leetcode题目记录
文章目录
- 单调栈
-
- [127. 单词接龙](https://leetcode.cn/problems/word-ladder/)
- [139. 单词拆分](https://leetcode.cn/problems/word-break/)
- [15. 三数之和](https://leetcode.cn/problems/3sum/)
- [140. 单词拆分 II](https://leetcode.cn/problems/word-break-ii/)
- [113. 路径总和 II](https://leetcode.cn/problems/path-sum-ii/)
- [437. 路径总和 III](https://leetcode.cn/problems/path-sum-iii/)
- ListNode题目
-
- [24. 两两交换链表中的节点](https://leetcode.cn/problems/swap-nodes-in-pairs/)
- [25. K 个一组翻转链表](https://leetcode.cn/problems/reverse-nodes-in-k-group/)
- **[148. 排序链表](https://leetcode.cn/problems/sort-list/)**
- **[23. 合并 K 个升序链表](https://leetcode.cn/problems/merge-k-sorted-lists/)**
- **[105. 从前序与中序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)**
- **[131. 分割回文串](https://leetcode.cn/problems/palindrome-partitioning/)**
-
- [34. 加油站](https://leetcode.cn/problems/gas-station/)
- [135. 分发糖果](https://leetcode.cn/problems/candy/)
- [25. K 个一组翻转链表](https://leetcode.cn/problems/reverse-nodes-in-k-group/)
- [121. 买卖股票的最佳时机](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/)
- [122. 买卖股票的最佳时机 II](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/)
- 123
- [42. 接雨水](https://leetcode.cn/problems/trapping-rain-water/)
- [300. 最长递增子序列](https://leetcode.cn/problems/longest-increasing-subsequence/)
- [128. 最长连续序列](https://leetcode.cn/problems/longest-consecutive-sequence/)
- Tree的题目
-
- [105. 从前序与中序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
- [129. 求根节点到叶节点数字之和](https://leetcode.cn/problems/sum-root-to-leaf-numbers/)
- [56. 合并区间](https://leetcode.cn/problems/merge-intervals/)
- [725. 分隔链表](https://leetcode.cn/problems/split-linked-list-in-parts/)
- [32. 最长有效括号](https://leetcode.cn/problems/longest-valid-parentheses/)
- [394. 字符串解码](https://leetcode.cn/problems/decode-string/)
- [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/)
- [124. 二叉树中的最大路径和](https://leetcode.cn/problems/binary-tree-maximum-path-sum/)
- 实现题(二分)
-
- [50. Pow(x, n)](https://leetcode.cn/problems/powx-n/)
- 安排会议室
- [341. 扁平化嵌套列表迭代器](https://leetcode.cn/problems/flatten-nested-list-iterator/)
- 多线程
- Two pointer
-
- [1438. 绝对差不超过限制的最长连续子数组](https://leetcode.cn/problems/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit/)
- [945. 使数组唯一的最小增量](https://leetcode.cn/problems/minimum-increment-to-make-array-unique/)
- [274. H 指数](https://leetcode.cn/problems/h-index/)
- [13. 罗马数字转整数](https://leetcode.cn/problems/roman-to-integer/)
- [6. Z 字形变换](https://leetcode.cn/problems/zigzag-conversion/)
单调栈
单调栈模板
127. 单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:0
解释:endWord "cog" 不在字典中,所以无法进行转换。
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
if(!wordList.contains(endWord)){
return 0;
}
Set<String> dict = new HashSet<>();
for (String s : wordList) {
dict.add(s);
}
int size = 0;
Queue<String> queue = new LinkedList<>();
queue.offer(beginWord);
while (!queue.isEmpty()) {
size++;
int currentSize = queue.size();
for (int i = 0; i < currentSize; i++) {
String currWord = queue.poll();
if (currWord.equals(endWord)) {
return size;
}
StringBuilder sb = new StringBuilder(currWord);
for(int j =0;j<currWord.length();j++){
for(char c='a';c<='z';c++){
if (c == currWord.charAt(j)) {
continue;
}
sb.setCharAt(j, c);
if (dict.contains(sb.toString())) {
queue.offer(sb.toString());
dict.remove(sb.toString());
}
}
sb.setCharAt(j, currWord.charAt(j));
}
}
}
return 0;
}
}
139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
**注意:**不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
思路:
我们需要记忆当前数组下表的一个状态,dp[i] =true。代表到当前的字符串,是可以在wordDict 着找到的。
