编者按:随着数据量和计算能力的增加,大模型的参数量也在不断增加,同时进行大模型微调的成本也变得越来越高。全参数微调需要大量的计算资源和时间,且在进行切换下游任务时代价高昂。
本文作者介绍了一种新方法 LoRA,可以在保持模型性能的同时大幅减少微调的参数量和所需资源。
LoRA通过引入两个低秩适配矩阵,用矩阵乘法的方法替换大部分参数。实验证明,LoRA 在多项 NLP 任务上的表现与许多微调方法(如Adapter 和 PreLayer 等)相当或更好。与全参数微调相比,LoRA降低了可训练参数数量 10,000 倍,GPU 内存需求减少 3 倍,存储需求减少 10,000 倍,训练速度提高 25 %。
LoRA 为大语言模型的高效多任务微调提供了一种有效途径。作者认为 LoRA 可以推广到更多模型结构,有望加深我们对模型微调机制的理解。
作者 | Arxiv Dives
编译 | 岳扬
欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
一、 背景知识
Paper: https://arxiv.org/abs/2106.09685
Published: October 16th, 2021, by Microsoft and CMU
这篇文章涉及的数学内容较多,但幸运的是,涉及的线性代数内容仅涉及基础的加法和乘法运算,我相信我们都能够理解。
首先,我将简要概述相关的数学原理及其原因,接下来,我们将深入探讨论文的细节,以及它们如何应用于 GPT-2 和 GPT-3 等 transformers 模型。
最重要的一点是:LoRA 减少了可训练参数(trainable parameters)的数量,从而减少了训练时间和 GPU 内存的使用量,同时保持了输出的质量。
LLM(顾名思义)的规模非常大。用于微调的数据集(fine-tuning datasets)通常比模型的预训练数据集小得多。当数据集比较小的时候,LoRA 只需更新较少的权重,这即是 LoRA 的优势所在。
二、LoRA 的工作原理
如果你熟悉矩阵乘法,那么应该知道 AxM 矩阵和 MxB 矩阵相乘得到的结果是一个 AxB 矩阵。
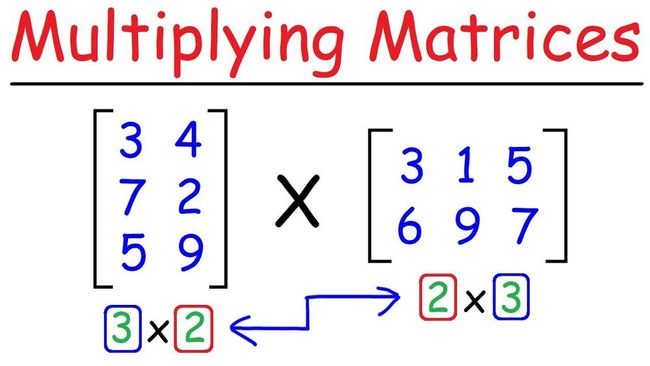
https://www.youtube.com/watch?app=desktop&v=2spTnAiQg4M
假设在神经网络中有一个 MxM 的预训练密集层(pre-trained dense layer)(权重矩阵)W。
例如,这个 Keras 模型有 3 个 size 为 512x512 的密集层(dense layers):

然后再初始化两个密集层 A 和 B,它们的 shapes 分别为 M x R 和 R x M。
