MIA | Multi-modal contrastive mutual learning and pseudo-label re-learning for semi-supervised medic
MIA|Multi-modal contrastive mutual learning and pseudo-label re-learning for semi-supervised medical image segmentation
论文标题: Multi-modal contrastive mutual learning and pseudo-label re-learning for semi-supervised medical image segmentation
论文发表期刊: Medical Image Analysis
论文地址: https://doi.org/10.1016/j.media.2022.102656
论文代码: 无
论文数据集: https://zhenghuaxu.info/publications/
零、个人总结
两个模态的融合过程通常需要在训练阶段进行权值共享或复杂的特征拼接(即高耦合),这导致在推理阶段需要同时馈送两个模态的图像数据。因此,需要在推理阶段只使用一种模态的多模态半监督模型来进行精确的医学图像分割是迫切的。
提出了一种新的低耦合多模态半监督分割框架Semi-CML和PReL,该框架可以在训练阶段充分考虑未标注多模态数据之间的潜在相关性和差异,并且在推理阶段仅使用一种模态进行准确的医学图像分割。
提出了一种新的ASC损失函数,该算法在半监督医学图像分割任务中取得了更好的分割效果。ASC损失函数目的是为了基于对比学习的跨模态互学习算法(1)最大化不同模态之间的预测相似性来学习不同模态间的一致性信息;(2)最小化负样本对之间的相似性来学习不同模态之间的差异信息。此前半监督使用MSE Loss,但是MSE只能关注相似性,不能关注不相似性,使得网络容易陷入过拟合;同时MSE只考虑两个预测图中每个像素之间的欧氏距离度量,而不能关注预测目标的边缘和区域上下文信息。
为了弥补不同模态之间的性能差距,进一步提出了一种软伪标签再学习(PReL)方案,该方案基于最佳模型移动平均(BMA)方法,利用高性能模态模型作为教师模型,生成高精度的软伪标签,用于低性能模态模型的再学习。常规半监督网络中的教师模型使用EMA更新网络参数,这可能会导致当模型效果差时更新权重会降低教师模型的可靠性。本文的BMA通过选择性的更新教师模型的权重,只选最优或次优的模型权重更新到教师模型。
一、摘要
半监督学习在少量标记数据的医学图像分割任务中具有很大的潜力,但大多数只考虑单模态数据。多模态数据的优良特性可以提高图像各模态的半监督分割性能。然而,现有的多模态解决方案的缺点是,由于多模态数据对应的处理模型是高度耦合的,不仅在训练阶段需要多模态数据,而且在推理阶段也需要多模态数据,这限制了其在临床实践中的应用。因此,我们提出了一种半监督对比互学习(Semi-CML)分割框架,其中一种新的区域相似对比(ASC)损失利用不同模态之间的跨模态信息和预测一致性进行对比互学习。虽然Semi-CML可以同时提高两种模态的分割性能,但两种模态之间存在性能差距,即存在一种模态的分割性能通常优于另一种模态。因此,我们进一步提出了软伪标签再学习(PReL)方案来弥补这一差距。我们在两个公开的多模态数据集上进行了实验。结果表明,带有PReL的Semi-CML大大优于目前最先进的半监督分割方法,并且与100%标记数据的完全监督分割方法实现了相似(有时甚至更好)的性能,同时将数据注释成本降低了90%。我们还进行了消融研究,以评估ASC损失和PReL模块的有效性。
