django 过往后端搭建笔记整理
目录
-
- 一、创建项目和应用
-
-
- 1 项目创建
- 2 应用创建
- 3 注册应用
- 4 配置mysql数据库
-
- 创建数据库
- 配置redis数据库
-
- 将时区设置为本地的
- 使用redis
- redis本地服务端 和客户端使用(windows)
- 日志输出器配置
- 5 配置模板文件
- 6 前后端分离开发配置跨域解决方案
-
- 配置跨域白名单
-
- 二、 模型设计
-
-
- 0.模型字段类型和约束
-
- 自定义用户模型类
- 注册用户模型类
- 1.定义常规模型类
-
- ①.设计图书类(model.py)
- ②.设计英雄类
- ③.迁移
- ④.数据操作
- ⑤.定义元选项
-
- 三 、后台管理
-
-
-
- 1.管理界面本地化
- 2.创建管理员
- 3.注册模型类
- 4.自定义管理页面的 列
-
- 4.1 自由设置列的内容
- 4.2 关联对象
- 4.3 自定义列名
- 5.自定义管理页面的 编辑页
-
- 5.1 展示顺序和字段名
- 5.2 分组显示
- 5.3 关联显示
- 重写管理模板
-
-
- 四、视图
-
-
-
- 1.定义视图
- 2.配置URLconf
- 3.URl参数配置
- 4.HttpReqeust对象
-
- GET属性
- POST属性
- 5.HttpResponse对象
- 6.cookie
-
- 设置Cookie
- 读取Cookie
- 7.Session
-
- 存储方式
- 对象及方法
- 示例
- 使用Redis存储Session
- 8.rest_framwork视图函数的书写
- 9.rest_framwork自定义路由的书写
-
-
- 五、模板
-
-
- 1 模板配置
- 2 定义模板
- 3 模板语法
- 4.过滤器
-
-
- 自定义过滤器
-
- 5模板继承
- 6 视图调用模板简写
- 7.反向解析
- 8.CSRF
-
- 六、查询
-
-
- 1.条件查询
-
- ①条件运算符
- ②聚合函数
- 2.查询集
- 3.关联查询
-
- 其他
-
-
- 1.静态文件
- 2.中间件
-
- 中间件定义
- 总的中间件举例django2.0+
- 3.celery
- 4.django项目终端常用命令
- 5
-
一、创建项目和应用
1 项目创建
用国内镜像安装包的时候会快一些
pip install django -i https://pypi.douban.com/simple
resful 风格的前后端分离包
pip install djangorestframework
django-admin startproject 项目名称
需要分支管理的话,可以创建本地新分支然后推到远程git仓库合并。 不需要的话忽略git操作。
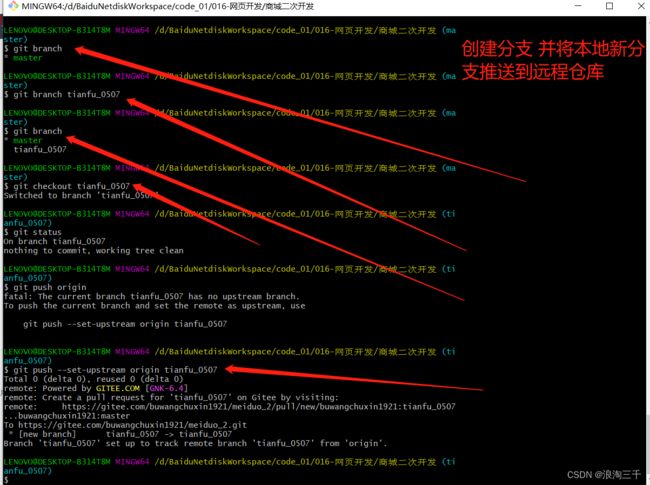
2 应用创建
进入到项目目录 然后创建应用(创建错了 就直接删除即可)
| 项目创建(这步可以做) | 应用创建(默认路径 可以自己调 紧接下面有讲) |
|---|---|
| django-admin startproject test1 | python manage.py startapp booktest |
如果应用较多的话用下面的方式创建并方便管理
① 手动在内层项目文件夹下创建 apps 文件夹
在settings环境设置文件里 添加下面两行代码添加 环境变量 以后应用就都从apps里找
import sys
sys.path.insert(0, os.path.join(BASE_DIR, 'apps'))
python …/…/manage.py startapp user

3 注册应用
(直接写应用名也可)不必参照上面的图片路径 本文档是多次项目合成的 但不影响逻辑
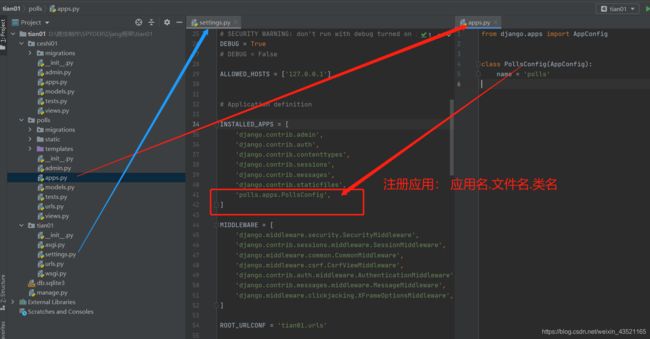
4 配置mysql数据库
修改为使用MySQL数据库,代码如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'test2', #数据库真实名字,
'USER': 'root', #数据库登录用户名
'PASSWORD': 'mysql', #数据库登录密码
'HOST': 'localhost', #数据库所在主机
'PORT': '3306', #数据库端口
}
}
#注意:数据库test2 Django框架不会自动生成,需要我们自己进入mysql数据库去创建。
创建数据库
#下面是手动创建数据库,打开新终端,在命令行登录mysql,创建数据库test2或meiduo2_db 自己定义数据库名字和Django中一致即可。
#注意:设置字符集为utf8
create database meiduo2_db charset=utf8;
# 为本项目创建数据库用户(不再使用root账户)
create user tianfu_meiduo identified by 'password'
grant all on meiduo2_db.* to 'tianfu_meiduo'@'%';
flush privileges;
说明:
第一句:创建用户账号 tianfu_meiduo, 密码password (由identified by 指明)
第二句:授权meiduo2_db数据库下的所有表(meiduo2_db.*)的所有权限(all)给用户tianfu_meiduo在以任何ip访问数据库的时候(‘tianfu_meiduo’@‘%’)
第三句:刷新生效用户权限

将引擎改为mysql,提供连接的主机HOST、端口PORT、数据库名NAME、用户名USER、密码PASSWORD。
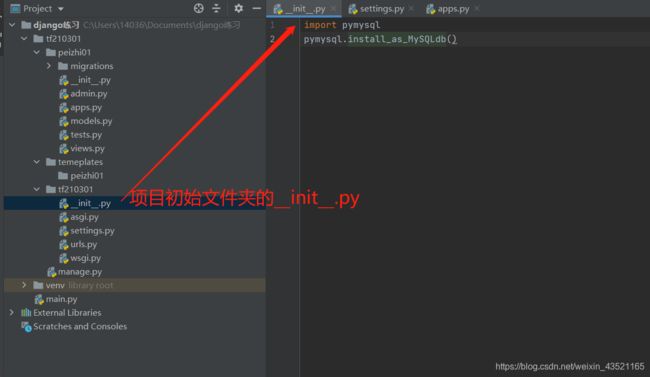
把数据库切换成了mysql,需要安装pymysql模块之后,Django框架才可以操作mysql数据库。安装命令如下:
pip install pymysql
# 安装成功之后,在test2/_init_.py文件中加上如下代码:
import pymysql
pymysql.install_as_MySQLdb()
如果之后迁移时候报mysqlclient版本较低 可以用如下语句升级(主要看django版本的新旧)
pip install --upgrade mysqlclient
配置redis数据库
将主要用于缓存作业,安装命令 :
pip install django_redis
# redis 配置 使用了 0 和 1 库 想用别的可以再配置
CACHES = {
"default": { # 缓存省市区数据
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
"session": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
"verify_codes": { # 验证码
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/2",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
SESSION_CACHE_ALIAS = "session"
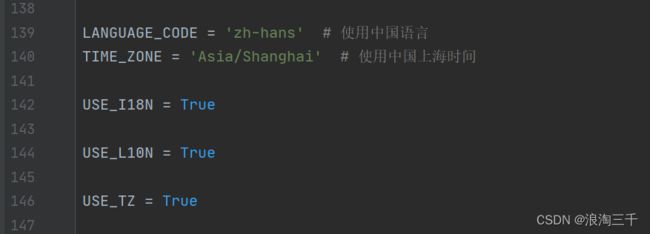
将时区设置为本地的
打开test1/settings.py文件,找到语言编码、时区的设置项,将内容改为如下:
LANGUAGE_CODE = 'zh-hans' # 使用中国语言
TIME_ZONE = 'Asia/Shanghai' # 使用中国上海时间
使用redis

此处注意下参数 email 名字即可
from django.urls import path,re_path
from . import views
urlpatterns = [
# path(r'^sms_code/(?p1)', views.SMSCodeView.as_view()),
# re_path('sms_code/(\d+)/', views.SMSCodeView.as_view()),
re_path(r'email/(?P[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+))/' , views.EmailCodeView.as_view())
]
