Python高级进阶--多线程爬取下载小说(基于笔趣阁的爬虫程序)
目录
一、前言
1、写在前面
2、本帖内容
二、编写代码
1、抓包分析
a、页面分析
b、明确需求
c、抓包搜寻
2、编写爬虫代码
a、获取网页源代码
b、提取所有章节的网页源代码
c、下载每个章节的小说
d、 清洗文件名
e、删除子文件夹
f、将下载的小说的所有txt文件夹放入所创建的文件夹路径
g、多线程下载
3、所有代码
三、后言
1、报错情况
2、线程不是越多越好
3、想要下载自己喜欢的小说
4、如何快速调试代码
5、建议
一、前言
1、写在前面
本帖采用了多线程的技术来加快爬虫的下载速度,对多线程不了解的同学可以自行百度或者关注本博主,博主后续将会出一篇详细的帖子来介绍多线程。此外,本帖还采用了正则表达式、Python的文件操作和xPath分析。不了解的小伙伴们也可以自行百度或者关注本博主,后续都会写几篇详细的帖子进行介绍!!!
2、本帖内容
笔趣阁(新笔趣阁_书友最值得收藏的网络小说阅读网 - TXT下载网)是一个资源丰富的小说网站,里面的小说全部免费。因此,对其的爬取比较简单,不需要用的逆向技术。对其的爬取,只需url,header请求头中的任何信息都用不上。本文详细讲解爬取里面的一本免费小说--《NBA:开局一张三分体验卡》,读者可以根据本帖,修改部分代码,爬取自己想要的小说。
笔趣阁现已更新为新笔趣阁,其首页:
本帖爬取的小说为《NBA:开局一张三分体验卡》(https://www.shuangliusc.com/html/469472/),其界面为:

二、编写代码
1、抓包分析
爬虫的第一步都是抓包分析(也就是分析网页,从网页源代码中找到自己想要的内容)。
a、页面分析
(1)页面中有最新章节章节目录和所有章节目录
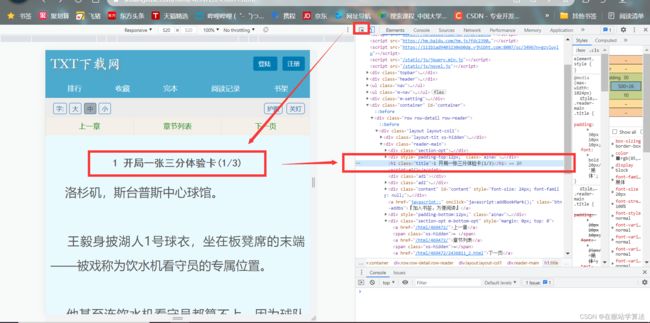
(2)点击一个章节就会跳转到其具体页面,但其中只是该章节的第一部分
(3)在一个章节的具体页面中存在下一页,点击下一页会跳转到该章节的下一个部分
(4)直到该章节的最后一个部分,下一页就会变成下一章
目录页:

具体章节页:


b、明确需求
根据以上页面分析,分析网页源代码,找到以下需求。
- 要获取到目录页中所有章节的链接
- 要获取到下一页链接
- 要找到小说内容所在网页源代码的所在位置
- 要找到小说章节标题所在网页源代码的所在位置
- 同一章节的小说内容放在一个txt文档中
- 为加快速度,采取多线程爬取下载
c、抓包搜寻
根据以上需求,分析网页源代码,找到想要的内容。
步骤:
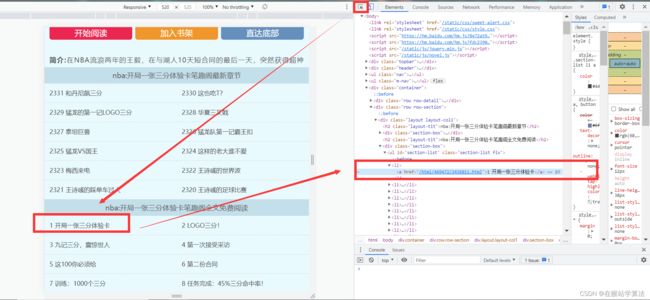
- 在目录页面,按下F12,打开开发者界面
- 点击开发者界面左上角的鼠标箭头
- 将箭头移到所有章节部分的一个章节上并点击一下
- 在开发者界面将会出现此部分的网页源代码

通过以上步骤,抓包寻找,可以分别找到需求部分所要内容:
- 要获取到目录页中所有章节的链接及标题所在源代码的位置
- 要获取到下一页链接
- 具体章节内容的标题

2、编写爬虫代码
根据上面的抓包分析,可以编写爬虫代码。
具体思路:
- 获取目录也中所有章节的源代码
- 获取具体章节的小说内容和标题
- 将获取到的小说内容根据顺序摆放下载到一个txt文档中
- 获取到下一页的链接
- 将同一章节的内容合并到一个txt文档中
- 采取多线程下载
- 最后以一个文件夹保存
- 文件名不能存在特殊字符,需要进行清洗
a、获取网页源代码
import os.path
from lxml import etree
import requests
# 1、获取小说目录页的网页源代码
index_url = 'https://www.shuangliusc.com/html/555664/'
r = requests.get(index_url, headers=header)b、提取所有章节的网页源代码
def gen_urls(index_url, q,p):
# 定义全局变量,gen_urls_done用于判断小说是否下载完成
global gen_urls_done
r = requests.get(url=index_url)