二、引言
近年来,深度学习技术在医学图像分析方面取得了一些巨大的成功,其中监督学习是最常用的解决方案,但通常需要大量的人工标注数据。然而,标注医学图像是一项高度专业化的任务,通常只能由具有丰富临床经验的放射科医生完成。由于专业放射科医生的数量、时间和标注效率有限,获得具有准确标注的大型医学图像数据集通常非常困难,从而限制了监督学习在实际临床实践中的使用。该问题的经典解决方案是半监督学习,其中少量标注数据和大量未标注数据一起用于深度模型的学习,以消除对大量昂贵标注数据的需求,同时保持令人满意的性能。然而,现有的半监督方法大多基于单模态数据,缺乏在多模态医学图像中利用有效信息的能力。
具体而言,已知一些医学成像方法可以生成多模态的医学图像,例如磁共振成像(MRI)可以生成T1、T1CE、T2和FLAIR四种模态的图像,正电子发射断层扫描(PET)可以与计算机断层扫描(CT)一起获得PET和CT扫描。为了充分利用多模态数据,目前已经提出了许多不同的全监督多模态融合分类和分割网络。然而,这些方法不能使用大量未标注的多模态数据,这限制了它们的性能。因此,一些研究倾向于使用半监督学习来利用未标注的多模态数据,但这些方法主要关注多模态分类和聚类任务。据我们所知,只有少数作品的目标是多模态半监督医学图像分割。然而,无论是否使用未标注的多模态数据,这些多模态分割方法都有一个共同的缺点。缺点是两个模态的融合过程通常需要在训练阶段进行权值共享或复杂的特征拼接(即高耦合),这导致在推理阶段需要同时馈送两个模态。这极大地限制了这些模型在临床实践中的应用,因为拍摄多模态的医学图像非常耗时和昂贵,并且在实践中通常只能获得单一模态的医学图像用于成像诊断。因此,需要在推理阶段只使用一种模态的多模态半监督模型来进行精确的医学图像分割是迫切的。
本文提出利用大量未标注的多模态数据,通过网络对不同模态的深度学习来提高各模态的分割性能,其中提出了一种新的对比损失来最小化两种图像模态的预测差异,从而得到多个单模态推理网络。我们称这个框架为半监督对比相互学习(Semi-CML)。具体而言,我们首先对不同模态的预测图进行均方误差(MSE)一致性损失,以实现不同模态之间的简单相互学习。然而,我们发现MSE损失不够好,因为(i)它没有考虑图像内的区域上下文信息,这对于医学图像分割任务通常很重要;(ii)它只旨在最小化正样本对之间的差异,而不能最大化负样本对之间的差异。因此,我们建议利用对比损失来解决这个问题。尽管最先进的对比损失,噪声对比估计(NCE)损失,可以最大化负样本之间的差异,区域上下文信息在NCE中仍然没有被考虑,从而限制了它的性能。因此,我们提出了一种改进的对比损失,称为面积相似对比损失(Area-Similarity contrast loss, ASC)。与传统的对比学习方法不同,ASC有以下两个优势:(1) ASC创造性地将Dice相似度融入到对比学习中,使得在学习中考虑区域上下文信息成为可能;(2)ASC可以绕过投影头,直接对预测的分割图进行基于区域的对比学习,无需ground-truth,从而直接有效地提高了半监督语义分割的性能。在多模态图像的互学习过程中,ASC损失可以最大化不同模态的预测分割图之间互信息的下界,从而获得更高的预测一致性。因此,损失使得网络深度学习不同图像模态之间潜在的互补信息,这在两模态之间的相互学习中起着至关重要的作用。
