大模型实战营第二期——3. 基于 InternLM 和 LangChain 搭建你的知识库
- github地址:InternLM/tutorial-书生·浦语大模型实战营
- 文档地址:基于 InternLM 和 LangChain 搭建你的知识库
- 视频地址:基于 InternLM 和 LangChain 搭建你的知识库
- Intern Studio: https://studio.intern-ai.org.cn/console/instance
- 动手学大模型应用开发
文章目录
- 1. 大模型开发范式
- 2. LangChain
- 3. 构建向量数据库
- 4. 搭建知识库助手
- 5. Web Demo部署
- 6. 实际操作
-
- 6.1 环境配置
- 6.2 词向量模型配置
- 6.3 项目代码
-
- 6.3.1 知识库构建(语料库向量持久化)
- 6.3.2 InternLM 接入 LangChain并运行
1. 大模型开发范式


- 时效性问题,23年训练的模型,问24年相关的内容,就无法回答

- 检索增强生成(Retrieval-Augmented Generation, RAG)技术
- 高级检索增强生成技术(RAG)全面指南:原理、分块、编码、索引、微调、Agent、展望
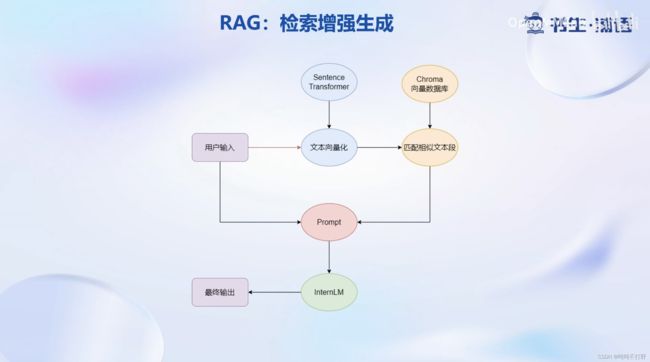
- 这部分内容的话,如果接触过知识图谱,或者基于知识图谱的问答系统,其实就很容易理解了
- 所以chatGPT这类的应用,首先是一个问答系统,只是所用的模型是大模型,也可以像之前的问答系统一样接入知识图谱。
2. LangChain


LangChain可以做很多大模型相关的事情,这里我们侧重使用的是使用LangChain进行RAG开发范式的实现。
- langchain-ai/langchain
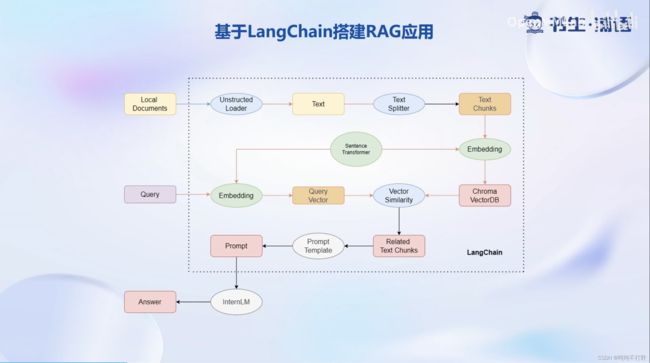
3. 构建向量数据库

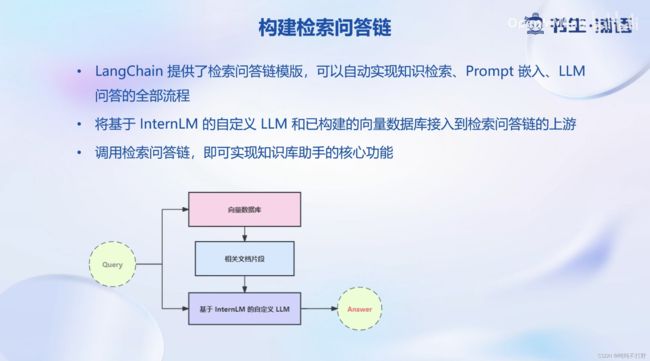
4. 搭建知识库助手



5. Web Demo部署

6. 实际操作
和大模型实战营第二期——2. 浦语大模型趣味Demo中一样,
6.1 环境配置
这里发现:

之前创建过的环境也都还在,因为默认用户操作的目录就是在root目录下,而且root内存给了56GB。。。真大方
bash
conda info -e
> base * /root/.conda
internlm-demo /root/.conda/envs/internlm-demo
# 如果之前没创建过环境,就重新搞一下
/root/share/install_conda_env_internlm_base.sh InternLM
conda activate InternLM
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
# 复制模型
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b
# langchain,以及向量数据库chromadb 还有gradio的web部署
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
6.2 词向量模型配置
另外,用到的词向量模型是Sentence Transformer开源词向量模型 ,也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,也可以自由尝试别的开源词向量模型。
pip install -U huggingface_hub
在/root/data 目录下新建python文件 download_hf.py,填入以下代码
import os
# 如果下载网速不行的话,可以设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')
如果是linux系统的话,其实可以直接在命令行执行:
# 1. 设置环境变量
export HF_ENDPOINT = https://hf-mirror.com
# 2.下载模型
huggingface-cli download \
--resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir \
/root/data/model/sentence-transformer
另外,在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。
# 直接下面的命令全部复制,回车一次即可,linux里会自动分步执行的
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
之后使用时服务器即会自动使用已有资源,无需再次下载。
6.3 项目代码
cd /root/data
git clone https://github.com/InternLM/tutorial
相关的代码都在langchain/demo文件夹中,感兴趣的可以自己看一下
~/data$ tree -L 1 ./tutorial/langchain/demo
./tutorial/langchain/demo
├── LLM.py
├── create_db.py
├── readme.md
└── run_gradio.py
0 directories, 4 files
6.3.1 知识库构建(语料库向量持久化)
demo所使用的数据考虑到版权等问题,选择由上海人工智能实验室开源的一系列大模型工具开源仓库作为语料库来源,包括:opencompass,lmdeploy,xtuner等
# 进入到数据库盘
cd /root/data
# clone 上述开源仓库
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git
- 为了处理方便,只使用这些仓库中的
.md和.txt文件作为语料来源 - 注意,也可以选用其中的代码文件加入到知识库中,但需要针对代码文件格式进行额外处理(因为代码文件对逻辑联系要求较高,且规范性较强,在分割时最好基于代码模块进行分割再加入向量数据库)。
所提供的语料处理脚本其实就是/tutorial/langchain/demo中的create_db.py脚本,直接运行即可
# 基本都是在data目录下运行的
/root/data $python tutorial/langchain/demo/create_db.py
>100%|████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [00:17<00:00, 1.44it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████| 9/9 [00:00<00:00, 23.32it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████| 18/18 [00:00<00:00, 46.71it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████| 72/72 [00:02<00:00, 29.10it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████| 130/130 [00:05<00:00, 22.66it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████| 38/38 [00:01<00:00, 21.35it/s]
# 运行完之后,就可以看到持久化之后的chroma向量数据库的内容了
$tree ./data_base/
./data_base/
└── vector_db
└── chroma
├── chroma.sqlite3
└── ee6d3440-6656-4224-94b8-c8d362de2f22
├── data_level0.bin
├── header.bin
├── index_metadata.pickle
├── length.bin
└── link_lists.bin
3 directories, 6 files
6.3.2 InternLM 接入 LangChain并运行
为便捷构建 LLM 应用,我们需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM LLM 子类,从而实现将 InternLM 接入到 LangChain 框架中。完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
脚本也是位于demo文件夹中,可以
python /root/data/tutorial/langchain/demo/run_gradio.py
直接通过 python 命令运行,即可在本地启动知识库助手的 Web Demo,默认会在 7860 端口运行,接下来将服务器端口映射到本地端口即可访问。
注意:如果想不配置端口直接访问,去vscode的终端里运行,而不是用jupyter的终端工具
页面还是乱码。。。这个端口转发可能还是有点问题