MIT-BEVFusion系列七--量化1_公共部分和激光雷达网络的量化
目录
- 官方readme的Notes
-
- ptq.py
-
- 量化模块初始化
- 解析命令行参数
- 加载配置信息
- 创建dataset和dataloader
- 构建模型
- 模型量化
-
- Lidar backbone 量化
-
- 稀疏卷积模块量化
- 量化完的效果
- 加法模块量化
本文是Nvidia的英伟达发布的部署MIT-BEVFusion的方案
官方readme的Notes

这是是官方提到的量化时需要注意的三个方面:
-
1)在模型进行前向时,使用 融合BN层 可以为模型带来更好的性能,所以这个操作需要在模型校准(calibration)前实现。
-
2)Add 和 Concat 层是具有多输入的,需要对所有输入使用相同量化器(quantizer或者说QDQ节点要相同),这样可以降低发生 Reformat 的可能。
- Reformat 表示量化过程中出现精度格式转换。如果使用不同精度的量化器,就会造成这种问题的发生。可以使用trt-engine-explore可视化查看数据是否有reformat
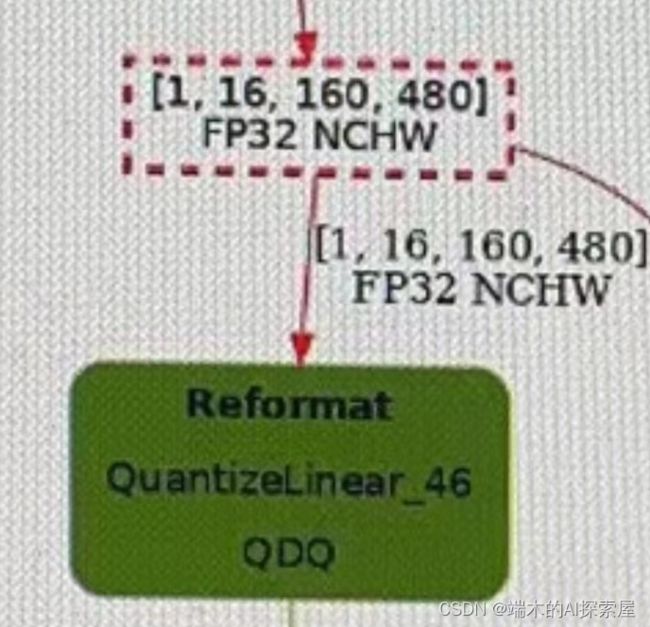
-
3)量化某些层时会造成严重的 mAP 掉点,所以在校准之后关闭这些层的量化是很有必要的。
ptq.py
执行结果:导入bevfusion_ptq.pth模型进行量化,导出一个量化后的模型'qat/ckpt/bevfusion_ptq.pth'
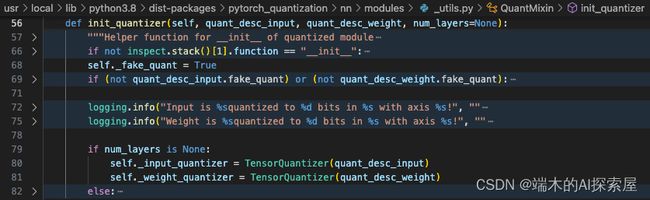
量化模块初始化
相对于pytorch_quantization工具中自带的自动插入QDQ节点的initialize方法,这里选择自己写initialize方法,手动插入QDQ节点