我们注意到不同模态之间存在性能差距。尽管Semi-CML可以缓解这个问题,但总有一种模态的性能相对较低。因此,为了进一步提高低性能图像模态模型的分割能力,我们利用对未标记的高性能图像模态的预测,开发了一种软伪标签再学习(PReL)方案。具体而言,通过一种改进的指数移动平均自集成技术,即最佳模型移动平均(BMA),将高性能模态模型用作具有更高置信度的教师模型。我们使用BMA更新策略得到一个更可靠的教师模型,称为最佳模型移动平均自集成教师模型(Best-model Moving Average self-ensembling teacher model, BMA teacher)。因此,使用BMA教师进行软伪标签再学习的半监督对比互学习框架被称为带PReL的半监督对比互学习框架。本工作的贡献简述如下:
- 我们确定了多模态分割方法的一个共同缺点:它们在推理阶段需要所有模态的图像,从而限制了它们在临床实践中的应用。为了缓解这一问题,在本工作中,我们提出了一种新的低耦合多模态半监督分割框架Semi-CML和PReL,该框架可以在训练阶段充分考虑未标注多模态数据之间的潜在相关性和差异,并且在推理阶段仅使用一种模态进行准确的医学图像分割。
- 为了更好地利用对比学习中的区域上下文信息,我们首先提出了一种新的ASC损失算法,该算法在半监督医学图像分割任务中取得了更好的分割效果。为了弥补不同模态之间的性能差距,我们进一步提出了一种软伪标签再学习(PReL)方案,该方案基于最佳模型移动平均(BMA)方法,利用高性能模态模型作为教师模型,生成高精度的软伪标签,用于低性能模态模型的再学习。
- 我们在两个公共的多模态医学图像分割数据集上进行了大量的实验。结果表明:(i)带PReL的Semi-CML实现了与100%标记数据的完全监督分割方案相似(有时甚至更好)的性能,并且大大优于目前最先进的半监督分割方法;(ii)所提出的ASC损失和PReL方案对于我们的模型实现优异的性能都是有效的和必不可少的。
三、方法
3.1 半监督对比互学习
受多模态数据内在相关性和对比自监督学习的潜在价值的启发,为了克服多模态融合模型中的高耦合问题,我们提出了一种新的低耦合半监督对比互学习框架Semi-CML,用于多模态图像分割,如图1所示。Semi-CML框架可以通过使用大量未标注数据的低耦合一致性损失对多模态数据进行跨模态知识互学习。具体而言,首先,我们构建了两个U-Net,它们具有相同的结构,作为两种不同模态的分割网络主干。然后,通过两个U-Net的前向传播获得两个不同模态的小批预测图,其中两种模态的标注批次执行监督学习。其次,对于两种模态之间的相互学习,将两种模态的未标注批次输入到简单相互学习的MSE损失中,并将提出的区域相似度对比损失用于深度相互学习。

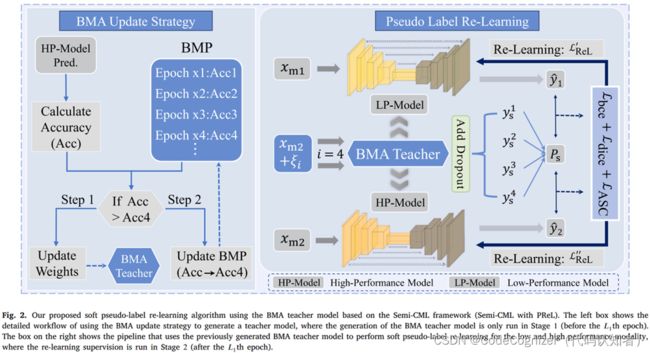
3.2 基于BMA教师模型的软伪标签再学习