# 获取目录页的各个目录及其标题
html = etree.HTML(r.text)
links = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/@href')
titles = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/text()')
# 将标题装入一个队列中,为了下载时可以保持顺序,不会乱章
for title in titles:
p.put(title)
# 将链接装入另一个队列,为了下载时可以保持顺序,不会乱章
for link in links:
link = regular_link + link
q.put(link)
# 所有链接都已获取完毕并装入队列中
gen_urls_done = Truec、下载每个章节的小说
def download_file(q,p):
while True:
# 链接队列为空且gen_urls_done为真时,下载完成
if q.empty() and gen_urls_done:
print("小说已全部下载完成...")
break
else:
# 获取队列的第一个链接和标题
cur_url = q.get()
file_name = p.get()
# 清洗文件名
file_name = clean_filename(file_name)
# 采取当前时间作为文件夹保存同一章节下载的小说内容
# 设置源文件夹和目标文件夹
# 定义父文件夹路径
base_folder = r'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 获取当前时间
now = time.perf_counter()
# 格式化时间字符串,例如 "2024-02-11_031559"
folder_name = str(now)
# 根据需求更改路径,这里使用之前定义的父文件夹路径
source_folder = os.path.join(base_folder, folder_name)
# 创建文件夹
try:
# 使用exist_ok=True避免目录已存在的异常
os.makedirs(source_folder, exist_ok=True)
except Exception as e:
print(f"文件创建错误: {e}")
# 将同一章节的小说内容和标题全都下载到一个txt文档中
while True:
# 获取具体章节的小说内容和标题,并将其放入一个txt文档中
# 如何将同一章节的所有内容合并到一个txt文档?
# 思路:将同一章节获取到的每部分的内容都保存在同一个文件夹(以当前时间命名)中
# 再将该文件夹中的所有txt文档合并该文件夹的上一级文件夹中以该章节名进行命名的txt文档中
# 最后删除这些文件夹(以当前时间命名)
r = requests.get(cur_url)
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="section-opt m-bottom-opt"]//a[text()="下一页"]/@href')
content = html.xpath('//div[@class="container"]//div[@class="content"]/text()')
# 去掉小说内容中的特殊字符
content = "".join(content).replace('\xa0','\n').strip()
# 将章节的标题的特殊字符进行去除
title = html.xpath('//h1[@class="title"]/text()')[0]
title = clean_filename(title)
# 下载小说内容
with open(f'{source_folder}/{title}.txt', 'a',encoding='utf-8') as f:
f.write(title+'\n\n')
f.write(content+'\n\n')
print(f'{threading.current_thread().name}已完成...{title}的下载')
