关于商店销售量的数据处理小问题(Python)
通过学校举行的某次学科竞赛,我接触到了kaggle上的一道题:Store Sales - Time Series Forecasting。由于题主资质尚浅,本文将对前期数据处理的一些小问题做出解答,不涉及后续更难的问题。
此处放原题链接:Store Sales - Time Series Forecasting
题主也是看了很多的资料,也看到了CSDN上另外一位大佬写的文章,收获颇多,此处也放一下链接:Kaggle实战:Store Sales - Time Series Forecasting
希望这位大佬不要介意呀~
本文提到并解决的一些问题:
1.得出各商品的总销售量并为商品种类排序
2.筛选,仅保留该sales文件中销售量前五名的商品类别
3.对各个文件的数据进行整合并保存
4.将这五类商品进行分类,另保存为文件并以商品类的名称命名
5.对油价的数据进行处理
6.得到每个类别单个日期的总销售量(即不区分商店编号),并附上每日油价和节日
如图所示是一个各个日期下的,各个商店的,不同种类的商品的销售量数据(最后一列为该系列促销的项目数量,先不用管)。
1.首先第一个小问题,那么如何得出各商品的总销售量并为商品种类排序?
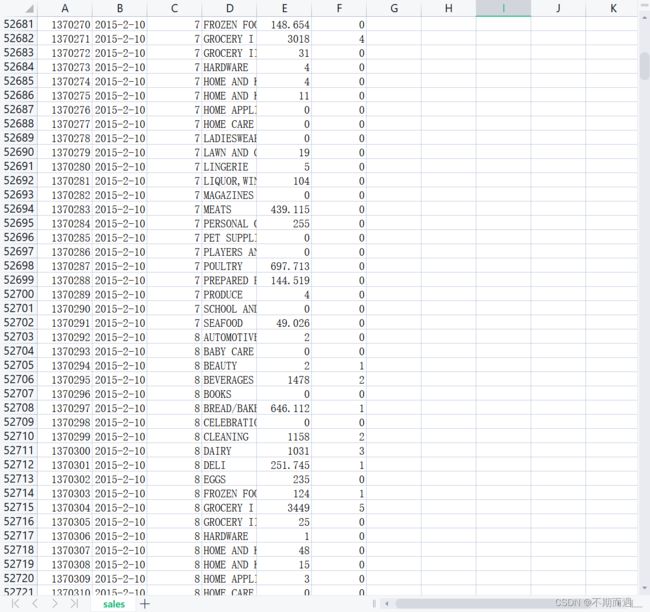
此时我们可以灵活运用pandas库,对该文件根据种类进行sum()相加处理并排序,并将结果转换为excel文件。
下面上代码。
import pandas as pd
# 读取销售数据文件
sales_data = pd.read_csv(r'./Cdata/sales.csv')
# 假设 sales_data 是一个包含销售数据的 DataFrame
grouped_sales = sales_data.groupby('family')['sales'].sum()
# 将分组结果转换为一个新的 DataFrame
grouped_sales_df = pd.DataFrame(grouped_sales).reset_index()
grouped_sales_df.sort_values(by="sales", inplace=True, ascending=False)
print(grouped_sales_df.head())
# 将结果写入 EXCEL 文件
grouped_sales_df.to_excel(r'./grouped_sales.xlsx', index=False)
excel和csv文件都可以相互转化o~
import pandas as pd
# 读取数据文件
data = pd.read_excel(r'BEVERAGES1.xlsx')
data.to_csv("BEVERAGES1.csv", index=False)
# 读取数据文件
data = pd.read_csv(r'BEVERAGES1.csv')
data.to_excel("BEVERAGES1.excel", index=False)
运行程序后,我们就得到了这样一个表格,就知道结果啦。
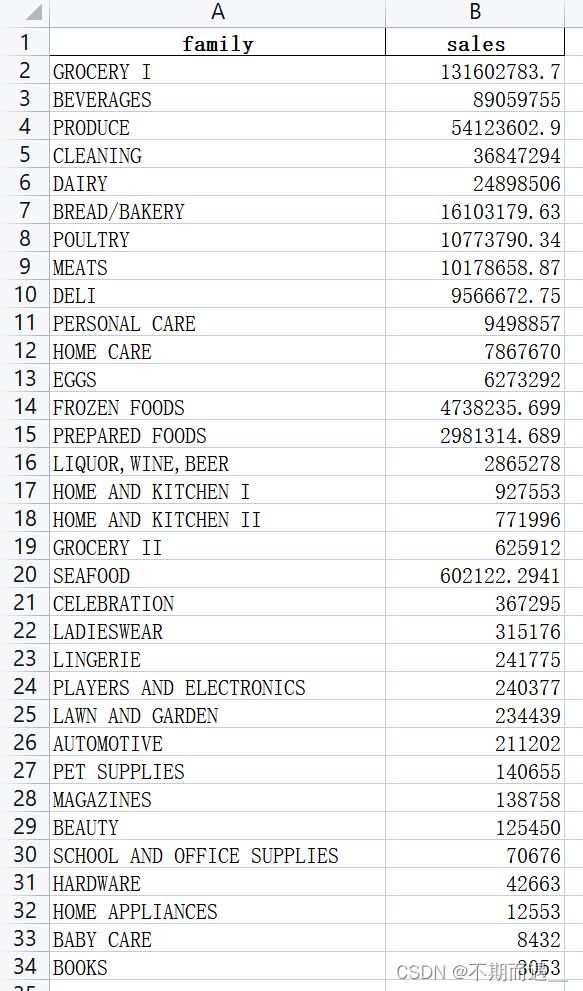
2.然后是第二个问题,我该如何进行筛选,仅保留该sales文件中销售量前五名的商品类别?
这个问题很好回答,只需要做一个简单的筛选并写入excel,命名为sales_1,与原文件做区分。
import pandas as pd
import numpy as np
import openpyxl
wb = openpyxl.Workbook()
# 激活表对象
ws = wb.active
ws = wb.create_sheet(index=0, title='sales_1')
