Python数据分析(Matplotlib、NumPy、Pandas)
Python数据分析(Numpy、Matplotlib、Pandas)
教程:黑马程序员
链接:https://www.bilibili.com/video/BV1hx411d7jb?p=1
一、基础概念和环境
1.1 什么是数据分析
数据分析是通过对收集到的数据进行解释、整理、转化和建模,以提取出有意义的信息、得出结论并支持决策的过程。
1.2 为什么要学习数据分析
- 是Python数据科学的基础
- 机器学习的基础
1.3 环境准备
准备好Anaconda环境和Jupyter Notebook
二、Matplotlib的基本使用
Matplotlib帮助我们进行绘图
2.1 什么是Matplotlib
Matplotlib是最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建
它能将数据进行可视化,更直观的呈现,使数据更加客观,更具有说服力
2.2 Matplotlib快速上手
引入一个例子,演示如何使用Matplotlib来画如下简单的折线图。

from matplotlib import pyplot as plt
# 绘制一天中每隔两个小时的气温折线图
# 在x轴的数据 是一个可迭代对象
x = range(2, 26, 2)
# 在y轴的数据 是一个可迭代对象
y = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15]
# x轴和y轴的数据一起组成了所有要绘制出的坐标 传入x和y 通过plot绘制出折线图
plt.plot(x, y)
# 在执行程序的时候展示图形
plt.show()
绘制出的图形效果如下:

可以发现,Matplotlib自动生成的折线图的坐标轴不是严格按照我们给的数据来显示的,并且也没有关于xy坐标轴分别表示什么的说明等等,我们可以通过编写代码来更加的完善这张图,例如可以添加以下信息:
- 设置图片的大小(想要高清无码的大图)
- 保存图片到本地
- 添加描述信息,例如x轴和y轴分别表示什么,这个图表示什么等等
- 调整x或y的刻度的间距
- 设置线条的样式(比如颜色,透明度等等)
- 标记出特殊的点(比如标记出最高点和最低点在哪)
- 给图片添加一个水印
2.3 设置图片的大小和分辨率并保存图片
修改figure类的参数从而改变图片的大小,获得修改后的fig对象对于我们全局需要绘制的图都是有效的
保存图片应该在绘制图片完成之后,调用save方法来保存,代码示例如下:
from matplotlib import pyplot as plt
# 绘制一天中每隔两个小时的气温折线图
# 在x轴的数据 是一个可迭代对象
x = range(2, 26, 2)
# 在y轴的数据 是一个可迭代对象
y = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15]
# 设置图片的大小
fig = plt.figure(figsize=(20,8), dpi=80)
# x轴和y轴的数据一起组成了所有要绘制出的坐标 传入x和y 通过plot绘制出折线图
plt.plot(x, y)
# 保存图片 只需传入要保存的位置即可
plt.savefig("./t1.png")
2.4 修改坐标轴刻度
我们可以通过plt.xticks和plt.yticks方法来修改坐标轴的刻度,传入的参数可以为我们想要的刻度的一个列表,例如我们想要将上面x轴的刻度变为2,2.5,3,3.5…,代码示例如下:
from matplotlib import pyplot as plt
# 绘制一天中每隔两个小时的气温折线图
# 在x轴的数据 是一个可迭代对象
x = range(2, 26, 2)
# 在y轴的数据 是一个可迭代对象
y = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15]
# 设置图片的大小
fig = plt.figure(figsize=(20,8), dpi=80)
# 设置x轴的刻度
xticks_labels = [i / 2 for i in range(4, 49)]
plt.xticks(xticks_labels[::3])
# 设置y轴的刻度 找出y轴数据中的最大值和最小值来设置刻度
yticks_labels = range(min(y), max(y)+1)
plt.yticks(yticks_labels)
# x轴和y轴的数据一起组成了所有要绘制出的坐标 传入x和y 通过plot绘制出折线图
plt.plot(x, y)
# 保存图片 只需传入要保存的位置即可
plt.show()
可以看到生成的图片就变成了:
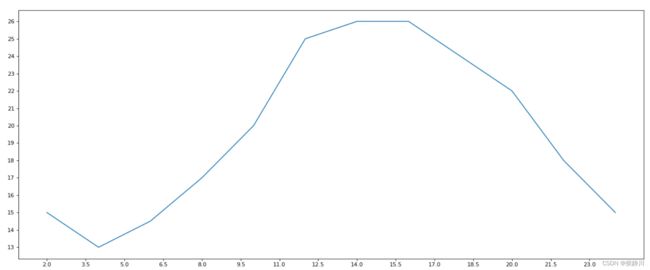
如果感觉刻度太密集,则可以将传入的刻度列表进行切片操作:plt.xticks(xticks_labels[::3]) 。总之,就是将自己想要的刻度列表放入xticks方法中,传什么刻度才会有什么刻度。
问题:如果我们想要绘制10点到12点两个小时内每分钟的温度情况,那么我们该如何让x轴刻度显示10点1分这样的中文呢?(即刻度显示字符串)
我们可以将传入的数据和刻度列表进行对应,即x轴上的什么数据对应刻度列表中的哪个值,代码示例如下:
import random
from matplotlib import pyplot as plt
# 绘制折线图观察10点到12点每一分钟的气温情况
# y轴数据
y = [random.randint(20, 35) for i in range(120)]
# x轴数据
x = range(0, 120)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["10点{}分".format(i) for i in range(60)]
xticks_labels += ["11点{}分".format(i) for i in range(60)]
# 取步长 数字和字符串一一对应 数据的长度一样
# 由于刻度太密集看不清 所以我们可以设置 rotation 刻度旋转的度数来调整 我们可以调整为45度
plt.xticks(_x[::3], xticks_labels[::3], rotation=45)
# y轴刻度
plt.yticks(range(min(y), max(y)+1))
# 绘图
plt.plot(x, y)
# 展示
plt.show()
这样,输出的图片效果如下:

注意:设置图片大小这一操作要在设置刻度之前来进行,否则会出现错误
可以看到,我们已经使用rotation参数来调整了刻度值的角度使得展示的更加清楚,但是出现了中文报错的问题,下面我们来解决中文乱码的问题。
解决方法一:通过matplotlib.rc来设置字体(family)
import random
import matplotlib
from matplotlib import pyplot as plt
# 通过matplotlib.rc()设置中文字体 设置为雅黑
font = {'family': 'MicroSoft YaHei',
'weight': 'bold'}
matplotlib.rc('font', **font)
# 绘制折线图观察10点到12点每一分钟的气温情况
# y轴数据
y = [random.randint(20, 35) for i in range(120)]
# x轴数据
x = range(0, 120)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["10点{}分".format(i) for i in range(60)]
xticks_labels += ["11点{}分".format(i) for i in range(60)]
# 取步长 数字和字符串一一对应 数据的长度一样
# 由于刻度太密集看不清 所以我们可以设置 rotation 刻度旋转的度数来调整 我们可以调整为45度
plt.xticks(_x[::3], xticks_labels[::3], rotation=45)
# y轴刻度
plt.yticks(range(min(y), max(y)+1))
# 绘图
plt.plot(x, y)
# 展示
plt.show()
解决后的图片如下:
解决方法二:通过matplotlib下的font_manager来设置fname,百分百可以更改成功
import random
import matplotlib
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 通过matplotlib下的font_manager来设置fname fname中传入的是本机字体对应的路径
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\STXINWEI.TTF")
# 绘制折线图观察10点到12点每一分钟的气温情况
# y轴数据
y = [random.randint(20, 35) for i in range(120)]
# x轴数据
x = range(0, 120)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["10点{}分".format(i) for i in range(60)]
xticks_labels += ["11点{}分".format(i) for i in range(60)]
# 取步长 数字和字符串一一对应 数据的长度一样
# 由于刻度太密集看不清 所以我们可以设置 rotation 刻度旋转的度数来调整 我们可以调整为45度
# 设置fontproperties参数来更改中文字体
plt.xticks(_x[::3], xticks_labels[::3], rotation=45, fontproperties=my_font)
# y轴刻度
plt.yticks(range(min(y), max(y)+1))
# 绘图
plt.plot(x, y)
# 展示
plt.show()
解决后的图片如下:
2.5 给图像添加描述信息
接下来,给我们上面绘制的图像添加一些描述信息,例如x轴代表什么,y轴代表什么,以及图片的标题是什么,代码展示如下(当然如果我们不使用第一种更改中文字体的方法的话,在添加描述信息的时候也一定要设置fontproperties参数来保证不会出现中文乱码):
import random
import matplotlib
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 通过matplotlib下的font_manager来设置fname
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\STXINWEI.TTF")
# 绘制折线图观察10点到12点每一分钟的气温情况
# y轴数据
y = [random.randint(20, 35) for i in range(120)]
# x轴数据
x = range(0, 120)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["10点{}分".format(i) for i in range(60)]
xticks_labels += ["11点{}分".format(i) for i in range(60)]
# 取步长 数字和字符串一一对应 数据的长度一样
# 由于刻度太密集看不清 所以我们可以设置 rotation 刻度旋转的度数来调整 我们可以调整为45度
plt.xticks(_x[::3], xticks_labels[::3], rotation=45, fontproperties=my_font)
# y轴刻度
plt.yticks(range(min(y), max(y)+1))
# 添加x轴描述信息
plt.xlabel("时间", fontproperties=my_font)
# 添加y轴描述信息
plt.ylabel("温度 单位(℃)", fontproperties=my_font)
# 添加图片描述信息
plt.title("10点到12点每分钟气温变化情况", fontproperties=my_font)
# 绘图
plt.plot(x, y)
# 展示
plt.show()
生成的图片如下:
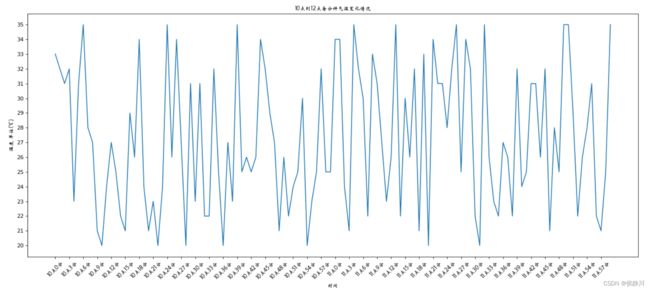
2.6 给图像加上网格
有时,我们观察图像的时候不方便观察到该点对应的刻度是多少,所以我们可以通过plt.grid(alpha)加上网格来方便我们观察,alpha可以调节网格的透明度,值是从0~1逐渐变得不透明的。代码如下:
import random
import matplotlib
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 通过matplotlib.rc()设置中文字体 设置为雅黑
font = {'family': 'MicroSoft YaHei'}
matplotlib.rc('font', **font)
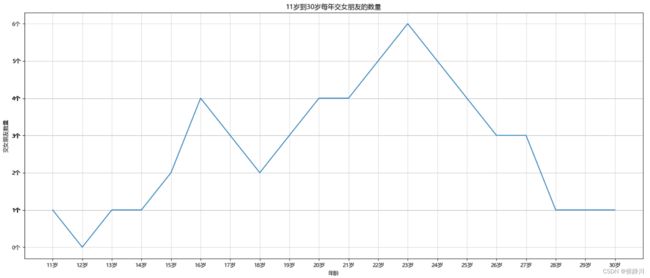
# 绘制折线图观察11到30岁每年的交女朋友数量
# y轴数据 表示处女朋友的个数
y = [1, 0, 1, 1, 2, 4, 3, 2, 3, 4, 4, 5, 6, 5, 4, 3, 3, 1, 1, 1]
# x轴数据 表示自己的年龄
x = range(11, 31)
# 设置图片大小 dpi是图片的清晰度
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["{}岁".format(i) for i in _x]
# 取步长 数字和字符串一一对应 数据的长度一样
plt.xticks(_x, xticks_labels)
# 调整y轴刻度显示字符串 将我们y轴的数据和我们想要显示的字符串做一一对应
_y = list(y)
yticks_labels = ["{}个".format(i) for i in _y]
plt.yticks(_y, yticks_labels)
# 添加x轴描述信息
plt.xlabel("年龄")
# 添加y轴描述信息
plt.ylabel("交女朋友数量")
# 添加图片描述信息
plt.title("11岁到30岁每年交女朋友的数量")
#绘制网格 alpha参数用来调节透明度
plt.grid(alpha=0.5)
# 绘图
plt.plot(x, y)
# 展示
plt.show()
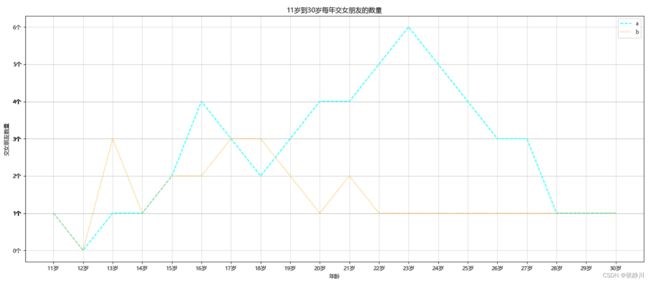
2.7 绘制多条曲线并添加图例
有时,我们需要再一个图像里绘制多个曲线来对比分析走势,matplotlib同样可以实现该操作,假设我们需要绘制a和b同学在11岁到30岁之间每年的交朋友数量。我们可以通过多次执行plot来实现。
那么,假设我们绘制了两条曲线后,如何知道谁是哪一条呢?我们可以通过添加图例来实现,首先在plot时设置label参数,接下来执行legend方法。
由于我们有两条曲线,那么我们可以给两个曲线的线条设置不同的属性,例如线条颜色,线条风格,线条粗细等。

