知识图谱与语言预训练:深度融合的智能问答时代
目录
- 前言
- 1 直接使用预训练模型 vs. 知识图谱与预训练相结合
-
- 1.1 直接使用预训练模型
- 1.2 构建知识图谱后与预训练相结合
- 2 预训练语言模型的发展历程
-
- 2.1 Word2Vec和GloVe
- 2.2 ELMo
- 2.3 BERT
- 3 知识图谱对预训练的助力
-
- 3.1 弥补低频实体信息的不足
- 3.2 提供领域知识的支持
- 4 典型知识驱动的语言预训练模型
-
- 4.1 ERNIE
- 4.2 KnowBERT
- 4.3 WKLM
- 4.4 K-Adapter
- 结语
前言
在自然语言处理领域,语言预训练模型的不断发展和知识图谱的广泛应用为智能问答等任务提供了新的可能性。本文将深入探讨直接使用预训练模型和构建知识图谱两种方法,并分析它们相结合的优势。我们还将回顾预训练语言模型的发展历程,以及知识图谱在弥补语言模型局限性方面的作用。最后,我们将介绍一些典型的知识驱动的语言预训练模型,以及它们在解决现实问题中的应用。
1 直接使用预训练模型 vs. 知识图谱与预训练相结合
1.1 直接使用预训练模型
直接使用预训练模型,如BERT,是一种高效而广泛应用的方法。这些模型通过在大规模语料上进行预训练,学习语言的上下文关系,从而使得它们能够更好地理解文本。然而,这类模型在处理低频实体和领域特定知识时表现较差。由于预训练是基于大量通用文本,对于特定领域的深入理解受到限制。
1.2 构建知识图谱后与预训练相结合
相较而言,另一种方法是构建知识图谱,并将其与预训练模型相结合。知识图谱是一种结构化的知识表示方式,它包含实体、关系和属性的网络,能够提供更为详实的实体关系信息。将知识图谱与预训练模型相结合,有助于弥补预训练模型在低频实体和领域特定知识方面的不足。通过这种方式,模型能够更好地理解上下文中的实体关系,提高在知识驱动的下游任务中的性能。
2 预训练语言模型的发展历程
2.1 Word2Vec和GloVe

在自然语言处理的早期,Word2Vec和GloVe是两个被广泛使用的模型。它们通过对词嵌入进行训练,试图为每个词汇赋予一个向量表示,以便计算机更好地理解语言。然而,这些模型存在一个共同的缺点,即信息单一,无法准确捕捉词汇在不同语境中的丰富语义。
2.2 ELMo
为了克服信息单一的问题,ELMo引入了上下文语境的变化。通过考虑词汇在不同上下文中的语义,ELMo提高了模型性能。这种方法使得模型能够更好地适应多义词汇和语境的变化,为后续预训练模型的发展提供了启示。
2.3 BERT
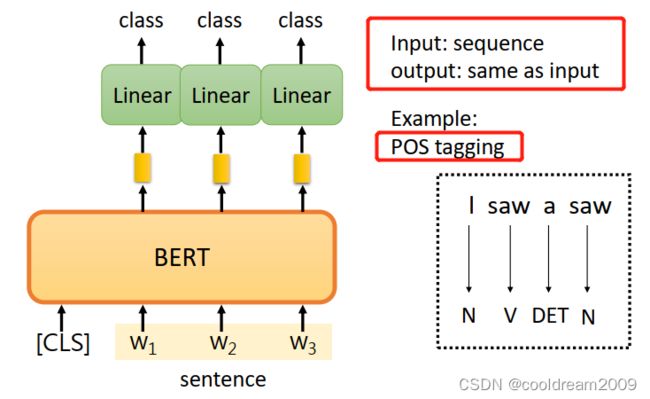
BERT则标志着预训练语言模型的重大突破。基于Transformer的架构,BERT通过双向编码文本,使得模型能够更全面地理解上下文。BERT的出现极大地提升了自然语言处理领域的性能,成为目前为止的一个重要里程碑。其成功也表明了通过预训练模型在大规模数据上学习语言知识的有效性,为后续模型的发展奠定了基础。
这一发展历程显示了预训练语言模型从最初简单的词嵌入方法到考虑上下文语境的模型,再到如今强大的双向编码模型的演进。这些进步为NLP任务提供了更强大、更灵活的语言理解工具,推动了自然语言处理领域的不断发展。
3 知识图谱对预训练的助力
知识图谱在预训练语言模型的发展中发挥着关键的助推作用。预训练语言模型,如BERT等,虽然在理解上下文语境中的常见实体和关系上取得了显著进展,但在捕获低频实体信息和领域特定知识方面存在一定的困难。