然后我们去判断下一个 dp[i] =true。然后i到j之间 如果也是在dict中。那么我们dp[j] =true。递推公式。
dp[n+1] dp[1】代表当前第一个字母。 dp[n]代表最后一个
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
boolean[]dp=new boolean[s.length()+1];
dp[0]=true;
for(int i=1;i<=s.length();i++){
for(int j=0;j<i;j++){
if(dp[j] && wordDict.contains(s.substring(j, i))){
dp[i]=true;
break;
}
}
}
return dp[s.length()];
}
}
15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。
示例 3:
输入:nums = [0,0,0]
输出:[[0,0,0]]
解释:唯一可能的三元组和为 0 。
思路:3个,我们先固定其中一个,然后去用寻找2个元素等于target的思路。思路很清晰:
问题难点:在于去重。同一个target我们只寻找一次。排序好的,所以 num[i]==num[i-1] 应该过滤。然后就是我们寻找到一个解的时候。这个时候, 我们应该继续往下找。这个时候也是,如果下一个,等于,也应该过滤。-2,0,0,2,2。
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
if(nums.length<=2){
return res;
}
Arrays.sort(nums);
for(int left=0;left<nums.length&&nums[left]<=0;left++){
if (left > 0 && nums[left] == nums[left - 1]) { //重复的元素,我们不需要重复寻找。
continue;
}
int mid = left+1;int right = nums.length-1;
int temp = 0 - nums[left];
while (mid < right) {
if (nums[mid] + nums[right] == temp) {
int tempMid = nums[mid];
int tempRight = nums[right];
res.add(Arrays.asList(nums[left], nums[mid], nums[right]));
while (mid<right&&nums[++mid]==tempMid); //为了去重。 比如-2,0,0,2,2。我们已经寻找到1个解。这个时候,如果下一个还相等,我们应该跳过。
while (mid<right&&nums[--right]==tempRight);
} else if (nums[mid] + nums[right] < temp) {
mid++;
}else{
right--;
}
}
}
return res;
}
}
140. 单词拆分 II
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
**注意:**词典中的同一个单词可能在分段中被重复使用多次。
示例 1:
输入:s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"]
输出:["cats and dog","cat sand dog"]
示例 2:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"]
输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
输出:[]
提示:
1 <= s.length <= 201 <= wordDict.length <= 10001 <= wordDict[i].length <= 10s和wordDict[i]仅有小写英文字母组成wordDict中所有字符串都 不同
class Solution {
public List wordBreak(String s, List wordDict) {
Set set = new HashSet<>(wordDict);
List ans = new ArrayList<>();
dfs(s, ans, 0, new LinkedList<>(), set);
return ans;
}
public void dfs(String s, List ans, int idx, Deque path, Set set) {
if (idx == s.length()) {
ans.add(String.join(" ", path));
return;
}
for (int i = idx; i < s.length(); i++) {
String str = s.substring(idx, i + 1);
if (set.contains(str)) {
path.add(str);
dfs(s, ans, i + 1, path, set);
path.removeLast();
}
}
}
}
113. 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
示例 2:
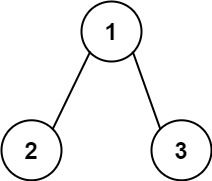
输入:root = [1,2,3], targetSum = 5
输出:[]
示例 3:
输入:root = [1,2], targetSum = 0
输出:[]
List> res=new ArrayList();
public List> pathSum(TreeNode root, int targetSum) {
dfs(root,targetSum,new ArrayList());
return res;
}
public void dfs(TreeNode root,int targetSum,List temp){
if(root==null){
return;
}
temp.add(root.val);
if(root.left==null&&root.right==null&&root.val==targetSum){
res.add(new ArrayList(temp));
}else{
dfs(root.left,targetSum-root.val,temp);
dfs(root.right,targetSum-root.val,temp);
}
temp.remove(temp.size()-1);
}
437. 路径总和 III
已解答
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:

输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
输出:3
解释:和等于 8 的路径有 3 条,如图所示。
示例 2:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:3
class Solution {
public int pathSum(TreeNode root, int targetSum) {
if (root == null) {
return 0;
}
int ret = rootSum(root, targetSum);
ret += pathSum(root.left, targetSum);
ret += pathSum(root.right, targetSum);
return ret;
return rootSum(root,targetSum)+ pathSu
}
public int rootSum(TreeNode root, int targetSum) {
int ret = 0;
if (root == null) {
return 0;
}
int val = root.val;
if (val == targetSum) {
ret++;
}
ret += rootSum(root.left, targetSum - val);
