space)
.sources..channels=
# setchannel for sinks
.sinks..channel=
.sinks..channel=
.sources..selector.type= replicating
上面指定了selector的type的值为replication,其他的配置没有指定,使用的Replication方式,Source1会将数据分别存储到Channel1和Channel2,这两个channel里面存储的数据是相同的,然后数据被传递到Sink1和Sink2。
Multiplexing方式,selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:
# Mappingfor multiplexing selector
.sources..selector.type= multiplexing
.sources..selector.header=
.sources..selector.mapping.=
.sources..selector.mapping.=
.sources..selector.mapping.=
.sources..selector.default=
上面selector的type的值为multiplexing,同时配置selector的header信息,还配置了多个selector的mapping的值,即header的值:如果header的值为Value1、Value2,数据从Source1路由到Channel1;如果header的值为Value2、Value3,数据从Source1路由到Channel2。
(4)实现 load balance功能:
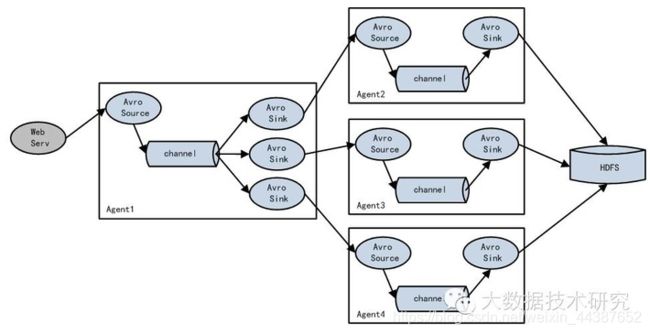
Loadbalancing Sink Processor能够实现load balance功能,上图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上,示例配置,如下所示:
a1.sinkgroups= g1
a1.sinkgroups.g1.sinks= k1 k2 k3
a1.sinkgroups.g1.processor.type= load_balance
a1.sinkgroups.g1.processor.backoff= true
a1.sinkgroups.g1.processor.selector= round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
实现failover功能:
FailoverSink Processor能够实现failover功能,具体流程类似loadbalance,但是内部处理机制与load balance完全不同:Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。如果一个Sink能够成功处理Event,则会加入到一个Pool中,否则会被移出Pool并计算失败次数,设置一个惩罚因子,示例配置如下所示:
a1.sinkgroups= g1
a1.sinkgroups.g1.sinks= k1 k2 k3
a1.sinkgroups.g1.processor.type= failover
a1.sinkgroups.g1.processor.priority.k1= 5
a1.sinkgroups.g1.processor.priority.k2= 7
a1.sinkgroups.g1.processor.priority.k3= 6
a1.sinkgroups.g1.processor.maxpenalty= 20000
4、Flume NG 三个组件概要
4.1、FlumeSource
| Source类型 | 描述 |
|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 |
| Spooling Directory Source | 监控指定目录内数据变更 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本)Flume Sink |
4.2、FlumeChannel
| Channel类型 | 描述 |
|---|---|
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
4.3、FlumeSink
| Sink类型 | 描述 |
|---|---|
| HDFS Sink | 数据写入HDFS |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回放 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃到所有数据 |
| HBase Sink | 数据写入HBase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink | 写数据到Kite Dataset,试验性质的 |
| Custom Sink | 自定义Sink实现 |
另外还有 ChannelSelector、Sink Processor、EventSerializer、Interceptor等组件,可以参考官网提供的用户手册。
5、入门应用
5.1、flume-ng 通过网络端口采集数据
(1)创建配置文件 example_telnet.conf,配置如下:
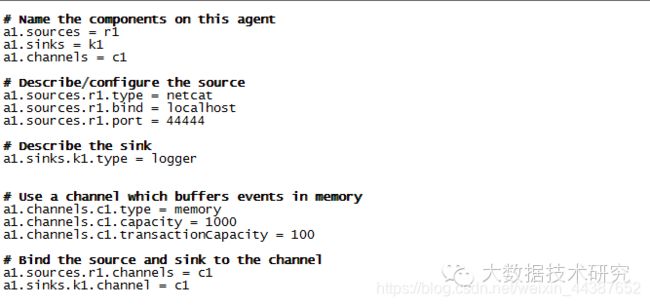
(2)启动 agent:
flume-ngagent --conf conf --conf-file example_telnet.conf --name a1 -Dflume.root.logger=INFO,console
(3)链接配置文件中设置的端口:
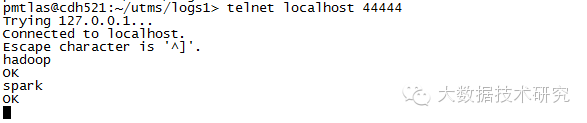
(4)测试:分别输入hadoop,spark两个单词:

source 是端口,sink 是 logger ,在 flume 的 agent 日志中显示已接收。
5.2、flume-ng 通过Exec tail采集数据
(1)创建配置文件 example_tail.conf,配置如下:
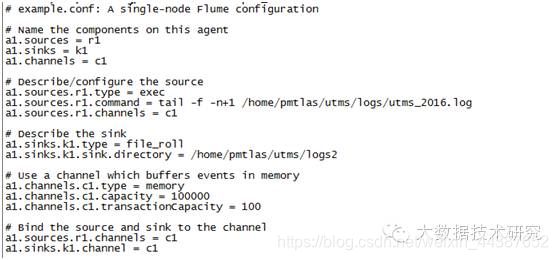
source 配置的是 exec tail -f ,
sink 配置的是 file_rool,这样flume采集的数据会写到新目录里。
(2)启动 Flume NG
flume-ngagent --conf conf --conf-file example_tail.conf --name a1 -Dflume.root.logger=INFO,console
(3)测试,向文件中写入信息:

可以查看FileRoll Sink对应的本地文件系统目录/home/pmtlas/utms/logs2/下,示例如下所示:

5.3、可能遇到的问题
(1)OOM 问题:
flume 报错:java.lang.OutOfMemoryError: GC overhead limit exceeded
或者:java.lang.OutOfMemoryError:Java heap space
Exceptionin thread "SinkRunner-PollingRunner-DefaultSinkProcessor"java.lang.OutOfMemoryError: Java heap space
Flume 启动时的最大堆内存大小默认是 20M,线上环境很容易 OOM,因此需要你在 flume-env.sh 中添加 JVM 启动参数:
JAVA_OPTS="-Xms8192m -Xmx8192m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
然后在启动 agent 的时候一定要带上 -c conf 选项,否则flume-env.sh 里配置的环境变量不会被加载生效。
(2)JDK 版本不兼容问题:
2020-09-1712:36:12,902 (agent-shutdown-hook) [WARN -org.apache.flume.sink.hdfs.HDFSEventSink.stop(HDFSEventSink.java:504)]Exception while closing hdfs://192.168.1.111:8020/flumeTest/FlumeData.Exception follows.
java.lang.UnsupportedOperationException:This is supposed to be overridden by subclasses.
atcom.google.protobuf.GeneratedMessage.getUnknownFields(GeneratedMessage.java:180)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos G e t F i l e I n f o R e q u e s t P r o t o . g e t S e r i a l i z e d S i z e ( C l i e n t N a m e n o d e P r o t o c o l P r o t o s . j a v a : 30108 ) a t c o m . g o o g l e . p r o t o b u f . A b s t r a c t M e s s a g e L i t e . t o B y t e S t r i n g ( A b s t r a c t M e s s a g e L i t e . j a v a : 49 ) a t o r g . a p a c h e . h a d o o p . i p c . P r o t o b u f R p c E n g i n e GetFileInfoRequestProto.getSerializedSize(ClientNamenodeProtocolProtos.java:30108) atcom.google.protobuf.AbstractMessageLite.toByteString(AbstractMessageLite.java:49) atorg.apache.hadoop.ipc.ProtobufRpcEngine GetFileInfoRequestProto.getSerializedSize(ClientNamenodeProtocolProtos.java:30108)atcom.google.protobuf.AbstractMessageLite.toByteString(AbstractMessageLite.java:49)atorg.apache.hadoop.ipc.ProtobufRpcEngineInvoker.constructRpcRequest(ProtobufRpcEngine.java:149)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:193)
把你的 jdk7 换成 jdk6 试试。
(3)小文件写入 HDFS 延时的问题:
flume 的 sink 已经实现了几种最主要的持久化触发器:
比如按大小、按间隔时间、按消息条数等等,针对你的文件过小迟迟没法写入 HDFS 持久化的问题,那是因为你此时还没有满足持久化的条件,比如你的行数还没有达到配置的阈值或者大小还没达到等等,可以针对配置微调下,例如:
agent1.sinks.log-sink1.hdfs.rollInterval= 20
当迟迟没有新日志生成的时候,如果你想很快的 flush,那么让它每隔 20s flush 持久化一下,agent 会根据多个条件,优先执行满足条件的触发器。
下面贴一些常见的持久化触发器:
# Numberof seconds to wait before rolling current file (in 600 seconds)
agent.sinks.sink.hdfs.rollInterval=600
# Filesize to trigger roll, in bytes (256Mb)
agent.sinks.sink.hdfs.rollSize= 268435456
# neverroll based on number of events
agent.sinks.sink.hdfs.rollCount= 0
# Timeoutafter which inactive files get closed (in seconds)
agent.sinks.sink.hdfs.idleTimeout= 3600
agent.sinks.HDFS.hdfs.batchSize= 1000
注意:对于HDFS 来说应当竭力避免小文件问题,所以请慎重对待你配置的持久化触发机制。
(4)数据重复写入、丢失问题:
Flume的HDFSsink在数据写入/读出Channel时,都有Transcation的保证。当Transaction失败时,会回滚,然后重试。但由于HDFS不可修改文件的内容,假设有1万行数据要写入HDFS,而在写入5000行时,网络出现问题导致写入失败,Transaction回滚,然后重写这10000条记录成功,就会导致第一次写入的5000行重复。这些问题是 HDFS 文件系统设计上的特性缺陷,并不能通过简单的Bugfix来解决。我们只能关闭批量写入,单条事务保证,或者启用监控策略,两端对数。
Memory和exec的方式可能会有数据丢失,file 是 end to end 的可靠性保证的,但是性能较前两者要差。
end to end、store on failure 方式 ACK 确认时间设置过短(特别是高峰时间)也有可能引发数据的重复写入。
(5)tail 断点续传的问题:
可以在 tail 传的时候记录行号,下次再传的时候,取上次记录的位置开始传输,类似:
agent1.sources.avro-source1.command= /usr/local/bin/tail -n +$(tail -n1/home/storm/tmp/n) --max-unchanged-stats=600 -F /home/storm/tmp/id.txt | awk 'ARNGIND==1{i=$0;next}{i++; if($0~/文件已截断/)i=0; print i >> "/home/storm/tmp/n";print$1"---"i}' /home/storm/tmp/n -
需要注意如下几点:
第 1 点,文件被 rotation 的时候,需要同步更新你的断点记录“指针”;
第 2 点,需要按文件名来追踪文件;
第 3 点,flume 挂掉后需要累加断点续传“指针”;
第 4 点,flume 挂掉后,如果恰好文件被 rotation,那么会有丢数据的风险,只能监控尽快拉起或者加逻辑判断文件大小重置指针;
第 5 点,tail 注意你的版本,请更新 coreutils 包到最新。