完蛋!我把AI喂吐了!
当我们用 RAG 构建一个知识库问答应用的时候,总是希望知识库里面灌的数据越多,问答的效果越好,事实真是如此吗?这篇文章给大家答案。

引言
在人工智能问答系统的发展中,RAG(Retrieval-Augmented Generation)技术以其独特的检索增强生成方式,为减少大模型幻觉开辟了新的天地。然而,在实际落地过程中有一个很大的疑问:RAG 系统,数据越多效果越好吗?本文将深入分析数据量如何影响 RAG 系统的问答效果,并讨论如何优化这一系统以适应不断增长的海量数据。
什么是 RAG?
大型语言模型(LLMs)已经展现出了强大的能力,但在实际应用中仍面临很多挑战,如模型幻觉、知识更新缓慢以及答案缺乏可信度等。LLM 虽然是在非常庞大的数据集上训练的,但并不是在您的数据上训练的。检索增强生成(RAG)通过将您的数据链接到 LLMs 来解决这个问题。
RAG 是一种将知识检索与生成模型相结合的技术,可以提高问答系统的准确性和相关性。它通过从外部知识源中动态检索信息,并将检索到的数据作为参考来组织答案,从而能有效缓解 LLM 中存在的幻觉问题。

RAG 系统
RAG 的工作流程主要包含三个模块:
-
索引(indexing):文本索引的构建包括以下步骤:文档解析、文本分块、Embedding 向量化和创建索引。先将不同格式的原始文件解析转换为纯文本,再把文本切分成较小的文本块。通过 Embedding 为每一个文本块生成一个向量表示,用于计算文本向量和问题向量之间的相似度。创建索引将原始文本块和 Embedding 向量以键值对的形式存储,以便将来进行快速和频繁的搜索。
-
检索(Retrieval):使用 Embedding 模型将用户输入问题转换为向量,计算问题的 Embedding 向量和语料库中文本块 Embedding 向量之间的相似度,选择相似度最高的前 K 个文档块作为当前问题的增强上下文信息。
-
生成(Generation):将检索得到的前 K 个文本块和用户问题一起送进大模型,让大模型基于给定的文本块来回答用户的问题。
有关 RAG 更全面的信息请参阅综述论文:Retrieval-Augmented Generation for Large Language Models: A Survey,不想阅读原始英文论文?使用「有道速读」快速了解什么是 RAG?
RAG 系统:数据越多,效果越好吗?
从宏观层面来看,RAG 包含两个核心的要素:数据和系统。RAG 的应用场景非常多,包括文档助手,智能客服机器人,领域 / 行业知识库问答等。不同的应用场景优化的侧重点可能有所差异。
对于文档助手这类应用来说,数据是已知的,我就上传几篇文档,就针对这些文档来问问题。我们几乎不用关注数据侧的事情,把精力放在优化系统就可以了。
而对于领域 / 行业知识库问答来说,需要从数据侧和系统侧同时优化。因为如果用户问题回答不上来,有可能是没相关数据,也有可能是有数据但 RAG 系统没找到。
数据侧的优化很 “简单”,就是尽可能多的收集领域内相关的数据,通通灌进知识库里面。但是, 请先别着急!在开始组织人力收集整理数据之前,我们首先得弄清楚一件事情:RAG 系统,数据越多,效果越好吗?
如果答案是肯定的,意味着:
-
海量数据放心灌,我可以一批一批地往知识库中加数据,不用担心数据量太大相互干扰导致效果不佳。
-
快速迭代快速优化,对于上线之后的 badcase,业务侧可以直接通过加相应数据来快速迭代优化。
-
降低数据成本,收集和整理的成本,不用费劲心思去做数据去重和脏数据的处理。
-
增加系统的稳定性,如果我加的数据不相关,问答的效果不一定会变好,但是起码能保证以前的效果不会变差。
反之,那工作量可就大了
实验:数据量对于问答效果的影响
以教育领域的知识库问答为例,我们基于 RAG 做了一个升学百科问答的应用,专门解答用户关于高考升学规划和志愿填报政策相关的问题。

