Debezium发布历史120
原文地址: https://debezium.io/blog/2022/04/07/read-only-incremental-snapshots/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
Read-only Incremental Snapshots for MySQL
April 7, 2022 by Kate Galieva
mysql snapshots
最近,位于斯博皮策的工程团队改进了Debezizmysql连接器,使其支持在没有连接器写入访问的情况下对数据库进行增量快照,这是指向Debezum到只读副本时所必需的。此外,Debezizmysql连接器现在还允许在增量快照期间对架构进行更改。这篇博文解释了这些功能的实现细节。
为什么是只读的?
德贝兹加了 递增式快闪功能 在1.6版中,网飞公司宣布 其变化数据采集框架 .在商店里, 我们使用德贝兹来获取变化数据(cds) 我们很期待成为早期的采用者。此外,我们希望有一个解决方案是写和锁没有。
"不写入"解决方案允许捕捉从Read复制品中获得的更改,并提供了最高的保证,即ccds不会在数据库方面造成数据损坏。
自从模式迁移障碍影响了其他项目的发展以来,过去我们不得不对迁移进行协调。解决方案是只在周末运行快照,因此,我们尽量少快照。我们也看到了改进这一部分进程的机会。
此博客帖子深入讨论了只读增量快照实现的技术细节,包括在mysql连接器的增量快照处理过程中的锁定无模式更改。
递增快照
… 德贝兹的增量快照 博客帖子详细涵盖默认实现。该算法使用两种信号的信令表:
snapshot-window-open/snapshot-window-close作为水印
execute-snapshot作为触发增量快照的一种方法
对于只读场景,我们需要用替代品来替换这两种类型的信号。
高水印和低水印显示主状态
解决方案是针对mysql的,它依赖于 全球交易标识符 .因此,你需要设置gtid_mode 到ON 如果您正在从读取副本中读取,则请配置数据库以保存Gtid订单。
先决条件:
gtid_mode = ON
enforce_gtid_consistency = ON
if replica_parallel_workers > 0 set replica_preserve_commit_order = ON
算法运行一个 显示主人身份 请求在块选择前后获得已执行的Gtid设置:
low watermark = executed_gtid_set
high watermark = executed_gtid_set - low watermark
在只读实现中,水印具有Gtid集的形式,例如。像这样:2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
这样的水印不会出现在双日志流中。相反,该算法将每个事件的Gtid与内存水印进行比较。实现确保没有陈旧的读取,并且块只具有不超过事件的更改,直到低水印。
带有只读水印的复制算法
在伪代码中,从双日志读取的事件和通过快照块检索到的事件的删除算法如下:
(1) pause log event processing
(2) GtidSet lwGtidSet := executed_gtid_set from SHOW MASTER STATUS
(3) chunk := select next chunk from table
(4) GtidSet hwGtidSet := executed_gtid_set from SHOW MASTER STATUS subtracted by lwGtidSet
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
append e to outputbuffer
if not inwindow then
if not lwGtidSet.contains(e.gtid) //reached the low watermark
inwindow := true
else
if hwGtidSet.contains(e.gtid) //haven’t reached the high watermark yet
if chunk contains e.key then
remove e.key from chunk
else //reached the high watermark
for each row in chunk do
append row to outputbuffer
// other steps of event processing loop
水印检查
数据库事务可以更改好几行。在本例中,多个绑定日志事件将具有相同的Gtid。由于GTDS不是唯一的,它影响了计算块选择窗口的逻辑.当水印的Gtid集不包含其Gtid时,事件会更新窗口状态。在事务完成和心跳等事件之后,将不再有任何相同Gtid的绑定日志事件。对于那些事件,它足以达到水印的上界触发窗口打开/关闭。
图片来自官网原文

图1块选择窗口
重复删除发生在块选择窗口中,与默认实现相同。最后,算法在高水印之后插入一个重复的块:
图片来自官网原文

图2一大块复制
表无更新
接收日志事件对于快照的进展至关重要。所以算法检查了 全部的 这些事件以及未包括的表格。
无绑定日志事件
mysql服务器在复制连接闲置X秒后发送一个心跳事件。只读实现使用心跳时,宾日志更新率较低。
心跳与最新的双日志事件具有相同的Gtid。因此,对于心跳来说,它足以达到高水印的上界。
算法使用了server_uuid 一个心跳的Gtid的一部分,从高水印获得最大事务标识。实现确保高水印包含一个单一的server_uuid .不变的server_uuid 允许在窗口因心跳过早关闭时避免出现这种情况。见下图作为一个例子:
图片来自官网原文
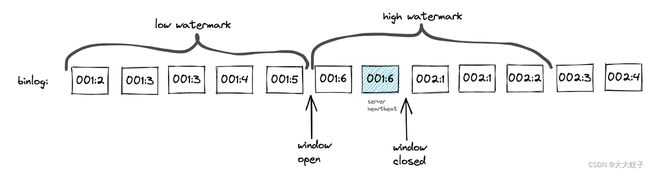
图3当窗口被心跳太早关闭时
与低水印进行心跳对比是不必要的,因为不管窗口是否打开都不重要。这简化了在高水印和低水印之间没有新事件时的检查。
水印之间无变化
当块选择过程中没有绑定日志事件时,一个双日志事件可以立即打开和关闭窗口。在这种情况下,高水印将是一个空集。在这种情况下,快照块会在低水印之后插入,而不会重复。
图片来自官网原文

图4一个空块选择窗口
基于卡夫卡主题的信号
Debezum支持通过插入到信号表中触发的临时增量快照。只读的选择是通过特定的卡夫卡主题发送信号。消息的格式模仿信号表的结构.一个执行者----------------------------------------------------------
data-collections-有待捕获的表格清单
type-定至递增
例子:
Key: dbserver1