虽然上述方法极大地提高了两种模态的分割性能,但我们的实验表明,两种模态的分割性能之间存在差距,即通常存在一种模态的分割性能优于另一种模态。为了进一步提高低性能模态的分割精度,我们利用具有高性能模态的模型设计了一种软伪标签再学习策略,如图2和算法1所示。具体来说,在EMA加权模型和Dropout作为贝叶斯近似的激励下,我们首先设计了一种新的最佳模型移动平均(BMA)自集成技术,以在阶段1(即在Semi-CML达到收敛的某个epoch之前,1)生成最优且可靠的教师模型。该教师模型称为最佳模型移动平均自集合教师模型(BMA teacher)。其次,在第2阶段(1 epoch之后),我们使用BMA教师模型和蒙特卡罗dropout抽样来生成具有更高可靠性的软伪标签。然后,使用软伪标签对低性能模态进行再学习。此外,教师模式对高性能模式也有帮助。因此,对高性能模型也执行重新学习过程,但在预热阶段之后开始。我们假设模型1和模型2是低性能和高性能模型。
四、实验
4.1 数据集
为了验证我们方法的有效性,我们对两个公开可用的多模态数据集进行了广泛的评估,MICCAI 2020 Hecktor挑战和BraTS 2019挑战赛。每个数据集基于患者级3D图像体积随机分为两部分:80%的3D图像体积作为训练集,另外20%作为测试集。然后,我们从每个3D体的Z轴中获取切片数据进行2D图像分割,并仅去除背景切片(不包含病变),以防止数据不平衡。最后,我们获得Hecktor数据集的5788片和BraTS数据集的13850片。数据集和预处理的细节如下。
Hecktor:该数据集由MICCAI 2020挑战提供,称为头颈部肿瘤分割挑战(Hecktor),这是一个由201个3D图像体积组成的多模态CT-PET数据集。所有CT体积在[−150,150]HU(Hounsfield Units)范围内进行裁剪。PET体积在0到1的范围内进行Max-min归一化。两种模式的所有切片都被裁剪为144×144的大小。
BraTS 2019:该数据集设计用于使用多模态磁共振成像(MRI)扫描进行脑肿瘤分割,包含259个高级别胶质瘤(HGG)数据和76个低级别胶质瘤(LGG)数据,我们仅在实验中使用HGG数据。数据集包含四种模式:T1、T1CE、T2和FLAIR。任务是分割三个区域,即整个肿瘤(WT),增强肿瘤(ET)和肿瘤核心(TC)。每个体积归一化为零均值和单位方差;切片中间裁剪为160×160的大小。
4.2 对比实验
4.2.1 与最先进的全监督方法的比较
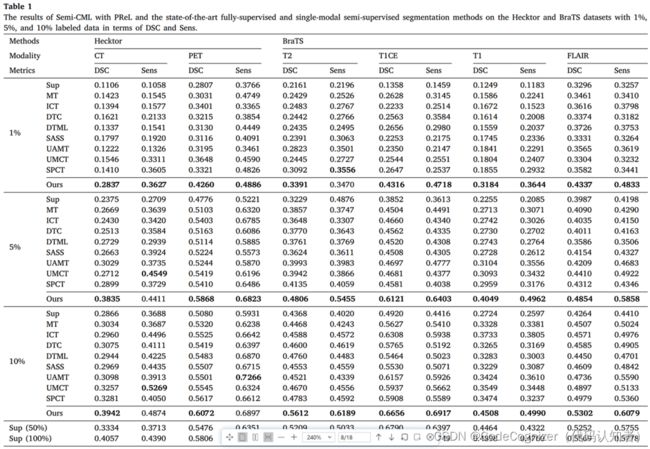
我们首先在两个数据集上使用1%、5%和10%的标记数据,将我们的方法与完全监督方法(标记为Sup)进行比较。表1中的结果表明,我们的半监督模型在两个数据集的任何模式下都有显著的改进。例如,当仅使用1%的标记Hecktor数据时,我们的方法在CT和PET模式上的DSC结果分别为0.2837和0.4260;但如果使用全监督学习方法(Sup),它们仅为0.1106和0.2807。此外,我们的方法在使用5%标记数据的BraTS上的T2和T1CE模式的DSC结果比Sup高0.1577和0.2269;而使用10%标记数据时,T1和FLAIR模式对BraTS的增加分别为0.1784和0.1038。然后,我们将我们的方法与使用更多标签的完全监督解决方案进行比较。我们的模型(使用10%标记数据)的分割结果超过了使用50%标记数据的大多数Sup的结果,并且接近使用100%标记数据的Sup的结果。特别是,在Hecktor数据集上,我们的方法(使用10%的标记数据)通常优于使用100%标记数据的完全监督方法。这些都证明了我们的方法在利用大量未标记数据帮助深度模型实现巨大性能提升方面的有效性。