下方所有步骤都是在初始化模型量化器的参数:
-
438行创建input数据应该使用的量化描述器quant_desc_input,447行,将quant_desc_input设置给每个量化层。含义就是默认对input使用直方图的方式进行校准。
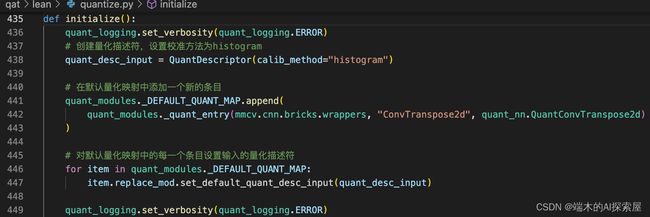
-
442行在
_DEFAULT_QUANT_MAP中添加新的条目。
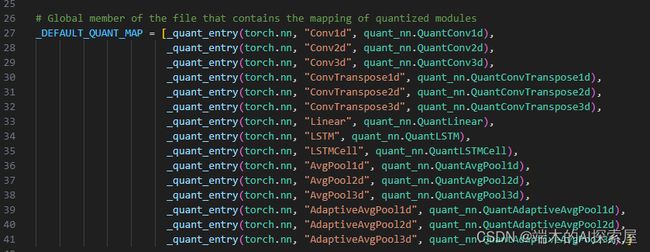
-
torch.nn中的层替换成pytorch_quantization中支持的量化层
- 没在
_DEFAULT_QUANT_MAP中的- 有的可以直接append进来,例如mmcv的ConvTranspose2d
- 有的要自己手动实现,并手动替换,例如SparseConvolutionQuant、add、concat
- 对于add、concat。还需要在网络中添加add层,修改前向
- 有的可以直接append进来,例如mmcv的ConvTranspose2d
- 没在
解析命令行参数

加载配置信息

-
注意事项
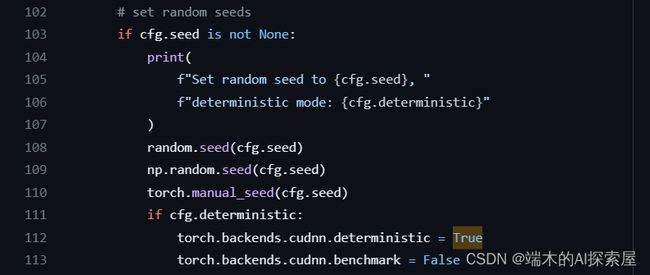
torch.backends.cudnn.deterministic = True
设置这个参数为True会让 cuDNN 使用确定性的算法。在深度学习中,某些卷积实现存在不确定性,因为它们可能使用一些优化,这可能会导致每次运行时得到稍微不同的结果。设定deterministic参数为True能保证每次运行的结果都是相同的,这对于调试非常有用。torch.backends.cudnn.benchmark = False
当这个参数被设置为True时,cuDNN 会在程序开始时,对卷积算法进行一次基准测试(benchmark),并选择最快的算法来实现卷积。这会使得计算过程更快。但是,如果网络的输入尺寸在运行时会改变,那么这个基准测试就会变得不准确,因此在这种情况下最好将这个参数设置为False。
对于大多数固定输入尺寸的任务,将benchmark设置为True是有益的,因为它会选择最优的卷积实现,从而提高运行速度。但是,为了保持可复现性,通常会将其设置为False。
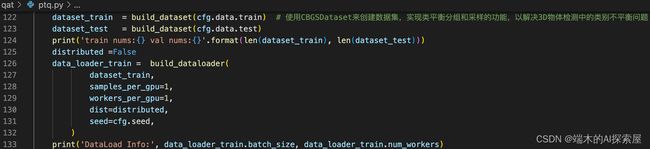
创建dataset和dataloader
- 创建traindataloader与valdataloader,这个在后续标定、评估过程中会用到
构建模型
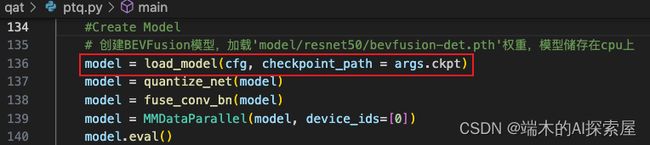