Value: {“type”:“execute-snapshot”,“data”: {“data-collections”: [“inventory.orders”], “type”: “INCREMENTAL”}}
mysql连接器的配置有一个新的signal.kafka.topic 财产。主题必须有一个分区和删除保留策略。
一个单独的线程从卡夫卡主题检索信号消息。卡夫卡消息的键需要与连接器的名称匹配。database.server.name .连接器将跳过与连接器名称不对应的事件,并使用日志项。消息键检查允许重用多个连接器的信号主题。
连接器的抵消包括在运行增量快照时的增量快照上下文。只读实现将卡夫卡信号偏移添加到增量快照上下文中。保持对偏移量的跟踪,允许它在连接器重新启动时不会错过或重复处理信号。
但是,不需要使用卡夫卡执行只读增量快照和默认的execute-snapshot 写进信号表的信号也会起作用。展望未来,还可以设想用于触发临时增量快照的RESTAPI,或者是通过Debezum服务器公开,或者是部署到卡夫卡连接中的额外REST资源。
增量快照期间的架构更改
德贝兹米斯克连接器 允许在增量快照期间进行架构更改 .连接器将在增量快照期间检测架构更改,并重新选择当前块,以避免锁定DDS。
注意,不支持对主键的更改,如果在增量快照中执行,会导致错误的结果。
像mysq1分析数据定义语言(DDL)事件之类的历史化的德贝兹连接器ALTER TABLE 从双日志流。连接器保存每个表模式的内存中表示,并使用这些模式生成适当的更改事件。
增量快照实现两次使用了宾日志架构:
在从数据库中选择块时
在将块插入到双日志流时
块的架构必须在两个时候都与双日志架构相匹配。让我们详细地探讨算法是如何实现匹配模式的。
匹配块和双日志模式的选择
当增量快照查询数据库时,行具有表的最新模式。如果双日志流落后,内存架构可能与最新架构不同。解决方案是等待连接器在双日志流中接收DDL事件。此后,连接器可以使用缓存表的结构生成正确的增量快照事件。
使用JDBCAPI选择快照块。 结果表元数据 存储块的模式。挑战在于来自结果元数据的模式和来自宾基日志DDL的模式有不同的格式,因此很难确定它们是否相同。
该算法采用两个步骤来获得匹配的基于数据集的和基于ddl的模式。首先,连接器在低水印和高水印之间查询表的架构。一旦连接器检测到窗口关闭,就可以使用结果元数据更新宾日志架构。在此之后,连接器查询数据库以验证架构保持不变。如果架构改变了,那么连接器会重复这个过程。
该算法将匹配的结果集和双日志模式保存在内存中,使连接器能够将每个块的模式与缓存的结果集模式进行比较。
当一个块的模式与缓存的结果集模式不匹配时,连接器将删除选定的块。然后,该算法重复了匹配结果集和双日志模式的验证过程。然后,连接器从数据库中重新选择相同的块:
图片来自官网原文
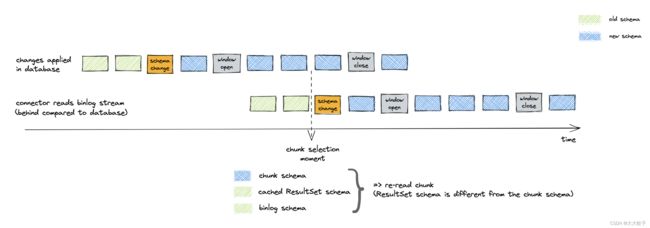
图5双日志模式在块选择上不匹配块模式
匹配插入块和双日志架构
DDL事件也会触发受影响表的重读块。当块具有比窗口关闭时的双日志流更老的模式时,重新读取将防止出现场景。例如,下图说明了在架构更改之前发生的块选择:
图片来自官网原文

图6在块插入上不匹配块模式
模拟的
我们将使用标准 指导部署 展示只读的特别的增量快照。我们用的是 Mysql 作为源数据库。对于这个演示,您需要打开多个终端窗口。
在开始阶段,我们将开始部署,创建信号卡夫卡主题,并启动连接器:
Terminal 1 - start the deployment
Start the deployment
export DEBEZIUM_VERSION=1.9
docker-compose -f docker-compose-mysql.yaml up
Terminal 2
Enable enforce_gtid_consistency and gtid_mode
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c ‘mysql -p$MYSQL_ROOT_PASSWORD inventory -e “SET GLOBAL enforce_gtid_consistency=ON; SET GLOBAL gtid_mode=OFF_PERMISSIVE; SET GLOBAL gtid_mode=ON_PERMISSIVE; SET GLOBAL gtid_mode=ON;”’
Confirm the changes
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c ‘mysql -p$MYSQL_ROOT_PASSWORD inventory -e “show global variables like “%GTID%”;”’
Create a signaling topic
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-topics.sh
–create
–bootstrap-server kafka:9092
–partitions 1
–replication-factor 1
–topic dbz-signals
Start MySQL connector, capture only customers table and enable signaling
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @- <
“name”: “inventory-connector”,
“config”: {
“connector.class”: “io.debezium.connector.mysql.MySqlConnector”,
“tasks.max”: “1”,
“database.hostname”: “mysql”,
“database.port”: “3306”,
“database.user”: “debezium”,
“database.password”: “dbz”,
“database.server.id”: “184054”,
“database.server.name”: “dbserver1”,
“database.include.list”: “inventory”,
“database.history.kafka.bootstrap.servers”: “kafka:9092”,
“database.history.kafka.topic”: “schema-changes.inventory”,
“table.include.list”: “inventory.customers”,
“read.only”: “true”,
“incremental.snapshot.allow.schema.changes”: “true”,
“incremental.snapshot.chunk.size”: “5000”,