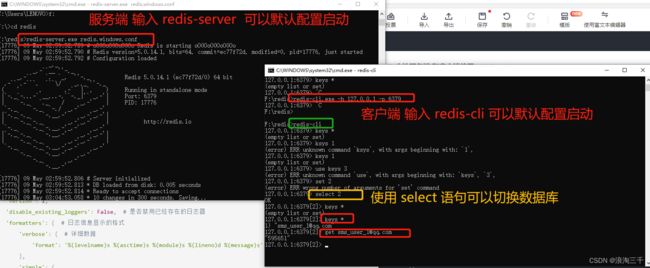
使用之前需要先启动redis 服务 redis-server
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
import random
from django_redis import get_redis_connection
from rest_framework import status
import logging
from celery_tasks.ce_email.tasks import send_emails
# Create your views here.
logger = logging.getLogger('django')
class EmailCodeView(APIView):
# 短信验证码 参数名需要和传来的一致
def get(self,request,mobile=0):
print("=========传进来号码参数是:",mobile)
# 1 生成验证码
sms_code = random.randint(100000,999999)
logger.info("验证码是:",sms_code)
# 2 创建并连接到redis的对象 verify_codes 是在配置文件中设置的缓存库名 默认2号
redis_conn = get_redis_connection('verify_codes')
# 2.1 创建redis 管道 当设置命令较多时候,可以通过管道一次性执行而不用每次单词链接执行 增加性能
redis_pipeline = redis_conn.pipeline()
# 3 配置60秒内不允许重发验证码
# 先查询这个用户的验证码有没有在redis里 如果在说明发过了则不再发
get_vertify_code = redis_conn.get(f'sms_{mobile}')
if get_vertify_code: # 如果获取的值不为空 说明限定时间内 发过短信则不再发
logger.info("获取到的值是:",get_vertify_code)
return Response({"message": "邮件已发送过了"},status=status.HTTP_400_BAD_REQUEST)
else: # 如果没取到值 则发送
# 设置键值及过期时间,以秒为单位 SETEX key seconds value
# 建立管道前写法
# redis_conn.setex(f'sms_{mobile}',60,sms_code)
# 建立管道后写法 过期时间15秒
redis_pipeline.setex(f'sms_{mobile}',15,sms_code)
redis_pipeline.execute()
# 触发异步任务 需要使用 delay 来调用
send_emails.delay(mobile,str(sms_code))
# send_emails.delay()
# send_emails()
logger.info("mobile,sms_code", mobile, sms_code)
# 发送邮件
# WangYiEmail.send_email(to_addrs=mobile, text=f"亲爱的学员,验证码是!{sms_code}")
return Response({"message": "邮件已发送"},status=status.HTTP_200_OK)
redis本地服务端 和客户端使用(windows)
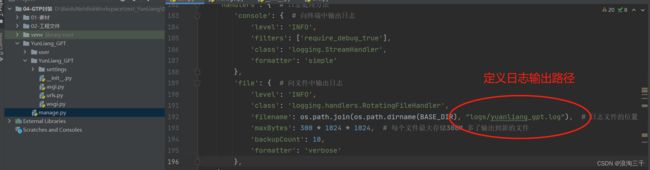
日志输出器配置
注意在外层项目直接目录下创建 logs 文件夹然后 把日志文件夹在 gitignore 里屏蔽掉
# 日志配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False, # 是否禁用已经存在的日志器
'formatters': { # 日志信息显示的格式
'verbose': { # 详细数据
'format': '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s'
},
'simple': {
'format': '%(levelname)s %(module)s %(lineno)d %(message)s'
},
},
'filters': { # 对日志进行过滤
'require_debug_true': { # django在debug模式下才输出日志
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': { # 日志处理方法
'console': { # 向终端中输出日志
'level': 'INFO',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'file': { # 向文件中输出日志
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(os.path.dirname(BASE_DIR), "logs/meiduo.log"), # 日志文件的位置
'maxBytes': 300 * 1024 * 1024, # 每个文件最大存储300M 多了输出到新的文件
'backupCount': 10,
'formatter': 'verbose'
},
},
'loggers': { # 日志器
'django': { # 定义了一个名为django的日志器
'handlers': ['console', 'file'], # 可以同时向终端与文件中输出日志
'propagate': True, # 是否继续传递日志信息
'level': 'INFO', # 日志器接收的最低日志级别
},
}
}
可以修改自己的路径
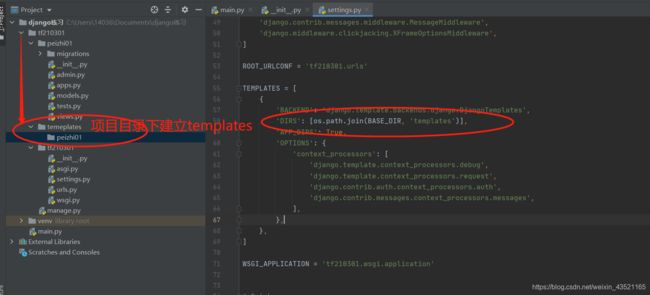
5 配置模板文件
DIRS定义一个目录列表,模板引擎按列表顺序搜索这些目录以查找模板文件,通常是在项目的根目录下创建templates目录。
Django处理模板分为两个阶段:
1.加载:根据给定的路径找到模板文件,编译后放在内存中。
2.渲染:使用上下文数据对模板插值并返回生成的字符串。
为了减少开发人员重复编写加载、渲染的代码,Django提供了简写函数render,用于调用模板。
然后再在templates里面创建应用对应的文件夹,之后再存模板文件
所填代码为:
os.path.join(BASE_DIR, 'templates')
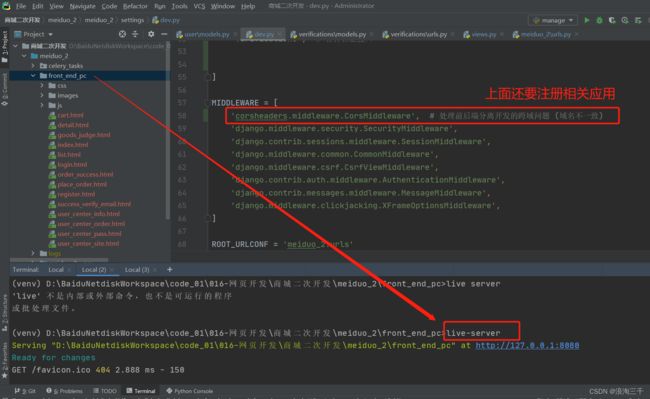
6 前后端分离开发配置跨域解决方案
(这样前端的网址就可以是 www.xxxx等正式定义的域名了 本段后文 还有设置白名单的操作)
如果前后端分离开发 想运行前端界面 可以安装 live-server 在此之前如果你本地有node 环境则可直接用 没有的请安装一下 node.js
npm install -g live-server
然后在前端代码总文件夹中 终端运行 liver-server 即可自动启动网页
live-server
live-server运行在8080端口下,可以通过127.0.0.1:8080 来访问静态页面。
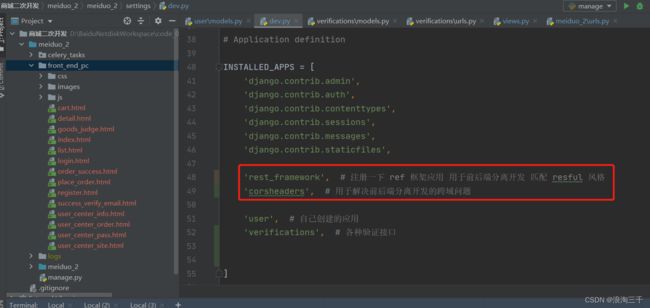
配置跨域白名单
需要安装如下库 然后记得注册到应用中
pip install django-cors-headers
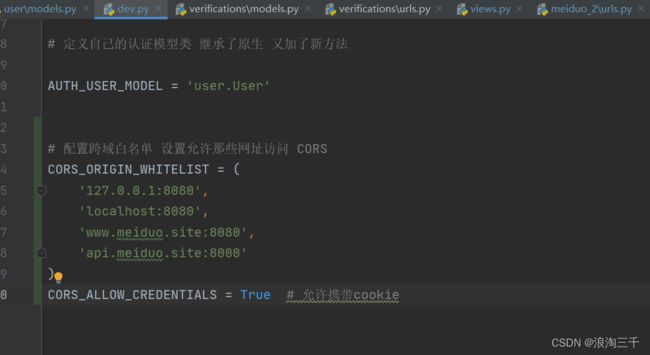
# 配置跨域白名单 设置允许那些网址访问 CORS 记得加协议 http...
CORS_ORIGIN_WHITELIST = (
'https://127.0.0.1:8080',
'https://localhost:8080',
'https://www.meiduo.site:8080',
'https://api.meiduo.site:8000'
)
CORS_ALLOW_CREDENTIALS = True # 允许携带cookie
记得按下图注册
'rest_framework', # 注册一下 ref 框架应用 用于前后端分离开发 匹配 resful 风格
'corsheaders', # 用于解决前后端分离开发的跨域问题
'corsheaders.middleware.CorsMiddleware', # 处理前后端分离开发的跨域问题 (域名不一致)

二、 模型设计
使用django进行数据库开发的步骤如下:
- 1.在models.py中定义模型类
- 2.迁移
- 3.通过类和对象完成数据增删改查操作
0.模型字段类型和约束
使用时需要引入django.db.models包,字段类型如下:
| 字段类型 | 功能解释 |
|---|---|
| AutoField | 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性。 |
| BooleanField | 布尔字段,值为True或False。 |
| NullBooleanField | 支持Null、True、False三种值。 |
| CharField(max_length=字符长度) | 字符串。参数max_length表示最大字符个数。 |
| TextField | 大文本字段,一般超过4000个字符时使用。 |
| IntegerField | 整数。 |
| DecimalField(max_digits=None, decimal_places=None) | 十进制浮点数。参数max_digits表示总位数。参数decimal_places表示小数位数。 |
| FloatField | 浮点数。 |
| DateField[auto_now=False, auto_now_add=False]) | 日期。参数auto_now表示每次保存对象时,自动设置该字段为当时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。 |
| TimeField | 时间,参数同DateField。 |
| DateTimeField | 日期时间,参数同DateField。 |
| FileField | 上传文件字段。 |
| ImageField | models.ImageField(upload_to=‘booktest/’),继承于FileField,对上传的内容进行校验,确保是有效的图片。 |
| ForeignKey | 一对多,将字段定义在多的一端中。 |
| ManyToManyField | 多对多,将字段定义在任意一端中。 |
| OneToOneField | 一对一,将字段定义在任意一端中。 |
hbook = models.ForeignKey('BookInfo')#英雄与图书表的关系为一对多,所以属性定义在英雄模型类中
ntype = models.ManyToManyField('TypeInfo') #通过ManyToManyField建立TypeInfo类和NewsInfo类之间多对多的关系
通过选项实现对字段的约束,选项如下:
| 参数选项 | 功能解释 |
|---|---|
| null | 如果为True,表示允许为空,默认值是False。 |
| blank | 综合演示如果为True,则该字段允许为空白,默认值是False。对比:null是数据库范畴的概念,blank是表单验证范畴的。 |
| db_column | 字段的名称,如果未指定,则使用属性的名称。 |
| db_index | 若值为True, 则在表中会为此字段创建索引,默认值是False。 |
| default | 默认值。 |
| primary_key | 若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。 |
| unique | 如果为True, 这个字段在表中必须有唯一值,默认值是False。 |
自定义用户模型类
如果原生的认证模型字段不够用,则可以改写用户认证模型,改写后参照下方第二图,修改配置文件的配置项。

from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
class User(AbstractUser):
"""用户模型类 基本信息django自带的父类已经自定义了 这里我们可以补充些别的
自带的 id 、username、password(密文)、first_name、last_name 、email、is_staff、is_active、 date_joined """
# 下面可以自定义模型字段
phone_number = models.CharField(max_length=11,unique=True,verbose_name='手机号码')
gender = models.BooleanField(default=None,null=True)
age = models.IntegerField(max_length=3,default=None)