模型量化
- 137行的方法,负责整个模型的量化

- 模型网络如下
BEVFusion(
(encoders): ModuleDict(
(camera): ModuleDict(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'}
(neck): GeneralizedLSSFPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(3072, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(vtransform): DepthLSSTransform(
(dtransform): Sequential(
(0): Conv2d(1, 8, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(8, 32, kernel_size=(5, 5), stride=(4, 4), padding=(2, 2))
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 64, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2))
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
(depthnet): Sequential(
(0): Conv2d(320, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 198, kernel_size=(1, 1), stride=(1, 1))
)
(downsample): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(80, 80, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
)
)
(lidar): ModuleDict(
(voxelize): Voxelization(voxel_size=[0.075, 0.075, 0.2], point_cloud_range=[-54.0, -54.0, -5.0, 54.0, 54.0, 3.0], max_num_points=10, max_voxels=(120000, 160000), deterministic=True)
(backbone): SparseEncoder(
(conv_input): SparseSequential(
(0): SubMConv3d()
(1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(encoder_layers): SparseSequential(
(encoder_layer1): SparseSequential(
(0): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConv3d()
(1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer2): SparseSequential(
(0): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConv3d()
(1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer3): SparseSequential(
(0): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConv3d()
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer4): SparseSequential(
(0): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SubMConv3d()
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SubMConv3d()
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
(conv_out): SparseSequential(
(0): SparseConv3d()
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
)
)
(fuser): ConvFuser(
(0): Conv2d(336, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(decoder): ModuleDict(
(backbone): SECOND(
(blocks): ModuleList(
(0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(neck): SECONDFPN(
(deblocks): ModuleList(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
)
init_cfg=[{'type': 'Kaiming', 'layer': 'ConvTranspose2d'}, {'type': 'Constant', 'layer': 'NaiveSyncBatchNorm2d', 'val': 1.0}]
)
(heads): ModuleDict(
(object): TransFusionHead(
(loss_cls): FocalLoss()
(loss_bbox): L1Loss()
(loss_iou): VarifocalLoss()
(loss_heatmap): GaussianFocalLoss()
(shared_conv): Conv2d(512, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(heatmap_head): Sequential(
(0): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(128, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(class_encoding): Conv1d(10, 128, kernel_size=(1,), stride=(1,))
(decoder): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=128, out_features=128, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=128, out_features=128, bias=True)
)
(linear1): Linear(in_features=128, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=256, out_features=128, bias=True)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
(self_posembed): PositionEmbeddingLearned(
(position_embedding_head): Sequential(
(0): Conv1d(2, 128, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
)
)
(cross_posembed): PositionEmbeddingLearned(
(position_embedding_head): Sequential(
(0): Conv1d(2, 128, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
)
)
)
)
(prediction_heads): ModuleList(
(0): FFN(
(center): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 2, kernel_size=(1,), stride=(1,))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 1, kernel_size=(1,), stride=(1,))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 3, kernel_size=(1,), stride=(1,))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 2, kernel_size=(1,), stride=(1,))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 2, kernel_size=(1,), stride=(1,))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv1d(128, 64, kernel_size=(1,), stride=(1,), bias=False)
(bn): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv1d(64, 10, kernel_size=(1,), stride=(1,))
)
)
)
)
)
)
- 方法内部将bevfuion模型,拆解成不同部分去量化。
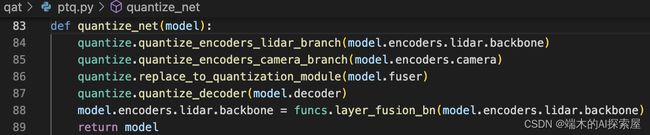
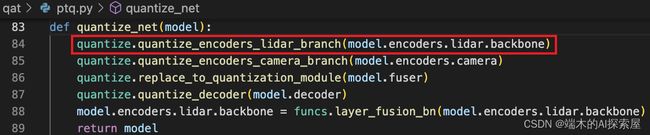
Lidar backbone 量化
- 首先观察 lidar 部分的网络。主要分为
voxelize与backbone两个部分。- 重点在 backbone 上。
- 首先想到的就是将卷积替换。但是稀疏卷积的
SubMConv3d与SparseConv3d不在_DEFAULT_QUANT_MAP这个列表中。于是代码中选择手写量化版的稀疏卷积。
稀疏卷积模块量化
在介绍 lidar backbone 量化之前,先了解接下来要使用的自定义的稀疏卷积量化模块 SparseConvolutionQuant。
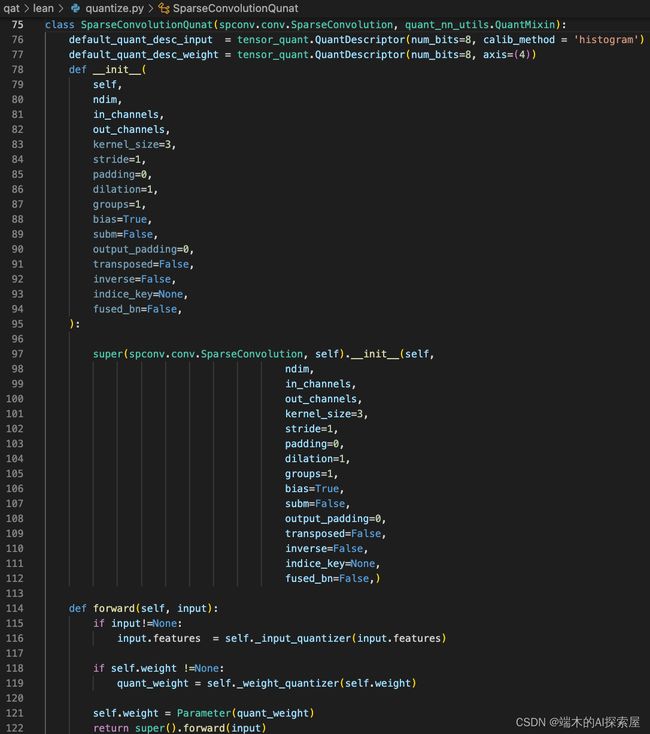
-
首先,量化版的 SparseConvolutionQuant 继承了 spconv.conv.SparseConvolution与quant_nn_utils.QuantMixin
-
这里初始化之前,就创建了输入和权重的量化描述器。
- 输入的量化精度为 int8,校准方法选择per-tensor+ histogram的方式。
- 权重的量化精度为 int8,会按照per-channel + amax的方式量化
-
forward 中如果存在输入和权重,就会对输入和权重进行量化操作。然后将量化后的权重注册为 SparseConvolution 的参数,将量化后的输入通过父类
SparseConvolution的前向,进行计算,返回的结果作为量化后稀疏卷积的前向结果。