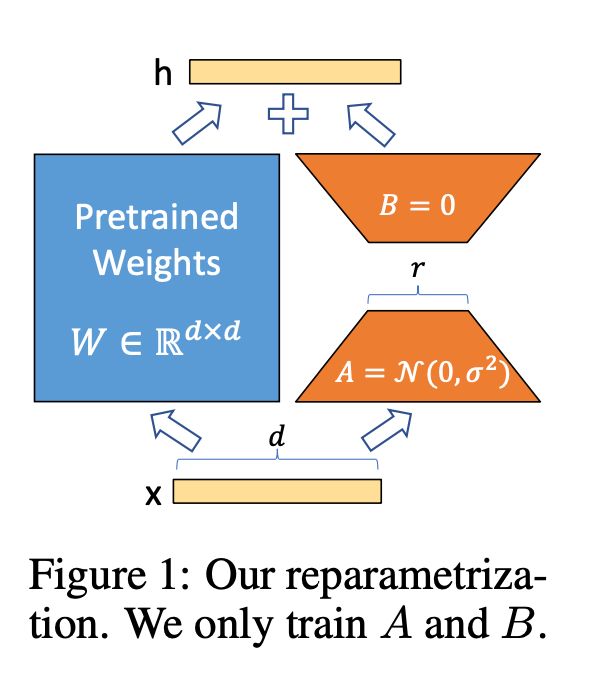
R(秩)远远小于 M。研究表明,R 的取值在1和4之间效果较好。
所以,举个例子,假设密集层拥有 512x512= 262,144 个参数。
因此,可以有一个 size 为 512x4 和一个 size 为 4x512 的矩阵,每个矩阵只有2048个参数,总共4096个参数。
密集层的原始方程式为:
Y = Wx + b
LoRA 将其修改为:
Y = Wx + b + BAx
其中,x 是一个 512x1 的向量,是神经网络的输入,b 是一个 512x1 的偏置向量。
矩阵乘法的数学公式如下:
Dimensions of each variable:
W = 512x512
x = 512x1
b = 1x512
B = 512x4 (New params)
A = 4x512 (New params)
Dimensions fully laid out:
Y = (512x512) * (512x1) + (1x512) + (512x4) * (4x512) * (512x1)但在这种情况下,我们只训练 A 和 B 两个矩阵,每个矩阵只有2048个参数。因此,通过使用LoRA方法,可将可训练参数的数量从 262,144 减少到 4,096 个。
三、可以优化神经网络的哪些部分?
在训练/运行神经网络时,我们需要考虑哪些部分可以进行优化?
1. 总体模型大小(Total model size)
● 模型的磁盘占用空间,使用 serverless 时,通过网络传输模型所需的模型大小,需要占用的 RAM 大小,需要占用的 GPU 大小,需要占用的 CPU 大小
2. 推理时的batch size(Inference batch size)
● batch size,序列长度(sequence length),data size
3. 训练所需的内存
● 所有模型参数 + 可训练参数的梯度
如果你还记得反向传播算法(backpropagation)的工作原理,你需要计算每个偏导数并将它们存储在内存中,以便进行反向传播。这意味着对于传统的全参数微调,所需的内存使用量将增加一倍。
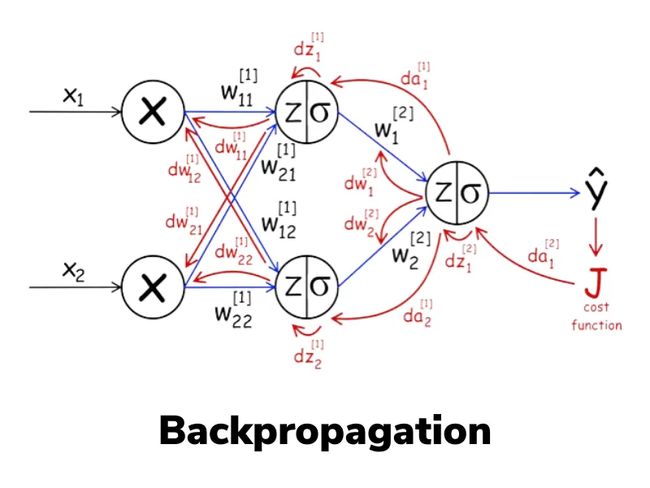
https://soumya997.github.io/2022-03-20-pytorch-params/
LoRA 只训练秩分解矩阵(rank decomposition matrices)(A和B),从而减少了总体训练所需的内存。
这些少量的适配器(adapter)权重可以合并到实际模型本身中,因此它们不会影响推理过程或总体模型的大小。
五、为什么没有额外的推理时间?