birth_data = models.DateField(default='1970-1-1')
class Meta:
db_table = "tb_users"
verbose_name = "用户"
verbose_name_plural = verbose_name
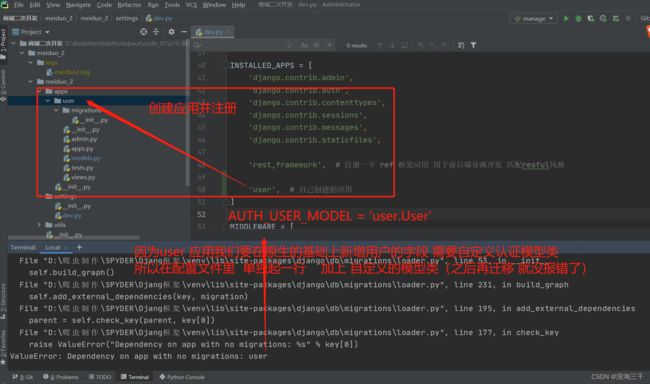
注册用户模型类
因为是用户模型 且是改写自原生的认证模型 所以要做如下配置
# 在settings配置文件里 定义自己的认证模型类 继承了原生 又加了新方法
AUTH_USER_MODEL = 'user.User'
注册
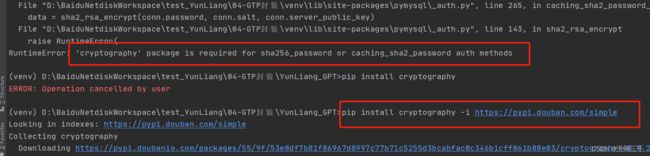
加密算法的需要,我们还要安装 cryptography 用于sha2加密
pip install cryptography -i https://pypi.douban.com/simple
迁移
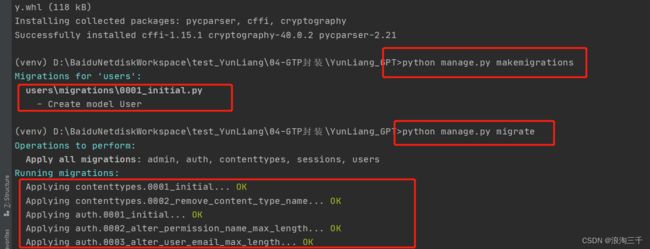
紧接着在下文看
综合演示
修改booktest/models.py中的模型类,代码如下:
from django.db import models
#定义图书模型类BookInfo
class BookInfo(models.Model):
#btitle = models.CharField(max_length=20)#图书名称
btitle = models.CharField(max_length=20, db_column='title')#通过db_column指定btitle对应表格中字段的名字为title
bpub_date = models.DateField()#发布日期
bread = models.IntegerField(default=0)#阅读量
bcomment = models.IntegerField(default=0)#评论量
isDelete = models.BooleanField(default=False)#逻辑删除
#定义英雄模型类HeroInfo
class HeroInfo(models.Model):
hname = models.CharField(max_length=20)#英雄姓名
hgender = models.BooleanField(default=True)#英雄性别
isDelete = models.BooleanField(default=False)#逻辑删除
#hcomment = models.CharField(max_length=200)#英雄描述信息
hcomment = models.CharField(max_length=200, null=True, blank=False) #hcomment对应的数据库中的字段可以为空,但通过后台管理页面添加英雄信息时hcomment对应的输入框不能为空
hbook = models.ForeignKey('BookInfo')#英雄与图书表的关系为一对多,所以属性定义在英雄模型类中
1.定义常规模型类
模型类定义在models.py文件中,继承自models.Model类。
定义方式: 属性=models.字段类型(选项)
说明:不需要定义主键列,在生成时会自动添加,并且值为自动增长。
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
注意:pk是主键的别名,若主键名为id2,那么pk是id2的别名。
①.设计图书类(model.py)
图书类:
- 类名:BookInfo
- 图书名称:btitle
- 图书发布日期:bpub_date
根据设计,在models.py中定义模型类如下:
from django.db import models
class BookInfo(models.Model):
btitle = models.CharField(max_length=20)
bpub_date = models.DateField()
②.设计英雄类
英雄类:
- 类名:HeroInfo
- 英雄姓名:hname
- 英雄性别:hgender
- 英雄简介:hcomment
- 英雄所属图书:hbook
图书-英雄的关系为一对多
打开booktest/models.py,定义英雄类代码如下:
class HeroInfo(models.Model):
hname = models.CharField(max_length=20)
hgender = models.BooleanField()
hcomment = models.CharField(max_length=100)
hbook = models.ForeignKey('BookInfo')
这里要说明的是,BookInfo类和HeroInfo类之间具有一对多的关系,这个一对多的关系应该定义在多的那个类,也就是HeroInfo类中。
总体代码如下:
from django.db import models
#定义图书模型类BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length=20)#图书名称
bpub_date = models.DateField()#发布日期
bread = models.IntegerField(default=0)#阅读量
bcomment = models.IntegerField(default=0)#评论量
isDelete = models.BooleanField(default=False)#逻辑删除
#定义英雄模型类HeroInfo
class HeroInfo(models.Model):
hname = models.CharField(max_length=20)#英雄姓名
hgender = models.BooleanField(default=True)#英雄性别
isDelete = models.BooleanField(default=False)#逻辑删除
hcomment = models.CharField(max_length=200)#英雄描述信息
hbook = models.ForeignKey('BookInfo')#英雄与图书表的关系为一对多,所以属性定义在英雄模型类中
③.迁移
迁移由两步完成:
- 1.生成迁移文件:根据模型类生成创建表的迁移文件。
- 2.执行迁移:根据第一步生成的迁移文件在数据库中创建表。
- 3.当执行迁移命令后,Django框架会读取迁移文件自动帮我们在数据库中生成对应的表格。
| 生成迁移文件命令 | 执行迁移命令 |
|---|---|
| python manage.py makemigrations | python manage.py migrate |
如果自己手动删库后又执行迁移 可能会探测不到迁移的应用 No changes detected可以手动指定迁移对象。 verifications是我的应用名
| 生成迁移文件命令 | 执行迁移命令 |
|---|---|
| python manage.py makemigrations --empty verifications | python manage.py migrate |
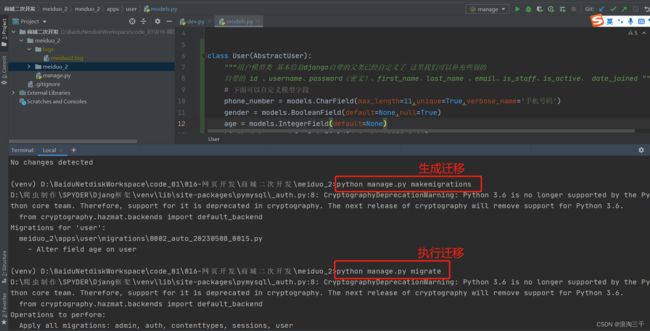
④.数据操作
完成数据表的迁移之后,下面就可以通过进入项目的shell,进行简单的API操作。如果需要退出项目,可以使用ctrl+d快捷键或输入quit()。
| 功能 | 语句 |
|---|---|
| 进入项目shell的命令 | python manage.py shell |
from booktest.models import BookInfo,HeroInfo
BookInfo.objects.all()
#新建图书对象
b=BookInfo()
b.btitle="射雕英雄传"
from datetime import date
b.bpub_date=date(1991,1,31)
b.save()
#再次查询所有图书信息:
BookInfo.objects.all()
#查找图书信息并查看值:
b=BookInfo.objects.get(id=1)
b
b.id
b.btitle
b.bpub_date
#修改图书信息
b.bpub_date=date(2017,1,1)
b.save()
b.bpub_date
#创建一个HeroInfo对象
h=HeroInfo()
h.hname='a1'
h.hgender=False
h.hcomment='he is a boy'
h.hbook=b
h.save()
#图书与英雄是一对多的关系,django中提供了关联的操作方式。
#获得关联集合:返回当前book对象的所有hero。
b.heroinfo_set.all()
⑤.定义元选项
元选项
在模型类中定义类Meta,用于设置元信息,如使用db_table自定义表的名字。
数据表的默认名称为:
例:
booktest_bookinfo
例:指定BookInfo模型类生成的数据表名为bookinfo。
在BookInfo模型类中添加如下内容,代码如下:
#定义图书模型类BookInfo
class BookInfo(models.Model):
...
#定义元选项
class Meta:
db_table='bookinfo' #指定BookInfo生成的数据表名为bookinfo
三 、后台管理
1.管理界面本地化
本地化是将显示的语言、时间等使用本地的习惯,这里的本地化就是进行中国化,中国大陆地区使用简体中文,时区使用亚洲/上海时区,注意这里不使用北京时区表示。
打开test1/settings.py文件,找到语言编码、时区的设置项,将内容改为如下:
LANGUAGE_CODE = 'zh-hans' # 使用中国语言
TIME_ZONE = 'Asia/Shanghai' # 使用中国上海时间
2.创建管理员
创建管理员的命令如下,按提示输入用户名、邮箱、密码。
python manage.py createsuperuser
3.注册模型类
启动本地服务器
python manage.py runserver
然后登录后台管理后,默认没有我们创建的应用中定义的模型类,需要在自己应用中的admin.py文件中注册,才可以在后台管理中看到,并进行增删改查操作。
打开booktest/admin.py文件,编写如下代码:
from django.contrib import admin
from booktest.models import BookInfo,HeroInfo
admin.site.register(BookInfo)
admin.site.register(HeroInfo)
到浏览器中刷新页面,可以看到模型类BookInfo和HeroInfo的管理了。
4.自定义管理页面的 列
在列表页只显示出了BookInfo object,对象的其它属性并没有列出来,查看非常不方便。 Django提供了自定义管理页面的功能,比如列表页要显示哪些值。
打开booktest/admin.py文件,自定义类,继承自admin.ModelAdmin类。
from django.contrib import admin
from booktest.models import BookInfo,HeroInfo
class BookInfoAdmin(admin.ModelAdmin):
list_display = ['id', 'btitle', 'bpub_date']
class HeroInfoAdmin(admin.ModelAdmin):
list_display = ['id', 'hname','hgender','hcomment']
admin.site.register(BookInfo,BookInfoAdmin)
admin.site.register(HeroInfo,HeroInfoAdmin)
| 属性 | 功能 |
|---|---|
| list_display=[模型字段] | 表示要显示哪些属性 |
| list_per_page=100 | 每页中显示多少条数据,默认为每页显示100条数据 |
| actions_on_top=True | 顶部显示的属性,设置为True在顶部显示,设置为False不在顶部显示,默认为True |
| actions_on_bottom=False | 底部显示的属性,设置为True在底部显示,设置为False不在底部显示,默认为False |
| list_filter=[‘atitle’] | 会将对应字段的值列出来,用于快速过滤。一般用于有重复值的字段。 |
| search_fields=[] | 搜索框,列表类型,表示在这些字段上进行搜索。 |
| fields=[] | 显示具体编辑页的字段顺序,按索引显示 |
| fieldset=() | 分组显示 下面5.2有用法,fields与fieldsets两者选一使用。 |
4.1 自由设置列的内容
将方法作为列
列可以是模型字段,还可以是模型方法,要求方法有返回值。
1)打开booktest/models.py文件,修改AreaInfo类如下:
class AreaInfo(models.Model):
...