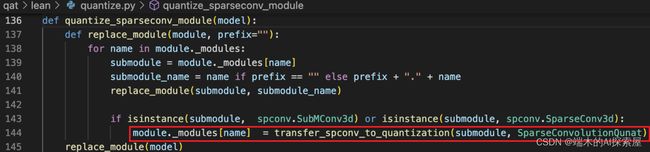
-
quantize_sparseconv_module 中主要是遍历 lidar backbone 中所有的模块,如果找到了属于 spconv.SubMConv3d 或者 spconv.SparseConv3d 的模块,就将该模块替换为量化后的稀疏卷积模块。
- 两个稀疏卷积,统一替换为 SparseConvolutionQuant
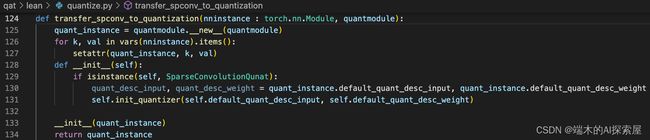
- 两个稀疏卷积,统一替换为 SparseConvolutionQuant
-
构建一个 **SparseConvolutionQunat **对象 quant_instance(125 行),
-
将原来 module (稀疏卷积) 中的所有属性以键值对的方式提取到 quant_instance 中,
-
然后用
__init__函数对 quant_instance 中的输入和权重的量化描述器进行更新,最后返回 quant_instance。
量化完的效果