LoRA 的原始方程为:
Y = Wx + b + BAx
由于加法的传递性质,我们可以将其重新表达为:
Y = Wx + BAx + b
或者将 x 因数合并为
Y = (W + BA)x + b
也就是说,我们可以简单地将 (W + BA) 替换为新的 W1,然后恢复原来的线性方程。
W1 = (W + BA)
我们用一组新的权重恢复到原来的方程:
Y = W1*x + b
这就意味着,如果我们将原始模型和适配器(adapter)的权重合并,我们所进行的计算基本上与原始模型相同!
五、深入探究这篇论文
目前自然语言处理的范式是先在大量通用数据上进行预训练,然后再对一项或多项特定任务进行微调。对于大模型来说,全面微调所有参数的成本变得过高。
以 GPT-3 为例,其拥有 175B 个参数,这意味着现在需要加倍存储所有梯度来进行训练,更不用说如果要存储多个微调后的模型,还需要将每个模型的全套参数保存下来。
LoRA 可以将可训练参数的数量减少 10,000 倍,GPU 内存的需求减少 3 倍。
在实际应用中,内存使用量的减少程度取决于模型的大小。

https://keras.io/examples/nlp/parameter_efficient_finetuning_...
虽然 LoRA 具有更高的训练吞吐量,而且没有额外的推理延迟,但其性能与微调(fine-tuning)相当,甚至更好。
5.1 Introduction
自然语言处理中的许多应用依赖于将一个大参数量的通用模型适应于多个下游应用。
例如,可能有一个通用模型,可以用最常见的 next words 完成大量的英语句子。人类语言的一个问题在于对于同一个句子可能有多种有效的延续方式。

想想人们对不同的话题有多少不同的看法。其中很多观点都基于他们的过去经验,人们在讨论和交流观点时经常会产生分歧和辩论。
例如,你希望下游模型能够用你的声音总结文本,或者能够将自然语言翻译成 SQL 查询语句,或者让微调后的模型比基础模型更有趣,这些都可以通过微调来实现。
对整个模型进行端到端(end to end)微调的一个缺点是,新模型包含的参数和旧模型一样多。如果要进行 N 次微调,这就意味着每个新模型的存储占用空间和内存都要线性增加。
一些人通过为新任务学习外部模块或在模型中添加新层来解决了这个问题,但这会增加推理延迟。
https://pyimagesearch.com/2019/06/03/fine-tuning-with-keras-a...
5.2 LoRA 中的“Rank”指的是什么?
他们强调了一个事实,即过参数化(over-parameterized)模型(参数量远超训练数据量的模型)实际上具有相对简单的内在空间维度,并假设在模型适应或调整过程中,权重的变化具有“低内在秩(low instrinsic rank)” (译者注:即其权重调整过程可能并不需要在所有这些维度上进行。实际上,有效的权重调整可能仅仅发生在一个相对较小的子空间内)。