def title(self):
return self.atitle
2)打开booktest/admin.py文件,修改AreaAdmin类如下:
class AreaAdmin(admin.ModelAdmin):
...
list_display = ['id','atitle','title']
列排序:方法列是不能排序的,如果需要排序需要为方法指定排序依据。
列名:列标题默认为属性或方法的名称,可以通过属性设置。需要先将模型字段封装成方法,再对方法使用这个属性,模型字段不能直接使用这个属性。
admin_order_field=模型类字段
short_description=‘列标题’
1)打开booktest/models.py文件,修改AreaInfo类如下:
class AreaInfo(models.Model):
...
def title(self):
return self.atitle
title.admin_order_field='atitle'
title.short_description='区域名称' # 定义方法的列名,默认是方法名
4.2 关联对象
无法直接访问关联对象的属性或方法,可以在模型类中封装方法,访问关联对象的成员。
1)打开booktest/models.py文件,修改AreaInfo类如下:
class AreaInfo(models.Model):
...
def parent(self):
if self.aParent is None:
return ''
return self.aParent.atitle
parent.short_description='父级区域名称'
2)打开booktest/admin.py文件,修改AreaAdmin类如下:
class AreaAdmin(admin.ModelAdmin):
...
list_display = ['id','atitle','title','parent']
4.3 自定义列名
打开booktest/models.py文件,修改模型类,为属性指定verbose_name参数,即第一个参数。
class AreaInfo(models.Model):
atitle=models.CharField('标题',max_length=30,verbose_name="标题")#名称
5.自定义管理页面的 编辑页
5.1 展示顺序和字段名
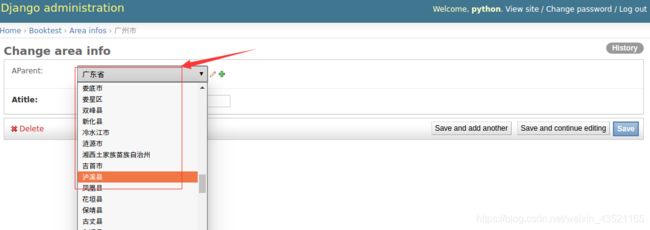
1)点击某行ID的链接,可以转到修改页面,默认效果如下图:
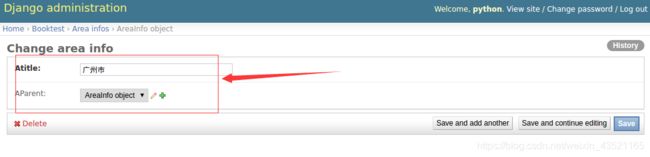
2)打开booktest/admin.py文件,修改AreaAdmin类如下:
class AreaAdmin(admin.ModelAdmin):
…
fields=[‘aParent’,‘atitle’]
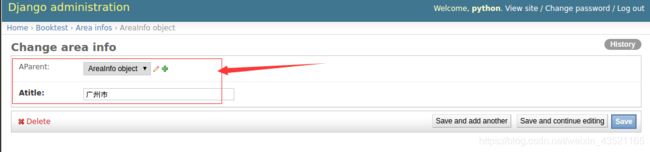
3)在下拉列表中输出的是对象的名称,可以在模型类中定义str方法用于对象转换字符串。
1)打开booktest/models.py文件,修改AreaInfo类,添加str方法。
class AreaInfo(models.Model):
def __str__(self):
return self.atitle
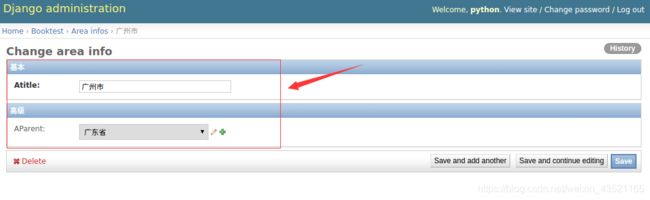
5.2 分组显示
属性如下:
说明:fields与fieldsets两者选一使用。
fieldset=(
('组1标题',{'fields':('字段1','字段2')}),
('组2标题',{'fields':('字段3','字段4')}),
)
1)打开booktest/admin.py文件,修改AreaAdmin类如下:
class AreaAdmin(admin.ModelAdmin):
...
# fields=['aParent','atitle']
fieldsets = (
('基本', {'fields': ['atitle']}),
('高级', {'fields': ['aParent']})
)
5.3 关联显示
在一对多的关系中,可以在一端的编辑页面中编辑多端的对象,嵌入多端对象的方式包括表格、块两种。 类型InlineModelAdmin:表示在模型的编辑页面嵌入关联模型的编辑。
子类StackedInline:以块的形式嵌入。
子类TabularInline:以表格的形式嵌入。
- 5.31 子类StackedInline:以块的形式嵌入。
1)打开booktest/admin.py文件,创建AreaStackedInline类。
# 先单独定义 然后在管理类中引入
class AreaStackedInline(admin.StackedInline):
model = AreaInfo#关联子对象
extra = 2#额外编辑2个子对象
class AreaAdmin(admin.ModelAdmin):
...
inlines = [AreaStackedInline]
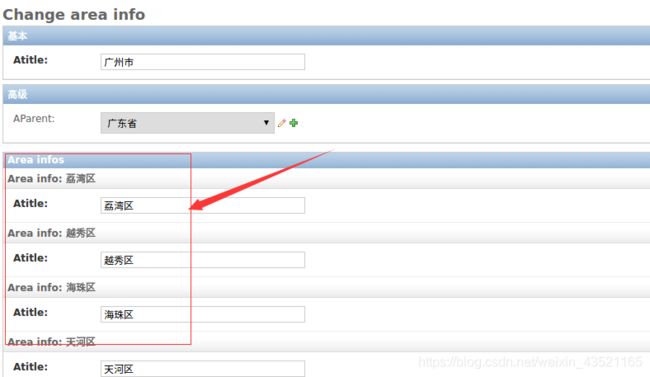
- 5.32 子类TabularInline:以表格的形式嵌入。
1)打开booktest/admin.py文件,创建AreaStackedInline类。
class AreaStackedInline(admin.StackedInline):
model = AreaInfo#关联子对象
extra = 2#额外编辑2个子对象
class AreaAdmin(admin.ModelAdmin):
...
inlines = [AreaStackedInline]

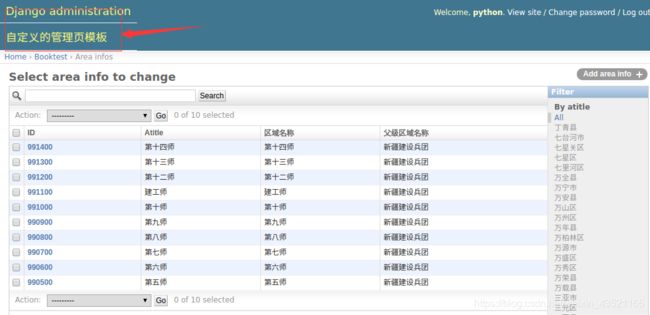
重写管理模板
1)在templates/目录下创建admin目录,结构如下图:
2)打开当前虚拟环境中Django的目录,再向下找到admin的模板,然后复制其中某一个想改页面的文件到,之前创建的admin文件夹里去
3)将需要更改文件拷贝到第一步建好的目录里,此处以base_site.html为例。

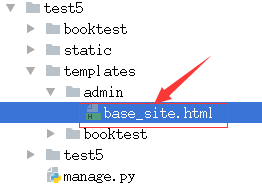
编辑base_site.html文件:
{% extends "admin/base.html" %}
{% block title %}{{ title }} | {{ site_title|default:_('Django site admin') }}{% endblock %}
{% block branding %}
<h1 id="site-name"><a href="{% url 'admin:index' %}">{{ site_header|default:_('Django administration') }}a>h1>
<hr>
<h1>自定义的管理页模板h1>
<hr>
{% endblock %}
{% block nav-global %}{% endblock %}
四、视图
使用视图时需要进行两步操作:
- 1.定义视图函数
- 2.配置URLconf
1.定义视图
视图就是一个Python函数,被定义在views.py中。
视图的必须有一个参数,一般叫request,视图必须返回HttpResponse对象,HttpResponse中的参数内容会显示在浏览器的页面上。
打开booktest/views.py文件,定义视图index如下
from django.shortcuts import render
from booktest.models import BookInfo
#首页,展示所有图书
def index(reqeust):
#查询所有图书
booklist = BookInfo.objects.all()
#将图书列表传递到模板中,然后渲染模板
return render(reqeust, 'booktest/index.html', {'booklist': booklist})
#详细页,接收图书的编号,根据编号查询,再通过关系找到本图书的所有英雄并展示
def detail(reqeust, bid):
#根据图书编号对应图书
book = BookInfo.objects.get(id=int(bid))
#查找book图书中的所有英雄信息
heros = book.heroinfo_set.all()
#将图书信息传递到模板中,然后渲染模板
return render(reqeust, 'booktest/detail.html', {'book':book,'heros':heros})
2.配置URLconf
一条URLconf包括url规则、视图两部分:
- url规则使用正则表达式定义。
- 视图就是在views.py中定义的视图函数。
需要两步完成URLconf配置:
- 1.在应用中定义URLconf
- 2.包含到项目的URLconf中
在booktest/应用下创建urls.py文件,应用文件中urls.py定义代码如下:
from django.urls import path
from . import views
app_name = 'polls'
urlpatterns = [
#配置首页url
path(r'^$', views.index),
# path('', views.IndexView.as_view(), name='index'),
# path(r'/', views.DetailView.as_view(), name='detail'),
#配置详细页url,\d+表示多个数字,小括号用于取值,建议复习下正则表达式
path(r'^(\d+)/$',views.detail),
]
项目目录的urls.py (include括号里的是应用名点urls)
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('polls/', include('polls.urls')),
]
3.URl参数配置
可以在匹配过程中从url中捕获参数,每个捕获的参数都作为一个普通的python字符串传递给视图。
获取值需要在正则表达式中使用小括号,分为两种方式:
- 方式一:位置参数
- 方式二:关键字参数
| 方式 | 内容 | 示例 | 视图 |
|---|---|---|---|
| 位置参数 | 直接使用小括号,通过位置参数传递给视图 | path(r'^delete(\d+)/$',views.show_arg) |
def show_arg(request,id): return HttpResponse(‘show arg %s’%id) |
| 关键字参数 | 在正则表达式部分为组命名(?P |
path(r'^delete(?P |
def show_arg(request,id1): return HttpResponse(‘show %s’%id1) |
4.HttpReqeust对象
定义在django.http.QueryDict
HttpRequest对象的属性GET、POST都是QueryDict类型的对象
与python字典不同,QueryDict类型的对象用来处理同一个键带有多个值的情况
方法get():根据键获取值
如果一个键同时拥有多个值将获取最后一个值
如果键不存在则返回None值,可以设置默认值进行后续处理
| 属性名 | 功能 |
|---|---|
| path | 一个字符串,表示请求的页面的完整路径,不包含域名和参数部分。 |
| method | 一个字符串,表示请求使用的HTTP方法,常用值包括:‘GET’、‘POST’。 |
