sql 数据库关系图
There are plenty of articles on the web comparing the traditional characteristics of relational and No-SQL databases. So I won’t repeat them again here. This article is intended to shed light on the catchup game that relational and No-SQL databases are in; learning and implementing some best practices from one another.
网络上有很多文章比较关系数据库和No-SQL数据库的传统特征。 所以我在这里不再重复。 本文旨在阐明关系数据库和No-SQL数据库所在的追赶游戏。 互相学习和实施一些最佳实践。
When relational databases were originally designed in the 1970’s, storage was very expensive. So relational databases were built keeping a single machine in mind and were meant to be used for properly structured data that needed ACID compliance enforced. Again, as storage was expensive, the data was normalized into several tables without any room for redundancy.
当关系数据库最初于1970年代设计时,存储非常昂贵。 因此,建立关系数据库时要牢记一台机器,并应将其用于需要强制执行ACID合规性的结构正确的数据。 同样,由于存储成本很高,因此将数据标准化为几个表,没有任何冗余空间。
As more and more companies went digital in the 2000’s — growing data collection and storage needs — it became clear that relational databases don’t give the necessary flexibility for unstructured or semi-structured data. They don’t scale well under growing demand and were a single point of failure which impacted the availability. In addition, they had slow performance due to data normalization and the added overhead of object to relational data transformation.
随着2000年代越来越多的公司实现数字化(数据收集和存储需求不断增长),很明显,关系数据库不能为非结构化或半结构化数据提供必要的灵活性。 在需求增长的情况下,它们无法很好地扩展,并且是影响可用性的单点故障。 另外,由于数据规范化以及对象到关系数据转换的额外开销,它们的性能较慢。
To address these shortcomings, at a time when storage was becoming cheaper, No-SQL databases started coming to the forefront. They provided the flexibility needed for semi-structured or unstructured data by relaxing ACID compliance and following something called BASE compliance. They also provided tremendous scalability for massive data storage needs by distributing the data on several machines. To enable high availability, they followed “eventual consistency” where availability, even with stale data, is favored over consistency with the most up-to-date data.
为了解决这些缺点,在存储变得便宜的时候,No-SQL数据库开始走在前列。 通过放宽ACID合规性并遵循所谓的BASE合规性,它们为半结构化或非结构化数据提供了所需的灵活性。 它们还通过将数据分布在多台计算机上,为海量数据存储需求提供了巨大的可伸缩性。 为了实现高可用性,他们遵循“最终一致性”,在这种情况下,即使是过时的数据,也要优先考虑可用性,而不是与最新数据保持一致。
However, it took a while for No-SQL databases to gain wide adoption. With their relaxed policies around data structure and eventual consistency, a lot of applications that needed structure and strong consistency did not lend themselves to No-SQL databases. It wasn’t easy for someone with a legacy application, built using relational databases, to port them over to No-SQL. Also, added complexity came with the distributed nature of these databases. The learning curve associated with the wide variety of No-SQL databases meant less tech savvy users weren’t able to explore the breadth of this category and the benefits offered.
但是,No-SQL数据库花了一段时间才被广泛采用。 由于他们放宽了关于数据结构和最终一致性的策略,因此许多需要结构和强一致性的应用程序无法适应No-SQL数据库。 对于具有使用关系数据库构建的遗留应用程序的人来说,将其移植到No-SQL上并不容易。 而且,这些数据库的分布式特性增加了复杂性。 与各种各样的No-SQL数据库相关的学习曲线意味着,精通技术的用户无法探索这一类别的广度以及所提供的好处。
In the last few years, the momentum behind open source databases has really paved the way for the developer community to think about the best practices offered in each database type and put efforts into overcoming some of the shortcomings. In addition, managed cloud solutions have invested a lot in building services to achieve optimal results for scalability, availability, performance, and security; these have made database maintenance and administration easier.
在过去的几年中,开源数据库背后的势头确实为开发人员社区思考每种数据库类型提供的最佳实践铺平了道路,并努力克服了一些缺点。 此外,托管云解决方案在构建服务上投入了大量资金,以实现可扩展性,可用性,性能和安全性的最佳结果。 这些使数据库的维护和管理更加容易。
As a result, some of the criteria that were used to decide when to use relational or a No-SQL database have changed and should be re-verified to see if they still hold true.
结果,用于决定何时使用关系数据库或No-SQL数据库的某些标准已更改,应重新验证以查看它们是否仍然适用。
Below, I will try to clarify some of the myths associated with relational and No-SQL databases.