升学百科问答
升学百科问答不是给定数据,给定问题,然后只需要去优化算法或者系统的 Benchmark 任务。它的问题是开放的,数据也是开放的(你可以收集到尽可能多的相关数据来提升问答的效果)。所以优化的变量就多了一个:系统是一部分,数据也是一部分。问答效果的好坏不光取决于好的 RAG 系统,还取决于你的数据量够不够,覆盖的知识全不全?如何优化 RAG 能让它完全发挥出海量数据的价值是我们研究的重点。
关于数据量对 RAG 问答质量的影响,我们在升学百科问答项目中做了比较详细的研究。实验设置如下:
-
用户问题:收集了 176 个升学百科相关的问题,包括升学路径、志愿填报、选科等相关政策咨询问题。
-
RAG 系统:一个经典的 RAG 系统,包括文本解析切片,embedding 向量化建库,检索相关片段,语言模型总结问答等模块。
-
领域数据:我们收集了海量升学规划相关的资料来验证数据的问题,包括教育领域的互联网数据,书本资料,FAQ 问答对等。
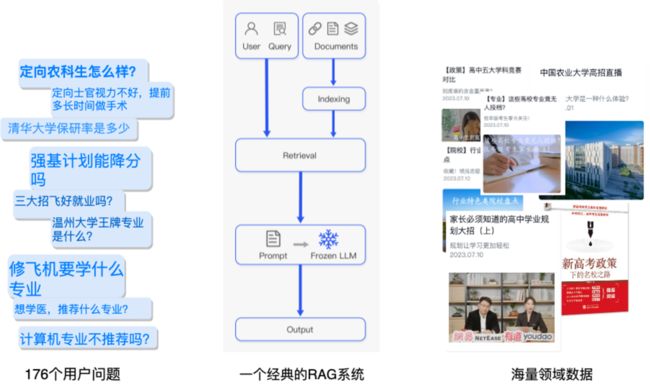
RAG 在升学百科问答中的实践
结果:检索退化问题
我们分批往 RAG 知识库中灌入数据,每加一批数据都做一次评测,观察随着数据量变大,问答效果的变化情况:
-
baseline:第一批数据加入后问答正确率有 42.6%,此时有一些问题没回答上来是因为确实缺少相关资料。我们继续加数据…
-
迎来上涨:第二批加了更多数据,覆盖知识范围更广。准确率提升到了 60.2%,提升非常明显,看来加数据确实还是挺有用的。
-
坏消息:当加入第三批数据的时候,我们最担心的事情还是发生了。正确率急剧下降,跌了将近 8 个百分点。
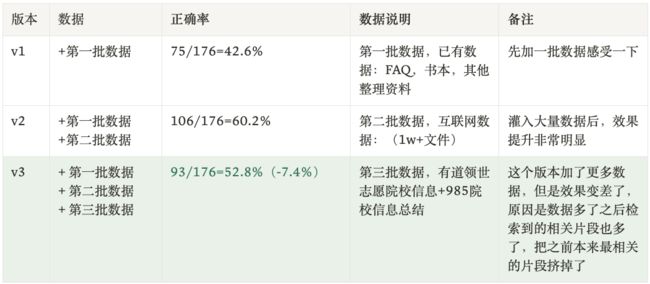
到这里,我们的问题有了答案,不是所的 RAG 系统都能保证:数据越多,效果越好。海量数据有可能会把 AI 喂吐,随着数据的增多,数据之间可能会有相互干扰,导致检索退化的问题,影响问答的质量。
具体问题具体分析
先抓一个典型看看,大连医科大学怎么样?这个问题在 v2 版本(加入第三批数据前)是能回答对的,v3 版本(加入第三批数据后)回答错了。看了一下送到 LLM 的文本片段,居然全部都是大连理工大学相关的信息。