| encoding | 一个字符串,表示提交的数据的编码方式。如果为None则表示使用浏览器的默认设置,一般为utf-8。 |
| GET | QueryDict类型对象,类似于字典,包含get请求方式的所有参数。 |
| POST | QueryDict类型对象,类似于字典,包含post请求方式的所有参数。 |
| FILES | 一个类似于字典的对象,包含所有的上传文件。 |
| COOKIES | 一个标准的Python字典,包含所有的cookie,键和值都为字符串。 |
| session | 一个既可读又可写的类似于字典的对象,表示当前的会话,只有当Django 启用会话的支持时才可用,详细内容见"状态保持"。 |
| 代码示例 |
def index(request):
str='%s,%s'%(request.path,request.encoding)
return render(request, 'booktest/index.html', {'str':str})
def method_show(request):
return HttpResponse(request.method)
GET属性
请求格式:在请求地址结尾使用?,之后以"键=值"的格式拼接,多个键值对之间以&连接。
POST属性
表单控件name属性的值作为键,value属性的值为值,构成键值对提交。
如果表单控件没有name属性则不提交。
对于checkbox控件,name属性的值相同为一组,被选中的项会被提交,出现一键多值的情况。
键是表单控件name属性的值,是由开发人员编写的。
值是用户填写或选择的。
属性代码
#接收请求参数
def show_reqarg(request):
if request.method == 'GET':
a = request.GET.get('a') #获取请求参数a
b = request.GET.get('b') #获取请求参数b
c = request.GET.get('c') #获取请求参数c
return render(request, 'booktest/show_getarg.html', {'a':a, 'b':b, 'c':c})
else:
name = request.POST.get('uname') #获取name
gender = request.POST.get('gender') #获取gender
hobbys = request.POST.getlist('hobby') #获取hobby
return render(request, 'booktest/show_postarg.html', {'name':name, 'gender':gender, 'hobbys':hobbys})
5.HttpResponse对象
视图在接收请求并处理后,必须返回HttpResponse对象或子对象。在django.http模块中定义了HttpResponse对象的API。HttpRequest对象由Django创建,HttpResponse对象由开发人员创建。
| 属性 | 含义 |
|---|---|
| content | 表示返回的内容。 |
| charset | 表示response采用的编码字符集,默认为utf-8。 |
| status_code | 返回的HTTP响应状态码。 |
| content-type | 指定返回数据的的MIME类型,默认为’text/html’。 |
6.cookie
是网站以键值对格式存储在浏览器中的一段纯文本信息,用于实现用户跟踪。
| 参数 | 含义 |
|---|---|
| max_age | 是一个整数,表示在指定秒数后过期。 |
| expires | 是一个datetime或timedelta对象,会话将在这个指定的日期/时间过期。 |
| max_age与expires二选一。如果不指定过期时间,在关闭浏览器时cookie会过期。 | |
| delete_cookie(key) | 删除指定的key的Cookie,如果key不存在则什么也不发生。 |
| write | 向响应体中写数据。 |
设置Cookie
方法
init:创建HttpResponse对象后完成返回内容的初始化。
set_cookie:设置Cookie信息。
set_cookie(key, value=‘’, max_age=None, expires=None)
def cookie_set(request):
response = HttpResponse("设置Cookie,请查看响应报文头
")
response.set_cookie('h1', '你好')
return response
读取Cookie
Cookie信息被包含在请求头中,使用request对象的COOKIES属性访问。
def cookie_get(request):
response = HttpResponse("读取Cookie,数据如下:
")
if 'h1' in request.COOKIES:
response.write(''
+ request.COOKIES['h1'] + '')
return response
7.Session
Django项目默认启用Session,禁用Session可以将Session中间件删除或注释。
存储方式
项目的settings.py文件,设置SESSION_ENGINE项指定Session数据存储的方式,可以存储在数据库、缓存、Redis等。
1)存储在数据库中,如下设置可以写,也可以不写,这是默认存储方式。
SESSION_ENGINE='django.contrib.sessions.backends.db'
2)存储在缓存中:存储在本机内存中,如果丢失则不能找回,比数据库的方式读写更快。
SESSION_ENGINE='django.contrib.sessions.backends.cache'
3)混合存储:优先从本机内存中存取,如果没有则从数据库中存取。
SESSION_ENGINE='django.contrib.sessions.backends.cached_db'
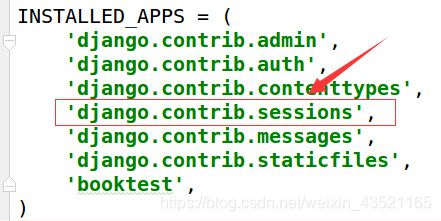
4)如果存储在数据库中,需要在项INSTALLED_APPS中安装Session应用。
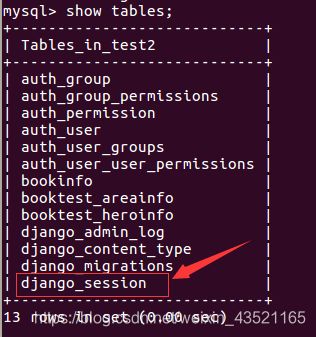
5)迁移后会在数据库中创建出存储Session的表。
6)表结构如下图。
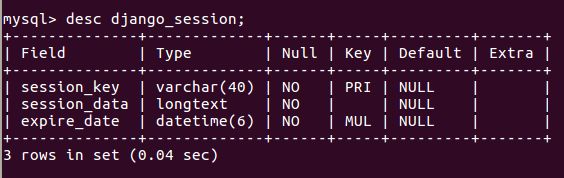
由表结构可知,操作Session包括三个数据:键,值,过期时间。
对象及方法
通过HttpRequest对象的session属性进行会话的读写操作。
| 功能 | 代码示例 |
|---|---|
| 1) 以键值对的格式写session。 | request.session[‘键’]=值 |
| 2)根据键读取值。 | request.session.get(‘键’,默认值) |
| 3)清除所有session,在存储中删除值部分。 | request.session.clear() |
| 4)清除session数据,在存储中删除session的整条数据。 | request.session.flush() |
| 5)删除session中的指定键及值,在存储中只删除某个键及对应的值。 | del request.session[‘键’] |
| 6)设置会话的超时时间,如果没有指定过期时间则两个星期后过期。 | request.session.set_expiry(value) |
| 如果value是一个整数,会话将在value秒没有活动后过期。 | |
| 如果value为0,那么用户会话的Cookie将在用户的浏览器关闭时过期。 | |
| 如果value为None,那么会话永不过期。 |
示例
写session
def session_test(request):
request.session['h1']='hello'
return HttpResponse('写session')
读session
def session_test(request):
# request.session['h1']='hello'
h1=request.session.get('h1')
return HttpResponse(h1)
删除
def session_test(request):
# request.session['h1']='hello'
# h1=request.session.get('h1')
del request.session['h1'] # 删除session中的指定键及值,在存储中只删除某个键及对应的值。
request.session.clear() # 清除所有session,在存储中删除值部分。
request.session.flush() # 清除session数据,在存储中删除session的整条数据
return HttpResponse('ok')
使用Redis存储Session
会话还支持文件、纯cookie、Memcached、Redis等方式存储,下面演示使用redis存储。
1)安装包。
pip install django-redis-sessions==0.5.6
2)修改项目settings文件,增加如下项:
SESSION_ENGINE = ‘redis_sessions.session’
SESSION_REDIS_HOST = ‘localhost’
SESSION_REDIS_PORT = 6379
SESSION_REDIS_DB = 2
SESSION_REDIS_PASSWORD = ‘’
SESSION_REDIS_PREFIX = ‘session’
3)视图函数
def session_test(request):
request.session['h1']='hello'
# h1=request.session.get('h1')
# del request.session['h1']
# request.session.flush()
return HttpResponse('ok')
4)管理redis的命令,需要保证redis服务被开启。
查看:ps ajx|grep redis
启动:sudo service redis start
停止:sudo service redis stop
使用客户端连接服务器:redis-cli
切换数据库:select 2
查看所有的键:keys *
获取指定键的值:get name
8.rest_framwork视图函数的书写
from django.shortcuts import render,HttpResponse
from django.views import View
from rest_framework.mixins import ListModelMixin, CreateModelMixin, \
RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin
from rest_framework.views import APIView
from rest_framework import serializers # 序列化数据 相对繁琐 要先建立对应的类
from rest_framework.viewsets import ModelViewSet
from rest_framework.generics import GenericAPIView,ListCreateAPIView,RetrieveUpdateDestroyAPIView