下面,我将尝试阐明与关系数据库和No-SQL数据库相关的一些神话。
有关关系数据库的神话 (Myths About Relational Databases)
1.关系数据库不提供快速读取性能或扩展能力 (1. Relational databases don’t offer fast read performance or scale)
If you have a read-heavy application, modern relational databases let you set up read replicas with configurations around how the replication would take place (synchronous vs asynchronous). This enables the application’s growing read traffic to get distributed across multiple read replicas through load balancing. The number of read replicas that can be configured varies by the database. Also, scaling compute, memory, and storage have become much easier with managed solutions such as AWS RDS and there is no downtime associated to achieve the scaling.
如果您有一个读取量很大的应用程序,那么现代的关系数据库可让您使用有关复制发生方式(同步与异步)的配置来设置只读副本。 这使应用程序不断增长的读取流量可以通过负载平衡在多个只读副本之间分配。 可以配置的只读副本数量因数据库而异。 而且,借助托管解决方案(例如AWS RDS) ,扩展计算,内存和存储变得更加容易,并且没有停机时间来实现扩展。
The message here is to evaluate your specific use case and determine how many read replicas are needed for your application’s growing demand and what size will be sufficient. Don’t blindly rule out relational databases assuming they don’t scale at all, because they do for reads.
这里的消息是评估您的特定用例,并确定您的应用程序不断增长的需求需要多少个只读副本,以及什么大小就足够了。 不要假定关系数据库根本不扩展就盲目地排除它们,因为它们可以读取。
Note: With asynchronous replication to read replicas, one gets a fast write performance but has to deal with the trade offs associated with eventual read consistency. Synchronous replication would result in immediate consistency but slow down the write performance.
注意:使用异步复制来读取副本时,可以获得快速的写入性能,但必须处理与最终读取一致性相关的折衷。 同步复制将导致立即的一致性,但会降低写入性能。
2.关系数据库的可用性不高 (2. Relational databases are not highly available)
Availability refers to the data being always made available to applications, whenever needed, despite failure conditions or infrastructure disruptions, etc. Availability is often measured by uptime. You have probably heard of the term RTO (Recovery Time Objective) — i.e how long does it take to restore something in case of a disruption. The lesser the RTO, the higher the availability.
可用性是指被随时提供给应用程序,需要时的数据,尽管失败条件或基础设施毁坏等情况往往是由正常运行时间测量。 您可能听说过RTO(恢复时间目标)一词-即在发生故障的情况下恢复某物需要花费多长时间。 RTO越小,可用性越高。
With managed solutions such as AWS RDS, the availability of a relational database has become super high with multi A-Z deployments. In case the primary database goes down, or connectivity to primary fails or the servers/data centers crash, AWS RDS can auto failover to the standby in a different A-Z without the need for applications to make any changes. This process of failover can take up to a couple of minutes (or even less if AWS Aurora is used).
借助AWS RDS之类的托管解决方案,在多可用区部署中,关系数据库的可用性变得非常高。 万一主数据库出现故障,与主数据库的连接失败或服务器/数据中心崩溃,AWS RDS可以自动将故障转移到另一个可用区中的备用数据库,而无需应用程序进行任何更改。 此故障转移过程可能需要花费几分钟(如果使用AWS Aurora,则可能更少)。
For non-cloud solutions, this might involve setting up a primary replica architecture and using solutions to detect the primary failure and failover to the standby (making it the new primary). This failover process could take a few hours.
对于非云解决方案,这可能涉及建立主副本体系结构,并使用解决方案来检测主故障并将故障转移到备用数据库(使其成为新的主数据库)。 此故障转移过程可能需要几个小时。
The message here is to evaluate if that amount of downtime is acceptable for your use case and to not rule out relational databases without that analysis.
此处的信息是评估您的用例是否可以接受该数量的停机时间,并且在不进行分析的情况下不排除关系数据库。
3.关系数据库不支持多种数据类型和结构 (3. Relational databases don’t offer support for a variety of data types and structures)
Traditional relational databases only offered support for certain standard data types such as Integer, String, Boolean, Long, etc. However, databases like PostgreSQL are object relational in nature and give you the ability to represent an object like structure in a database. Data need not be normalized in a traditional relational database style, requiring multiple tables with joins to represent that structure. They also support several data types suited for storing geometric, network address, text search, money, and array type data. You can also define your own custom data type as well. With the support for storing data in JSONB format, PostgreSQL provides flexibility for unstructured data and enables faster data retrieval.