ret += rootSum(root.right, targetSum - val);
return ret;
}
}
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
思路:自定义一个类,使用双向链表。只有这样,删除尾部元素的复杂度是O(1)。自定义一个类。双向链表类。LRUcache,需要有一个属性size。代表当前lru已经存在的元素数量。
put操作
key 存在。更新缓存。node.val= val; delete node; addToHead(node);
key 不存在。判断当前size。如果大于。找到队列尾部的元素,deleteNode,size–; cache 移除key。
然后生成当前新的node,put,size++;get
如果元素存在,删除当前元素(delete Node)。然后把这个元素重新放到对头(addToHead)。
public class LRUCache {
//双链表 从左往右使用减少
class DLinkedNode{
int key, val;
DLinkedNode pre;
DLinkedNode next;
public DLinkedNode(){}
public DLinkedNode(int _key, int _val) {
this.key = _key;
this.val = _val;
}
}
DLinkedNode tail, head; //双链表头指针和尾部指针
HashMap<Integer, DLinkedNode> cache = new HashMap<>();
int size; //当前元素数量
int capacity; //容量
//1.初始化
public LRUCache(int _capacity) {
this.capacity = _capacity;
this.size = 0;
tail = new DLinkedNode();
head = new DLinkedNode();
head.next = tail;
tail.pre = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if(node == null){
//不存在key
return -1;
}else {
//使用了该数,更新缓存
deleteNode(node);
addToHead(node);
}
return node.val;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
//如果存在,修改并更新缓存;
if(node != null){
node.val = value;
deleteNode(node);
addToHead(node);
}else {
//不存在
//1.判断容量 达到最大容量,删除最近未使用节点(别忘了cache也要删)
if(size == capacity){
DLinkedNode removeNode = tail.pre;
deleteNode(removeNode);
cache.remove(removeNode.key);
size--;
}
DLinkedNode newNode = new DLinkedNode(key, value);
size++;
addToHead(newNode);
cache.put(key, newNode);
}
}
//删除双链表中的节点
public void deleteNode(DLinkedNode node){
node.pre.next = node.next;
node.next.pre = node.pre;
}
//加入到链表头部
public void addToHead(DLinkedNode node){
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
ListNode题目
24. 两两交换链表中的节点
已解答
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode pre = new ListNode(0);
pre.next = head;
ListNode temp = pre;
while(temp.next != null && temp.next.next != null) {
ListNode start = temp.next;
ListNode end = temp.next.next;
temp.next = end;
start.next = end.next;
end.next = start;
temp = start;
}
return pre.next;
}
}
25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode cur = head;
int len = 0;
while(cur!=null){
len++;
cur = cur.next;
}
cur = head;
ListNode prev = dummy;
int size = len/k;
ListNode next;
for(int i =0;i148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
!https://assets.leetcode.com/uploads/2020/09/14/sort_list_1.jpg
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
!https://assets.leetcode.com/uploads/2020/09/14/sort_list_2.jpg
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
if(head == null || head.next == null)return head;
ListNode slow = head;
ListNode fast = head;
while(fast.next != null && fast.next.next != null){
slow = slow.next;
fast = fast.next.next;
}
ListNode mid = slow.next;
slow.next = null;
return merge(sortList(head),sortList(mid));
}
public ListNode merge(ListNode left,ListNode right){
ListNode head = new ListNode(0);
ListNode curr = head;
while(left != null && right != null){
if(left.val <= right.val){
curr.next = left;
left = left.next;
}else{
curr.next = right;
right = right.next;
}
curr = curr.next;
}
if(left != null)
curr.next = left;
else if(right != null)
curr.next = right;
return head.next;
}
}
23. 合并 K 个升序链表
已解答
困难
相关标签
相关企业
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
return merge(lists, 0, lists.length - 1);
}
public ListNode merge(ListNode[]lists,int l,int r){
if(l==r){
return lists[l];
}
if(l>r){
return null;
}
int mid = (l+r)>>1;
return mergeTwoListNode(merge(lists,l,mid),merge(lists,mid+1,r));
}