from rest_framework.response import Response # 响应时将序列字符串数据转为json返回
from drfdemo.models import Student,Author,Publish,BookInfo,HeroInfo
# Create your views here.
from drfdemo.my_serializers import StudetModelSerializer
class StudentSerializer(serializers.Serializer):
# 使用原生序列化器方法构建序列化对象 后续都可以升级为 serializers.ModelSerializer
# 这里面有的字段名才会被序列化 source 值的名需要和models里一致 不然变量名要一致
name = serializers.CharField()
sex = serializers.BooleanField()
age = serializers.IntegerField()
class_null = serializers.CharField()
# 使用drf的 view
class StudentView(APIView):
def get(self, request):
print(request.GET)
print(request.query_params) # 获取get请求的参数
student = Student.objects.all()
# 序列化对象 对查询的queryset 结果做序列化 构建成json格式
Serializer = StudentSerializer(instance=student,many=True)
print(11112,Serializer.data)
return Response(Serializer.data)
# return HttpResponse(f"STUDENT get ..请求{Serializer.data}")
def post(self, request):
# post 请求有data功能
print(request.data) # 获取post请求的参数
return HttpResponse(f"STUDENT post ..请求{request.data}")
class StudentDetailView(APIView):
def get(self, request,id):
print(request.query_params)
print("调用 StudentDetailView--id:",id)
student = Student.objects.get(pk=id)
# 序列化对象 对查询的queryset 结果做序列化 构建成json格式 instance 序列化时候参数
Serializer = StudentSerializer(instance=student,many=False)
return Response(Serializer.data)
def post(self, request,id):
# post 请求有data功能
print("StudentDetailView 的 post请求",request.data)
# data 做反序列化时候用
serializer_data = StudentSerializer(data=request.data)
# serializer_data有三个方法 第一个必须先调用才有后两个
# ①is_valid() 去校验数据是否符合 StudentSerializer 规则 返回true or false
# ②validated_data 去获取校验通过的数据
# ②errors 去获取校 不 验通过的数据及报错原因
"""
if serializer_data.is_valid():
# 数据格式校验通过
stu = Student.objects.create(**serializer_data.validated_data)
ser = StudentSerializer(instance=stu,many=False)
return Response(ser.data)
else:
print("校验不通过")
return Response(serializer_data.errors) # serializer_data.errors 校验错误报的信息
# return HttpResponse(f"STUDENT post ..请求{request.data}")
"""
# 重写上面的if分支
try:
serializer_data.is_valid(raise_exception=True)
print('反序列化后的数据:', serializer_data.validated_data)
# 如果没有报错(校验通过) 则插入记录
stu = Student.objects.create(**serializer_data.validated_data)
ser = StudentSerializer(instance=stu, many=False)
return Response(ser.data)
except:
return Response(serializer_data.errors)
def delete(self,request,id):
Student.objects.get(pk=id).delete()
return Response(f"删除id={id}成功")
def put(self,request,id):
serializer_data = StudentSerializer(data=request.data)
if serializer_data.is_valid():
n = Student.objects.filter(pk=id).update(**serializer_data.validated_data)
print("n:",n)
stu = Student.objects.get(pk=id)
RES = StudentSerializer(instance=stu)
return Response(RES.data)
else:
print("校验不通过")
return Response(serializer_data.errors)
# 使用 ModelViewSet
class StudetModelSerializer_2(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
class StudetModelViewSet(ModelViewSet):
queryset = Student.objects.all()
print("我被执行了",queryset)
serializer_class = StudetModelSerializer_2
print("我被执行了", serializer_class.is_valid)
#########################################################################
# 下面三个搭配使用 序列化器 多值视图 单值视图
class AuthorSerializers(serializers.Serializer):
name = serializers.CharField(max_length=32)
age = serializers.CharField()
def create(self,validated_data):
# 向数据库Author添加记录
authoor_obj = Author.objects.create(**validated_data)
return authoor_obj
def update(self, instance, validated_data):
# 向数据库Author添加记录
Author.objects.filter(pk=instance.pk).update(**validated_data)
return instance
class AuthorView(APIView):
"""多个查询"""
def get(self, requests):
authors = Author.objects.all()
serializer = AuthorSerializers(instance=authors,many=True)
return Response(serializer.data)
def post(self, requests):
serializer = AuthorSerializers(data=requests.data, many=True)
try :
serializer.is_valid(raise_exception=True)
# 向数据库 Author 表添加记录
# authoor_obj = Author.objects.create(**serializer.validated_data)
# 使用save方法 解耦post 校验和增查操作 需要在序列化器中重写 create 方法
serializer.save()
print("serializer.data:",serializer.data)
return Response(serializer.data)
except:
return Response(serializer.errors)
class AuthorDetailView(APIView):
"""单个查询"""
def get(self,request,id):
author = Author.objects.get(pk=id)
serializer = AuthorSerializers(instance=author,many=False)
return Response(serializer.data)
def put(self,request,id):
author = Author.objects.get(pk=id)
serializer = AuthorSerializers(instance=author,data=request.data)
try:
serializer.is_valid(raise_exception=True)
# 序列化器里 有instance的值 则走更新逻辑 否则走创建逻辑
serializer.save()
return Response(serializer.data)
except:
return Response(serializer.errors)
def delete(self,request,id):
Author.objects.get(pk=id).delete()
return Response("OK")
##########################################################################
# 跟上方 AUTHOR 类似 下面升级一下换一个序列化器 ModelSerializer 简化序列化验证代码
# 下面三个搭配使用 序列化器 多值视图 单值视图
class PublishSerializers(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
"""下面可以写各种校验规则 validate_字段名"""
# def validate_name(self,value):
# if value.endwith("出版社"):
# return value
# else:
# raise serializers.ValidationError("出版社名称没有以出版社结尾!")
# 使用 GenericAPIView 简化查询 和序列化重复的代码 其继承自 APIView
class PublishView(GenericAPIView):
"""多个查询"""
# 下面定义两个固定字段属性 用于后续被Generic调用
queryset = Publish.objects
serializer_class = PublishSerializers
# self.get_serializer 可以获取到序列化器类并将数据传入后进行序列化后返回
def get(self, request):
serializer = self.get_serializer(instance=self.get_queryset(),many=True)
return Response(serializer.data)
def post(self, request):
serializer = self.get_serializer(data=request.data)
try:
serializer.is_valid(raise_exception=True)
serializer.save()
print("serializer.data:",serializer.data)
return Response(serializer.data)
except:
return Response(serializer.errors)
class PublishDetailView(GenericAPIView):
"""单个查询 更新 删除"""
# 下面定义两个固定字段属性 用于后续被Generic调用
queryset = Publish.objects
serializer_class = PublishSerializers
def get(self,request,pk): # 此处字段参数pk 必须和url路径中定义的一致
# self.get_object() 会对pk进行查询
serializer = self.get_serializer(instance=self.get_object(),many=False)
return Response(serializer.data)
def put(self,request,pk):
serializer = self.get_serializer(instance=self.get_object(),data=request.data)
try:
serializer.is_valid(raise_exception=True)
# 序列化器里 有instance的值 则走更新逻辑 否则走创建逻辑
serializer.save()
return Response(serializer.data)
except:
return Response(serializer.errors)
def delete(self,request,pk):
self.get_object().delete()
return Response("OK")
#############################继续升级代码封装####然而还可以继续封装#########################################
# 继续升级代码封装 除了继承GenericAPIView,还继承mixins的各种增删改查父类
# 下面三个搭配使用 序列化器 多值视图 单值视图
class PublishSerializers_2(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
# 使用 GenericAPIView 和 mixins 简化查询 和序列化重复的代码
# 再使用 from rest_framework.mixins import ListModelMixin 。。。。简化请求处理逻辑
class PublishView_2(GenericAPIView,ListModelMixin,CreateModelMixin):
"""多个查询 和 post 增加"""
# 下面定义两个固定字段属性 用于后续被Generic调用
queryset = Publish.objects
serializer_class = PublishSerializers_2
def get(self, request):
return self.list(request)
def post(self, request):
return self.create(request)
class PublishDetailView_2(GenericAPIView,RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin):
"""单个查询 更新 删除"""
# 下面定义两个固定字段属性 用于后续被Generic调用
queryset = Publish.objects
serializer_class = PublishSerializers_2
def get(self,request,pk): # 此处字段参数pk 必须和url路径中定义的一致
return self.retrieve(request)
def put(self,request,pk):
return self.update(request)
def delete(self,request,pk):
return self.destroy(request)
#############################继续升级代码封装####然而还可以继续封装#########################################
# 继续升级代码封装 除了继承GenericAPIView,还继承mixins的各种增删改查父类
# 下面三个搭配使用 序列化器 多值视图 单值视图
class PublishSerializers_3(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
# 使用 ListCreateAPIView ,RetrieveUpdateDestroyAPIView其继承了 GenericAPIView 和 mixins 可以进一步将固定的请求方法进一步封装 之后只写序列化器和查询集即可
# 再使用 from rest_framework.generics import ListCreateAPIView 。。。。简化请求处理逻辑
class PublishView_3(ListCreateAPIView):
"""多个查询 和 post 增加"""
# 下面定义两个固定字段属性 用于后续被Generic调用
queryset = Publish.objects
