PgSQL内核特性 - push-based pipeline 执行引擎
PgSQL内核特性 - push-based pipeline 执行引擎
数据库的SQL执行引擎负责处理和执行SQL请求。通常情况下,查询优化器会输出物理执行计划,一般由一系列的算子组成。当前,有两种算子流水线构建方式:1)需求驱动的流水线,由算子不断从下级算子拉取数据;2)数据驱动的流水线,由算子将每个数据推送给父算子。
论文《Push versus pull-based loop fusion in query engines》说明了push和pull执行引擎的区别:

Pull流水线基于经典的火山迭代器模型,将每个操作抽象成一个算子。整个SQL语句构成一个算子树,从树顶递归调用next接口,向下层算子请求数据,直到查询计划树的叶子节点。优缺点:
1)以行为单位处理数据,每一行数据的处理都会调用next接口(当然也可以基于pull模型改造成以batch为单位处理数据)
2)以行为单位处理,会导致CPU缓存使用效率低下
3)火山模型接口看起来干净且易懂
论文《Efficiently compiling efficient query plans for modern hardware》提出的Push模型采用Pipeline来组合算子,自底而上Push调度。Pipeline的目的:1) 降低计算节点的任务调度代价;2) 提升 CPU 利用率;3)充分利用多核计算能力,提升查询性能、自动设置并行度、消除人为设置并行度的不准确性。
1、PgSQL的pipeline执行引擎
GSoC 2017中有个改造pipeline的项目,基本思想是遍历执行计划树,找到叶子节点,从叶子节点开始获取数据,然后推送给各个父节点。
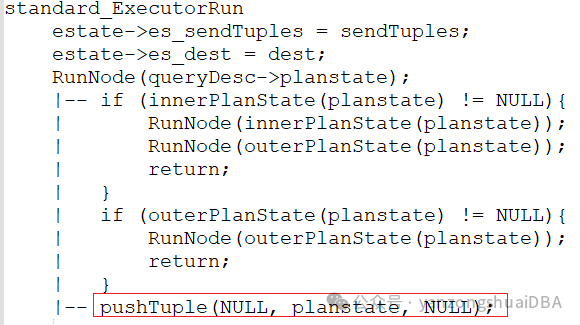
执行器中,使用RunNode函数递归调用,得到叶子节点:先遍历右节点,然后再遍历左节点;当然若没有右节点,则直接遍历左节点;当没有左右子节点时,就到了叶子节点,那么通过pushTuple来推送数据。

pushTuple根据父节点类型调用各自推送函数,将数据推送给父节点,比如上面流程:当父节点是LimitState时,调用pushTupleToLimit进行推送。
我们看下SeqScan:其实就是从存储引擎获取数据,进行过滤和投影,然后根据父节点类型,推送给父节点。
pushTupleToSeqScan(SeqScanState *node)
heappushtups(...,node->ss.ps.parent,node)
|-- get a tuple in the page
SeqPushHeapTuple(HeapTuple tuple, PlanState *node,SeqScanState *pusher)
|-- slot = SeqStoreTuple(pusher, tuple);
|-- ExecQual && ExecProject
|-- return pushTuple(slot, node, (PlanState *) pusher);
|-- if (!node){//pusher top level node, send to dest
return SendReadyTuple(slot, pusher);
}对于hash join来说,需要先构建hash表,然后外表数据从hash表中进行探测;pipeline引擎中怎么推送完成hash join呢?
从RunNode函数中可以也可以看到,他是先从内表分支开始推送数据,推送给Hash节点构建hash表,然后推送给父节点。pushTuple函数中,当hash join的右分支推送上来时,pushTupleToHashJoinFromInner函数仅获取hash表,并不继续向上推送;而是HashJoin的左子分支推送上来的数据进入pushTupleToHashJoinFromOuter,进行hash探测,找到符合条件的数据,并向上层父节点推送join结果:

可以得知,该改造并没有充分利用各个叶子分支并行,未来可以向整个方向进行优化。
3、效果
TPCH的 q1, q3, q4, q5,q10, q12 and q14:

4、总结
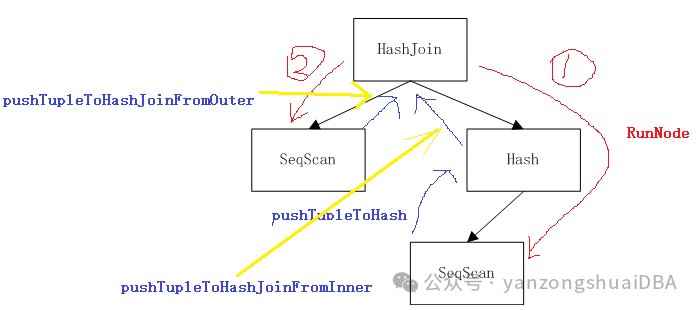
1)红色线:找叶子节点递归方向;蓝色线:数据推送方向
2)物理执行计划被执行器ExecInitNode初始化时,参数带入父节点,从而将执行计划构建为子节点-->父节点的关系
3)通过RunNode递归调用,找到叶子节点SeqScan。获取数据后推送给父节点Hash
4)Hash节点构建hash表,推送给父节点HashJoin。因为数据处于HashJoin的右分支,所以通过pushTupleToHashJoinFromInner仅获取hash表,到此该分支推送执行就结束了
5)左分支SeqScan获取数据后推送给HashTable,HashJoin由pushTupleToHashJoinFromOuter执行,进行hash探测并将join的结果推送给上层父节点,若无上层父节点,则推送给用户,至此push-based pipeline执行结束。
6)该改造,并没有将pipeline依据叶子节点进行并行执行,仍旧有提升空间;当然,仅作为一个初次尝试,验证push-based pipeline执行。和clickhouse、starrocks等相比,仍旧有很大不足。
5、参考
https://postgrespro.com/list/thread-id/2309959
https://wiki.postgresql.org/wiki/GSoC_2017#Implementing_push-based_query_executor