linux swap 内存交换分区 详细介绍
目录
1、什么是SWAP,到底是干嘛的?
为什么要进行内存回收?
会回收的两种内存
2、swappiness到底是用来调节什么的?
那么这个swappiness到底起到了什么作用呢?
3、kswapd什么时候会进行swap操作?
4、什么是内存水位标记?(watermark)
相关参数设置
swap的相关操纵命令
5、swap分区的优先级(priority)有啥用?
最后
Q&A:
概述
本文讨论的 swap基于Linux4.4内核代码 。Linux内存管理是一套非常复杂的系统,而swap只是其中一个很小的处理逻辑。
希望本文能让读者了解Linux对swap的使用大概是什么样子。阅读完本文,应该可以帮你解决以下问题:
1、 swap到底是干嘛的?
2、 swappiness到底是用来调节什么的?
3、 kswapd什么时候会进行swap操作?
4、 什么是内存水位标记?
5、 swap分区的优先级(priority)有啥用?
1、什么是SWAP,到底是干嘛的?
我们一般所说的swap,指的是一个交换分区或文件。在Linux上可以使用swapon -s命令查看当前系统上正在使用的交换空间有哪些,以及相关信息:
[zorro@zorrozou-pc0 linux-4.4]$ swapon -s
Filename Type Size Used Priority
/dev/dm-4 partition 33554428 0 -1从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。
所以,当内存使用存在压力,开始触发内存回收的行为时,就可能会使用swap空间。
内核对swap的使用实际上是跟内存回收行为紧密结合的。那么关于内存回收和swap的关系,我们需要思考以下几个问题:
-
为什么要进行内存回收?
-
哪些内存可能会被回收呢?
-
回收的过程中什么时候会进行交换呢?
-
具体怎么交换?
下面我们就从这些问题出发,一个一个进行分析。
为什么要进行内存回收?
内核之所以要进行内存回收,主要原因有两个:
-
内核需要为任何时刻突发到来的内存申请提供足够的内存。所以一般情况下保证有足够的free空间对于内核来说是必要的。
另外,Linux内核使用cache的策略虽然是不用白不用,内核会使用内存中的page cache对部分文件进行缓存,以便提升文件的读写效率。
所以内核有必要设计一个周期性回收内存的机制,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
-
当真的有大于空闲内存的申请到来的时候,会触发强制内存回收。
所以,内核在应对这两类回收的需求下,分别实现了两种不同的机制:
-
一个是使用 kswapd进程对内存进行周期检查 ,以保证平常状态下剩余内存尽可能够用。
-
另一个是 直接内存回收(directpagereclaim) ,就是当内存分配时没有空闲内存可以满足要求时,触发直接内存回收。
这两种内存回收的触发路径不同:
-
一个是由内核进程kswapd直接调用内存回收的逻辑进行内存回收;
参见mm/vmscan.c中的kswapd()主逻辑
-
另一个是内存申请的时候进入slow path的内存申请逻辑进行回收。
参见内核代码中的mm/page_alloc.c中的__alloc_pages_slowpath方法
这两个方法中实际进行内存回收的过程殊途同归,最终都是 调用shrink_zone() 方法进行针对每个zone的内存页缩减。
这个方法中会再调用shrink_lruvec()这个方法对每个组织页的链表进程检查。找到这个线索之后,我们就可以清晰的看到内存回收操作究竟针对的page有哪些了。
这些链表主要定义在mm/vmscan.c一个enum中:
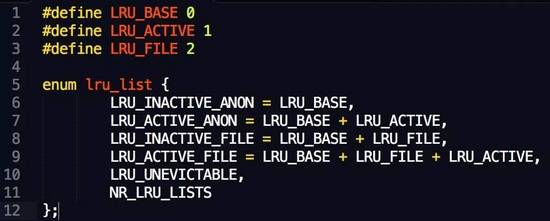
根据这个enum可以看到,内存回收主要需要进行扫描的链表有如下4个:
-
anon的inactive
-
anon的active
-
file的inactive
-
file的active
就是说,内存回收操作主要针对的就是内存中的文件页(file cache)和匿名页。
关于活跃(active)还是不活跃(inactive)的判断内核会使用lru算法进行处理并进行标记,我们这里不详细解释这个过程。
整个扫描的过程分几个循环:
-
首先扫描每个zone上的cgroup组;
-
然后再以cgroup的内存为单元进行page链表的扫描;
-
内核会先扫描anon的active链表,将不频繁的放进inactive链表中,然后扫描inactive链表,将里面活跃的移回active中;
-
进行swap的时候,先对inactive的页进行换出;
-
如果是file的文件映射page页,则判断其是否为脏数据,如果是脏数据就写回,不是脏数据可以直接释放。
会回收的两种内存
这样看来, 内存回收这个行为会对两种内存的使用进行回收:
-
一种是anon的匿名页内存,主要回收手段是swap;
-
另一种是file-backed的文件映射页,主要的释放手段是写回和清空。
因为针对filebased的内存,没必要进行交换,其数据原本就在硬盘上,回收这部分内存只要在有脏数据时写回,并清空内存就可以了,以后有需要再从对应的文件读回来。
内存对匿名页和文件缓存一共用了 四条链表 进行组织,回收过程主要是针对这四条链表进行扫描和操作。
2、swappiness到底是用来调节什么的?