ws.append(['id', 'date', 'store_nbr', 'family', 'sales', 'onpromotion'])
familys = ['GROCERY I', 'BEVERAGES', 'PRODUCE', 'CLEANING', 'DAIRY']
sales_data_frame = pd.read_csv(r'./Cdata/sales.csv')
sales_data = np.array(sales_data_frame) # 转化为数组形式
data = []
for item in sales_data:
family = item[3]
if family in familys:
data.append(item)
print(item)
row = len(data)
col = 6
for i in range(1, row + 1):
for j in range(1, col + 1):
value = str(data[i - 1][j - 1])
if value == '':
value = 0
ws.cell(i, j, value=value)
wb.save(r'sales_1.xlsx')我的方法还是比较蠢的,单元格一个个进行写入,此处仅供参考。
3.接着是第三个小问题:此时我还有节假日信息(日期、类型、地点、范围和名称)、每日油价、商店信息(所在国家和城市、聚团)、每日各商店交易额等csv文件。那我们该如何对各个文件的数据进行整合并保存呢?

还是要用到强大的pandas库,这时轮到merge函数上场了。
import pandas as pd
# 读取数据并处理日期
sales = pd.read_excel(r'sales_1.xlsx')
stores = pd.read_csv(r'./Cdata/stores.csv')
oil = pd.read_excel(r'oil_2.xlsx')
holidays_events = pd.read_csv(r'./Cdata/holidays_events.csv')
transactions = pd.read_csv(r'./Cdata/transactions.csv')
# 将日期字段转换为统一的日期格式
sales['date'] = pd.to_datetime(sales['date'])
oil['date'] = pd.to_datetime(oil['date'])
holidays_events['date'] = pd.to_datetime(holidays_events['date'])
transactions['date'] = pd.to_datetime(transactions['date'])
# 将商店数据合并到销售数据中
data = pd.merge(sales, stores, on='store_nbr', how='left')
# 将油价数据合并到数据中
data = pd.merge(data, oil, on='date', how='left')
# 将节假日事件数据合并到数据中
data = pd.merge(data, holidays_events, on='date', how='left')
# 将交易数据合并到数据中
data = pd.merge(data, transactions, on=['date', 'store_nbr'], how='left')
# 查看数据
print(data)
data.to_excel('merge_3.xlsx', index=False)结果也保存在了一个excel文件中。(为什么保存为merge_3而不是_1,因为本人更改了三次......)