serializer_class = PublishSerializers_3
class PublishDetailView_3(RetrieveUpdateDestroyAPIView):
"""单个查询 更新 删除"""
queryset = Publish.objects
serializer_class = PublishSerializers_3
#############################继续升级代码封装#####使用ModelViewSet##
class PublishSerializers_4(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
class PublishView_4(ModelViewSet):
"""根据路由中定义好的方法进行多种请求操作"""
queryset = Publish.objects
serializer_class = PublishSerializers_4
9.rest_framwork自定义路由的书写
from django.urls import path, re_path
from .views import StudetModelViewSet, AuthorView, AuthorDetailView, PublishView, PublishDetailView, \
PublishDetailView_2, PublishView_2, PublishDetailView_3, PublishView_3, PublishView_4
from rest_framework.routers import DefaultRouter
urlpatterns = [
path("aut",AuthorView.as_view()),
re_path("aut(\d+)/",AuthorDetailView.as_view()),
path("pub/",PublishView.as_view()),
path("pub2/",PublishView_2.as_view()),
path("pub3/",PublishView_3.as_view()),
path("pub4/",PublishView_4.as_view({"get":"list","post":"create"})),
re_path("pub/(?P\d+)" ,PublishDetailView.as_view()),
re_path("pub2/(?P\d+)" ,PublishDetailView_2.as_view()),
re_path("pub3/(?P\d+)" ,PublishDetailView_3.as_view()),
re_path("pub4/(?P\d+)" ,PublishView_4.as_view({"get":"retrieve","put":"update","delete":"destroy"}))
]
router = DefaultRouter() # 可以处理视图的路由器
router.register('students',StudetModelViewSet)
urlpatterns += router.urls
五、模板
虽然官网演示说在应用目录下建立模板文件夹,但是问了使用方便,一般在和应用平级的目录下建立templates文件夹即可,然后分别再在其中建立多个对应应用名称的文件夹,存储前端代码文件,然后记得在settings文件中做配置
1 模板配置

2 定义模板
打开templtes/booktest/index.html文件,定义代码如下:
<html>
<head>
<title>首页title>
head>
<body>
<h1>图书列表h1>
<ul>
{#遍历图书列表#}
{%for book in booklist%}
<li>
{#输出图书名称,并设置超链接,链接地址是一个数字#}
<a href="/{{book.id}}/">{{book.btitle}}a>
li>
{%endfor%}
ul>
body>
html>
编写templates/booktest/detail.html文件如下:
<html>
<head>
<title>详细页title>
head>
<body>
{#输出图书标题#}
<h1>{{book.btitle}}h1>
<ul>
{#通过关系找到本图书的所有英雄,并遍历#}
{%for hero in heros%}
{#输出英雄的姓名及描述#}
<li>{{hero.hname}}---{{hero.hcomment}}li>
{%endfor%}
ul>
body>
html>
3 模板语法
在模板中输出变量语法如下,变量可能是从视图中传递过来的,也可能是在模板中定义的。
模板变量的作用是计算并输出,变量名必须由字母、数字、下划线(不能以下划线开头)和点组成。
- 当模版引擎遇到点如book.title,会按照下列顺序解析:
1.字典book[‘title’]
2.先属性后方法,将book当作对象,查找属性title,如果没有再查找方法title()
3.如果是格式为book.0则解析为列表book[0]
如果变量不存在则插入空字符串’'。
在模板中调用方法时不能传递参数。
在模板中使用如下模板注释,这段代码不会被编译,不会输出到客户端;html注释只能注释html内容,不能注释模板语言。
| 前端书写格式 | 语法功能 |
|---|---|
| {{变量名}} | 变量 |
| {%代码段%} | 内写python语法 |
| {{forloop.counter}} | 表示当前是第几次循环,从1开始 |
| == != < > <= >= | 注意:运算符左右两侧不能紧挨变量或常量,必须有空格。 |
| and or not | 布尔运算符 |
| {#…#} | 单行注释语法 |
| {%comment%}…{%endcomment%} | 多行注释使用comment标签 |
for标签语法如下:
{%for item in 列表%}
循环逻辑
{{forloop.counter}}表示当前是第几次循环,从1开始
{%empty%}
列表为空或不存在时执行此逻辑
{%endfor%}
if标签语法如下:
{%if ...%}
逻辑1
{%elif ...%}
逻辑2
{%else%}
逻辑3
{%endif%}
4.过滤器
语法如下:
使用管道符号|来应用过滤器,用于进行计算、转换操作,可以使用在变量、标签中。
如果过滤器需要参数,则使用冒号:传递参数。
变量|过滤器:参数
长度length,返回字符串包含字符的个数,或列表、元组、字典的元素个数。
默认值default,如果变量不存在时则返回默认值。
data|default:‘默认值’
日期date,用于对日期类型的值进行字符串格式化,常用的格式化字符如下:
Y表示年,格式为4位,y表示两位的年。
m表示月,格式为01,02,12等。
d表示日, 格式为01,02等。
j表示日,格式为1,2等。
H表示时,24进制,h表示12进制的时。
i表示分,为0-59。
s表示秒,为0-59。
value|date:"Y年m月j日 H时i分s秒"
自定义过滤器
过滤器就是python中的函数,注册后就可以在模板中当作过滤器使用,下面以求余为例开发一个自定义过滤器mod。
在应用中创建templatetags目录,当前示例为"booktest/templatetags",创建_init_文件,内容为空。

2)在"booktest/templatetags"目录下创建filters.py文件,代码如下:
#导入Library类
from django.template import Library
#创建一个Library类对象
register=Library()
#使用装饰器进行注册
@register.filter
#定义求余函数mod,将value对2求余
def mod(value):
return value%2 == 0
3)在templates/booktest/temp_filter.html中,使用自定义过滤器。
首先使用load标签引入模块。
{%load filters%}
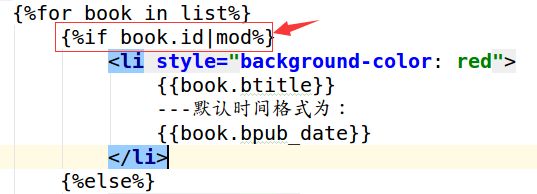
过滤器可以接收参数,将booktest/templatetags/filters.py中增加mod_num函数。
#使用装饰器进行注册
@register.filter
#定义求余函数mod_num,将value对num求余
def mod_num(value,num):
return value%num

5模板继承
5.1父模板
标签block:用于在父模板中预留区域,留给子模板填充差异性的内容,名字不能相同。 为了更好的可读性,建议给endblock标签写上名字,这个名字与对应的block名字相同。父模板中也可以使用上下文中传递过来的数据。
{%block 名称%}
预留区域,可以编写默认内容,也可以没有默认内容
{%endblock 名称%}
5.2子模板
子模版不用填充父模版中的所有预留区域,如果子模版没有填充,则使用父模版定义的默认值。
标签extends:继承,写在子模板文件的第一行。
{% extends "父模板路径"%}
填充父模板中指定名称的预留区域。
{%block 名称%}
实际填充内容
{{block.super}}用于获取父模板中block的内容
{%endblock 名称%}
{%extends 'booktest/inherit_base.html'%}
{%block qu2%}
{%for book in list%}
- {{book.btitle}}
{%endfor%}
{%endblock qu2%}
6 视图调用模板简写
视图调用模板都要执行以上三部分,于是Django提供了一个函数render封装render方法,
render包含3个参数:
- 第一个参数为request对象
- 第二个参数为模板文件路径
- 第三个参数为字典,表示向模板中传递的上下文数据
打开booktst/views.py文件,调用render的代码如下:
from django.shortcuts import render
def index(request):
context={'title':'图书列表','list':range(10)}
return render(request,'booktest/index.html',context)
#重定向
from django.shortcuts import redirect
def red1(request):
return redirect('/')
#直接传字典给模板
def index3(request):
return render(request, 'booktest/index3.html', {'h1': 'hello'})
#反向解析重定向
项目url
path(r'^',include('booktest.urls',namespace='booktest'))
应用url
path(r'^fan2/$', views.fan2,name='fan2')
from django.shortcuts import redirect
from django.core.urlresolvers import reverse
return redirect(reverse('booktest:fan2'))
7.反向解析
总结:在定义url时,需要为include定义namespace属性,为url定义name属性,使用时,在模板中使用url标签,在视图中使用reverse函数,根据正则表达式动态生成地址,减轻后期维护成本。
URL的参数
有些url配置项正则表达式中是有参数的,接下来讲解如何传递参数。
情况一:位置参数
url路径
path(r’^fan(\d+)_(\d+)/$', views.fan3,name=‘fan2’)
视图函数
def fan3(request, a, b):
return HttpResponse(a+b)
使用重定向传递位置参数格式如下:
return redirect(reverse(‘booktest:fan2’, args=(2,3)))
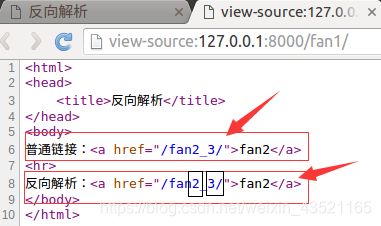
模板文件
<html>
<head>
<title>反向解析title>
head>
<body>
普通链接:<a href="/fan2_3/">fan2a>
<hr>
反向解析:<a href="{%url 'booktest:fan2' 2 3%}">fan2a>
body>
html>
情况二:关键字参数
url路径
path(r’^fan(?P\d+)_(?P\d+)/$', views.fan4,name=‘fan2’),
视图函数
def fan4(request, id, age):
return HttpResponse(id+age)
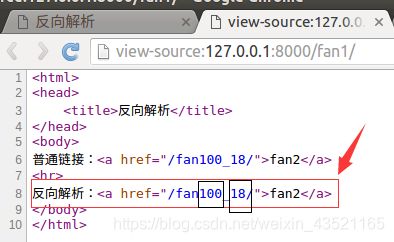
模板文件
<html>
<head>
<title>反向解析title>
head>
<body>
普通链接:<a href="/fan100_18/">fan2a>
<hr>
反向解析:<a href="{%url 'booktest:fan2' id=100 age=18%}">fan2a>
body>
html>
8.CSRF
Django提供了csrf中间件用于防止CSRF攻击,只需要在test4/settings.py中启用csrf中间件即可。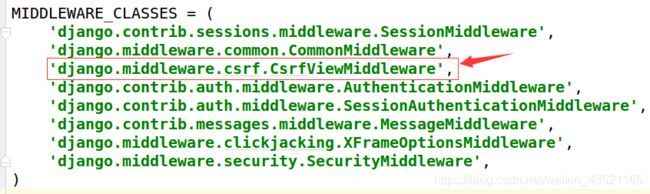
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>发帖页title>
head>
<body>
<form method="post" action="/post_action/">
{% csrf_token %}
标题:<input type="text" name="title"/><br/>
内容:<textarea name="content">textarea>
<input type="submit" value="发帖"/>
form>
body>
html>
六、查询
1.条件查询
字段查询
实现sql中where的功能,调用过滤器filter()、exclude()、get(),下面以filter()为例。
通过"属性名_id"表示外键对应对象的id值。
语法如下:
说明:属性名称和比较运算符间使用两个下划线,所以属性名不能包括多个下划线。
属性名称__比较运算符=值
①条件运算符
| 功能 | 符号 | 演示 | 解释 |
|---|
- 查询等|exact:表示判等。|list=BookInfo.objects.filter(id__exact=1) 可简写为:list=BookInfo.objects.filter(id=1)|查询编号为1的图书。
- 模糊查询|contains:是否包含。|list = BookInfo.objects.filter(btitle__contains=‘传’)|查询书名包含’传’的图书。
||startswith、endswith:以指定值开头或结尾。|list = BookInfo.objects.filter(btitle__endswith=‘部’)|查询书名以’部’结尾的图书
||以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith. - 空查询|isnull:是否为null。|list = BookInfo.objects.filter(btitle__isnull=False)|查询书名不为空的图书。
- 范围查询|in:是否包含在范围内。|list = BookInfo.objects.filter(id__in=[1, 3, 5])|查询编号为1或3或5的图书
- 比较查询|gt、gte、lt、lte:大于、大于等于、小于、小于等于。|list = BookInfo.objects.filter(id__gt=3)|查询编号大于3的图书
||不等于的运算符,使用exclude()过滤器。|list = BookInfo.objects.exclude(id=3)|查询编号不等于3的图书 - 日期查询|year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。|list = BookInfo.objects.filter(bpub_date__year=1980)|查询1980年发表的图书。
|||list = BookInfo.objects.filter(bpub_date__gt=date(1990, 1, 1))|查询1980年1月1日后发表的图书。
||||
F对象|进行两个属性之间的比较,需要导入from django.db.models import F|list = BookInfo.objects.filter(bread__gte=F(‘bcomment’))|查询阅读量大于等于评论量的图书
||可以在F对象上使用算数运算。|list = BookInfo.objects.filter(bread__gt=F(‘bcomment’) * 2)|查询阅读量大于2倍评论量的图书
||||
Q对象|进行或且非的操作,也需要导入 from django.db.models import Q |list = BookInfo.objects.filter(Q(bread__gt=20))|查询阅读量大于20的图书
||Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。|list = BookInfo.objects.filter(Q(bread__gt=20) | Q(pk__lt=3))|查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
||Q对象前可以使用~操作符,表示非not|list = BookInfo.objects.filter(~Q(pk=3))|查询编号不等于3的图书。
②聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg,Count,Max,Min,Sum,被定义在django.db.models中。
例:查询图书的总阅读量。
from django.db.models import Sum
...
