【简单文本相似度分析】( LCS | Trie | DP | 词频统计 | hash | 单词分割 )
两个文本的相似度的指标有很多,常见的有词袋分析,词向量余弦,LCS(子串,子序列),Jaccard相似度分析(单词集合的对称差和最小全集比值),编辑距离等等
我在自己的程序里只定义两个指标:
1 单词重复度
2 最长公共子序列长度
首先用c++builtin的字符输入流对象istringstream做单词分割
然后用我自己写的patriaca trie树当作词袋,把词量小的string做映射集合(类似重链合并),插入到trie中,另一个单词序列检索trie树(我写的trie树有统计词频的附加数据域),统计出顶一个指标
LCS的求解就是经典的动态规划(没有压存),带了状态空间标记(自定义了强枚举类型 enum state : char {...}),方便离线回溯,最后还原LCS在原单词序列的索引,最终还原LCS
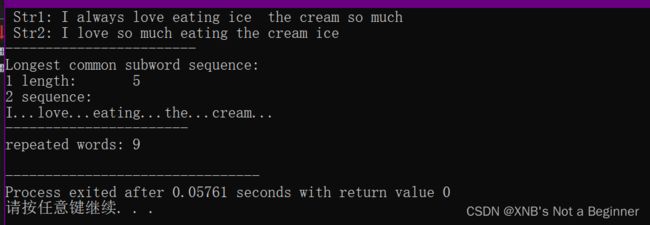
Demo

单词分割:string文本 -> istringstream送入缓冲->vector< string > split words单词序列
dp求LCS
matrix是一个template type
typename < std::size_t N, std::size_t M, typename Ty >
using matrix = std::array< std::array< Ty, M >, N >
两个非类型模板参数N,M接受编译器常量作为矩阵维度界限
SAME_AS LHS RHS为强枚举类型 enum state : char { ... } 定义状态空间标记用的。

回溯 收集lcs对应的下标,因为递归,所以求出来逆序的,输出的时候用range for配合管道运算符和concept std::views::reverse可以正常还原LCS

完整程序
template < std::size_t N, std::size_t M, typename Ty >
using matrix = std::array< std::array< Ty, M >, N >;
static constexpr std::size_t LENGTH_LIMIT { 64 };
enum state : char { SAME_AS = 0, LHS, RHS } ;
template < std::size_t N >
void GetLCString( matrix< N, N, state > &record,
std::size_t i, std::size_t j,
const std::vector< std::string >& dest,
std::vector< std::size_t >& indices ){
if( !i || !j ) return;
if( record[i][j] == SAME_AS ){
indices.push_back( i );
GetLCString( record, i-1, j-1, dest, indices );
}else if( record[i][j] == LHS )
GetLCString( record, i-1, j, dest, indices );
else
GetLCString( record, i, j-1, dest, indices );
}
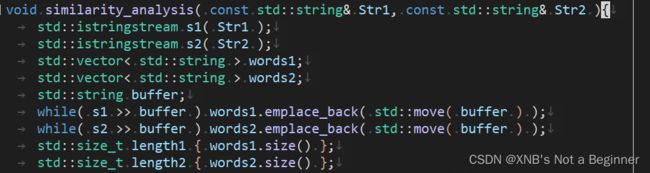
void similarity_analysis( const std::string& Str1, const std::string& Str2 ){
std::istringstream s1( Str1 );
std::istringstream s2( Str2 );
std::vector< std::string > words1;
std::vector< std::string > words2;
std::string buffer;
while( s1 >> buffer ) words1.emplace_back( std::move( buffer ) );
while( s2 >> buffer ) words2.emplace_back( std::move( buffer ) );
std::size_t length1 { words1.size() };
std::size_t length2 { words2.size() };
matrix< LENGTH_LIMIT, LENGTH_LIMIT, std::size_t > dp;
matrix< LENGTH_LIMIT, LENGTH_LIMIT, state > record;
for( auto i { 1U }; i < length1; ++i )
for( auto j { 1U }; j < length2; ++j ){
if( words1[i] == words2[j] ){
dp[i][j] = dp[i-1][j-1] + 1;
record[i][j] = SAME_AS;
}else if( dp[i][j-1] <= dp[i-1][j]){
dp[i][j] = dp[i-1][j];
record[i][j] = LHS;
}else{
dp[i][j] = dp[i][j-1];
record[i][j] = RHS;
}
}
std::vector< std::size_t > indices;
indices.reserve( length1 << 1U | 1U );
GetLCString( record, length1 - 1, length2 - 1, words1, indices );
std::size_t common_length { dp[ length1 - 1 ][ length2 - 1 ] };
std::cout << "Longest common subword sequence:\n";
std::cout << "1 length:\t" << common_length << '\n';
puts("2 sequence:");
namespace std_v = std::views;
for( const auto& Word :
indices | std_v::reverse | std_v::transform(
[&]< typename Value>( Value index ){
return words1[index];
} ) )
std::cout << Word << "...";
endl( std::cout );
trie T;
for( const auto& W : words1 )
T.insert( W );
std::size_t repeated { 0U };
for( const auto& W : words2 )
repeated += T.count( W );
std::puts("-----------------------");
std::cout << "repeated words:\t" << repeated << '\n';
}