“signal.kafka.topic”: “dbz-signals”,
“signal.kafka.bootstrap.servers”: “kafka:9092”
}
}
EOF
从日志上我们看到table.include.list 只放一张桌子,customers :
教师-连接-1/2022-02-21:04:30:039936信息mysql/db服务-1/快照在进行交易时浏览一个表的内容[I.debezium.关系.关系.“关系”/"弹射"事件来源]
在下一步,我们将模拟数据库中的连续活动:
Terminal 3
Continuously consume messages from Debezium topic for customers table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh
–bootstrap-server kafka:9092
–from-beginning
–property print.key=true
–topic dbserver1.inventory.customers
Terminal 4
Modify records in the database via MySQL client
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c ‘i=0; while true; do mysql -u M Y S Q L U S E R − p MYSQL_USER -p MYSQLUSER−pMYSQL_PASSWORD inventory -e “INSERT INTO customers VALUES(default, “nameKaTeX parse error: Can't use function '\"' in math mode at position 2: i\̲"̲, \"surnamei”, “email$i”);”; ((i++)); done’
主题dbserver1.inventory.customers 接收连续的消息流。现在连接器将重新配置,以捕捉orders 表:
Terminal 5
#在捕获的订单中添加订单表
curl -i -X PUT -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/inventory-connector/config -d @- <
“connector.class”: “io.debezium.connector.mysql.MySqlConnector”,
“tasks.max”: “1”,
“database.hostname”: “mysql”,
“database.port”: “3306”,
“database.user”: “debezium”,
“database.password”: “dbz”,
“database.server.id”: “184054”,
“database.server.name”: “dbserver1”,
“database.include.list”: “inventory”,
“database.history.kafka.bootstrap.servers”: “kafka:9092”,
“database.history.kafka.topic”: “schema-changes.inventory”,
“table.include.list”: “inventory.customers,inventory.orders”,
“read.only”: “true”,
“incremental.snapshot.allow.schema.changes”: “true”,
“incremental.snapshot.chunk.size”: “5000”,
“signal.kafka.topic”: “dbz-signals”,
“signal.kafka.bootstrap.servers”: “kafka:9092”
}
平均值
如所料,没有任何讯息orders 表:
Terminal 5
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh
–bootstrap-server kafka:9092
–from-beginning
–property print.key=true
–topic dbserver1.inventory.orders
现在,让我们通过发送信号开始一个增量的临时快照。提供给orders 表格已交回dbserver1.inventory.orders 专题。给customers 桌子不间断地交付.
Terminal 5
Send the signal
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-producer.sh
–broker-list kafka:9092
–property “parse.key=true”
–property “key.serializer=org.apache.kafka.common.serialization.StringSerializer”
–property “value.serializer=custom.class.serialization.JsonSerializer”
–property “key.separator=;”
–topic dbz-signals
dbserver1;{“type”:“execute-snapshot”,“data”: {“data-collections”: [“inventory.orders”], “type”: “INCREMENTAL”}}
Check messages for orders table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh
–bootstrap-server kafka:9092
–from-beginning
–property print.key=true
–topic dbserver1.inventory.orders
如果你要修改orders 当快照运行时,这将作为一个read 事件或作为update 事件,取决于事情的准确时间和顺序。
作为最后一步,让我们终止部署的系统并关闭所有终端:
Shut down the cluster
docker-compose -f docker-compose-mysql.yaml down
结论
Debezns是一个非常好的改变数据捕捉工具,在积极的开发下,它是一个愉快的社区的一部分。我们很高兴能在这里使用生产中的增量快照。如果您有类似的数据库使用限制,请检查只读增量快照功能。非常感谢我的团队和德贝兹团队,没有他们,这个项目就不会发生。