ListNode mergeTwoListNode(ListNode l1, ListNode l2) {
if (l1 == null) {
return l2;
} else if (l2 == null) {
return l1;
} else if (l1.val < l2.val) {
l1.next = mergeTwoListNode(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoListNode(l1, l2.next);
return l2;
}
}
}
105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一
class Solution {
private Map indexMap;
public TreeNode myBuildTree(int[] preorder, int[] inorder, int preLeft, int preRight, int inLeft, int inRight) {
if (preLeft >preRight ) {
return null;
}
int inRoot = indexMap.get(preorder[preLeft]);
TreeNode root = new TreeNode(preorder[preLeft]);
int leftTreeSize = inRoot - inLeft;
root.left= myBuildTree(preorder,inorder,preLeft+1,preLeft+leftTreeSize,inLeft,inRoot-1);
root.right= myBuildTree(preorder,inorder,preLeft+1+leftTreeSize,preRight,inRoot+1,inRight);
return root;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
int n = preorder.length;
// 构造哈希映射,帮助我们快速定位根节点
indexMap = new HashMap();
for (int i = 0; i < n; i++) {
indexMap.put(inorder[i], i);
}
return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);
}
}
131. 分割回文串
给你一个字符串 s,请你将 **s **分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
输入:s = “aab” 输出:[[“a”,“a”,“b”],[“aa”,“b”]]
class Solution {
public List> partition(String s) {
List> list = new ArrayList<>();
dfs(s,0, new ArrayList(), list);
return list;
}
private void dfs(String s, int start, ArrayList path, List> list) {
if (start == s.length()) {
list.add(new ArrayList<>(path));
return;
}
for (int i = start; i < s.length(); i++) {
String s1 = s.substring(start, i + 1);
if (!isPalindrome(s1)) {
continue;
}
path.add(s1);
dfs(s,i + 1, path, list);
path.remove(path.size() - 1);
}
}
private boolean isPalindrome(String s) {
if (s == null || s.length() <= 1) {
return true;
}
int left = 0;
int right = s.length() - 1;
while (left < right) {
if (s.charAt(left) != s.charAt(right)) {
return false;
}
left++;
right--;
}
return true;
}
}
34. 加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入: gas = [2,3,4], cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
class Solution {
public int canCompleteCircuit(int[] gas, int[] cost) {
int sum = 0;
int min = Integer.MAX_VALUE;
int minIndex = -1;
for(int i = 0; i < gas.length; i++){
sum = sum + gas[i] - cost[i];
if(sum < min && sum < 0){
min = sum;
minIndex = i;
}
}
if(sum < 0) return -1;
return (minIndex + 1 )%gas.length;
}
}
135. 分发糖果
困难
相关标签
相关企业
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
- 每个孩子至少分配到
1个糖果。 - 相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:
输入:ratings = [1,0,2]
输出:5
解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:ratings = [1,2,2]
输出:4
解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
class Solution {
public int candy(int[] ratings) {
int n = ratings.length;
int[] left = new int[n];
for (int i = 0; i < n; i++) {
if (i > 0 && ratings[i] > ratings[i - 1]) {
left[i] = left[i - 1] + 1;
} else {
left[i] = 1;
}
}
int right = 0, ret = 0;
for (int i = n - 1; i >= 0; i--) {
if (i < n - 1 && ratings[i] > ratings[i + 1]) {
right++;
} else {
right = 1;
}
ret += Math.max(left[i], right);
}
return ret;
}
}
25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:

输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
**进阶:**你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
动态规划 0 1背包
dp[i][0】 表示当前没有买 = dp[i-1 0,dp i-1,1 +price[i
dp[i][1 表示当前买入。
class Solution {
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n + 1][2];
dp[0][1] = Integer.MIN_VALUE;
for (int i = 1; i <= n; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i - 1]);