矩阵的“秩(rank)”是指其中线性无关的列或行的数量。
我们可以将神经网络中的线性无关性(linear independence)理解为“每组权重对决策的影响有多大”。
秩为零的矩阵将是一个全零矩阵。
如果你有一个看起来像这样的矩阵:
1 2 3 4
2 4 6 8
5 3 9 7我们可以看到这个矩阵前两行其实是彼此的倍数,所以它们会继续指向相同的方向。但是,第三行则带我们走向完全不同的方向。
在下图中,秩为2的矩阵将形成一个二维平面,因为所有向量都在同一平面上,而秩为3的矩阵则更像一个立方体,因为每个向量指向不同的方向。
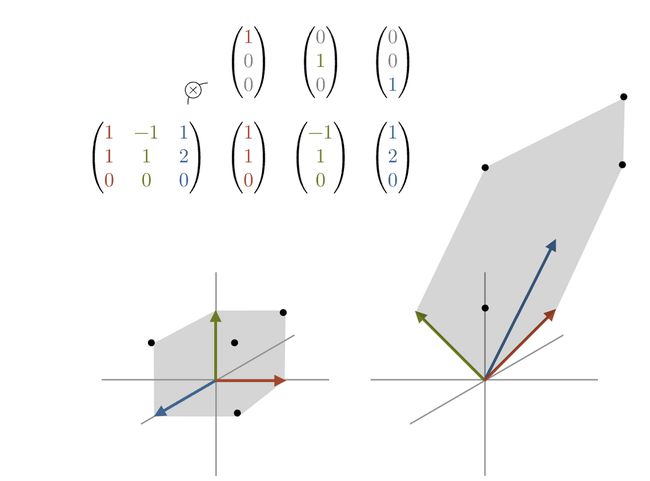
https://peterbloem.nl/blog/pca-4?ref=blog.oxen.ai
神经网络的维度通常非常高,而我们的大脑很难想象或理解这么高维度的空间。
即使原始数据的维度非常高(高达12,228),使用低秩(甚至是1或2)也能够有效地表示数据。
这种技术的优势包括:
● 可以共享同一个预训练模型,也可以为不同的任务构建许多更小的 LoRA 模型。
● LoRA 提高了训练效率,降低了硬件门槛。
● 简单的线性设计允许权重可合并,不会带来推理延迟。
● LoRA 可应用于许多模型架构和先前的方法,因为它是一个简单的密集层(dense layer)。
在本例中将 LoRA 应用于 Transformer 架构。因此,下一节一起来了解有哪些变量,分别代表着什么。

5.3 现有解决方案还不够好吗?
论文承认,这绝不是一个新问题。迁移学习(Transfer learning)有多种方法提高模型自适应(Model Adaptation)的效率,包括参数和计算的效率。。
论文作者特别关注了在模型自适应(Model Adaptation)过程中使用 adapter layers 以及优化输入层(input layers)或 prompts 的方法。
adapter layers 虽然体积小,但必须按顺序处理,而不是并行处理,因此会增加额外的延迟。

他们对 A 从高斯分布中随机选择初始值来初始化矩阵中的元素,并将矩阵 B 初始化为零,这样在训练开始时,矩阵 B 乘以矩阵 A 的结果为零。
论文指出,LoRA 可以进行全参数微调,因为一旦将 LoRA 的秩设为预训练权重矩阵的秩,LoRA会逐渐收敛到与原始模型相似的状态,从而实现对原始模型的训练。
当模型部署到生产环境中时,可以进行 W = W + BA 的计算并将结果存储下来,然后像往常一样进行推理。当需要将微调后的模型切换到另一个任务时,可以通过简单的数学操作来恢复原始的模型权重W,而且不会占用太多额外的内存空间。
5.4 将 LoRA 应用于 Transformers
论文只将 LoRA 应用于注意力机制(attention mechanism)中的查询(Query)、键(Key)和值(Value)权重矩阵,而不将其应用于其他密集层(dense layers)。