# 如果下一页的链接不存在,则跳出。也就是该章节的所有部分均已下载完毕!
if len(next_page) == 0:
break
# 获取下一页的内容
next_page = regular_link + next_page[0]
cur_url = next_page
# 将同一章节中的内容合并到一个txt文档中
target_folder = "C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说"
# 指定合并后的文件名(确保该文件不存在于temp文件夹内,避免被删除)
combined_file_path = os.path.join(target_folder, f'{file_name}.txt')
# 确保目标文件夹存在
os.makedirs(target_folder, exist_ok=True)
# 遍历文件夹中的所有.txt文件
with open(combined_file_path, 'w', encoding='utf-8') as combined_file:
for filename in os.listdir(source_folder):
file_path = os.path.join(source_folder, filename)
# 如果是文件且后缀是.txt就进行处理
if os.path.isfile(file_path) and filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as file:
combined_file.write(file.read() + '\n') # 将内容写入合并的文件
os.remove(file_path) # 删除已经合并的文件d、 清洗文件名
def clean_filename(filename):
# 以下正则表达式匹配有效的文件名字符,包括中文、英文、数字以及“-_(). ”
# 可以继续加入任何其他可接受的字符
pattern = re.compile(r'[^a-zA-Z0-9\u4e00-\u9fa5\-\_\.\(\)\s]')
cleaned_filename = re.sub(pattern, '', filename)
return cleaned_filenamee、删除子文件夹
# 删除子文件夹
def move_off():
parent_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 检查文件夹是否存在
if os.path.exists(parent_folder_path):
# 遍历该文件夹
for entry in os.listdir(parent_folder_path):
# 构建完整的文件/文件夹路径
full_path = os.path.join(parent_folder_path, entry)
# 检查这个路径是否是一个文件夹
if os.path.isdir(full_path):
# 删除文件夹
shutil.rmtree(full_path)
print(f"子文件夹 '{full_path}' 已被删除。")
else:
print(f"父文件夹 '{parent_folder_path}' 不存在。")f、将下载的小说的所有txt文件夹放入所创建的文件夹路径
def combine_file():
# 指定源文件夹路径
source_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 指定目标文件夹路径
target_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说/nba开局一张三分体验卡' # 你要移动到的新文件夹路径
# 检查目标文件夹是否存在,如果不存在,则创建它
if not os.path.exists(target_folder_path):
os.makedirs(target_folder_path)
# 遍历源文件夹
for entry in os.listdir(source_folder_path):
# 检查文件扩展名是否为.txt
if entry.lower().endswith('.txt'):
# 构建完整的文件路径
full_file_path = os.path.join(source_folder_path, entry)
# 构建目标文件路径
target_file_path = os.path.join(target_folder_path, entry)
# 移动文件
shutil.move(full_file_path, target_file_path)
# 输出完成的消息
print(f"所有的.txt文件已经从'{source_folder_path}'移动到'{target_folder_path}'。")g、多线程下载
# 主线程
def main():
# th1是获取链接
index_url = 'https://www.shuangliusc.com/html/555664/'
q = Queue(maxsize=2500)
p = Queue(maxsize=2500)
th1 = threading.Thread(target=gen_urls, args=(index_url, q, p))
th1.start()
threads = [th1]
# th2是下载小说,采取循环的方式,一共有20个线程执行下载小说
for i in range(20):
th2 = threading.Thread(target=download_file,args=(q, p),name=f"线程{i}")
th2.start()
threads.append(th2)
# 等待上面所有的线程完成
for thread in threads:
thread.join()
# 以上所有线程完成后调用move_off,此处可以不用线程,直接调用函数也可,但速度太慢。
# 注:此处由于使用的是多线程操作,存在多个线程对一个文件夹进行操作,以至于报错,但不影响最后需要的结果
# 报错是因为一个文件夹已经被一个线程操作完了,而另一个线程也想对其操作但找不到该文件夹,以至于报错。
threads2 = []
for i in range(10):
th3 = threading.Thread(target=move_off)
th3.start()
threads2.append(th3)
for thread in threads2:
thread.join()
# 所有线程完成后,执行combine_file函数
combine_file()
if __name__ == '__main__':
main()3、所有代码
注:此代码存在一点问题,请看后言的建议部分!!!
