doris数据库介绍
目录
1、简介
2、特点
3、doris架构
4、doris数据表设计-分区与分桶
5、doris的数据模型
1、简介
Apache Doris是一个分布式在线分析处理(OLAP)数据库,它的特点是基于列存储的MPP架构,支持快速的交互式查询和高并发的随机写入。
2、特点
https://www.cnblogs.com/liujichang/p/17384083.html
基于列式存储
行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。
数据写入对比:
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
数据读取对比:
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3)两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
4)从数据的压缩以及更性能的读取来对比
优缺点:
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
总结:
传统行式数据库的特性如下:
①数据是按行存储的。
②没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率。
③建立索引和物化视图需要花费大量的时间和资源。
④面对查询需求,数据库必须被大量膨胀才能满足需求。
列式数据库的特性如下:
①数据按列存储,即每一列单独存放。
②数据即索引。
③只访问查询涉及的列,可以大量降低系统I/O。
④每一列由一个线程来处理,即查询的并发处理性能高。
⑤数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗
3、doris架构
Doirs只有两个主进程模块。一个是 Frontend(FE),另一个是Backend(BE)
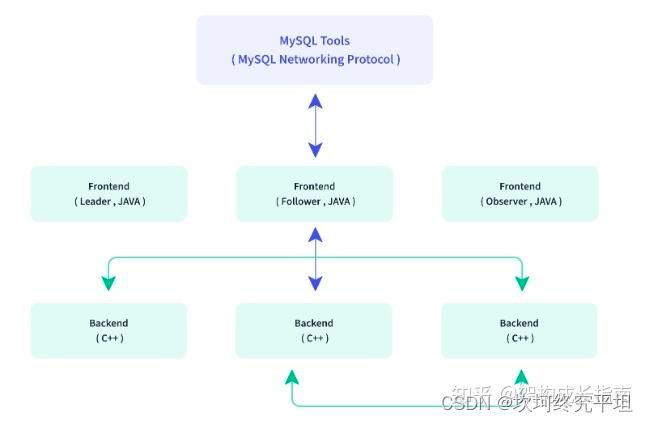
Frontend(FE)
主要负责用户请求的接入、查询计划的解析、元数据的存储和集群管理相关工作, Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。
4、doris数据表设计-分区与分桶
分区(partition)说明
分区是指将数据按照某个规则划分到不同的物理存储节点上,以实现数据的分布式存储和查询。在 Doris 中,可以通过指定分区键来进行数据的分区。分区键是指在表中用于划分数据的列或列组合。Doris 支持RANGE 分区和 LIST 分区两种方式。
逻辑上可以理解为将原始表划分成了多个子表。可以方便的按分区对数据进行管理,例如,删除数据时,更加迅速。
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
Doris在建立分区时,可以不等分,比如:历史数据可以用年来分区,近年的数据可以用月来分区
range分区和list分区
HASH分桶(bucket)说明
根据hash值将数据划分成不同的 bucket。
建议采用区分度大的列做分桶, 避免出现数据倾斜
为方便数据恢复, 建议单个 bucket 的 size 不要太大, 保持在 10GB 以内, 所以建表或增加 partition 时请合理考虑 bucket 数目, 其中不同 partition 可指定不同的 buckets 数。
5、doris的数据模型
Aggregate 模型(聚合模型)
Unique 模型
读时合并、写时合并
Duplicate 模型(重复、复制)模型
数据模型的选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用自1.2版本加入的写时合并实现。
Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。