4.2.2 与最先进的单模态半监督方法的比较
几种最先进的半监督单模态分割方法也被作为基线,包括平均教师(MT)、插值一致性训练(ICT)、双任务一致性(DTC)、双任务相互学习(DTML)、形状感知半监督(SASS)、不确定性感知平均教师(UAMT)、不确定性感知多视角协同训练(UMCT)和自定节奏自一致协同训练(SPCT)。由于这些方法是针对单模态图像设计的,而我们的方法在推理阶段只需要一个模态(多模态数据只在训练阶段使用),所以我们选择了上述方法,并使用两种模态的数据训练它们的模型,与我们的方法进行比较。结果如表1所示。
总的来说,在几乎所有情况下,我们的方法在DSC和Sens方面都明显优于所有最先进的单模态半监督方法,这证明了我们的工作具有优越的医学图像分割性能。此外,还提出了其他一些看法。首先,与全监督方法(Sup)相比,所有的半监督分割方法都获得了一定的性能提升,这表明半监督分割方法可以有效地利用未标注的数据来提高模型的性能。其次,与其他半监督方法相比,协同训练方法获得了更好的分割性能,证明了多视图协同训练的有效性。第三,现有的单模态半监督方法对于Hecktor和BraTS上的低性能图像模态的性能改进通常很差。例如,使用10%的标记数据,与全监督方法(Sup)相比,最佳基线(SPCT)在低性能模式(CT、T2和T1)中的DSC改进仅为0.0415、0.0415和0.0750,而在相应的高性能模式(PET、T1CE和FLAIR)中的DSC改进分别为0.0537、0.0988和0.0715。然而,我们的方法可以在低性能和高性能模式下实现显着的性能改进。例如,对于10%的标记数据,与全监督方法相比,我们的方法在低性能模式CT,T2、T1上的DSC改进分别为0.1076,0.1244和0.1784;而PET、T1CE和FLAIR对应的高性能模式,分别为0.0992、0.1736和0.1038。这些结果充分表明,在CML和PReL的相互学习的帮助下,我们的方法可以利用两种模式的信息进行互补,从而在两种模式下都取得了很大的性能提升。
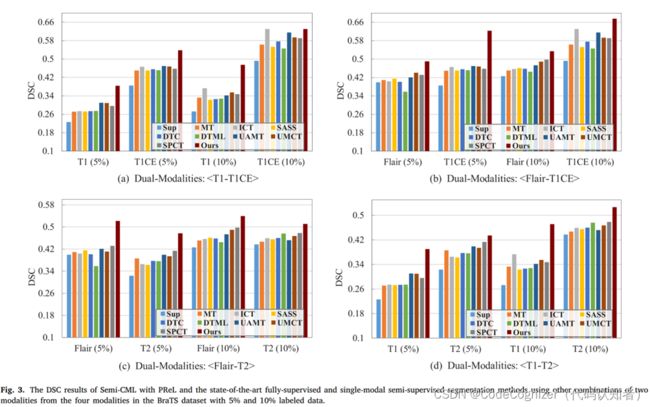
为了进一步验证我们提出的方法的有效性,还使用BraTS数据集中四种模式中的两种模式的其他组合进行评估;图3显示了使用5%和10%标记数据的四组DSC实验结果。总的来说,我们的方法在两种模式的任意组合下仍然比最先进的全监督和半监督分割方法获得更好的分割性能。为了定性地展示我们提出的方法的优越性能,我们将我们的方法、全监督方法和半监督基线的分割结果可视化,其中包含10%的标记数据,如图4所示。我们展示了在Hecktor数据集中对应相同切片数的CT和PET图像的结果,以及在BraTS数据集中对应T2和T1CE的结果。在图4中,我们的方法显示出比基线更高的病变区域重叠率和更少的假阳性。此外,对于给定的一对多模态图像,我们的工作产生的分割结果比基线的结果更加一致。这是因为我们的方法利用相互学习来帮助不同的模型相互学习,使它们的预测更好、更接近。因此,我们得出结论,多模态数据中的信息非常重要,应该用于半监督医学图像分割任务。