3.1 弥补低频实体信息的不足
知识图谱作为一种对实体关系进行结构化建模的工具,为预训练模型提供了丰富的实体关系信息。对于那些在通用文本中出现较少的低频实体,知识图谱提供了一个额外的信息来源,使得模型能够更全面地了解各种实体及其关系。这有助于提高模型对文本中特定实体的认知水平,增强了模型对复杂语境的适应性。
3.2 提供领域知识的支持
知识图谱还为预训练模型引入了更多的领域知识。通常,通用预训练模型学习的是通用性的语言知识,对于特定领域的深入理解存在一定的欠缺。知识图谱通过提供领域内实体和关系的结构信息,使得模型能够在领域特定任务中更准确地推理和理解。这种结合为模型提供了更强大的推断能力,使其在知识驱动的下游任务中表现更加出色。
知识图谱的引入有助于弥补预训练语言模型在低频实体和领域知识方面的不足,提升了模型在特定任务中的性能。未来,更深度的融合或者新颖的结合方式有望进一步推动知识图谱与预训练模型相结合的研究和应用,为自然语言处理领域带来更多创新。
4 典型知识驱动的语言预训练模型
知识驱动的语言预训练模型在整合领域知识和语言理解方面取得了显著的进展。以下是一些代表性的模型:
4.1 ERNIE
ERNIE(Enhanced Representation through kNowledge Integration)采用了一种独特的方式,通过引入外部知识来提升模型性能。然而,这种方法也伴随着噪音问题,即外部知识的质量和可靠性可能会影响模型的性能。ERNIE力图通过引入更多背景知识来增强对低频实体的理解,为知识驱动任务提供了一种创新的思路。
4.2 KnowBERT
KnowBERT是另一个知识驱动的模型,它采用类似的知识融合技术。通过更好地捕捉低频实体的语义信息,KnowBERT致力于提升模型对上下文的理解。该模型通过在预训练阶段引入额外的知识,为模型提供更全面、准确的实体关系信息,从而在各种语言理解任务中表现更为出色。
4.3 WKLM
WKLM(Wikipedia Knowledge Enhanced Language Model)通过在预训练阶段引入百科全书的知识,构建了一种预训练的百科全书模型。尽管该模型在丰富的知识方面表现出色,但它仍然面临无法进行终身学习的问题。这意味着模型在知识更新方面存在一定的局限性,需要定期重新训练以保持最新的知识。
4.4 K-Adapter
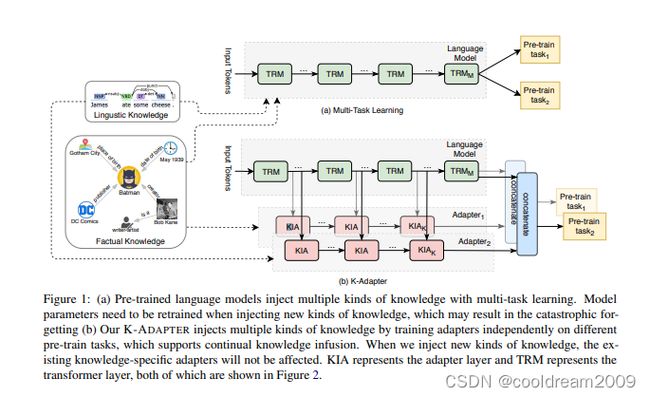
K-Adapter是一种尝试将知识注入到语言模型中的创新方法。通过向语言模型注入知识,并采用类似于TransE的预选连机制,K-Adapter增强了文本的表示,提高了模型对实体的理解能力。基于Wikipedia的知识,该模型在捕捉低频实体信息和领域知识方面取得了一定的成功。
这些模型代表了知识驱动的语言预训练模型在整合外部知识、捕捉低频实体信息和提升模型性能方面的不同尝试。随着研究的深入,我们可以期待看到更多创新的模型涌现,为知识图谱和预训练模型的深度融合提供更多可能性。
结语
在知识图谱与语言预训练相结合的趋势下,我们见证了自然语言处理领域的巨大进步。从直接使用预训练模型到构建知识图谱,再到两者相结合,我们正不断拓展智能问答等应用的边界。未来,随着技术的不断演进,我们有望看到更多基于知识图谱和语言预训练的创新,为人工智能的发展带来更多可能性。