list = BookInfo.objects.aggregate(Sum('bread'))
注意aggregate的返回值是一个字典类型,格式如下:
{'聚合类小写__属性名':值}
如:{'sum__bread':3}
使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
list = BookInfo.objects.count()
注意count函数的返回值是一个数字。
2.查询集
查询集表示从数据库中获取的对象集合,在管理器上调用某些过滤器方法会返回查询集,查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果,从Sql的角度,查询集和select语句等价,过滤器像where和limit子句。
两大特性
1惰性执行:创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用。
2缓存:使用同一个查询集,第一次使用时会发生数据库的查询,然后把结果缓存下来,再次使用这个查询集时会使用缓存的数据。
返回查询集的过滤器如下:
| 过滤器 | 功能 | 举例 |
|---|---|---|
| all() | 返回所有数据。 | list=BookInfo.objects.all() |
| filter() | 返回满足条件的数据。 | |
| exclude() | 返回满足条件之外的数据,相当于sql语句中where部分的not关键字。 | |
| order_by() | 对结果进行排序。 | |
| 返回单个值的过滤器如下: | ||
| 过滤器 | 功能 | 举例 |
| — | — | – |
| get() | 返回单个满足条件的对象如果未找到会引发"模型类.DoesNotExist"异常。如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常。 | |
| count() | 返回当前查询结果的总条数。 | |
| aggregate() | 聚合,返回一个字典。 |
判断某一个查询集中是否有数据:
| 过滤器 | 功能 | 举例 |
|---|---|---|
| exists() | 判断查询集中是否有数据,如果有则返回True,没有则返回False。 | |
| 限制查询集 | ||
| 可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。 |
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:获取第1、2项,运行查看。
list=BookInfo.objects.all()[0:2]
3.关联查询
Django中也能实现类似于join查询。
1通过对象执行关联查询
在定义模型类时,可以指定三种关联关系,最常用的是一对多关系,如本例中的"图书-英雄"就为一对多关系,接下来进入shell练习关系的查询。
①由一到多的访问语法:
一对应的模型类对象.多对应的模型类名小写_set
例:获得book图书的所有英雄。
b = BookInfo.objects.get(id=1)
b.heroinfo_set.all()
②由多到一的访问语法:
多对应的模型类对象.多对应的模型类中的关系类属性名
例:
h = HeroInfo.objects.get(id=1)
h.hbook
③访问一对应的模型类关联对象的id语法:
多对应的模型类对象.关联类属性_id
例:
h = HeroInfo.objects.get(id=1)
h.book_id
2通过模型类执行关联查询
①由一模型类条件查询多模型类数据: 语法如下:
一模型类关联属性名__一模型类属性名__条件运算符=值
例:查询书名为“天龙八部”的所有英雄。
list = HeroInfo.objects.filter(hbook__btitle=‘天龙八部’)
②由多模型类条件查询一模型类数据:
语法如下:
关联模型类名小写__属性名__条件运算符=值
如果没有"__运算符"部分,表示等于,结果和sql中的inner join相同。
例:查询图书,要求图书中英雄的描述包含’八’。
list = BookInfo.objects.filter(heroinfo__hcontent__contains=‘八’)
其他
1.静态文件
为了安全可以通过配置项隐藏真实图片路径,在模板中写成固定路径,后期维护太麻烦,可以使用static标签,根据配置项生成静态文件路径。
说明:这种方案可以隐藏真实的静态文件路径,但是结合Nginx布署时,会将所有的静态文件都交给Nginx处理,而不用转到Django部分,所以这项配置就无效了。
在项目根目录下创建static目录,再创建img、css、js目录。
项目配置
STATIC_URL = ‘/static/’
STATICFILES_DIRS = [os.path.join(BASE_DIR, ‘static’),]
<html>
<head>
<title>静态文件title>
head>
<body>
修改前:<img src="/static/img/sg.png"/>
<hr>
修改后:<img src="/abc/img/sg.png"/>
<hr>
动态配置:
{%load static from staticfiles%}
 body>
html>
body>
html>
2.中间件
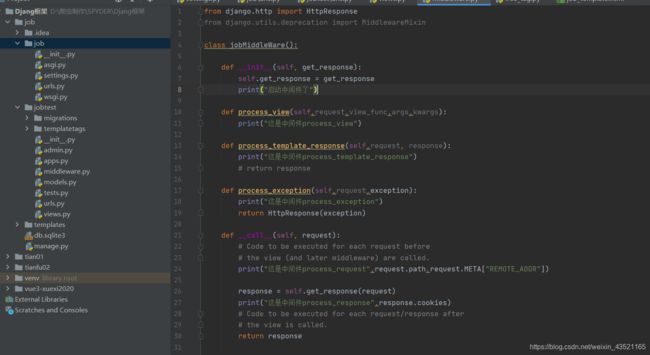
中间件定义
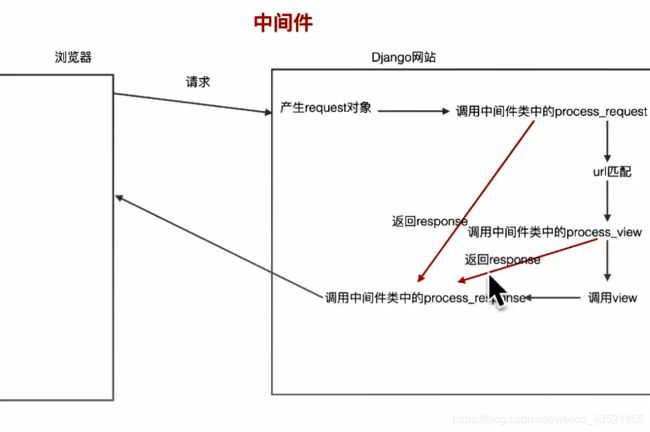
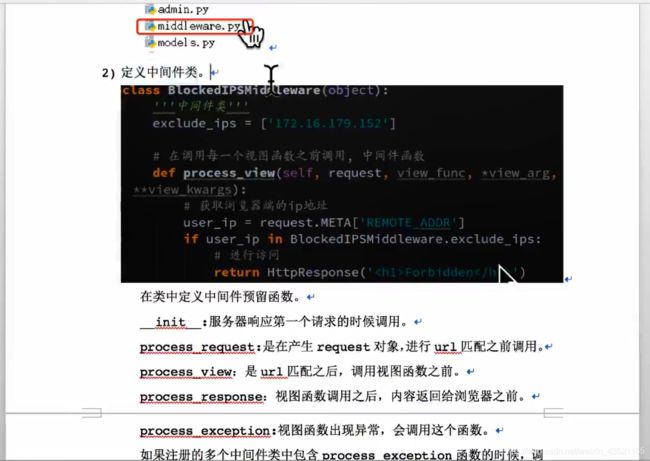
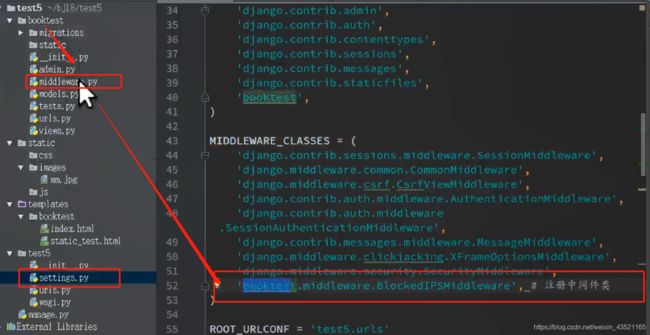
总的中间件举例django2.0+
3.celery
celery
情景:用户发起request,并等待response返回。在某些views中,可能需要执行一段耗时的程序,那么用户就会等待很长时间,造成不好的用户体验,比如发送邮件、手机验证码等。
使用celery后,情况就不一样了。解决:将耗时的程序放到celery中执行。
celery名词:
任务task:就是一个Python函数。
队列queue:将需要执行的任务加入到队列中。
工人worker:在一个新进程中,负责执行队列中的任务。
代理人broker:负责调度,在布置环境中使用redis。
安装包:
celery3.1.25
django-celery3.1.17
示例
5)在test6/settings.py中安装。
INSTALLED_APPS = (
…
‘djcelery’,
}
6)在test6/settings.py文件中配置代理和任务模块。
import djcelery
djcelery.setup_loader()
BROKER_URL = ‘redis://127.0.0.1:6379/2’
7)在booktest/目录下创建tasks.py文件。
9)执行迁移生成celery需要的数据表。
python manage.py migrate
(11)2023记录。
celery 文件和包的建立 tasks 名字要固定
celery 服务启动命令 (windows 环境下要加 -P gevent 没有的需要pip 安装一下)
celery -A celery_tasks.main worker -l info -P gevent

4.django项目终端常用命令
**********************公网IP:150.------9**********私网IP:*----*************************************
服务器: redis服务端: mysql服务端: 虚拟机 workon bj18_py3
python manage.py runserver sudo redis-server sudo service mysql start
ctrl+c 结束 ctrl+c 结束 sudo service mysql stop
云端 /usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
*******************************************************************************************************************
FDFS:
sudo service fdfs_trackerd start *** sudo service fdfs_trackerd stop
sudo service fdfs_storaged start *** sudo service fdfs_storaged stop
云端启动:
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf start
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf start
重启
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf restart
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf restart
********************************************************************************************************************
Nginx: Celery:
sudo /usr/local/nginx/sbin/nginx celery -A celery_tasks.tasks worker -l info
sudo /usr/local/nginx/sbin/nginx -s stop ctrl+c 结束
报错查询 grep "error_log" /usr/local/nginx/* -R
重启 sudo /usr/local/nginx/sbin/nginx -s reload
********************************************************************************************************************
uwsgi的启动和停止
启动:uwsgi –-ini 配置文件路径 例如:uwsgi --ini uwsgi.ini
停止:uwsgi --stop uwsgi.pid路径 例如:uwsgi --stop uwsgi.pid
重启:uwsgi --reload uwsgi.pid
sudo uwsgi --http :8000 --module juhe.wsgi
生成静态文件
python3 manage.py collectstatic