import os
import pprint
import queue
import re
import shutil
import string
import threading
import time
import requests
from lxml import etree
from queue import Queue
import os
from datetime import datetime
lock = threading.Lock()
# 固定链接
regular_link = 'https://www.shuangliusc.com'
gen_urls_done = False
# 清洗文件名
def clean_filename(filename):
# 以下正则表达式匹配有效的文件名字符,包括中文、英文、数字以及“-_(). ”
# 可以继续加入任何其他可接受的字符
pattern = re.compile(r'[^a-zA-Z0-9\u4e00-\u9fa5\-\_\.\(\)\s]')
cleaned_filename = re.sub(pattern, '', filename)
return cleaned_filename
# 1、获取目录页中的各个目录的链接
# 需要小说目录的链接和一个装各个目录的链接的队列
def gen_urls(index_url, q,p):
# 装入全局变量
global gen_urls_done
r = requests.get(url=index_url)
# 获取目录页的各个目录及其标题
html = etree.HTML(r.text)
links = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/@href')
titles = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/text()')
# 将标题装入一个队列中
for title in titles:
p.put(title)
# 将链接装入队列,为了下载时可以保持顺序,不会乱章
for link in links:
link = regular_link + link
q.put(link)
# 所有链接都已获取完毕并装入队列中
gen_urls_done = True
# 下载该章节
# 传入下载链接和章节名称的队列,以及下载路径
def download_file(q,p):
while True:
# 链接队列为空且gen_urls_done为真时,下载完成
if q.empty() and gen_urls_done:
print("小说已全部下载完成...")
break
else:
# 获取队列的第一个链接和标题
cur_url = q.get()
file_name = p.get()
# 清洗文件名
file_name = clean_filename(file_name)
# 采取当前时间作为文件夹保存同一章节下载的小说内容
# 设置源文件夹和目标文件夹
# 定义父文件夹路径
base_folder = r'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 获取当前时间
now = time.perf_counter()
# 格式化时间字符串,例如 "2024-02-11_031559"
folder_name = str(now)
# 根据需求更改路径,这里使用之前定义的父文件夹路径
source_folder = os.path.join(base_folder, folder_name)
# 创建文件夹
try:
# 使用exist_ok=True避免目录已存在的异常
os.makedirs(source_folder, exist_ok=True)
except Exception as e:
print(f"文件创建错误: {e}")
# 将同一章节的小说内容和标题全都下载到一个txt文档中
while True:
# 获取具体章节的小说内容和标题,并将其放入一个txt文档中
# 如何将同一章节的所有内容合并到一个txt文档?
# 思路:将同一章节获取到的每部分的内容都保存在同一个文件夹(以当前时间命名)中
# 再将该文件夹中的所有txt文档合并该文件夹的上一级文件夹中以该章节名进行命名的txt文档中
# 最后删除这些文件夹(以当前时间命名)
r = requests.get(cur_url)
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="section-opt m-bottom-opt"]//a[text()="下一页"]/@href')
content = html.xpath('//div[@class="container"]//div[@class="content"]/text()')
# 去掉小说内容中的特殊字符
content = "".join(content).replace('\xa0','\n').strip()
# 将章节的标题的特殊字符进行去除
title = html.xpath('//h1[@class="title"]/text()')[0]
title = clean_filename(title)
# 下载小说内容
with open(f'{source_folder}/{title}.txt', 'a',encoding='utf-8') as f:
f.write(title+'\n\n')
f.write(content+'\n\n')
print(f'{threading.current_thread().name}已完成...{title}的下载')