本文还将 LoRA 应用于 Transformer 的其他部分留作 “未来的工作” 。
5.5 实际优势 Practical Benefits
LoRA带来的最显著好处是内存和存储空间的减少。
对于 GPT-3 175B,该技术将 VRAM 消耗从 1.2TB 减少到 350GB。这是相当惊人的,训练 GPT-3 需要如此大量的 VRAM。
由于 r=4 且仅调整 Q 和 V 矩阵,微调(fine-tuning)过程中生成的 checkpoint 大小约为 35MB,而不是 350GB......因此减少了 10,000 倍。
请注意,在模型的部署过程中仍然需要 350GB 存储空间,但存储 100 个微调后的模型仅需要 350GB + 35MB 100 ≈ 354GB,而不是 100 350GB ≈ 35TB。
这样就可以创建许多定制模型,并且可以在存储预训练权重(pre-trained weights)的机器上随时切换模型。
论文作者还观察到,与全参数微调相比,训练速度提高了 25%,因为不需要为绝大多数参数计算梯度。
5.6 根据经验和实验证明
论文评估了 LoRA 在 RoBERTa、DeBERTa 和 GPT-2 上的下游任务性能,然后将其扩展到了 GPT-3。
论文在多个基准测试上进行了评估:
● GLUE(General Language Understanding Evaluation),这个基准测试包含许多子任务。
● WikiSQL
● SAMsum(conversation summarization)
● Baselines
我们不会对所有 adapters 进行比较,但我们可以看到,在 RoBERTa 上使用 LoRA 时,LoRA 甚至比许多 adapters 更有竞争力。
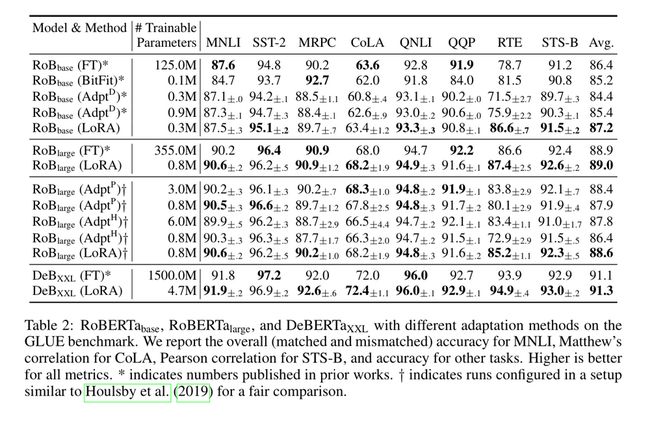
即使可训练参数的数量要小得多,但是当应用于 GPT-2 时,性能超过了许多 Adapter 和 PreLayer 方法。
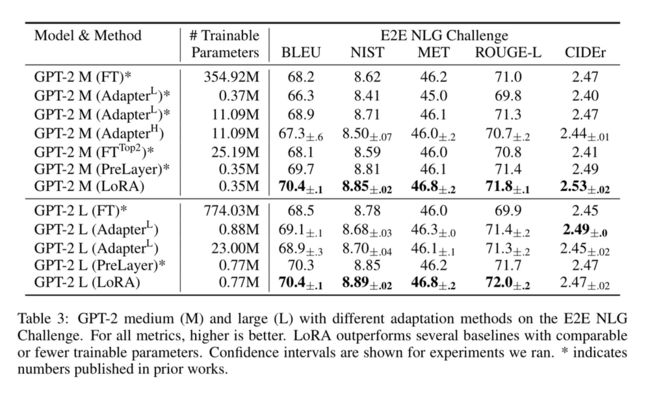
在上述任务中,GPT-3 也是如此。GPT-3 的运行成本要高得多,所以作者会更加谨慎地选择对 GPT-3 进行评估的基准测试,以避免过高的运行成本。

5.7 什么是 prompt engineering?
他们承认 prompt engineering 可以用来最大限度地提高通用模型在特定任务中的性能,并指出微调 GPT-3 与 prompt engineering 进行比较并不十分科学,因此在 prompting 和微调之间还没有进行过很多比较。
此外,David在谈话中提到,prompt engineering 比全参数微调更不稳健,更容易受到提示语注入攻击(prompt injection hacks)的影响。
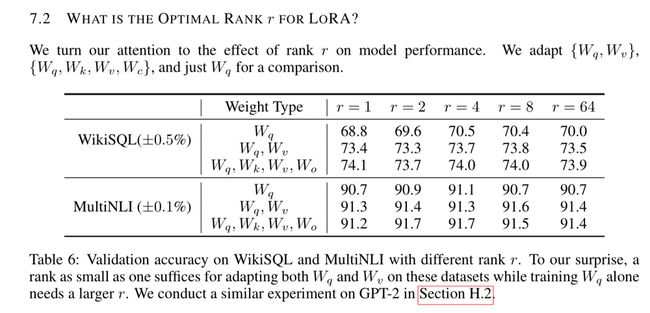
5.8 使用多少秩(Rank)以及应用于哪些权重(weights)?