最终代码展示如下:
import random
import matplotlib
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 通过matplotlib.rc()设置中文字体 设置为雅黑
font = {'family': 'MicroSoft YaHei'}
matplotlib.rc('font', **font)
# 也可以通过font_manager来设置字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\STXINWEI.TTF")
# y轴数据 表示处女朋友的个数
y_1 = [1, 0, 1, 1, 2, 4, 3, 2, 3, 4, 4, 5, 6, 5, 4, 3, 3, 1, 1, 1]
y_2 = [1, 0, 3, 1, 2, 2, 3, 3, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# x轴数据 表示自己的年龄
x = range(11, 31)
# 设置图片大小 dpi是图片的清晰度
plt.figure(figsize=(20, 8), dpi=80)
# 调整x轴刻度显示字符串 将我们x轴的数据和我们想要显示的字符串做一一对应
_x = list(x)
xticks_labels = ["{}岁".format(i) for i in _x]
# 取步长 数字和字符串一一对应 数据的长度一样
plt.xticks(_x, xticks_labels)
# 调整y轴刻度显示字符串 将我们y轴的数据和我们想要显示的字符串做一一对应
_y = list(y_1)
yticks_labels = ["{}个".format(i) for i in _y]
plt.yticks(_y, yticks_labels)
# 添加x轴描述信息
plt.xlabel("年龄")
# 添加y轴描述信息
plt.ylabel("交女朋友数量")
# 添加图片描述信息
plt.title("11岁到30岁每年交女朋友的数量")
# 绘制网格 alpha参数用来调节透明度
plt.grid(alpha=0.5)
# 绘图 每个曲线可以添加label color linestyle linewidth 等等参数
plt.plot(x, y_1, label="a", color="cyan", linestyle='--')
plt.plot(x, y_2, label="b", color="orange", linestyle=':')
# 添加图例 prop参数可以设置我们配置好的字体 loc参数是图例展示的位置
# loc=0 可以让matplotlib自动调整图例最合适的位置
plt.legend(prop=my_font, loc=0)
# 展示
plt.show()
效果图为:
注意:在给图例设置中文字体的时候,给legend设置的是prop参数而不是之前的fontproperties了
三、Matplotlib常用统计图

3.1 绘制散点图
假设通过爬虫获取到了北京2016年3,10月份每天白天的最高气温(分别位于列表a和b),那么此时如何寻找出气温和随时间(天)变化的某种规律?
我们可以通过使用plt.scatter(x,y)来绘制散点图。绘制的细节用代码展示如下:
from matplotlib import pyplot as plt
from matplotlib import font_manager
# 绘制散点图来观察不同月份中每天的最高气温变化规律
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# y轴数据 3月份和十月份每天的最高温度
y_3 = [11, 17, 16, 11, 12, 11, 12, 6, 6, 7, 8, 9, 12, 15, 14, 17, 18, 21, 16, 17, 20, 14, 15, 15, 15, 19, 21, 22, 22, 22, 23]
y_10 = [26, 26, 28, 19, 21, 17, 16, 19, 18, 20, 20, 19, 22, 23, 17, 20, 21, 20, 22, 15, 11, 15, 5, 13, 17, 10, 11, 13, 12, 13, 6]
# x轴数据 天数 为了不让两个月份的数据点混合到一起 我们可以将10月的x轴数据右移即加50
x_3 = range(1, 32)
x_10 = range(51, 82)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
# 设置x轴刻度 将两个x轴刻度合并在一起
_x_3 = list(x_3)
xticks_labels_3 = ["3月{}号".format(i) for i in _x_3]
_x_10 = list(x_10)
xticks_labels_10 = ["10月{}号".format(i-50) for i in _x_10]
_x = _x_3 + _x_10
xticks_labels = xticks_labels_3 + xticks_labels_10
# 合并两个x轴刻度并旋转45度
plt.xticks(_x, xticks_labels, rotation=45, fontproperties=my_font)
# 设置y轴刻度
_y = y_10 + y_3
plt.yticks(range(min(_y), max(_y)+1), fontproperties=my_font)
# 绘制图像
plt.scatter(x_3, y_3, label="三月份")
plt.scatter(x_10, y_10, label="十月份")
# 添加图例
plt.legend(prop=my_font, loc=0)
# 添加描述信息
plt.xlabel("时间", fontproperties=my_font)
plt.ylabel("温度 单位(℃)", fontproperties=my_font)
plt.title("三月份和十月份每日最高气温散点图", fontproperties=my_font)
# 展示图片
plt.show()
生成的图片如下:

可以看到,我们通过该散点图就能发现,三月份的温度随着时间增加气温逐渐升高,而十月份的温度随着时间增加气温逐渐降低。
关于散点图的绘制实际上和之前折线图的绘制并无差别,最重要的就是绘图的时候调用的是plt.scatter(x,y)方法。
3.2 绘制条形图
假设获取到了2017年内地电影票房前20的电影(列表a)和电影票房数据(列表b),那么如何更加直观的展示该数据?
我们可以绘制条形图来观察票房数据,代码实现细节如下:
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 绘制电影票房条形图
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# x轴数据 电影名字
x = ["战狼2", "速度与激情8", "功夫瑜伽", "西游伏妖篇", "变形金刚5:最后的骑士", "摔跤吧!爸爸", "加勒比海盗5:死无对证", "金刚:骷髅岛", "极限特工:终极回归", "生化危机6:终章", "乘风破浪", "神偷奶爸3", "智取威虎山", "大闹天竺", "金刚狼3:殊死一战", "蜘蛛侠:英雄归来", "悟空传", "银河护卫队2", "情圣", "新木乃伊"]
# y轴数据 对应电影的票房
y = [56.01, 26.94, 17.53, 16.49, 15.45, 12.96, 11.8, 11.61, 11.28, 11.12, 10.49, 10.3, 8.75, 7.55, 7.32, 6.99, 6.88, 6.86, 6.58, 6.23]
# 设置图形大小
plt.figure(figsize=(20, 8), dpi=160)
# 设置x轴刻度 生成电影的序号(排名) 并将其与电影名一一对应
_x = range(len(x))
plt.xticks(_x, x, fontproperties=my_font, rotation=90)
# 设置y轴刻度
plt.yticks(range(0, 51, 10))
# 绘制条形图 由于bar绘制条形图只能接受含数字的可迭代对象
# 所以我们不能传入x来绘制,而要传入_x来绘制
# width表示长条的宽度 默认0.8
plt.bar(_x, y, color="orange")
# 添加图像描述
plt.xlabel("电影名称", fontproperties=my_font)
plt.ylabel("电影票房(单位:亿)", fontproperties=my_font)
plt.title("2017年内地电影票房top20", fontproperties=my_font)
# Pad margins so that markers don't get clipped by the axes
# plt.margins(0.2)
# 调整间距以防止勾号标签被剪切导致x轴显示不全或x轴描述显示不全
plt.subplots_adjust(bottom=0.3)
# 展示图像
plt.show()
注意:绘制条形图时,由于bar绘制条形图只能接受含数字的可迭代对象,我们可以传入电影的数量来进行绘图,后面再设置x轴刻度进行电影名字的对应
注意:在编写代码调试的过程中,会出现x轴的刻度显示不全的问题,这是因为图片的高度不合适,我们可以在设置图片大小的时候将图片高度设置的合适一点,也可以使用plt.subplots_adjust()方法来调整间距让刻度显示完整。
生成的图片如下:

但我们发现,x轴刻度的电影名字过长会影响美观,我们可以调用plt.barh()方法将数据横向展,实现代码如下:
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 绘制电影票房条形图
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# x轴数据 电影名字
x = ["战狼2", "速度与激情8", "功夫瑜伽", "西游伏妖篇", "变形金刚5:最后的骑士", "摔跤吧!爸爸", "加勒比海盗5:死无对证", "金刚:骷髅岛", "极限特工:终极回归", "生化危机6:终章", "乘风破浪", "神偷奶爸3", "智取威虎山", "大闹天竺", "金刚狼3:殊死一战", "蜘蛛侠:英雄归来", "悟空传", "银河护卫队2", "情圣", "新木乃伊"]
# y轴数据 对应电影的票房
y = [56.01, 26.94, 17.53, 16.49, 15.45, 12.96, 11.8, 11.61, 11.28, 11.12, 10.49, 10.3, 8.75, 7.55, 7.32, 6.99, 6.88, 6.86, 6.58, 6.23]
# 设置图形大小
plt.figure(figsize=(20, 8), dpi=160)
# 设置x轴刻度
plt.yticks(range(0, 51, 10))
# 设置y轴刻度 生成电影的序号(排名) 并将其与电影名一一对应
_x = range(len(x))
plt.yticks(_x, x, fontproperties=my_font)
# 绘制条形图 barh方法的条形宽度对应的参数变为了height(因为是横着看的)
plt.barh(_x, y, height=0.5, color="orange")
# 添加图像描述
plt.ylabel("电影名称", fontproperties=my_font)
plt.xlabel("电影票房(单位:亿)", fontproperties=my_font)
plt.title("2017年内地电影票房top20", fontproperties=my_font)
# Pad margins so that markers don't get clipped by the axes
# plt.margins(0.2)
# 调整间距以防止勾号标签被剪切导致x轴显示不全或x轴描述显示不全
plt.subplots_adjust(bottom=0.3)
# 添加网格
plt.grid(alpha=0.3)
# 展示图像
plt.show()
注意:在切换成横着的条形图之后,调用plt.barh()方法来绘制,这时x和y的数据不用更换,只需要注意在设置长条的宽度时参数变为了height即可。

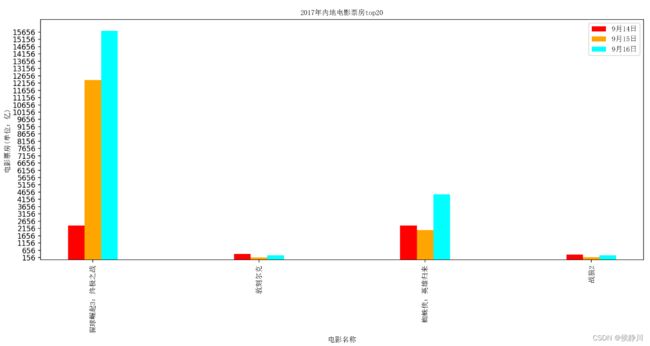
假设我们知道了列表a中电影分别在三天的票房,如何展示列表中电影本省的票房以及同其他电影的数据对比情况呢?我们可以采用绘制多次条形图的办法来实现。代码实现如下:
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 绘制电影票房条形图
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# x轴数据 电影名字
x = ["猩球崛起3:终极之战", "敦刻尔克", "蜘蛛侠:英雄归来", "战狼2"]
# y轴数据 对应电影的票房
y14 = [2358, 399, 2358, 362]
y15 = [12357, 156, 2045, 168]
y16 = [15746, 312, 4497, 319]
# 重新设置x轴数据 让其不重合
bar_width = 0.1
x_14 = list(range(len(x)))
x_15 = [i+bar_width for i in x_14]
x_16 = [i+bar_width*2 for i in x_14]
# 设置图形大小
plt.figure(figsize=(15, 8), dpi=160)
# 设置x轴刻度 生成电影的序号与电影名一一对应 因为这里绘制了多个条形图 所以我们刻度对应中间那个即可
plt.xticks(x_15, x, fontproperties=my_font, rotation=90)
# 设置y轴刻度
_y = y14 + y15 + y16
plt.yticks(range(min(_y), max(_y)+1, 500))
# 绘制条形图 由于bar绘制条形图只能接受含数字的可迭代对象
# 所以我们不能传入x来绘制,而要传入_x来绘制
# width表示长条的宽度 默认0.8
plt.bar(x_14, y14, color="red", width=bar_width, label="9月14日")
plt.bar(x_15, y15, color="orange", width=bar_width, label="9月15日")
plt.bar(x_16, y16, color="cyan", width=bar_width, label="9月16日")
# 添加图像描述
plt.xlabel("电影名称", fontproperties=my_font)
plt.ylabel("电影票房(单位:亿)", fontproperties=my_font)
plt.title("2017年内地电影票房top20", fontproperties=my_font)
# 添加图例
plt.legend(prop=my_font, loc=0)
# 调整间距以防止勾号标签被剪切导致x轴显示不全或x轴描述显示不全
plt.subplots_adjust(bottom=0.3)
# 展示图像
plt.show()
注意:当我们要将多个条形图绘制到一个图中时,我们需要将x轴移动一点(移动一个width的距离),即重新设置一个x轴数据
3.3 绘制直方图
假设我们获取了250部电影的时长(列表a中),希望统计出这些电影时长的分布状态(比如时长为100分钟到120分钟电影的数量,出现的频率)等信息,应该如何呈现这些数据?
我们可以使用直方图来呈现这些数据。
绘制直方图就需要设置组数,那么我们计算一个合适的组数可以参考如下公式:

根据这个公式就可以确定组数的大小了,这样我们可以调用plt.hist()方法来绘制直方图。代码实现如下:
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 绘制电影时长直方图
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
a = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124,
101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111, 78, 132, 124, 113, 150, 110, 117, 86,
95, 144, 105, 126, 130, 126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136, 123, 117, 119, 105, 137,
123, 128, 125, 104, 109, 134, 125, 127, 105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114, 105, 115,
132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134, 156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,
123, 107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133, 112, 114, 122, 109, 106, 123, 116, 131, 127,
115, 118, 112, 135, 115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154, 136, 100, 118, 119, 133, 134,
106, 129, 126, 110, 111, 109, 141, 120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126, 114, 140, 103,
130, 141, 117, 106, 114, 121, 114, 133, 137, 92, 121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113, 134,
106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110, 105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146,
133, 101, 131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111, 111, 133, 150]
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=150)
# 计算组数
bin_width = 3 # 组距
num_bins = (max(a) - min(a)) // bin_width
# 设置x轴的刻度
plt.xticks(range(min(a), max(a)+bin_width, bin_width))
# 绘制直方图 传入需要统计的数据和组数即可
plt.hist(a, num_bins)
# 添加网格
plt.grid()
# 添加图像描述
plt.ylabel("电影数量", fontproperties=my_font)
plt.xlabel("电影时长(单位:分钟)", fontproperties=my_font)
plt.title("250部电影时长分布直方图", fontproperties=my_font)
# 展示图片
plt.show()
注意:在绘制直方图的时候,一定要选对组数,不然生成的图片中x轴刻度对应不上直方图。
生成的图片如下:

以上是频数直方图的画法,如果想要生成频率直方图,只需要设置plt.hist(density=True)即可,生成图片的效果如下:

那么假设我们目前有一组已经统计好的数据要我们绘制直方图,我们还能使用plt.hist方法吗?
不能,plt.hist只能绘制未统计好的数据,但我们可以使用plt.bar来绘制条形图模拟直方图(即将width设置过大导致看起来连续)。
假设目前有一组统计好的数据:在美国2004年人口普查发现有124 million的人在离家相对较远的地方工作。根据他们从家到上班地点所需要的时间,通过抽样统计(最后一列)出了下表的数据。

我们可以根据统计好的数据来绘制条形图从而模拟生成直方图,代码实现如下:
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 绘制条形图模拟直方图
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# 已经统计好的数据
# interval为x轴刻度 width为组距宽度 quantity为统计到的值
interval = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 60, 90]
width = [5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 30, 60]
quantity = [836, 2737, 3723, 3926, 3596, 1438, 3273, 642, 824, 613, 215, 47]
# 设置图形大小
plt.figure(figsize=(20, 8), dpi=160)
# 设置x轴刻度 这里加1是因为width为12个数 实际上x轴的刻度要显示13个数
# 并且因为条形图的刻度对应的都是长条的正中央 所以我们要将刻度左移0.5
_x = [i-0.5 for i in range(13)]
# 根据width手动计算出最后一个刻度为150
xticks_labels = interval + [150]
plt.xticks(_x, xticks_labels)
# 绘制条形图
plt.bar(range(len(quantity)), quantity, width=1)
# 添加网格
plt.grid()
# 展示图形
plt.show()
注意:在使用条形图来模拟直方图的时候,要注意给出的刻度和宽度,因为直方图的刻度要比条形图的刻度多一个,所以可能我们需要手动计算最后一个刻度
注意:因为条形图的刻度对应的是长条的正中央,而直方图对应的是两边,所以我们要左移刻度来对应到两边。
生成的图片为:

3.4 其他的图形
在matplotlib中除了以上可以绘制的图形外,还有各种各样的图形可以绘制,我们只需要在使用的时候,查看官方文档即可,用法大致都差不多。
官方文档链接:https://matplotlib.org/stable/plot_types/index.html
四、NumPy的使用
4.1 什么是NumPy
NumPy帮助我们处理数值型数据
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。NumPy 是一个运行速度非常快的数学库,主要用于数组计算。
4.2 NumPy基础
Numpy中最重要的一个数据类型即ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。ndarray 对象是用于存放同类型元素的多维数组。
快速创建一个ndarray对象:
import numpy as np
# 传入列表来创建ndarray对象
t1 = np.array([1, 2, 3, 4])
print(t1) # [1 2 3 4]
print(type(t1)) # ndarray类型中有一个属性为dtype,表示的是ndarray中存放的数据的数据类型
dtype的类型有很多,如下:

我们在创建ndarray数组的过程中可以指定dtype:
# 指定数据类型dtype 可以指定python内置数据类型 也可以使用字符串指定dtype中的数据类型
t4 = np.array(range(1, 5, 1), dtype=float)
# t4 = np.array(range(1, 5, 1), dtype="l3")
# t4 = np.array(range(1, 5, 1), dtype="float32")
print(t4) # [1. 2. 3. 4.]
print(type(t4)) # numpy中对小数的操作:
import numpy as np
import random
# numpy中针对小数的操作
t1 = np.array([random.random() for i in range(10)])
print(t1)
# [0.43432773 0.36172079 0.16807058 0.94278348 0.11666628 0.718820460.26382661 0.56468615 0.72081291 0.24169676]
print(t1.dtype) # float64
# 修改浮点型的小数位数
t2 = np.round(t1, 2)
print(t2)
# [0.41 0.73 0.77 0.18 0.44 0.49 0.27 0.8 0.6 0.66]
print(t2.dtype) # float64
ndarray类型中有一个属性为shape,表示的是ndarray中保存数组的形状,我们也可以使用reshape()方法来改变数组形状。
import numpy as np
t1 = np.array([[1, 2, 3], [4, 5, 6]])
print(t1.shape) # (2, 3) 表示两行三列的二维数组
t2 = np.array(range(24)).reshape((4, 6))
print(t2)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
print(t2.shape) # (4, 6)
t3 = t2.reshape((2, 2, 6))
print(t3)
# 变成了 两块 两行 六列
# [[[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
#
# [[12 13 14 15 16 17]
# [18 19 20 21 22 23]]]
print(t3.shape) # (2, 2, 6)
# 变成一维的数组 不能写(1, 24) 元组中数字的个数代表维数
t4 = t3.reshape((24,))
print(t4)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
print(t4.shape) # (24,)
# 变成一维数组有一个特殊的方法 flatten() 可以将ndarray数组拉直成一维的
t5 = t3.flatten()
print(t5)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
print(t5.shape) # (24,)
注意:reshape方法不会改变原有的数组,而是返回一个修改后的新数组
**ndarray数组的计算:**广播机制
数组和数的计算
import numpy as np
t1 = np.array(range(24), dtype="i1").reshape((4, 6))
print(t1)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
t1 = t1 + 2
print(t1)
# numpy的广播机制会使ndarray数字中的每一个数都加2
# [[ 2 3 4 5 6 7]
# [ 8 9 10 11 12 13]
# [14 15 16 17 18 19]
# [20 21 22 23 24 25]]
t1 = t1 / 0
print(t1)
# inf表示为无限大 即在numpy中一个数除以0 会将0看成一个非常小的值 导致计算结果为无限大
# [[inf inf inf inf inf inf]
# [inf inf inf inf inf inf]
# [inf inf inf inf inf inf]
# [inf inf inf inf inf inf]]
数组和数组的计算:
t2 = np.array(range(0, 24), dtype="i2").reshape((4, 6))
t3 = np.array(range(100, 124), dtype="i2").reshape((4, 6))
print(t2)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
print(t3)
# [[100 101 102 103 104 105]
# [106 107 108 109 110 111]
# [112 113 114 115 116 117]
# [118 119 120 121 122 123]]
t4 = t2 + t3
print(t4)
# 对应位置相加
# [[100 102 104 106 108 110]
# [112 114 116 118 120 122]
# [124 126 128 130 132 134]
# [136 138 140 142 144 146]]
t5 = t2 * t3
print(t5)
# 对应位置相乘 而非点乘
# [[ 0 101 204 309 416 525]
# [ 636 749 864 981 1100 1221]
# [1344 1469 1596 1725 1856 1989]
# [2124 2261 2400 2541 2684 2829]]
# 当数组的维度不同时 但在某一维度上的形状一致 则会选择该维度进行计算
t6 = np.arange(6)
print(t6) # [0 1 2 3 4 5]
t7 = t5 - t6
print(t7)
# 可以发现由于是列数一样 所以t5的每一行都减去了t6
# [[ 0 100 202 306 412 520]
# [ 636 748 862 978 1096 1216]
# [1344 1468 1594 1722 1852 1984]
# [2124 2260 2398 2538 2680 2824]]
t8 = np.array(range(4)).reshape((4, 1))
print(t8)
# [[0]
# [1]
# [2]
# [3]]
t9 = t5 - t8
print(t9)
# 会发现t5的每一列都减去了t8
# [[ 0 101 204 309 416 525]
# [ 635 748 863 980 1099 1220]
# [1342 1467 1594 1723 1854 1987]
# [2121 2258 2397 2538 2681 2826]]
# 当两个数组的形状完全不一致的时候 则无法进行计算
# 点乘
a = np.arange(12).reshape((3, 4))
b = np.arange(12).reshape((4, 3))
print(a)
print(b)
c = a.dot(b)
print(c)
# [[ 42 48 54]
# [114 136 158]
# [186 224 262]]
注意:数组和数组之间的计算,当维度不同的时候,由以下原则可以判断能否进行计算:

例如,shape为(3,3,3)的数组不能和(3,2)的数组进行计算,shape为(3,3,2)的数组能和(3,2)或(3,1)或(3,3)的数组进行计算。即观察是否有某一个方向上大小相同或某个方向大小为1的,当任何一个方向上大小都不一样的时候则不能进行计算。
ndarray数组的转置:可以通过调用transpose方法来进行转置或**调用其属性T进行转置或调用交换轴的方法swapaxes**来指定轴进行转置
t = np.array(range(24)).reshape((4, 6))
print(t)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
t = t.transpose()
print(t)
# [[ 0 6 12 18]
# [ 1 7 13 19]
# [ 2 8 14 20]
# [ 3 9 15 21]
# [ 4 10 16 22]
# [ 5 11 17 23]]
t = t.T
print(t)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
# 交换轴 交换0轴和1轴
t = t.swapaxes(1, 0)
print(t)
# [[ 0 6 12 18]
# [ 1 7 13 19]
# [ 2 8 14 20]
# [ 3 9 15 21]
# [ 4 10 16 22]
# [ 5 11 17 23]]
**ndarray中轴(axis)的概念:**在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴。
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值。
维度不同的数组,其轴的方向是不同的,例如维度为2的数组,axis=0代表的是行就是改变列方向。但维度为3的数组,axis=0代表的即为改变块方向上。所以不能单纯的记住axis=0代表列方向,这只是根据二维数组来说的。


4.3 NumPy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的。
其NumPy中读取数据的方法为:
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