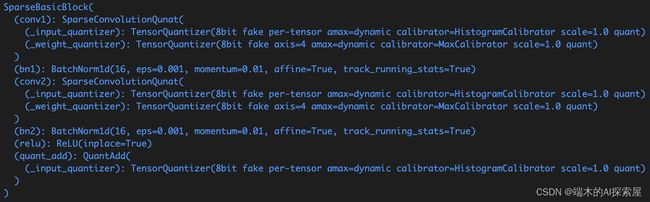
量化之后的稀疏卷积模块就是这样的,内部会有一个 _input_quantizer 和 _weight_quantizer,它们内部的量化维度和校准器是不同的。
加法模块量化


这里找到了属于 SparseBasicBlock 的 block 之后,就会在 block 中添加一个属性 quant_add,赋值为 QuantAdd()。

这里可以看到初始化时,会设置 QuantDescriptor 的量化精度为 int8,校准方法为 histogram,通过这个 QuantDescriptor 来构建 TensorQuantizer,主要用于对输入的量化。
![]()
forward 会根据是否量化来使用相对应的张量加法。在这里可以看到使用量化时,两个输入通过相同的输入量化器进行前向再相加,这就是在最开始提到的 Add 操作需要使用相同精度量化器。
![]()
这个是 TensorQuantizer 对象的信息:
- 8bit 表示量化为 8 比特
- fake 表示采用 fake quantization,即不真实量化 tensor 的值
- per-tensor 表示量化粒度为每个 tensor 独立,不区分通道等
- amax=dynamic 表示 amax 是动态的,学习输入的范围而不是固定值
- calibrator=HistogramCalibrator 表示使用直方图算法进行量化校准
- scale=1.0 表示量化比例因子为 1.0,这个用于调整量化范围
- quant 表示最终会执行 tensor 的量化运算(虽然 fake quantized)
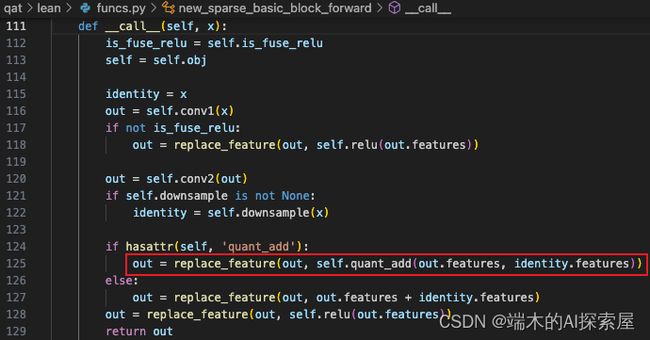
这个forward函数是SparseBasicBlock经过bn融合时替换的,将原先的残差结构修改成了这里的形式

添加 quant_add 前的 SqarseBasicBlock
添加 quant_add 后的 SqarseBasicBlock
总的来说,lidar backbone 的量化就是先将模型中的 spconv.SubMConv3d 和 spconv.SparseConv3d 替换为自定义的 SparseConvolutionQuant,然后将模型中的 SparseBasicBlock 中的卷积加法替换为 QuantAdd。
- 只替换卷积,与增加 ADD 节点的
model.encoders.lidar.backbone对比 - 可以明显的发现,多出了
quant_add层
SparseEncoder(
(conv_input): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(encoder_layers): SparseSequential(
(encoder_layer1): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer2): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer3): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer4): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
(conv_out): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
SparseEncoder(
(conv_input): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(encoder_layers): SparseSequential(
(encoder_layer1): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer2): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(32, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer3): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(2): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(encoder_layer4): SparseSequential(
(0): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
(1): SparseBasicBlock(
(conv1): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(conv2): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(quant_add): QuantAdd(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
)
)
)
(conv_out): SparseSequential(
(0): SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=4 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm1d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)