在评估过程中,较低秩的模型表现优于较高秩的模型,这可能令人感到惊讶。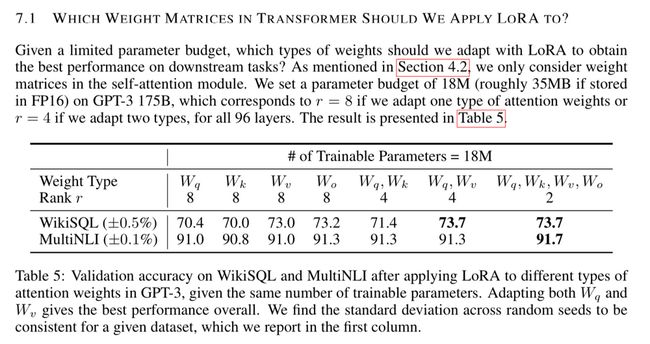
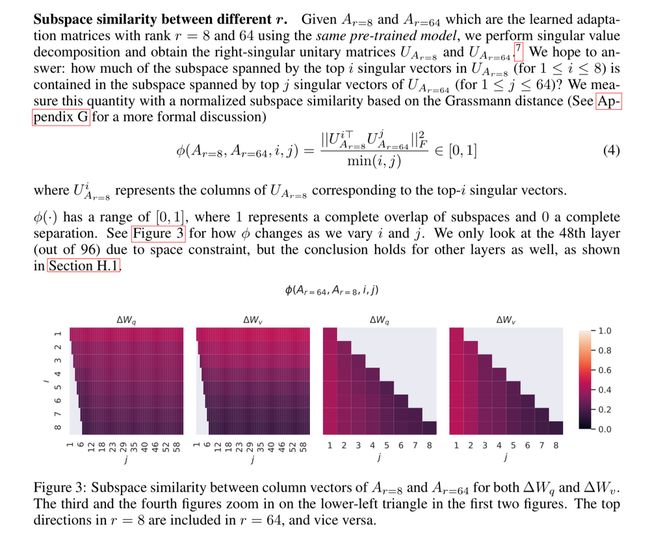
5.9 Subspace Similarity
(译者注:"Subspace Similarity"指的是在线性代数中,两个向量空间之间的相似性。)他们使用奇异值分解来研究模型中不同子空间之间的相似性。他们发现,在观察模型中的不同子空间时,直到维度为1时,这些子空间之间的相似性仍然很高。这可能对于理解为什么较低秩的模型表现更好具有重要意义。
下面是对列向量之间子空间相似性的另一个可视化图示。可以看到,很多列向量的值都接近于零,这意味着它们非常相似,只有那些 top ranks 的列向量才会显示出差异。(译者注:"top ranks" 可能指的是奇异值分解中最大的奇异值对应的向量。)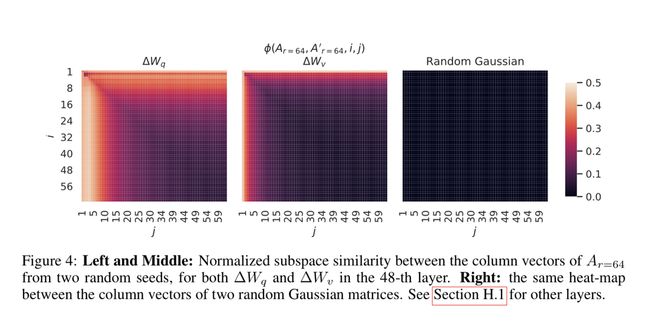
这些关于权重的研究提出了一个问题:如果有如此多的参数是线性相关的,那么一般来说,大语言模型到底需要多少参数呢?
六、 结论和未来展望
对大语言模型进行微调的成本过高,尤其是在需要切换不同任务时。
LoRA有助于降低训练成本,并实现快速任务切换。
由于 LoRA 是一种与模型架构无关的技术,因此可以与许多其他方法和模型结合使用。
微调或 LoRA 背后的机制尚不清楚,他们认为通过研究矩阵的秩,可以更容易地理解 LoRA 的工作机制,相较于全参数微调的方法。
他们认为模型的许多其他部分也可以应用 LoRA,而且他们的许多设置都是基于启发式方法(heuristics)选择的。
作者在微调 Llama 时使用 LoRA 不会增加硬件要求,同时我们也看到很多人将其应用于 stable diffusion(用于图像生成),我认为很多云服务可能也都在使用 Lora 来提高不同任务的准确性。
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://blog.oxen.ai/arxiv-dives-how-lora-fine-tuning-works/