注意:unpack参数为True时,表示读出的数组转置
例如我们读取下面两个csv文件,代码如下:
import numpy as np
# 设置文件路径
us_file_path = "../CSV/archive_01/USvideos0123.csv"
gb_file_path = "../CSV/archive_01/GBvideos0123.csv"
# 读取文件 跳过第一行
us_arr = np.loadtxt(us_file_path, delimiter=",", dtype="int", skiprows=1)
gb_arr = np.loadtxt(gb_file_path, delimiter=",", dtype="int", skiprows=1)
print(us_arr)
print(gb_arr)
4.4 NumPy切片和索引
对于我们刚刚加载出来的数据,若只想选择其中的某一列(行),应该怎么做?
这时候就会用到numpy中的切片和索引的操作了。
import numpy as np
a = np.arange(24).reshape((4, 6))
print(a)
# 取一行
print(a[2]) # [12 13 14 15 16 17]
# 取连续的多行
print(a[1:])
# [[ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
# 取不连续的多行
print(a[[0, 2]])
# [[ 0 1 2 3 4 5]
# [12 13 14 15 16 17]]
# 通用的方法
# 取一行 列都要
print(a[1, :])
# 取连续的多行 列都要
print(a[2:, :])
# 取不连续的多行 列都要
print(a[[0, 2], :])
# 当然也可以加上步长 例如从第一行开始按照步长2来取
print(a[1::2, :])
# [[ 6 7 8 9 10 11]
# [18 19 20 21 22 23]]
# 取列
# 取一列
print(a[:, 0]) # [ 0 6 12 18]
# 取连续的多列
print(a[:, 2:])
# [[ 2 3 4 5]
# [ 8 9 10 11]
# [14 15 16 17]
# [20 21 22 23]]
# 取不连续的多列
print(a[:, [0, 2]])
# [[ 0 2]
# [ 6 8]
# [12 14]
# [18 20]]
# 取行和列
# 取单行和单列 例如第三行第四列的值
val = a[3, 4]
print(val) # 22
# 返回值的类型是numpy中的dtype类型的值
print(type(val)) # 我们可以对取到区域的值重新进行赋值,直接赋值即可完成。
假设我们要取的值条件更复杂怎么办?我们可以使用更高级的索引布尔索引和三元运算where方法和clip裁剪方法来实现:
import numpy as np
a = np.arange(24).reshape((4, 6))
print(a)
# 如果我们想给某些元素赋值 那么使用切片操作后直接赋值即可
a[1,:] = 0
print(a)
# [[ 0 1 2 3 4 5]
# [ 0 0 0 0 0 0]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
# 如果我们想给数组中大于10的值赋值为0 那么我们可以使用布尔索引
a = np.arange(24).reshape((4, 6))
a[a>10] = 0
print(a)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 0]
# [ 0 0 0 0 0 0]
# [ 0 0 0 0 0 0]]
# 如果我们想将大于10的赋值为10 小于10的赋值为0 那么我们可以使用where方法
a = np.arange(24).reshape((4, 6))
a = np.where(a>10, 10, 0)
print(a)
# [[ 0 0 0 0 0 0]
# [ 0 0 0 0 0 10]
# [10 10 10 10 10 10]
# [10 10 10 10 10 10]]
# 如果我们想将小于10的赋值为10 大于20的赋值为20 那么我们可以使用clip方法
a = np.arange(24).reshape((4, 6))
a = np.clip(a, 10, 20)
print(a)
# [[10 10 10 10 10 10]
# [10 10 10 10 10 11]
# [12 13 14 15 16 17]
# [18 19 20 20 20 20]]
print('*' * 100)
4.5 Numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
- 当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
- 当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf):
- 比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
关于nan和inf,我们用代码来演示:
# numpy中nan是浮点类型的 nan: Final[float] 即整数类型的dtype无法赋值为nan
a = np.arange(24).reshape((4, 6))
# a[1, 1] = np.nan
a = a.astype("float32")
a[1, 1] = np.nan
print(a)
# [[ 0. 1. 2. 3. 4. 5.]
# [ 6. nan 8. 9. 10. 11.]
# [12. 13. 14. 15. 16. 17.]
# [18. 19. 20. 21. 22. 23.]]
# 在上面的clip方法中 nan是不会被替换的
# *******************************************************************************
import numpy as np
# 两个nan是不相等的
print(np.nan == np.nan) # False
print(np.nan != np.nan) # True
# 根据两个nan不相等的特性 我们可以使用 count_nonzero方法来统计数组中nan的个数
a = np.arange(24, dtype="float").reshape((4, 6))
a[:, 0] = 0
a[3, 4] = np.nan
print(a != a)
# [[False False False False False False]
# [False False False False False False]
# [False False False False False False]
# [False False False False True False]]
# 统计数组中不是0的个数
count = np.count_nonzero(a != a)
print(count) # 1
# 实际上 np.isnan方法 就是 执行的 a != a 的操作
a1 = np.isnan(a)
print(a1)
# [[False False False False False False]
# [False False False False False False]
# [False False False False False False]
# [False False False False True False]]
count = np.count_nonzero(a1)
print(count) # 1
# 我们可以利用 isnan方法 来将nan的值设置为0
# a[np.isnan(a)] = 0
print(a)
# [[ 0. 1. 2. 3. 4. 5.]
# [ 0. 7. 8. 9. 10. 11.]
# [ 0. 13. 14. 15. 16. 17.]
# [ 0. 19. 20. 21. 0. 23.]]
# nan和任何值计算都是nan 例如np.sum()用于数组求和
print(np.sum(a)) # nan
# 对每一列进行求和
print(np.sum(a, axis=0))
# [ 0. 40. 44. 48. nan 56.]
在一组数据中如果出现nan的话,是做不了计算的,那么我们会想办法将nan替换掉,直接替换为0也不合适,一般我们可以替换为均值或中值,最暴力的方法是将nan所在的一行数据全部删掉。为了能够方便的计算出均值和中值,我们来引入numpy中常用的统计函数。
4.6 NumPy中常用的统计函数
-
求和:t.sum(axis=None)
-
均值:t.mean(a,axis=None) 受离群点的影响较大
-
中值:np.median(t,axis=None)
-
最大值:t.max(axis=None)
-
最小值:t.min(axis=None)
-
极值:np.ptp(t,axis=None) 即最大值和最小值只差
-
标准差:t.std(axis=None):标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。反映出数据的波动稳定情况,越大表示波动越大,越不稳定。

代码展示如下:
import numpy as np
a = np.arange(24, dtype="float").reshape((4, 6))
a[:, 0] = 0
a[3, 4] = np.nan
print(a)
# [[ 0. 1. 2. 3. 4. 5.]
# [ 0. 7. 8. 9. 10. 11.]
# [ 0. 13. 14. 15. 16. 17.]
# [ 0. 19. 20. 21. nan 23.]]
print('*' * 100)
# 常用的统计函数
# 默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
# 求和
print(a.sum(axis=0)) # [ 0. 40. 44. 48. nan 56.]
# 均值
print(a.mean(axis=0)) # [ 0. 10. 11. 12. nan 14.]
# 中值
print(np.median(a, axis=0)) # [ 0. 10. 11. 12. nan 14.]
# 最大值
print(a.max(axis=0)) # [ 0. 19. 20. 21. nan 23.]
# 最小值
print(a.min(axis=0)) # [ 0. 1. 2. 3. nan 5.]
# 极值
print(np.ptp(a, axis=0)) # [ 0. 18. 18. 18. nan 18.]
# 标准差
print(a.std(axis=0)) # [0. 6.70820393 6.70820393 6.70820393 nan 6.70820393]
接下来,我们来演示如何将数组中的nan值替换掉,代码如下:
import numpy as np
t1 = np.arange(12).reshape((3, 4)).astype("float")
t1[1, 2:] = np.nan
print(t1)
# [[ 0. 1. 2. 3.]
# [ 4. 5. nan nan]
# [ 8. 9. 10. 11.]]
# 定义一个方法将nan替换为当前列的均值
def fill_nan_by_column_mean(t):
for i in range(t.shape[1]): # 对列进行遍历
nan_num = np.count_nonzero(np.isnan(t[:, i])) # 计算当前列nan的个数
if nan_num > 0: # 如果存在nan
now_col = t[:, i]
now_col_not_nan_sum = now_col[np.isnan(now_col) == False].sum() # 求当前列不是nan的值的和
now_col_mean = now_col_not_nan_sum / (t.shape[0] - nan_num) # 求出当前列的均值
print("mean = " + str(now_col_mean))
now_col[np.isnan(now_col)] = now_col_mean # 将nan替换为当前列的均值
t[:, i] = now_col # 更新当前列
return t
fill_nan_by_column_mean(t1)
print(t1)
# mean = 6.0
# mean = 7.0
# [[ 0. 1. 2. 3.]
# [ 4. 5. 6. 7.]
# [ 8. 9. 10. 11.]]
4.7 使用NumPy来解决实际问题
英国和美国各自youtube1000的数据结合之前的matplotlib绘制出各自的评论数量的直方图,这里我们只绘制美国的直方图,代码如下:
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# 设置文件路径
us_file_path = "../CSV/archive_01/USvideos0123.csv"
gb_file_path = "../CSV/archive_01/GBvideos0123.csv"
# 读取文件 跳过第一行
us_arr = np.loadtxt(us_file_path, delimiter=",", dtype="int", skiprows=1)
gb_arr = np.loadtxt(gb_file_path, delimiter=",", dtype="int", skiprows=1)
# 提取出各自评论的数量 即x轴数据
us_comment_arr = us_arr[:, -1]
gb_comment_arr = gb_arr[:, -1]
# 去掉值大于5000的数据
us_comment_arr = us_comment_arr[us_comment_arr <= 5000]
# 计算组数
bin_width = 100 # 组距
num_bins = (max(us_comment_arr) - min(us_comment_arr)) // bin_width
print(num_bins)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=150)
# 绘制图像
plt.hist(us_comment_arr, num_bins, color="orange")
# 设置x轴刻度
plt.xticks(range(min(us_comment_arr), max(us_comment_arr)+bin_width, bin_width), rotation=45)
# 添加网格
plt.grid()
# 添加描述信息
plt.xlabel("评论数量", fontproperties=my_font)
plt.ylabel("视频数量", fontproperties=my_font)
plt.title("美国YouTube视频评论数量分布直方图", fontproperties=my_font)
# 展示图像
plt.show()