4.第四个问题,我想将这五类商品进行分类,另保存为文件并以商品类的名称命名。
不得不说pandas库真的很好用!!
import pandas as pd
# 读取数据文件
data = pd.read_excel(r'merge_3.xlsx')
# 数据集是data
product_types = data['family'].unique()
for product in product_types:
product_df = data[data['family'] == product]
# 对每种商品类型的数据集product_df进行分类
print(product_df)
product_df.to_excel("./classify_excel/{}.xlsx".format(product),
index=False)最后能得到新的五个文件:

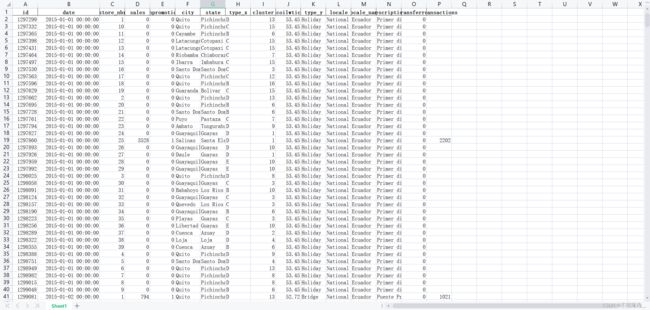
由于后续编码原因,我已经将表格中family一列删除(不删除无法后续操作)。
5.第五个问题,我需要对油价的数据进行处理。原本的油价数据有空缺值,且日期不连续。我们需要做的是对空缺值进行处理。
(这里题主偷了一个懒,用SPSSPRO对空缺值进行前一日数据的填充)
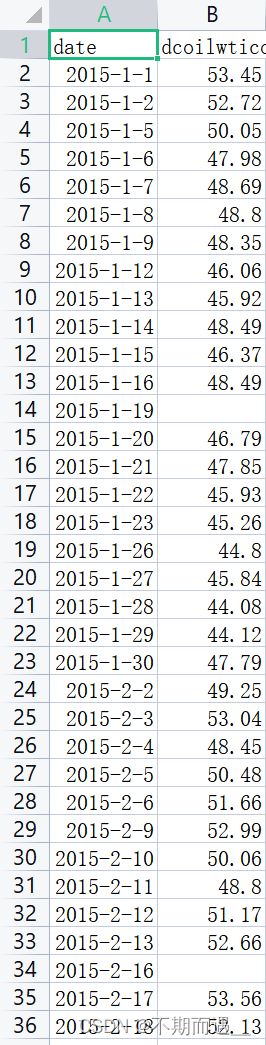
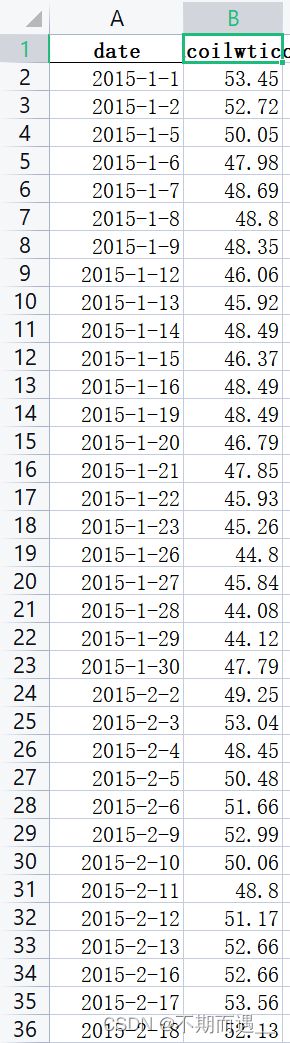
填充完之后我们将空缺的日期进行补充,然后用差分的办法进行空缺值处理 。(我得到唯一日期值的办法太笨了,大家有更好的方法,欢迎来交流~)
import pandas as pd
import numpy as np
from datetime import datetime
'''
import openpyxl
wb = openpyxl.Workbook()
# 激活表对象
ws = wb.active
ws = wb.create_sheet(index=0, title='Sheet1')
# 读取数据文件,去重
data = pd.read_excel(r'sales_1.xlsx')
date = data['date']
date_new = date.drop_duplicates(keep='first')
data_1 = np.array(date_new) # 转化为数组形式
row = len(data_1)
for i in range(1, row + 1):
value = str(data_1[i - 1])
value = datetime.strptime(value, '%Y-%m-%d')
value = value.strftime('%Y/%m/%d')
ws.cell(i, 1, value=value)
wb.save(r'oil_2.xlsx')
'''
# 合并数据
oil_data2 = pd.read_excel(r'oil_2.xlsx')
oil_data1 = pd.read_excel(r'oil_1.xlsx')
oil_data1['date'] = pd.to_datetime(oil_data1['date'])
oil_data2['date'] = pd.to_datetime(oil_data2['date'])
data = pd.merge(oil_data2, oil_data1, on='date', how='outer')
data.to_excel(r'oil_2.xlsx', index=False)
# 再次处理缺失值
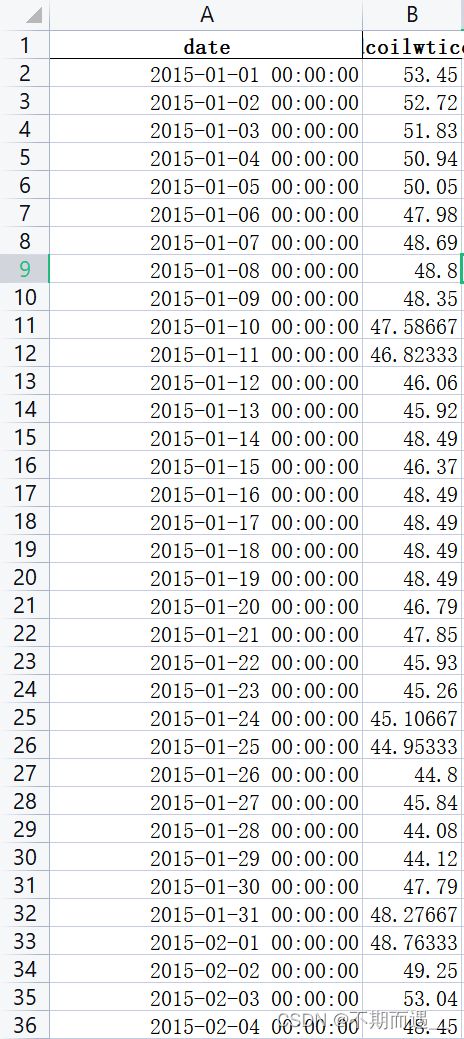
data = pd.read_excel(r'oil_2.xlsx')
data['dcoilwtico_1'] = data['dcoilwtico_1'].interpolate()