dp[i][1] = Math.max(dp[i - 1][1], -prices[i - 1]);
}
return dp[n][0];
}
}
122. 买卖股票的最佳时机 II
已解答
中等
相关标签
相关企业
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
总利润为 4 。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n + 1][2];
dp[0][1] = Integer.MIN_VALUE;
for (int i = 1; i <= n; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i - 1]);
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i - 1]);
}
return dp[n][0];
}\
123
public int maxProfit(int[] prices) {
int n = prices.length, k = 2;
int[][][] dp = new int[n + 1][k + 1][2];
for (int i = 0; i <= n; i++) dp[i][0][1] = Integer.MIN_VALUE;
for (int i = 0; i <= k; i++) dp[0][i][1] = Integer.MIN_VALUE;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= k; j++) {
dp[i][j][0] = Math.max(dp[i - 1][j][0], dp[i - 1][j][1] + prices[i - 1]);
dp[i][j][1] = Math.max(dp[i - 1][j][1], dp[i - 1][j - 1][0] - prices[i - 1]);
}
}
return dp[n][k][0];
}
42. 接雨水
已解答
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
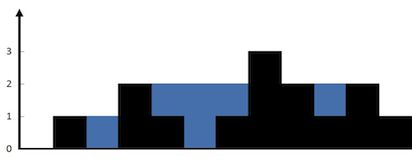
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
class Solution {
public int trap(int[] height) {
/*
方法1:动态规划
统计每个柱子的竖直方向能接多少水
那么该题目就是要找某个柱子左边和右边(不含)的最大值中较小的那个
该短板决定了该柱子上方能装的水的体积
由题目的数据范围得知,该题目必须要以O(N)的方式求出,因此想到动态规划
设left[i]为柱子i左边(不含)的柱子高度的最大值;right[i]为柱子i右边(不含)的柱子高度的最大值
通过递推的方式即可求出两个数组,最后再遍历每个柱子统计即可得到答案
时间复杂度:O(N) 空间复杂度:O(N)
*/
int n = height.length;
if (n <= 2) return 0;
int[] left = new int[n], right = new int[n];
// 这里初始化必须取实际值
left[0] = height[0];
right[n - 1] = height[n - 1];
for (int i = 1; i < n; i++) {
left[i] = Math.max(left[i - 1], height[i]);
// Systm.out.println(left[i]);
}
for (int i = n - 2; i >= 0; i--) {
right[i] = Math.max(right[i + 1], height[i]);
}
int res = 0;
for (int i = 1; i <= n - 2; i++) {
// 短板
System.out.println(right[i]+"_"+left[i]);
int min = Math.min(left[i], right[i]);
if (min > height[i]) res += min - height[i];
}
return res;
}
}
class Solution {
public int trap(int[] height) {
/*
方法2:单调栈
遍历每一个元素,以当前元素为左边界,栈顶元素获取中间高度,栈顶元素下面的元素为右边界
那么我们只需要维护一个非严格单调递增栈(从左到右),然后当遇到大于栈顶元素的元素时候
计算围城的以宽为:right - i + 1 高为:min(height[i], height[right]) - height[mid]的矩形面积
将所有矩形面积累加即可,这其实是统计每个横向夹缝之间的矩形面积
时间复杂度:O(N) 空间复杂度:O(N)
*/
int n = height.length;
if (n <= 2) return 0;
int[] stack = new int[n];
int p = -1;
int res = 0;
for (int i = n - 1; i >= 0; i--) {
// 栈不为空&&当前元素大于栈顶元素
while (p != -1 && height[i] > height[stack[p]]) {
// 栈顶元素出栈,并作为中间的低谷
int mid = stack[p--];
// 栈为空说明右边不存在比height[i]大的元素,结束循环
if (p == -1) break;
// 右边界索引(此时左边界索引为i)
int right = stack[p];
int w = right - i - 1; // 宽度
int h = Math.min(height[i], height[right]) - height[mid]; // 储水高度
res += w * h; // 累加面积
}
// 直至栈为空或者当前元素小于等于栈顶元素,入栈
stack[++p] = i;
}
return res;
}
}
300. 最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4
示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1
class Solution {
public int lengthOfLIS(int[] nums) {
int n=nums.length;
int dp[]=new int[n];
if(nums.length==0){
return 0;
}
Arrays.fill(dp,1);
int max=1;
for(int i=0;inums[j]){
dp[i]=Math.max(dp[i],dp[j]+1);
max=Math.max(max,dp[i]);
}
}
}
return max;
}
}
128. 最长连续序列
已解答
中等
相关标签
相关企业
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
class Solution {
public int longestConsecutive(int[] nums) {
Set set =new HashSet();
for(int num:nums){
set.add(num);
}
int len = 0;
for(int num:nums){
if(!set.contains(num-1)){
int currentNum = num;
int currentLen = 1;
while(set.contains(currentNum+1)){
currentNum+=1;
currentLen+=1;
}
len = Math.max(len,currentLen);
}
}
return len;
}
}
Tree的题目
105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
class Solution {
private Map indexMap;