传统的关系数据库仅支持某些标准数据类型,例如Integer,String,Boolean,Long等。但是,像PostgreSQL这样的数据库本质上是对象关系的,使您能够在数据库中表示类似结构的对象。 数据不需要以传统的关系数据库样式进行规范化,而需要使用带有联接的多个表来表示该结构。 它们还支持几种适合存储几何,网络地址,文本搜索,资金和数组类型数据的数据类型。 您还可以定义自己的自定义数据类型。 凭借对以JSONB格式存储数据的支持,PostgreSQL为非结构化数据提供了灵活性,并实现了更快的数据检索。
关于No-SQL数据库的神话 (Myths About No-SQL Databases)
1. No-SQL数据库或非关系数据库不能用于存储实体之间的关系 (1. No-SQL databases or non-relational databases cannot be used for storing relationships between entities)
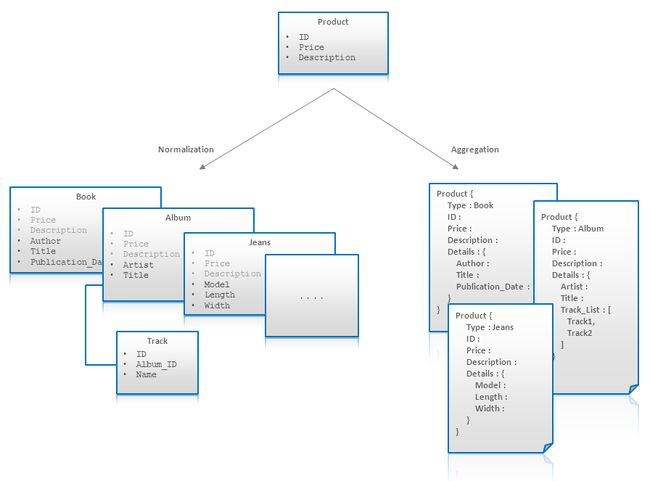
When someone says No-SQL or non-relational databases, it does not mean they don’t or can’t represent relationships between entities. They definitely do, but it doesn’t need to be in a normalized table/column format. In the below example you can see the contrast on how relationships are expressed in a document hierarchical structure.
当有人说No-SQL或非关系数据库时,这并不意味着它们不代表实体之间的关系。 他们当然可以,但是不必采用规范化的表/列格式。 在下面的示例中,您可以看到在文档层次结构中如何表达关系的对比。
Ex: Normalized structure in relational vs hierarchical structure in No-SQL
例如:No-SQL中关系结构与分层结构中的规范化结构
2. No-SQL数据库对于关键的应用程序用例不可靠,因为它们最终是一致的 (2. No-SQL databases are not reliable for critical application use cases because they are eventual consistent)
Originally, No-SQL databases practiced eventual consistency to offer high availability and to have fast write performance. The tradeoffs involved applications accepting the risk of reading stale data for a while and eventually getting caught up or having data loss.
最初,No-SQL数据库通过实践最终的一致性来提供高可用性并具有快速的写入性能。 折衷方案涉及应用程序冒着读取旧数据一段时间的风险,并最终陷入困境或丢失数据。
However, No-SQL databases these days allow you to choose between eventual consistency and strong consistency. You can also configure how many replicas need to acknowledge a transaction before it is committed (commonly called quorum).
但是,如今,No-SQL数据库使您可以在最终一致性和强一致性之间进行选择。 您还可以配置在提交事务之前需要确认多少个副本(通常称为仲裁)。
Ex: Eventual Consistency in No-SQL databases
例如:No-SQL数据库中的最终一致性

3. No-SQL数据库在所有情况下均提供更好的性能 (3. No-SQL databases offer far better performance for all scenarios)
It is generally true that No-SQL databases offer superior read performance because they come custom fit for the structure of your data (key-value, graph, documents, etc).
通常,No-SQL数据库可提供卓越的读取性能,因为它们自定义适合您的数据结构(键值,图形,文档等)。
However, there are a couple of nuances.
但是,有一些细微差别。
a. Database Design: Extracting the best performance is heavily dependent on understanding the commonly used applications data access patterns and then designing the database based on those patterns. A bad database design, despite the right choice of No-SQL database, will not yield good results. Also, if you issue ad hoc queries outside of those standard application access patterns to the No-SQL databases, the performance won’t be ideal.