# 将结果写入 EXCEL 文件
data.to_excel('oil_2.xlsx', index=False)interpolate()函数是一个差值函数,处理数据很好用。操作就是类似下图的操作...
6.第六个问题,我需要得到每个类别单个日期的总销售量(即不区分商店编号),并附上每日油价和节日。
import pandas as pd
import numpy as np
import openpyxl
import time
familys = ['GROCERY I', 'BEVERAGES', 'PRODUCE', 'CLEANING', 'DAIRY']
col = ['date', 'sales', 'dcoilwtico', 'transactions']
oil_data = pd.read_excel('oil_2.xlsx')
for i in familys:
data_frame = pd.read_excel('{}.xlsx'.format(i))
wb = openpyxl.Workbook()
ws = wb.active
ws = wb.create_sheet(index=0, title='Sheet1')
ws.append(col)
sales = [None] * len(familys)
data = data_frame[col]
data['transactions'] = data['transactions'].fillna(0)
date_unique = list(data_frame['date'].unique())
sales_data = [None] * len(date_unique)
transactions_data = [None] * len(date_unique)
for i in range(len(data)):
if not sales_data[date_unique.index(data['date'][i])]:
sales_data[date_unique.index(data['date'][i])] = int(
data['sales'][i])
else:
sales_data[date_unique.index(data['date'][i])] += int(
data['sales'][i])
if data['transactions'][i] != '':
if not transactions_data[date_unique.index(data['date'][i])]:
transactions_data[date_unique.index(data['date'][i])] = int(
data['transactions'][i])
else:
transactions_data[date_unique.index(data['date'][i])] += int(
data['transactions'][i])
row = len(date_unique)
for i in range(1, row + 1):
for j in range(1, 5):
if j == 1:
value = str(date_unique[i - 1])
elif j == 2:
value = str(sales_data[i - 1])
elif j == 3:
value = str(oil_data['dcoilwtico'][i - 1])
else:
value = str(transactions_data[i - 1])
ws.cell(i, j, value=value)
print(i)
wb.save('{}_1.xlsx'.format(i))
看着就很繁琐...不过好在能解决问题。

继续加油!!!