public TreeNode myBuildTree(int[] preorder, int[] inorder, int preLeft, int preRight, int inLeft, int inRight) {
if (preLeft >preRight ) {
return null;
}
int inRoot = indexMap.get(preorder[preLeft]);
TreeNode root = new TreeNode(preorder[preLeft]);
int leftTreeSize = inRoot - inLeft;
root.left= myBuildTree(preorder,inorder,preLeft+1,preLeft+leftTreeSize,inLeft,inRoot-1);
root.right= myBuildTree(preorder,inorder,preLeft+1+leftTreeSize,preRight,inRoot+1,inRight);
return root;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
int n = preorder.length;
// 构造哈希映射,帮助我们快速定位根节点
indexMap = new HashMap();
for (int i = 0; i < n; i++) {
indexMap.put(inorder[i], i);
}
return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);
}
}
129. 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:

输入:root = [1,2,3]
输出:25
解释:
从根到叶子节点路径 1->2 代表数字 12
从根到叶子节点路径 1->3 代表数字 13
因此,数字总和 = 12 + 13 = 25
示例 2:
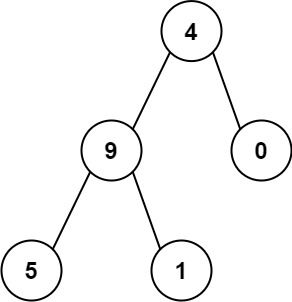
输入:root = [4,9,0,5,1]
输出:1026
解释:
从根到叶子节点路径 4->9->5 代表数字 495
从根到叶子节点路径 4->9->1 代表数字 491
从根到叶子节点路径 4->0 代表数字 40
因此,数字总和 = 495 + 491 + 40 = 1026
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int sumNumbers(TreeNode root) {
i(root==null){
return 0;
}
return dfs(root,0);
}
int dfs(TreeNode root,int sum){
if(root==null){
return 0;
}
int sum1= sum*10+root.val;
if(root.left==null&&root.right==null){
return sum;
}else{
return dfs(root.left,sum1)+dfs(root.right,sum1);
}
}
}
56. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
public int[][] merge(int[][] arr) {
Arrays.sort(arr,new Comparator(){
public int compare(int[]a,int[]b){
return a[0]-b[0];
}
});
int i =0;
int n = arr.length;
Listres = new ArrayList();
while(i=arr[i+1][0]){
right = Math.max(right,arr[i+1][1]);
i++;
}
res.add(new int[]{left,right});
i++;
}
return res.toArray(new int[res.size()][2]);
}
}
725. 分隔链表
给你一个头结点为 head 的单链表和一个整数 k ,请你设计一个算法将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等:任意两部分的长度差距不能超过 1 。这可能会导致有些部分为 null 。
这 k 个部分应该按照在链表中出现的顺序排列,并且排在前面的部分的长度应该大于或等于排在后面的长度。
返回一个由上述 k 部分组成的数组。
难点:对链表的操作
示例 1:

输入:head = [1,2,3], k = 5
输出:[[1],[2],[3],[],[]]
解释:
第一个元素 output[0] 为 output[0].val = 1 ,output[0].next = null 。
最后一个元素 output[4] 为 null ,但它作为 ListNode 的字符串表示是 [] 。
示例 2:

输入:head = [1,2,3,4,5,6,7,8,9,10], k = 3
输出:[[1,2,3,4],[5,6,7],[8,9,10]]
解释:
输入被分成了几个连续的部分,并且每部分的长度相差不超过 1 。前面部分的长度大于等于后面部分的长度。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode[] splitListToParts(ListNode head, int k) {
ListNode cur= head;
int len=0;
while(cur!=null){
len++;
cur = cur.next;
}
int size = len/k;
int remain = len%k;
int index= 0 ;
ListNode[] res = new ListNode[k];
ListNode tmp = head;
while(tmp!=null){
res[index++]=tmp;
ListNode pre= tmp;
for(int i =0;i0){
pre = tmp;
tmp = tmp.next;
remain--;
}
pre.next = null;
}
return res;
}
}
32. 最长有效括号
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
示例 2:
输入:s = ")()())"
输出:4
解释:最长有效括号子串是 "()()"
示例 3:
输入:s = ""
输出:0
class Solution {
public int longestValidParentheses(String s) {
int maxans = 0;
Deque stack = new LinkedList();
stack.push(-1);
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) == '(') {
stack.push(i);
} else {
stack.pop();
if (stack.isEmpty()) {
stack.push(i);
} else {
maxans = Math.max(maxans, i - stack.peek());
}
}
}
return maxans;
}
}
394. 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = "3[a]2[bc]"
输出:"aaabcbc"
示例 2:
输入:s = "3[a2[c]]"
输出:"accaccacc"
示例 3:
输入:s = "2[abc]3[cd]ef"
输出:"abcabccdcdcdef"
示例 4:
输入:s = "abc3[cd]xyz"
输出:"abccdcdcdxyz"
stack实现题目。
class Solution {
public String decodeString(String s) {
Stack stack = new Stack<>();
for(char c : s.toCharArray())