一个。 数据库设计 :提取最佳性能在很大程度上取决于对常用应用程序数据访问模式的了解,然后根据这些模式设计数据库。 尽管正确选择了No-SQL数据库,但不良的数据库设计不会产生良好的结果。 另外,如果您在对No-SQL数据库的那些标准应用程序访问模式之外发出临时查询,则性能将不是理想的。
b. Sharding: One of the main benefits of using a No-SQL database is how efficiently it can scale to high traffic loads using a distributed architecture technique called sharding, which is also known as a horizontal scaling mechanism. Instead of the traditional approach of increasing CPU/RAM/Disk space for a server (vertical scaling), sharding stores the data in a distributed fashion across several machines. When the traffic goes up, by increasing the number of shards (the number of machines in the cluster), the database adjusts itself to the load automatically. However, one needs to be aware of possible hotspots that can arise by choosing a wrong shard key. Data can get unevenly distributed among the shards and all the load can heavily concentrate on certain shards, not yielding the best performance.
b。 分片 :使用No-SQL数据库的主要好处之一是可以使用称为分片的分布式体系结构技术有效地扩展到高流量负载,该技术也称为水平缩放机制。 分片代替了为服务器增加CPU / RAM /磁盘空间(垂直扩展)的传统方法,而是以分布方式在多台计算机上存储数据。 当流量增加时,通过增加分片(集群中的计算机数量),数据库会自动调整自身以适应负载。 但是,需要注意选择错误的分片密钥可能引起的热点。 数据可能会在各个分片之间分布不均,并且所有负载都可能严重集中在某些分片上,从而无法获得最佳性能。
The message here is using the wrong No-SQL database for your use case or using it incorrectly will not get you positive results. There are specific scenarios for which No-SQL databases offer far better performance, but not for everything.
这里的消息是针对您的用例使用了错误的No-SQL数据库,或者使用不当将不会给您带来积极的结果。 在某些特定情况下,No-SQL数据库可提供更好的性能,但不能提供所有功能。
4.没有SQL数据库只能用于海量数据需求 (4. No SQL databases are only to be used for massive data needs)
While it is true that NO SQL databases are a great choice when your data is getting continuously generated and you have massive storage needs, one should not rule out No-SQL databases when they have smaller data storage needs. With “pay what you use” pricing models in the cloud, you won’t lose anything by picking No-SQL databases for small data footprints.
当确实要连续生成数据并且有大量存储需求时,没有SQL数据库是不错的选择,但是当数据存储需求较小时,不应该排除No-SQL数据库。 借助云中的“按使用付费”定价模型,通过选择No-SQL数据库以减少数据占用量,您将不会损失任何东西。
5.没有SQL意味着没有架构 (5. No SQL means no schema)
No SQL databases give you the flexibility to store unstructured or semi-structured data. However, you can still enforce a schema, if you want to, where it is needed. Databases such as MongoDB, which stores data in a JSON format, let you perform validations using JSON Schema. You can configure if you want those validations to result in accepting or rejecting the documents during inserts or updates, and how they apply to existing documents.
没有SQL数据库可让您灵活地存储非结构化或半结构化数据。 但是,如果需要,您仍然可以在需要的地方实施方案。 诸如MongoDB之类的数据库以JSON格式存储数据,使您可以使用JSON模式执行验证。 您可以配置是否希望这些验证在插入或更新期间导致接受或拒绝文档,以及它们如何应用于现有文档。
As you can see, relational and No-SQL databases have come a long way in overcoming some of their shortcomings and have started to learn from each other. While they are still very different and solve different problems, a lot has changed over time. This convergence across database families should force us to rethink our database choices. Let’s not rule out certain databases based on market popularity or historical comparison of traditional traits. Because that information might not be as relevant in 2020 as it once was.
如您所见,关系数据库和No-SQL数据库在克服它们的某些缺点方面已经走了很长一段路,并且已经开始相互学习。 尽管它们仍然非常不同并且可以解决不同的问题,但是随着时间的流逝,发生了很多变化。 数据库系列之间的这种融合将迫使我们重新考虑数据库的选择。 我们不排除基于市场知名度或传统特征的历史比较的某些数据库。 因为该信息在2020年可能不再像以前那样重要。
Originally published at https://www.capitalone.com.
最初在 https://www.capitalone.com上 发布 。
DISCLOSURE STATEMENT: © 2020 Capital One. Opinions are those of the individual author. Unless noted otherwise in this post, Capital One is not affiliated with, nor endorsed by, any of the companies mentioned. All trademarks and other intellectual property used or displayed are property of their respective owners.
披露声明:©2020 Capital One。 观点是个别作者的观点。 除非本文中另有说明,否则Capital One不与任何提及的公司有附属关系或认可。 使用或显示的所有商标和其他知识产权均为其各自所有者的财产。
翻译自: https://medium.com/capital-one-tech/popular-myths-about-relational-no-sql-databases-explained-60c0e1c3c87a
sql 数据库关系图