希望了解英国的youtube中视频的评论数和喜欢数的关系,应该如何绘制改图?
我们可以绘制散点图来解决这个问题。代码如下:
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 了解英国的youtube中视频的评论数和喜欢数的关系
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\simsun.ttc")
# 设置文件路径
gb_file_path = "../CSV/archive_01/GBvideos0123.csv"
# 读取文件 跳过第一行
gb_arr = np.loadtxt(gb_file_path, delimiter=",", dtype="int", skiprows=1, usecols=(1, 3))
# print(gb_arr)
# 选择喜欢数比50万小的数据
gb_arr = gb_arr[gb_arr[:, 1] < 500000]
# 分别提取出like量数组 和 comment量数组
gb_like_arr = gb_arr[:, 1]
gb_comment_arr = gb_arr[:, -1]
# print(gb_like_arr)
# print(gb_comment_arr)
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=150)
# 绘制图像
plt.scatter(gb_like_arr, gb_comment_arr)
# 添加描述信息
plt.xlabel("like数量", fontproperties=my_font)
plt.ylabel("comment数量", fontproperties=my_font)
plt.title("英国YouTube视频like和comment数量关系散点图", fontproperties=my_font)
# 展示图像
plt.show()
4.8 NumPy中数组拼接与交换行、列
数组拼接调用的是vstack和hstack方法,交换行、交换列使用的是重新赋值的方法
import numpy as np
t1 = np.arange(12).reshape((2, 6))
t2 = np.arange(12, 24).reshape((2, 6))
print(t1)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
print(t2)
# [[12 13 14 15 16 17]
# [18 19 20 21 22 23]]
# 数组的拼接
# 横向拼接
t3 = np.hstack((t1, t2))
print(t3)
# [[ 0 1 2 3 4 5 12 13 14 15 16 17]
# [ 6 7 8 9 10 11 18 19 20 21 22 23]]
# 竖直拼接
t4 = np.vstack((t1, t2))
print(t4)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
# 数组行交换 列交换
t = np.arange(12, 24).reshape((3, 4))
print(t)
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]
# 将第二行和第三行交换
t[[1, 2], :] = t[[2, 1], :]
print(t)
# [[12 13 14 15]
# [20 21 22 23]
# [16 17 18 19]]
# 将第一列和第三列交换
t[:, [0, 2]] = t[:, [2, 0]]
print(t)
# [[14 13 12 15]
# [22 21 20 23]
# [18 17 16 19]]
例子:现在希望将之前案例中两个国家的数据方法一起来进行研究,同时保留国家的信息(每条数据的国家来源),应该怎么做?代码实现如下:
import numpy as np
# 设置读取文件的路径
us_file_path = "../CSV/archive_01/USvideos0123.csv"
gb_file_path = "../CSV/archive_01/GBvideos0123.csv"
# 读取文件
us_arr = np.loadtxt(us_file_path, dtype="int", delimiter=",", skiprows=1)
gb_arr = np.loadtxt(gb_file_path, dtype="int", delimiter=",", skiprows=1)
# 处理数据 将每一个数组加一列数据来源的国家
# 这里0表示us 1表示gb
us_info_arr = np.zeros((us_arr.shape[0], 1), dtype=int)
gb_info_arr = np.ones((gb_arr.shape[0], 1), dtype=int)
# print(us_info_arr)
# print(gb_info_arr)
us_arr = np.hstack((us_arr, us_info_arr))
gb_arr = np.hstack((gb_arr, gb_info_arr))
# print(us_arr)
# print(gb_arr)
# 将两个国家的数据进行拼接
arr = np.vstack((us_arr, gb_arr))
print(arr)
# [[4394029 320053 5931 46245 0]
# [7860119 185853 26679 0 0]
# [5845909 576597 39774 170708 0]
# ...
# [ 170003 6592 127 454 1]
# [ 893125 44811 652 2056 1]
# [1474925 58532 3223 14396 1]]
4.9 NumPy中创建特殊数组的方法
在最后,还有一些快捷的方法方便我们使用,例如:
import numpy as np
# 创建一个全0的数组
t1 = np.zeros((3, 4), dtype=int)
print(t1)
# [[0 0 0 0]
# [0 0 0 0]
# [0 0 0 0]]
# 创建一个全1的数组
t2 = np.ones((3, 4), dtype=int)
print(t2)
# [[1 1 1 1]
# [1 1 1 1]
# [1 1 1 1]]
# 创建单位矩阵
t3 = np.eye(3)
print(t3)
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
# 获取最大值 最小值的位置
print(np.argmax(t3, axis=0)) # [0 1 2]
t3[t3 == 1] = -1
print(t3)
# [[-1. 0. 0.]
# [ 0. -1. 0.]
# [ 0. 0. -1.]]
print(np.argmin(t3, axis=1)) # [0 1 2]
除此之外,还有有关numpy生成随机数的方法:

import random
import numpy as np
# numpy生成随机数组
# rand()生成均匀分布的随机数数组 浮点数 范围0-1
t1 = np.random.random((3, 4))
print(t1)
# [[0.62126117 0.39281679 0.12689758 0.44011514]
# [0.81656603 0.26793356 0.15391204 0.26048273]
# [0.53988191 0.09194691 0.10156257 0.49374052]]
# randn()生成标准正态分布的随机数数组 浮点数 平均数为0 标准差为1
t2 = np.random.randn(3, 4)
print(t2)
# [[-0.99719964 -0.92671733 -0.66757139 0.58836346]
# [-0.32952336 -0.21159296 0.98641237 1.57330059]
# [ 0.36211835 -0.65642499 0.42358759 0.87969236]]
# randint()从给定的上下限选取随机整数构成随机数数组
t3 = np.random.randint(10, 20, (3, 4))
print(t3)
# [[10 10 10 15]
# [12 16 16 18]
# [18 11 12 18]]
# uniform()从给定的上下限中选取随机浮点数来构成均匀分布的随机数数组
t4 = np.random.uniform(10, 20, (3, 4))
print(t4)
# [[11.42312609 18.53202919 16.35032317 10.58863793]
# [12.14488183 18.5306514 13.28766479 14.87781637]
# [18.60283709 18.12281844 10.60385424 11.63453863]]
# normal()从指定正态分布中随机抽取样本 分布中心为loc 标准差为scale
t5 = np.random.normal(0, 1, (3, 4))
print(t5)
# [[-0.47506168 0.48176307 0.6167924 1.20963802]
# [ 0.80811058 -0.36889478 0.60429659 1.90024402]
# [ 0.23394873 -1.41348168 0.29006471 -0.83633099]]
# 设置随机数种子 设定种子后 可以每次生成相同的随机数
np.random.seed(10)
t = np.random.randint(10, 20, (3, 4))
print(t)
# [[19 14 10 11]
# [19 10 11 18]
# [19 10 18 16]]
# 多次执行还是上面的数组
4.10 NumPy的注意点copy和view
-
a = b 完全不复制,a和b相互影响
-
a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的。
-
a = b.copy(),复制,a和b互不影响。
所以,直接赋值的操作是浅拷贝,只是将指针赋值给了新变量,如果改变原来数组中的数据,那么新变量指向的区域也是会改变的,因为指向的是同一块区域
视图操作即切片,虽然会产生新的对象,但产生的新的对象数据也是由旧对象保管的(实际上应该是包装了一层,最底层还是指向的旧对象的内存区域),所以两个变量也会相互影响
copy方法是深拷贝,即开辟了一块新的内存区域来进行copy,这时候两个变量不会相互影响
五、Pandas的使用
numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够,很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等:
-
比如:我们通过爬虫获取到了存储在数据库中的数据
-
比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等
所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据。
Pandas中主要有两个数据结构:series和dataFrame,分别处理一维(带标签/索引的数组)的和二维的数据(Series容器)
5.1 Series数据类型
Series的创建:
import string
import pandas as pd
t = pd.Series([1, 2, 3, 4])
print(t)
# 0 1
# 1 2
# 2 3
# 3 4
# dtype: int64
print(type(t)) # Series的切片和索引:
import string
import pandas as pd
# 我们创建一个series
temp_dict = {string.ascii_uppercase[i]: i for i in range(10)}
t = pd.Series(temp_dict)
# 获取t的索引值
print(t.index) # Index(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
print(type(t.index)) # 5.2 Pandas读取外部数据
现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?

我们使用pd.read_csv方法来读取这些数据,代码如下:
import pandas as pd
df = pd.read_csv("../CSV/archive_02/dogNames2.csv")
print(df)
# Row_Labels Count_AnimalName
# 0 1 1
# 1 2 2
# 2 40804 1
# 3 90201 1
# 4 90203 1
# ... ... ...
# 16215 37916 1
# 16216 38282 1
# 16217 38583 1
# 16218 38948 1
# 16219 39743 1
#
# [16220 rows x 2 columns]
我们以为读取的结果会返回一个series数据类型的对象,但实际上不是,而是返回了一个dataFrame对象,我们接下来来了解一下该类型。
5.3 DataFrame数据类型
DataFrame的创建:
import numpy as np
import pandas as pd
# 传入一个二维数组来创建DataFrame
t1 = pd.DataFrame(np.arange(12).reshape((3, 4)))
print(t1)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
# 我们会发现其同时具有行索引index和列索引columns
# 我们也可以指定行索引和列索引
t2 = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list("abc"), columns=list("WXYZ"))
print(t2)
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
# 通过字典来创建DataFrame
temp_dict = {"name":["xiaoming", "xiaogang"], "age":[20, 32], "tel":[10086, 10010]}
t3 = pd.DataFrame(temp_dict)
print(t3)
# name age tel
# 0 xiaoming 20 10086
# 1 xiaogang 32 10010
# 通过列表中存放的字典来创建DataFrame
temp_list = [{"name":"xiaoming", "age":18, "tel":10086}, {"name":"xiaogang", "tel":10010}, {"age":20, "tel":12345}]
t4 = pd.DataFrame(temp_list)
print(t4)
# 可以发现如果某个字典没有其他字典对应的字段 就会将该字段的值设置为NaN
# name age tel
# 0 xiaoming 18.0 10086
# 1 xiaogang NaN 10010
# 2 NaN 20.0 12345
DataFrame对象既有行索引,又有列索引
-
行索引,表明不同行,横向索引,叫index,0轴,axis=0
-
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
通过上面的练习,我们会发现,DataFrame中装的实际上就是很多个Series,所以被称为Series容器
DataFrame的属性和方法:

import pandas as pd
temp_dict = {"name": ["xiaoming", "xiaogang"], "age": [20, 32], "tel": [10086, 10010]}
t = pd.DataFrame(temp_dict)
# DataFrame的属性
print(t.shape) # (2, 3)
print(t.dtypes)
# name object
# age int64
# tel int64
# dtype: object
print(t.ndim) # 2
print(t.index) # RangeIndex(start=0, stop=2, step=1)
print(t.columns) # Index(['name', 'age', 'tel'], dtype='object')
print(t.values)
# 是一个二维的ndarray数组
# [['xiaoming' 20 10086]
# ['xiaogang' 32 10010]]
# DataFrame整体情况查询的方法
print(t.head(3))
# name age tel
# 0 xiaoming 20 10086
# 1 xiaogang 32 10010
print(t.tail(3))
# name age tel
# 0 xiaoming 20 10086
# 1 xiaogang 32 10010
print(t.info())
# 展示一下关于DataFrame的信息
# 我们回到Pandas读取外部数据的案例中,分析一下dogName数据的信息,取出使用次数最多的十个名字。这里我们就需要用到了一个排序的方法即sort_values(),代码示例如下:
import pandas as pd
df = pd.read_csv("../CSV/archive_02/dogNames2.csv")
# 查看一下基本信息
print(df.head())
# Row_Labels Count_AnimalName
# 0 1 1
# 1 2 2
# 2 40804 1
# 3 90201 1
# 4 90203 1
print(df.info())
# 这里我们并没有取出前十条数据,因为还没有学DataFrame的切片和索引,下面我们开始介绍。
DataFrame的切片和索引:
import numpy as np
import pandas as pd
df = pd.read_csv("../CSV/archive_02/dogNames2.csv")
# 按照名字使用次数进行降序
df = df.sort_values(by="Count_AnimalName", ascending=False)
# Pandas取行或者列
# 方括号写数字表示取行 对行进行操作
# 方括号写字符串表示取列索引,对列进行操作
# 取前20行数据
print(df[:20])
# 取Row_Labels索引的这一列
print(df["Row_Labels"])
# 1156 BELLA
# 9140 MAX
# 2660 CHARLIE
# 3251 COCO
# 12368 ROCKY
# ...
# 6884 J-LO
# 6888 JOANN
# 6890 JOAO
# 6891 JOAQUIN
# 16219 39743
# Name: Row_Labels, Length: 16220, dtype: object
print(type(df["Row_Labels"]))
# 如果我们想取指定的列和行 就可以使用loc和iloc:
-
df.loc 通过标签索引行数据
-
df.iloc 通过位置获取行数据
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list("abc"), columns=list("WXYZ"))
print(df)
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
# loc[行索引,列索引] 通过标签来获取数据
print(df.loc["a", "W"]) # 0
print(df.loc["a", ["W", "X"]])
# W 0
# X 1
# Name: a, dtype: int32
print(type(df.loc["a", ["W", "X"]])) # 同样,通过切片和索引选中以后,可以对其进行赋值来更改数据。
那么,根据之前的案例,假如我们想要取狗狗名字使用次数大于800次的数据,该怎么取呢?同样我们可以使用布尔索引。代码示例如下:
import pandas as pd
df = pd.read_csv("../CSV/archive_02/dogNames2.csv")
# 例如我们取狗名使用超过800次的数据
df1 = df[df["Count_AnimalName"] > 800]
print(df1)
# Row_Labels Count_AnimalName
# 1156 BELLA 1195
# 2660 CHARLIE 856
# 3251 COCO 852
# 9140 MAX 1153
# 12368 ROCKY 823
# 如果想要设置多条件 我们还可以使用 & | 来添加条件
# 例如我们取狗名使用超过800次并且名字超过4个字符的数据
df2 = df[(df["Count_AnimalName"] > 800) & (df["Row_Labels"].str.len() > 4)]
print(df2)
# Row_Labels Count_AnimalName
# 1156 BELLA 1195
# 2660 CHARLIE 856
# 12368 ROCKY 823
关于字符串的方法,我们有很多需要经常使用,例如:

5.4 DataFrame缺失数据的处理
我们的缺失值一般会有两种情况,一种是nan一种是0,但0我们要确定它是无意义的才可以进行填充。相关代码如下:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list("abc"), columns=list("WXYZ"))
df.iloc[[1, 2], [0, 1]] = np.nan
print(df)
# W X Y Z
# a 0.0 1.0 2 3
# b NaN NaN 6 7
# c NaN NaN 10 11
# 判断数据是否为NaN:pd.isnull() pd.notnull()
print(pd.isnull(df))
# W X Y Z
# a False False False False
# b True True False False
# c True True False False
print(pd.notnull(df))
# W X Y Z
# a True True True True
# b False False True True
# c False False True True
# 处理方式1:删除NaN所在的行列 dropna(axis, how, inplace) 一般我们不这么处理
# how表示这一行/列是否需要全是NaN才删除 any为有NaN就删除 all为全是NaN才删除
# inplace表示是否对原有数据进行替换 True为替换 则无返回值
df1 = df.dropna(axis=0, how='any', inplace=False)
print(df1)
# W X Y Z
# a 0.0 1.0 2 3
# 处理方式2:填充数据
# df.mean()表示使用的每一列的中位数进行填充
df2 = df.fillna(df.mean(), inplace=False)
print(df2)
# 假设我们只想填充第0列的NaN 常用方法
df["W"] = df["W"].fillna(df["W"].mean())
print(df)
# W X Y Z
# a 0.0 1.0 2 3
# b 0.0 NaN 6 7
# c 0.0 NaN 10 11
# 如果要处理为0的数据 我们可以将为0的数据设置为NaN再进行处理
df[df == 0] = np.nan
print(df)
# W X Y Z
# a NaN 1.0 2 3
# b NaN NaN 6 7
# c NaN NaN 10 11
5.5 Pandas中常用统计函数
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?我们可以使用Pandas中的统计函数来获取,代码如下:
import pandas as pd
import numpy as np
df = pd.read_csv("../CSV/archive_03/IMDB-Movie-Data.csv")
# print(df.info())
# 例子:对于这一组电影数据,如果我们希望统计电影分类的情况,该如何处理数据?
我们可以重新构造一个全为0的二维数组,列名为电影类别,如果某一条数据中分类出现过,就让0变为1
这种思路很重要,在以后也会经常使用,代码实现如下:
import pandas as pd
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 处理数据
df = pd.read_csv("../CSV/archive_03/IMDB-Movie-Data.csv")
# print(df.info())
# 生成的图片如下:

5.6 DataFrame数据合并和分组聚合
join:默认情况下他是把行索引相同的数据合并到一起
import numpy as np
import pandas as pd
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "B"], columns=list("abcd"))
print(df1)
# a b c d
# A 1.0 1.0 1.0 1.0
# B 1.0 1.0 1.0 1.0
df2 = pd.DataFrame(np.zeros((3, 3)), index=list("ABC"), columns=list("xyz"))
print(df2)
# x y z
# A 0.0 0.0 0.0
# B 0.0 0.0 0.0
# C 0.0 0.0 0.0
# 将行索引相同的数据合并到一起 即合并列 以df1的行索引为准 df2中多的索引直接整行舍弃
df3 = df1.join(df2)
print(df3)
# a b c d x y z
# A 1.0 1.0 1.0 1.0 0.0 0.0 0.0
# B 1.0 1.0 1.0 1.0 0.0 0.0 0.0
# 以df2的行索引为准 df1中没有df2的索引补成NaN
df4 = df2.join(df1)
print(df4)
# x y z a b c d
# A 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# B 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# C 0.0 0.0 0.0 NaN NaN NaN NaN
merge:按照指定的列把数据按照一定的方式合并到一起

在pandas中类似的分组的操作我们有很简单的方式来完成:df.groupby(by="columns_name")
我们可以对其返回值进行遍历,其返回值为按照我们指定的字段分成的一个一个的元组,并且返回的group对象可以调用很多聚合函数供我们进行数据分析:

具体由代码来展示:
import pandas as pd
df = pd.read_csv("../CSV/archive_04/directory.csv")
# print(df.info())
# 5.7 索引和复合索引
设置索引和复合索引:
import numpy as np
import pandas as pd
df = pd.read_csv("../CSV/archive_04/directory.csv")
grouped = df["Brand"].groupby(by=[df["Country"], df["State/Province"]]).count()
print(grouped.index)
# MultiIndex([('AD', '7'),
# ('AE', 'AJ'),
# ('AE', 'AZ'),
# ...
# ('VN', 'HN'),
# ('VN', 'SG'),
# ('ZA', 'GT')],
# names=['Country', 'State/Province'], length=545)
df1 = pd.DataFrame(np.ones((2, 4), dtype="float"), index=["a", "b"], columns=list("abcd"))
print(df1)
# a b c d
# a 1.0 1.0 1.0 1.0
# b 1.0 1.0 1.0 1.0
# 查看df1的索引
print(df1.index)
# Index(['a', 'b'], dtype='object')
# 重新给df1指定索引
df1.index = ["c", "d"]
print(df1)
# a b c d
# c 1.0 1.0 1.0 1.0
# d 1.0 1.0 1.0 1.0
# 指定某一列作为索引 set_index("column_name", drop=True)
# drop为True 表示是否将指定的列作为索引后删除原来的列 默认为True
df1.loc["c", "a"] = 0
df2 = df1.set_index("a")
print(df2)
# b c d
# a
# 0.0 1.0 1.0 1.0
# 1.0 1.0 1.0 1.0
# 我们也可以设置某几列为复合索引
df3 = df1.set_index(["a", "b"])
print(df3)
# c d
# a b
# 0.0 1.0 1.0 1.0
# 1.0 1.0 1.0 1.0
# 返回index的唯一值 这说明索引是可以有重复值的
print(df2.index.unique())
# Float64Index([0.0, 1.0], dtype='float64', name='a')
# 复合索引用法
a = pd.DataFrame(
{'a': range(7), 'b': range(7, 0, -1), 'c': ['one', 'one', 'one', 'two', 'two', 'two', 'two'], 'd': list("hjklmno")})
print(a)
# a b c d
# 0 0 7 one h
# 1 1 6 one j
# 2 2 5 one k
# 3 3 4 two l
# 4 4 3 two m
# 5 5 2 two n
# 6 6 1 two o
b = a.set_index(["c", "d"])
print(b)
# a b
# c d
# one h 0 7
# j 1 6
# k 2 5
# two l 3 4
# m 4 3
# n 5 2
# o 6 1
如何使用复合索引来取数据:
import pandas as pd
a = pd.DataFrame(
{'a': range(7), 'b': range(7, 0, -1), 'c': ['one', 'one', 'one', 'two', 'two', 'two', 'two'], 'd': list("hjklmno")})
# 设置复合索引并且不删除原有列
b = a.set_index(["c", "d"], drop=False)
# print(b)
# a b c d
# c d
# one h 0 7 one h
# j 1 6 one j
# k 2 5 one k
# two l 3 4 two l
# m 4 3 two m
# n 5 2 two n
# o 6 1 two o
# Series复合索引的用法
# 我们取a列使其变成Series
c = b["a"]
# print(c)
# c d
# one h 0
# j 1
# k 2
# two l 3
# m 4
# n 5
# o 6
# Name: a, dtype: int64
# 如果我们取第一个索引
print(c["one"])
# d
# h 0
# j 1
# k 2
# Name: a, dtype: int64
# 我们取索引j对应的值 我们可以取两次索引来取到
print(c["one"]["j"]) # 1
# 我们可以将第一个索引和第二个索引交换位置
# 我们发现第一个索引要求必须是unique的 而第二个索引就不需要
d = c.swaplevel()
print(d)
# d c
# h one 0
# j one 1
# k one 2
# l two 3
# m two 4
# n two 5
# o two 6
# Name: a, dtype: int64
# DataFrame复合索引的用法
# 由于DataFrame在用[字符串]来索引的时候 是使用的列索引来查找的 所以不能这样来索引
# print(b["one"])
# print(b)
# a b c d
# c d
# one h 0 7 one h
# j 1 6 one j
# k 2 5 one k
# two l 3 4 two l
# m 4 3 two m
# n 5 2 two n
# o 6 1 two o
# 我们可以用loc来进行索引
# 取one h对应的值
print(b.loc["one"].loc["h"])
# a 0
# b 7
# c one
# d h
# Name: h, dtype: object
# 如果想直接取索引h对应的值 可以先交换一下两个索引
print(b.swaplevel().loc[["h"]])
# a b c d
# d c
# h one 0 7 one h
练习案例:使用matplotlib呈现出店铺总数排名前10的国家
代码如下:
import pandas as pd
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\\Windows\\Fonts\\simsun.ttc")
# 读数据
df = pd.read_csv("../CSV/archive_04/directory.csv")
# 使用matplotlib呈现出店铺总数排名前10的国家
# 数据清洗
# print(df.info())
# 
练习案例:使用matplotlib呈现出每个中国每个城市的店铺数量
代码如下:
import pandas as pd
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\\Windows\\Fonts\\simsun.ttc")
# 读数据
df = pd.read_csv("../CSV/archive_04/directory.csv")
# 使用matplotlib呈现出每个中国每个城市的店铺数量
# 数据清洗
# print(df.info())
# 
练习案例:
现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
-
不同年份书的数量
-
不同年份书的平均评分情况
代码如下:
import pandas as pd
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
from tool import set_display_all_info
# 现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
# 1. 不同年份书的数量
# 2. 不同年份书的平均评分情况
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\\Windows\\Fonts\\simsun.ttc")
# 读数据
df = pd.read_csv("../CSV/archive_05/books.csv")
# print(df.info())
# 5.8 Pandas时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系。而且在pandas中处理时间序列是非常简单的。
pd.date_range(start=None, end=None, periods=None, freq='D'):生成一段时间范围
-
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
-
start和periods(个数)以及freq配合能够生成从start开始的频率为freq的periods个时间索引
freq的缩写有很多,如图:

代码示例如下:
import pandas as pd
# 使用pd.data_range()生成时间序列
# 使用start和end与freq配合生成
print(pd.date_range(start="20171230", end="20180131", freq="D"))
# DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
# '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
# '2018-01-07', '2018-01-08', '2018-01-09', '2018-01-10',
# '2018-01-11', '2018-01-12', '2018-01-13', '2018-01-14',
# '2018-01-15', '2018-01-16', '2018-01-17', '2018-01-18',
# '2018-01-19', '2018-01-20', '2018-01-21', '2018-01-22',
# '2018-01-23', '2018-01-24', '2018-01-25', '2018-01-26',
# '2018-01-27', '2018-01-28', '2018-01-29', '2018-01-30',
# '2018-01-31'],
# dtype='datetime64[ns]', freq='D')
print(pd.date_range(start="20171230", end="20180131", freq="10D"))
# DatetimeIndex(['2017-12-30', '2018-01-09', '2018-01-19', '2018-01-29'], dtype='datetime64[ns]', freq='10D')
# 使用start和period和freq配合生成
print(pd.date_range(start="20171230", periods=10, freq="D"))
# DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
# '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
# '2018-01-07', '2018-01-08'],
# dtype='datetime64[ns]', freq='D')
我们可以在DataFrame中使用时间序列:
# 在DataFrame中使用时间序列作为索引
index = pd.date_range(start="20170101", periods=10)
df = pd.DataFrame(np.random.randint(0, 10, (10, 1)), index=index)
print(df)
# 0
# 2017-01-01 9
# 2017-01-02 7
# 2017-01-03 2
# 2017-01-04 5
# 2017-01-05 5
# 2017-01-06 1
# 2017-01-07 0
# 2017-01-08 2
# 2017-01-09 6
# 2017-01-10 8
# 在911数据案例中,我们可以使用Pandas提供的方法将时间字符串转换为时间序列
# format 参数大部分情况下可以不用写 但是对于pandas无法格式化的时间字符串 我们可以使用该参数 比如包含中文的情况下
df["timeStamp"] = pd.to_datetime(df["timeStamp"], format="%Y-%m")
print(df["timeStamp"])
当我们的时间序列应用于DataFrame中后,就可以完成重采样的操作了。
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。
pandas提供了一个resample的方法来帮助我们实现频率转化,如果我们的DataFrame索引是时间序列的话就可以调用resample方法,代码示例如下:
# 在911数据案例中,我们可以使用Pandas提供的方法将时间字符串转换为时间序列
# format 参数大部分情况下可以不用写 但是对于pandas无法格式化的时间字符串 我们可以使用该参数 比如包含中文的情况下
df["timeStamp"] = pd.to_datetime(df["timeStamp"], format="%Y-%m")
# print(df["timeStamp"])
# 我们将时间序列设置为新的索引
df.set_index("timeStamp", inplace=True)
# print(df.head(5))
# 通过降采样来统计出不同月份的电话次数
count_by_month = df.resample("M")["lat"].count()
print(count_by_month.head(5))
# timeStamp
# 2015-12-31 7916
# 2016-01-31 13096
# 2016-02-29 11396
# 2016-03-31 11059
# 2016-04-30 11287
# Freq: M, Name: lat, dtype: int64
# 注意一个小功能
# 这里观察一下我们取到的索引的数据类型
x = count_by_month.index
for i in x:
print(i)
print(type(i))
# 2020 - 07 - 31 00: 00:00
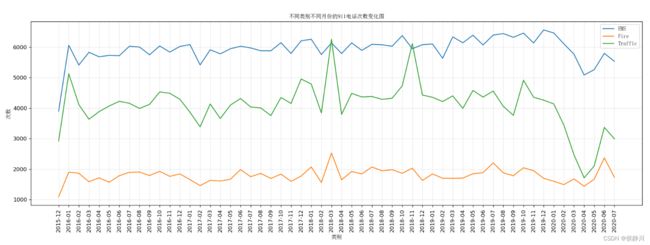
# 关于911案例的最后一个问题:统计出911数据中不同月份不同类型的电话的次数的变化情况。
这个问题的解决代码如下,实际上整合了上面的多种方法:
import pandas as pd
import numpy as np
from matplotlib import font_manager
from matplotlib import pyplot as plt
from tool import set_display_all_info
# 问题3:统计出911数据中不同月份不同类型的电话的次数的变化情况
# 配置中文字体
my_font = font_manager.FontProperties(fname="C:\\Windows\\Fonts\\simsun.ttc")
# 设置控制台信息全部显示
set_display_all_info()
# 读数据
df = pd.read_csv("../CSV/archive_06/911.csv")
# 这里注意一个点 即cast_df合并到df中 必须在更换索引之前进行
# 因为行索引不同cast_df的索引是0123... 而df的索引是时间戳 在合并赋值的时候只会赋值为NaN
# 将每个911的cast从title中提取出来并组成新的cast_df列合并到df中
cast_list_all = [i[0] for i in df["title"].str.split(": ").tolist()]
cast_df = pd.DataFrame(np.array(cast_list_all).reshape((len(cast_list_all), 1)), columns=["cast"])
df["cast"] = cast_df
# 将TimeStamp设置为pandas中的时间序列并将其设置为df的索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp", inplace=True)
# 对df按照cast进行分类得到分组
grouped = df.groupby("cast")
print(grouped)
# 设置图片格式
plt.figure(figsize=(20, 8), dpi=120)
# 开始绘图
for group_name, group_data in grouped:
# 对不同的分类都进行绘图
count_by_month = group_data.resample("M")["lat"].count()
# 画图
_x = count_by_month.index
_y = count_by_month.values
# 因为这里的时间序列不是我们想要的格式 所以将时间序列重新进行格式化
_x = [i.strftime("%Y-%m") for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
# 设置x轴刻度
plt.xticks(range(len(_x)), _x, rotation = 90)
# 添加网格
plt.grid(alpha=0.3)
# 添加图例
plt.legend(prop=my_font, loc=0)
# 添加图像描述
plt.xlabel("类别", fontproperties=my_font)
plt.ylabel("次数", fontproperties=my_font)
plt.title("不同类别不同月份的911电话次数变化图", fontproperties=my_font)
# 调整间距以防止勾号标签被剪切导致x轴显示不全或x轴描述显示不全
plt.subplots_adjust(bottom=0.3)
# 展示图片
plt.show()
生成的图片如下:
接下来现在我们有北上广、深圳、和沈阳5个城市空气质量数据,请绘制出5个城市的PM2.5随时间的变化情况但是观察这组数据中的时间结构,并不是字符串,而是年月日分开来进行记录的,这时候我们使用一种新的方法来将其转换为我们熟悉的时间戳类型。
之前所学习的DatetimeIndex可以理解为时间戳,那么现在我们要学习的PeriodIndex可以理解为时间段。
接下来我们展示使用PeriodIndex来作为索引的代码:
import pandas as pd
import numpy as np
from tool import set_display_all_info
# 设置控制台信息全部显示
set_display_all_info()
df = pd.read_csv("../CSV/archive_07/BeijingPM20100101_20151231.csv")
# print(df.info())
# 到此为止就结束了所有Python数据分析的课程,显然这门课程只是帮助我们快速的入门Matplotlib、NumPy和Pandas,里面有好多不常用的细节没有讲,因为可能在以后不常用到。Matplotlib、NumPy和Pandas只是工具而已,我们快速入门只是为了在我们以后碰到不会的功能后,能快速的看懂它的用法即可。