{
if(c != ']')
stack.push(c); // 把所有的字母push进去,除了]
else
{
//step 1: 取出[] 内的字符串
StringBuilder sb = new StringBuilder();
while(!stack.isEmpty() && Character.isLetter(stack.peek()))
sb.insert(0, stack.pop());
String sub = sb.toString(); //[ ]内的字符串
stack.pop(); // 去除[
//step 2: 获取倍数数字
sb = new StringBuilder();
while(!stack.isEmpty() && Character.isDigit(stack.peek()))
sb.insert(0, stack.pop());
int count = Integer.valueOf(sb.toString()); //倍数
//step 3: 根据倍数把字母再push回去
while(count > 0)
{
for(char ch : sub.toCharArray())
stack.push(ch);
count--;
}
}
}
//把栈里面所有的字母取出来,完事L('ω')┘三└('ω')」
StringBuilder retv = new StringBuilder();
while(!stack.isEmpty())
retv.insert(0, stack.pop());
return retv.toString();
}
}
34. 在排序数组中查找元素的第一个和最后一个位置
已解答
中等
相关标签
相关企业
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
class Solution {
public int[] searchRange(int[] nums, int target) {
int[] res = new int[2];
if(nums.length<1){
return res;
}
int l=0;
int r=nums.length-1;
while (ltarget) r= mid-1;
else l=mid;
}
if(nums[l]==target){
res[1] = l;
}else{
res[1] = -1;
}
return res;
}
}
124. 二叉树中的最大路径和
已解答
困难
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:

输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:

输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
实现题(二分)
50. Pow(x, n)
实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn )。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
class solution{
double myPow(double x,int n){
long n1= n;
if(n1<0){
x=1/x;
n= -n;
}
return fastPow(x,n);
}
double fastPow(double x,int n){
if(n==0){
return 1.0;
}
double half = fastPow(x,n/2);
if(n%2==0){
return half*half;
}else{
return half*half*x;
}
}
}
54. 螺旋矩阵 非常经典的一个题目
class Solution {
public List spiralOrder(int[][] matrix) {
int[] dr = {0,1,0,-1};
int[] dc = {1,0,-1,0};
int di = 0;
int size = matrix.length*matrix[0].length;
int m = matrix.length;int n = matrix[0].length;
List res = new ArrayList();
boolean[][] visited = new boolean[m][n];
int x=0;
int y=0;
for(int i =0;i=0&&dy>=0&&dy 安排会议室

class Solution {
public int minMeetingRooms(int[][] intervals) {
if (intervals.length == 0) return 0;
// 最小堆
PriorityQueue allocator = new PriorityQueue(intervals.length, (a, b) -> a - b);
// 对时间表按照开始时间从小到大排序
Arrays.sort(intervals, (a, b) -> a[0] - b[0]);
// 添加第一场会议的结束时间
allocator.add(intervals[0][1]);
// 遍历除第一场之外的所有会议
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] >= allocator.peek()) {
// 如果当前会议的开始时间大于前面已经开始的会议中最晚结束的时间
// 说明有会议室空闲出来了,可以直接重复利用
// 当前时间已经是 intervals[i][0],因此把已经结束的会议删除
allocator.poll();
}
// 把当前会议的结束时间加入最小堆中
allocator.add(intervals[i][1]);
}
// 当所有会议遍历完毕,还在最小堆里面的,说明会议还没结束,此时的数量就是会议室的最少数量
return allocator.size();
}
}
341. 扁平化嵌套列表迭代器
给你一个嵌套的整数列表 nestedList 。每个元素要么是一个整数,要么是一个列表;该列表的元素也可能是整数或者是其他列表。请你实现一个迭代器将其扁平化,使之能够遍历这个列表中的所有整数。
实现扁平迭代器类 NestedIterator :
NestedIterator(List用嵌套列表nestedList) nestedList初始化迭代器。int next()返回嵌套列表的下一个整数。boolean hasNext()如果仍然存在待迭代的整数,返回true;否则,返回false。
你的代码将会用下述伪代码检测:
initialize iterator with nestedList
res = []
while iterator.hasNext()
append iterator.next() to the end of res
return res
如果 res 与预期的扁平化列表匹配,那么你的代码将会被判为正确。
示例 1:
输入:nestedList = [[1,1],2,[1,1]]
输出:[1,1,2,1,1]
解释:通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,1,2,1,1]。
示例 2:
public class NestedIterator implements Iterator {
private List vals;
private Iterator cur;
public NestedIterator(List nestedList) {
vals = new ArrayList();
dfs(nestedList);
cur = vals.iterator();
}
@Override
public Integer next() {
return cur.next();
}
@Override
public boolean hasNext() {
return cur.hasNext();
}
private void dfs(List nestedList) {