4.2.3 与最先进的多模态半监督方法的比较
此外,为了证明我们的工作的优越性能不仅仅来自多模态信息,而且由于其技术优势,我们进一步将我们的方法与现有的多模态半监督分割解决方案DAFNet和few-shot GAN以及MT, ICT, DTC, DTML, SASS, UAMT, UMCT和SPCT的多模态扩展版本进行了比较。具体来说,扩展是通过使用双模态融合模型(U-Net网络具有双编码器和共享解码器)并同时将双模态图像馈送到网络中来实现的。根据表2的结果,我们首先发现,与表1中原始的单模态模型相比,多模态模型的分割性能有了很大的提高。因此,这证明了使用多模态数据可以提高模型的性能,因此在医学图像分割任务中利用多模态信息是很重要的。其次,我们提出的方法大大优于现有的两种多模态半监督方法(即DAFNet和FewGAN),当所有模型都使用两种模态进行训练并仅使用一种模态进行推断时,扩展的多模态半监督方法在几乎所有情况下都能在两个数据集上工作(最好的结果是粗体);此外,即使DAFNet、FewGAN和扩展的多模态半监督方法使用两种模态进行推理,我们的方法(仅使用一种模态进行推理)仍然可以获得与它们的双模态推理结果(特别是在T1-FLAIR情况下)相当的性能,有时甚至更好(最好的结果被下划线)。这是因为多模态半监督基线通常是高度耦合的融合网络,因此在推理阶段需要双模态信息以确保满意的结果;因此,当只有一种模态进行推理时,由于缺乏其他模态的信息,它们通常会有很大的性能下降。例如,MM-UAMT在进行T2-T1CE双峰推理时的DSC为0.7069,但在仅使用T1CE进行推理时,其DSC仅为0.1066。然而,对于我们的方法,学习到两种模态的分割模型是非常独立的,所以它只需要一个模态进行推理,它的单模态推理结果接近甚至有时超过了多模态基线的双模态推理结果。因此,我们的方法更容易在临床实践中使用,因为它只需要一种医学图像的模态就可以获得满意的分割结果,大大减少了患者的时间和金钱成本。
4.2.4 消融实验
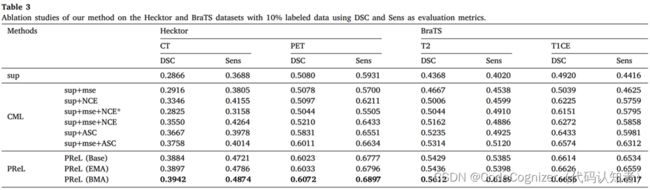
为了验证我们的半监督分割方法的有效性,我们对两个数据集进行了消融实验,结果如表3所示,其中CML代表半CML, PReL代表带PReL的半CML。
五、结论
本文提出了一种基于PReL的多模态半监督分割框架Semi-CML。该体系结构利用无标注的多模态数据进行相互监督学习,实现医学图像的精确分割。具体来说,借助面积相似度对比损失,一个模态模型可以从另一个模态中学习互补信息,同时提高了所有模态的分割性能。此外,我们设计了一种基于BMA教师模型的软伪标签再学习方案,进一步提高低性能模态的分割性能。我们在多个数据集上进行了大量实验,结果表明,我们提出的方法(仅使用一小部分标注数据)的性能接近或有时甚至优于100%标记数据的全监督方法,并且我们提出的方法也通常优于最先进的半监督解决方案。此外,我们的工作可以在只有一种模态数据的情况下进行推理,并且相应的分割结果接近甚至超过了使用多模态数据进行推理的最先进的半监督多模态模型。因此,我们的方法更容易在临床实践中使用,并将大大减少患者的时间和金钱成本。