# 如果下一页的链接不存在,则跳出。也就是该章节的所有部分均已下载完毕!
if len(next_page) == 0:
break
# 获取下一页的内容
next_page = regular_link + next_page[0]
cur_url = next_page
# 将同一章节中的内容合并到一个txt文档中
target_folder = "C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说"
# 指定合并后的文件名(确保该文件不存在于temp文件夹内,避免被删除)
combined_file_path = os.path.join(target_folder, f'{file_name}.txt')
# 确保目标文件夹存在
os.makedirs(target_folder, exist_ok=True)
# 遍历文件夹中的所有.txt文件
with open(combined_file_path, 'w', encoding='utf-8') as combined_file:
for filename in os.listdir(source_folder):
file_path = os.path.join(source_folder, filename)
# 如果是文件且后缀是.txt就进行处理
if os.path.isfile(file_path) and filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as file:
combined_file.write(file.read() + '\n') # 将内容写入合并的文件
os.remove(file_path) # 删除已经合并的文件
# 删除子文件夹
def move_off():
parent_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 检查文件夹是否存在
if os.path.exists(parent_folder_path):
# 遍历该文件夹
for entry in os.listdir(parent_folder_path):
# 构建完整的文件/文件夹路径
full_path = os.path.join(parent_folder_path, entry)
# 检查这个路径是否是一个文件夹
if os.path.isdir(full_path):
# 删除文件夹
shutil.rmtree(full_path)
print(f"子文件夹 '{full_path}' 已被删除。")
else:
print(f"父文件夹 '{parent_folder_path}' 不存在。")
def combine_file():
# 指定源文件夹路径
source_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 指定目标文件夹路径
target_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说/nba开局一张三分体验卡' # 你要移动到的新文件夹路径
# 检查目标文件夹是否存在,如果不存在,则创建它
if not os.path.exists(target_folder_path):
os.makedirs(target_folder_path)
# 遍历源文件夹
for entry in os.listdir(source_folder_path):
# 检查文件扩展名是否为.txt
if entry.lower().endswith('.txt'):
# 构建完整的文件路径
full_file_path = os.path.join(source_folder_path, entry)
# 构建目标文件路径
target_file_path = os.path.join(target_folder_path, entry)
# 移动文件
shutil.move(full_file_path, target_file_path)
# 输出完成的消息
print(f"所有的.txt文件已经从'{source_folder_path}'移动到'{target_folder_path}'。")
# 主线程
def main():
# th1是获取链接
index_url = 'https://www.shuangliusc.com/html/555664/'
q = Queue(maxsize=2500)
p = Queue(maxsize=2500)
th1 = threading.Thread(target=gen_urls, args=(index_url, q, p))
th1.start()
threads = [th1]
# th2是下载小说,采取循环的方式,一共有20个线程执行下载小说
for i in range(20):
th2 = threading.Thread(target=download_file,args=(q, p),name=f"线程{i}")
th2.start()
threads.append(th2)
# 等待上面所有的线程完成
for thread in threads:
thread.join()
# 以上所有线程完成后调用move_off,此处可以不用线程,直接调用函数也可,但速度太慢。
# 注:此处由于使用的是多线程操作,存在多个线程对一个文件夹进行操作,以至于报错,但不影响最后需要的结果
# 报错是因为一个文件夹已经被一个线程操作完了,而另一个线程也想对其操作但找不到该文件夹,以至于报错。
threads2 = []
for i in range(10):
th3 = threading.Thread(target=move_off)
th3.start()
threads2.append(th3)
for thread in threads2:
thread.join()
# 所有线程完成后,执行combine_file函数
combine_file()
if __name__ == '__main__':
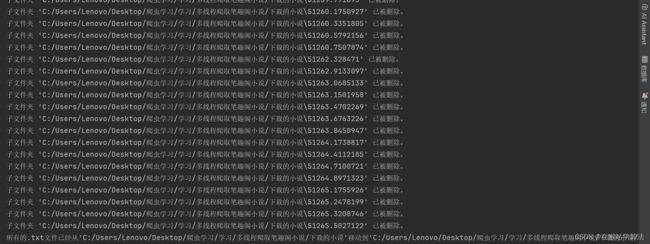
main()部分运行结果截图:


三、后言
1、报错情况
因为此处采取的是多线程下载,容易出现多个线程对一个任务的操作。一旦某个进程完成了对该任务的操作,该任务资源将会得到释放,则其他线程会因找不到对该操作的资源而进行报错。在运行过程中经常会看到报错情况,但这个是不要紧的,它不影响最终结果。这是由于代码没有进行更深一步的优化而引起的原因。
2、线程不是越多越好
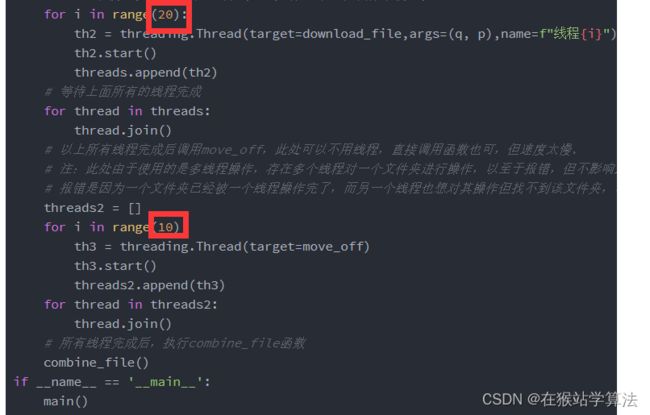
采取多线程会加快下载速度,但也不是线程越多越好。这要看个人电脑的CPU来决定线程的数量。一旦线程加多了,CPU因运转不够来而导致宕机,那就得不偿失了。本人是小新系列的轻薄本,采用了30个线程就已经快跑到了CPU的极限了!请读者自己测试一下自己的电脑可以跑多少个线程而不会加重CPU的负担,找到一个合适的值!!!