问题分析:大连医科大学的问答结果
主要原因是第三批加入的某些文档中恰好有大连理工大学 xxx 怎么样?的句子,和 query 大连医科大学怎么样?表面上看起来确实非常像,Embedding 给它打了比较高的分。
而类似大连医科大学师资介绍这样的片段相关性就稍微低了些。而 LLM 输入 token 有限制,前面两个最相关但是实际并不能回答 query 问题的片段就已经占满了 token 的窗口,只能把他俩送进 LLM 里。结果可想而知,啥都不知道。
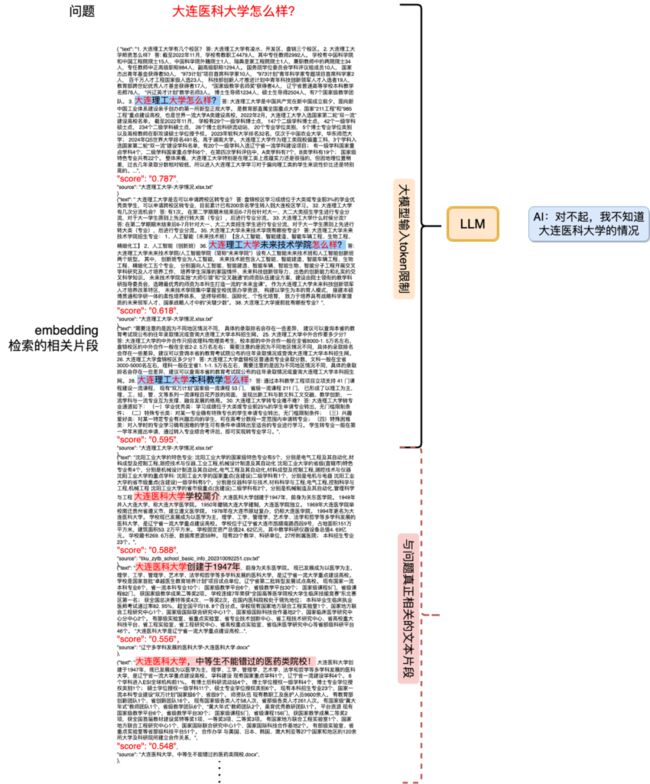
RAG 中的检索退化问题
语义检索:相似≠相关
文本片段与 query 的相似性和文本片段是否包含 query 的答案(相关性)是两回事。RAG 中一个非常重要的矛盾点在于检索召回的片段比较多,但是 LLM 输入 token 是有限制,所以必须把能回答 query 问题的片段(和问题最相关)给 LLM。
Embedding(Bi-Encoder)
Embedding 也可以给出一个得分,但是这个得分描述的更多的是相似性。Embedding 本质上是一个双编码器,两个文本在模型内部没有任何信息交互。只在最后计算两个向量的余弦相似度时才进行唯一一次交互。所以 Embedding 检索只能把最相似的文本片段给你,没有能力来判断候选文本和 query 之间的相关性。但是相似又不等于相关。
如下图所示,从某种程度上,Embedding 其实就是在算两个文本块中相似字符的个数占比,它分不清 query 中的重点是大连医科大学,在它看来每个字符的重要性都是一样的。感兴趣的话可以计算一下下图中红字部分的占比,和最后余弦相似度的得分基本是吻合的。

Embedding 原理
Rerank(Cross-Encoder)
Rerank 本质是一个 Cross-Encoder 的模型。Cross-Encoder 能让两个文本片段一开始就在 BERT 模型各层中通过 self-attention 进行交互。它能够用 self-attention 判断出来这个 query 中的重点在于大连医科大学,而不是怎么样?。所以,如下图所示,大连医科大学怎么样?这个 query 和大连医科大学创建于 1947 年… 更相关。

Rerank 原理
Cross-Encoder 这么好,为什么不直接用?
因为速度慢。这里说的速度慢不是 cross-encoder 的模型比 bi-encoder 的模型速度慢。关键在于 bi-encoder 可以离线计算海量文本块的向量化表示,把他们暂存在向量数据库中,在问答检索的时候只需要计算一个 query 的向量化表示就可以了。拿着 query 的向量表示去库里找最相似的文本即可。
但是 cross-encoder 需要实时计算两个文本块的相关度,如果候选文本有几万条,每一条都需要和 query 一起送进 BERT 模型中算一遍,需要实时算几万次。这个成本是非常巨大的。
所以,我们可以把检索过程分为两个阶段:召回(粗排)和重排。
-
第一个阶段的目标是尽可能多的召回相似的文本片段,这个阶段的文本得分排序不是特别靠谱,所以候选的 topK 可以设置大一些,比如 topK=100;
-
第二个阶段的目标是对 100 个粗排的候选文本片段进行重新排序,用 cross-encoder 计算 100 个候选文本和 query 的相关度得分;
两阶段检索结合可以兼顾效果和效率。
两阶段检索在 RAG 中的实验
我们对上面升学百科中的文本片段用 Rerank 模型再做一次排序,重排序后的结果如下图所示,左右可以对照着看,左边是 Rerank 之前的文本片段,右边是 Rerank 重排之后的文本片段。可以明显看到右边文本片段的得分和排序更加合理,和人的感受基本上是一致的。重排序之后送进 LLM 窗口内的文本和 query 是最相关的,语言模型也能轻松根据相关信息回答出问题,再也不会说不知道了。
两阶段检索在 RAG 中的实验
QAnything:两阶段检索问答框架
QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统。基于有道自研两阶段检索框架,能够做到数据越多,问答效果越好!
QAnything 具有以下特点:
-
数据安全放心用,完全离线使用;
-
跨语种知识随意问,中英文问答随意切换,无所谓文件是什么语种;
-
海量数据放心灌,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好;
-
生产级系统直接装,可直接部署企业级应用;
-
一键安装轻松用,无需繁琐的配置,一键安装部署,拿来就用;
-
多知识库随时切,支持多个知识库联合问答。
-
完全开源,完全免费!