for (NestedInteger nest : nestedList) {
if (nest.isInteger()) {
vals.add(nest.getInteger());
} else {
dfs(nest.getList());
}
}
}
}
多线程
1115. 交替打印 FooBar
给你一个类:
class FooBar {
public void foo() {
for (int i = 0; i < n; i++) {
print("foo");
}
}
public void bar() {
for (int i = 0; i < n; i++) {
print("bar");
}
}
}
两个不同的线程将会共用一个 FooBar 实例:
- 线程 A 将会调用
foo()方法,而 - 线程 B 将会调用
bar()方法
请设计修改程序,以确保 "foobar" 被输出 n 次。
class FooBar {
private int n;
private Semaphore fooSema = new Semaphore(1);
private Semaphore barSema = new Semaphore(0);
public FooBar(int n) {
this.n = n;
}
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
fooSema.acquire();//值为1的时候,能拿到,执行下面的操作
printFoo.run();
barSema.release();//释放许可给barSema这个信号量 barSema 的值+1
}
}
Two pointer
1438. 绝对差不超过限制的最长连续子数组
给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit 。
如果不存在满足条件的子数组,则返回 0 。
示例 1:
输入:nums = [8,2,4,7], limit = 4
思路:读懂题意。最长连续子数组的长度。该数组任意二个元素之间的绝对差小于或者等于limit。
这意味着,我们需要维护一个窗口,这个窗口任意2个元素之间的绝对差小于或者等于limit。维护一个元素区间 最大值,最小值。用最大值减去最小值。作为一个更新条件。在一个窗口。还需要保证顺序,我们使用treeMap。
class Solution {
public int longestSubarray(int[] nums, int limit) {
TreeMap<Integer, Integer> map = new TreeMap<Integer, Integer>();
int n = nums.length;
int left = 0, right = 0;
int ret = 0;
while (right < n) {
map.put(nums[right], map.getOrDefault(nums[right], 0) + 1);
while (map.lastKey() - map.firstKey() > limit) {
map.put(nums[left], map.get(nums[left]) - 1);
if (map.get(nums[left]) == 0) {
map.remove(nums[left]);
}
left++;
}
ret = Math.max(ret, right - left + 1);
right++;
}
return ret;
}
}
31. 下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
- 例如,
arr = [1,2,3],以下这些都可以视作arr的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1]。
整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 下一个排列 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
- 例如,
arr = [1,2,3]的下一个排列是[1,3,2]。 - 类似地,
arr = [2,3,1]的下一个排列是[3,1,2]。 - 而
arr = [3,2,1]的下一个排列是[1,2,3],因为[3,2,1]不存在一个字典序更大的排列。
给你一个整数数组 nums ,找出 nums 的下一个排列。
必须** 原地 **修改,只允许使用额外常数空间。
class Solution {
public void nextPermutation(int[] nums) {
int i = nums.length - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
if (i >= 0) {
int j = nums.length - 1;
while (j >= 0 && nums[i] >= nums[j]) {
j--;
}
swap(nums, i, j);
}
reverse(nums, i + 1);
}
public void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
public void reverse(int[] nums, int start) {
int left = start, right = nums.length - 1;
while (left < right) {
swap(nums, left, right);
left++;
right--;
}
}
}
945. 使数组唯一的最小增量
已解答
中等
相关标签
相关企业
给你一个整数数组 nums 。每次 move 操作将会选择任意一个满足 0 <= i < nums.length 的下标 i,并将 nums[i] 递增 1。
返回使 nums 中的每个值都变成唯一的所需要的最少操作次数。
示例 1:
输入:nums = [1,2,2]
输出:1
解释:经过一次 move 操作,数组将变为 [1, 2, 3]。
示例 2:
输入:nums = [3,2,1,2,1,7]
输出:6
解释:经过 6 次 move 操作,数组将变为 [3, 4, 1, 2, 5, 7]。
可以看出 5 次或 5 次以下的 move 操作是不能让数组的每个值唯一的。
class Solution {
public int minIncrementForUnique(int[] nums) {
int minIncrement = 0;
Arrays.sort(nums);
int length = nums.length;
for (int i = 1; i < length; i++) {
int currValue = Math.max(nums[i], nums[i - 1] + 1);
minIncrement += currValue - nums[i];
nums[i] = currValue;
}
return minIncrement;a
}
}
274. H 指数
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
示例 1:
输入:citations = [3,0,6,1,5]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
示例 2:
输入:citations = [1,3,1]
输出:1
class Solution {
public int hIndex(int[] citations) {
Arrays.sort(citations);
int h = 0, i = citations.length - 1;
while (i >= 0 && citations[i] > h) {
h++;
i--;
}
return h;
}
}
13. 罗马数字转整数
问题抽象:
如何模拟。 定义map key是字符,value是对应数值。
IV这种情况。i对应的value 小于i+1对应的value,说明是这种,这个时候应该减去,其他都是加。
从前往后遍历。如果当前字符小于