如何增加减少线程数量? 只需要修改一下所框选的数字即可!!!
3、想要下载自己喜欢的小说
需要进行以下操作:
- 找到自己喜欢的小说的目录页(不太情况的,可以看上面的截图)
- 将代码中的index_url改成你喜欢的小说的目录页
- 抓包分析一下,所需要的部分是否可以用以上的xPath提取到。不可以的话,进行修改
- 将文件的路径进行修改
4、如何快速调试代码
由于下载的小说《NBA:开局一张三分体验卡》有2300多章,想要快速验证调试代码是否存在问题。可以将以下部分进行修改:不选择下载2300多章,自己定义想要下载多少章。

5、建议
在所有代码中,可以实现下载整本小说的所有章节。但由于章节数量过多,在下载线程跑完后,卡死在了删除多余的文件夹的多线程和移动txt文档的的函数中。如果要实现小数量(大约500章)可以快速的完成,但要实现大数量的下载,建议采取两个Python文件进行运行,一个跑下载小说,一个跑文件操作。当运行小说下载的Python程序完毕后,再运行文件操作的Python!!!
下载小说的Python文件
import os
import pprint
import queue
import re
import shutil
import string
import threading
import time
import requests
from lxml import etree
from queue import Queue
import os
from datetime import datetime
lock = threading.Lock()
# 固定链接
regular_link = 'https://www.shuangliusc.com'
gen_urls_done = False
# 清洗文件名
def clean_filename(filename):
# 以下正则表达式匹配有效的文件名字符,包括中文、英文、数字以及“-_(). ”
# 可以继续加入任何其他可接受的字符
pattern = re.compile(r'[^a-zA-Z0-9\u4e00-\u9fa5\-\_\.\(\)\s]')
cleaned_filename = re.sub(pattern, '', filename)
return cleaned_filename
# 1、获取目录页中的各个目录的链接
# 需要小说目录的链接和一个装各个目录的链接的队列
def gen_urls(index_url, q,p):
# 装入全局变量
global gen_urls_done
r = requests.get(url=index_url)
# 获取目录页的各个目录及其标题
html = etree.HTML(r.text)
links = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/@href')
titles = html.xpath('//div[@class="section-box"]//ul[@id="section-list"]//a/text()')
# 将标题装入一个队列中
for title in titles:
p.put(title)
# 将链接装入队列,为了下载时可以保持顺序,不会乱章
for link in links:
link = regular_link + link
q.put(link)
# 所有链接都已获取完毕并装入队列中
gen_urls_done = True
# 下载该章节
# 传入下载链接和章节名称的队列,以及下载路径
def download_file(q,p):
while True:
# 链接队列为空且gen_urls_done为真时,下载完成
if q.empty() and gen_urls_done:
print("小说已全部下载完成...")
break
else:
# 获取队列的第一个链接和标题
cur_url = q.get()
file_name = p.get()
# 清洗文件名
file_name = clean_filename(file_name)
# 采取当前时间作为文件夹保存同一章节下载的小说内容
# 设置源文件夹和目标文件夹
# 定义父文件夹路径
base_folder = r'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 获取当前时间
now = time.perf_counter()
# 格式化时间字符串,例如 "2024-02-11_031559"
folder_name = str(now)
# 根据需求更改路径,这里使用之前定义的父文件夹路径
source_folder = os.path.join(base_folder, folder_name)
# 创建文件夹
try:
# 使用exist_ok=True避免目录已存在的异常
os.makedirs(source_folder, exist_ok=True)
except Exception as e:
print(f"文件创建错误: {e}")
# 将同一章节的小说内容和标题全都下载到一个txt文档中
while True:
# 获取具体章节的小说内容和标题,并将其放入一个txt文档中
# 如何将同一章节的所有内容合并到一个txt文档?
# 思路:将同一章节获取到的每部分的内容都保存在同一个文件夹(以当前时间命名)中
# 再将该文件夹中的所有txt文档合并该文件夹的上一级文件夹中以该章节名进行命名的txt文档中
# 最后删除这些文件夹(以当前时间命名)
r = requests.get(cur_url)
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="section-opt m-bottom-opt"]//a[text()="下一页"]/@href')
content = html.xpath('//div[@class="container"]//div[@class="content"]/text()')
# 去掉小说内容中的特殊字符
content = "".join(content).replace('\xa0','\n').strip()
# 将章节的标题的特殊字符进行去除
title = html.xpath('//h1[@class="title"]/text()')[0]
title = clean_filename(title)
# 下载小说内容
with open(f'{source_folder}/{title}.txt', 'a',encoding='utf-8') as f:
f.write(title+'\n\n')
f.write(content+'\n\n')
print(f'{threading.current_thread().name}已完成...{title}的下载')
# 如果下一页的链接不存在,则跳出。也就是该章节的所有部分均已下载完毕!
if len(next_page) == 0:
break
# 获取下一页的内容
next_page = regular_link + next_page[0]
cur_url = next_page
# 将同一章节中的内容合并到一个txt文档中
target_folder = "C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说"
# 指定合并后的文件名(确保该文件不存在于temp文件夹内,避免被删除)
combined_file_path = os.path.join(target_folder, f'{file_name}.txt')
# 确保目标文件夹存在
os.makedirs(target_folder, exist_ok=True)
# 遍历文件夹中的所有.txt文件
with open(combined_file_path, 'w', encoding='utf-8') as combined_file:
for filename in os.listdir(source_folder):
file_path = os.path.join(source_folder, filename)
# 如果是文件且后缀是.txt就进行处理
if os.path.isfile(file_path) and filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as file:
combined_file.write(file.read() + '\n') # 将内容写入合并的文件
os.remove(file_path) # 删除已经合并的文件
# 主线程
def main():
# th1是获取链接
index_url = 'https://www.shuangliusc.com/html/555664/'
q = Queue(maxsize=2500)
p = Queue(maxsize=2500)
th1 = threading.Thread(target=gen_urls, args=(index_url, q, p))
th1.start()
# th2是下载小说,采取循环的方式,一共有20个线程执行下载小说
for i in range(20):
th2 = threading.Thread(target=download_file,args=(q, p),name=f"线程{i}")
th2.start()
if __name__ == '__main__':
main()进行文件操作的Python程序
import shutil
import threading
import time
import requests
from lxml import etree
from queue import Queue
import os
def move_off():
parent_folder_path = "C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说"
# 检查文件夹是否存在
if os.path.exists(parent_folder_path):
# 遍历该文件夹
for entry in os.listdir(parent_folder_path):
# 构建完整的文件/文件夹路径
full_path = os.path.join(parent_folder_path, entry)
# 检查这个路径是否是一个文件夹
if os.path.isdir(full_path):
# 删除文件夹
shutil.rmtree(full_path)
print(f"子文件夹 '{full_path}' 已被删除。")
else:
print(f"父文件夹 '{parent_folder_path}' 不存在。")
def combine_file():
# 指定源文件夹路径
source_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说'
# 指定目标文件夹路径
target_folder_path = 'C:/Users/Lenovo/Desktop/爬虫学习/学习/多线程爬取笔趣阁小说/下载的小说/nba开局一张三分体验卡' # 你要移动到的新文件夹路径
# 检查目标文件夹是否存在,如果不存在,则创建它
if not os.path.exists(target_folder_path):
os.makedirs(target_folder_path)
# 遍历源文件夹
for entry in os.listdir(source_folder_path):
# 检查文件扩展名是否为.txt
if entry.lower().endswith('.txt'):
# 构建完整的文件路径
full_file_path = os.path.join(source_folder_path, entry)
# 构建目标文件路径
target_file_path = os.path.join(target_folder_path, entry)
# 移动文件
shutil.move(full_file_path, target_file_path)
# 输出完成的消息
print(f"所有的.txt文件已经从'{source_folder_path}'移动到'{target_folder_path}'。")
# 主线程
def main():
threads2 = []
for i in range(20):
th3 = threading.Thread(target=move_off)
th3.start()
threads2.append(th3)
for thread in threads2:
thread.join()
# 所有线程完成后,执行combine_file函数
combine_file()
if __name__ == '__main__':
main()注:本帖用于学习交流,禁止商用!!!