QAnything 系统架构
QAnything 使用的有道自研检索组件 BCEmbedding 有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异。其中包含的 embedding 和 rerank 模型均达到业界 SOTA,详细评测指标请参考:有道 BECEmbedding 模型和 Rerank 模型指标汇总,如果需要单独使用 embedding 和 rerank 组件,点击下面的链接进行下载:
https://github.com/netease-youdao/BCEmbedding
最终结果
至此,我们可以在以上两阶段检索的 QAnything 系统上重新跑前三批数据的实验了。结果如下:
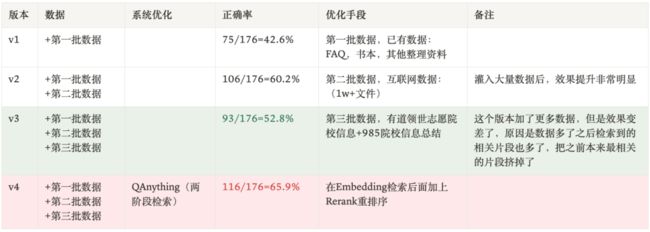
在数据不变的情况,两阶段检索问答准确率从 52.8% 提升到 65.9%,这个结果再次证明了一阶段检索中存在数据互相干扰的情况。两阶段检索可以最大化的挖掘出数据的潜力,我们继续加数据,效果能够稳定提升。

QAnything 实现数据越多效果越好
QAnything 两阶段检索最大的意义不是在某一个实验上面提升了 10 个点。它最大的意义在于让 “数据越多,效果越好” 变成了现实。这是在准备开始优化一个 RAG 系统之前要确保的第一件事情。
QAnything 应用
QAnything 和有道领世联合推出「AI 升学规划师」。基于 QAnything 强劲的检索增强生成能力和有道领世多年深耕的海量升学数据资料,可以为每个学生和家长配备一名私人 AI 升学规划师,提供更加全面、专业、及时的升学规划服务。
基于「QAnything」,有道 AI 升学规划师在升学百科问答中准确率达到 95%,可以解答用户关于高考政策、升学路径、学习生活以及职业规划等各种问题。并且随着不断地数据补充和更新,这个准确率会一直上涨。
有道领世AI升学规划师
有道领世 AI 规划师(Powered by QAnything)
展望
两阶段检索是一个大的框架,给 RAG 提供了一个好的基础。未来可以在两阶段的基础上做更多细致的优化。这里有一些想法,贴出来和大家一起探讨:
-
切片策略:切片策略对检索召回的影响非常大,目前主流的切片策略还比较机械,经常造成一些信息的损失,未来可能会出现更加智能的切片方式。
-
多路召回:可以在 embedding 检索的基础上增加 BM25 检索,或者通过 LLM 改写 query 的方式生成多个检索 query 增加召回率。
-
意图分类:不同的问题走不同的知识库,或者用不同的处理逻辑。
-
Agent:基于文档的问答能做的事情非常有限,Agent 和 RAG 结合起来可以做更多事情。
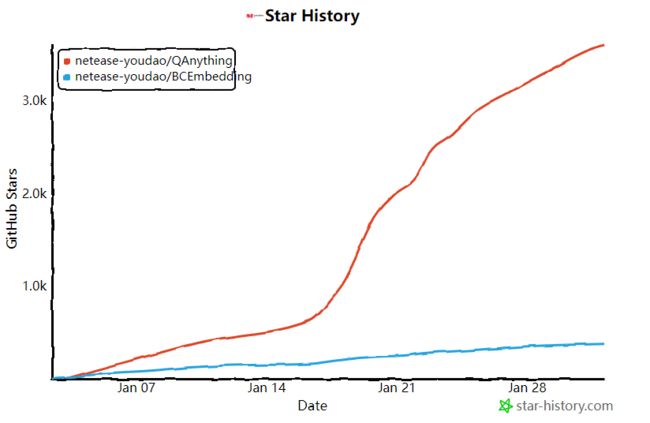
自从_「QAnything」_项目开放源代码以来,受到了开发社区的热烈欢迎和广泛认可。截至 2024 年 2 月 1 日,项目在 GitHub 上已经积累了 3600 多个星标,这反映出了其流行度和用户对其价值的高度评价。
欢迎点击下面的链接下载试用:
QAnything github: https://github.com/netease-youdao/QAnything
QAnything gitee: https://gitee.com/netease-youdao/QAnything
欢迎大家在 GitHub 上为「QAnything」加星助力,方便收到新版本更新的通知!
参考信息
QAnything: https://github.com/netease-youdao/QAnything
BCEmbedding: https://github.com/netease-youdao/BCEmbedding
RAG Survery: Retrieval-Augmented Generation for Large Language Models: A Survey
LlamaIndex RAG: https://docs.llamaindex.ai/en/stable/getting_started/concepts.html#retrieval-augmented-generation-rag
Cross-encoder: https://www.sbert.net/examples/applications/cross-encoder/README.html
Sentence-BERT: https://arxiv.org/pdf/1908.10084.pdf