很多人应该都知道 /proc/sys/vm/swappiness 这个文件,是个可以用来调整跟swap相关的参数。这个文件的默认值是60,可以的取值范围是0-100。
这很容易给大家一个暗示:我是个百分比哦!
那么这个文件具体到底代表什么意思呢?我们先来看一下说明:
======
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase agressiveness, lower values decrease the amount of swap.
A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
======
这个文件的值用来定义内核使用swap的积极程度:
-
值越高,内核就会越积极的使用swap;
-
值越低,就会降低对swap的使用积极性。
-
如果这个值为0,那么内存在free和file-backed使用的页面总量小于高水位标记(high water mark)之前,不会发生交换。
在这里我们可以理解file-backed这个词的含义了,实际上就是上文所说的文件映射页的大小。
那么这个swappiness到底起到了什么作用呢?
我们换个思路考虑这个事情。假设让我们设计一个内存回收机制,要去考虑将一部分内存写到swap分区上,将一部分file-backed的内存写回并清空,剩余部分内存出来,我们将怎么设计?
我想应该主要考虑这样几个问题:
-
如果回收内存可以有两种途径(匿名页交换和file缓存清空),那么我应该考虑在本次回收的时候,什么情况下多进行file写回,什么情况下应该多进行swap交换。说白了就是平衡两种回收手段的使用,以达到最优。
-
如果符合交换条件的内存较长,是不是可以不用全部交换出去?比如可以交换的内存有100M,但是目前只需要50M内存,实际只要交换50M就可以了,不用把能交换的都交换出去。
分析代码会发现,Linux内核对这部分逻辑的实现代码在 get_scan_count() 这个方法中,这个方法被 shrink_lruvec() 调用。
get_sacn_count()就是处理上述逻辑的,swappiness是它所需要的一个参数,这个参数实际上是指导内核在清空内存的时候,是更倾向于清空file-backed内存还是更倾向于进行匿名页的交换的。
当然,这只是个倾向性,是指在两个都够用的情况下,更愿意用哪个,如果不够用了,那么该交换还是要交换。
简单看一下get_sacn_count()函数的处理部分代码,其中关于swappiness的第一个处理是:

这里注释的很清楚:
-
如果swappiness设置为100,那么匿名页和文件将用同样的优先级进行回收。
很明显,使用清空文件的方式将有利于减轻内存回收时可能造成的IO压力。
因为如果file-backed中的数据不是脏数据的话,那么可以不用写回,这样就没有IO发生,而一旦进行交换,就一定会造成IO。
所以系统默认将swappiness的值设置为60,这样回收内存时,对file-backed的文件cache内存的清空比例会更大,内核将会更倾向于进行缓存清空而不是交换。
-
这里的swappiness值如果是60,那么是不是说内核回收的时候,会按照60:140的比例去做相应的swap和清空file-backed的空间呢?并不是。
在做这个比例计算的时候,内核还要参考当前内存使用的其他信息。对这里具体是怎么处理感兴趣的人,可以自己详细看get_sacn_count()的实现,本文就不多解释了。
我们在此要明确的概念是: swappiness的值是用来控制内存回收时,回收的匿名页更多一些还是回收的file cache更多一些 。
-
swappiness设置为0的话,是不是内核就根本不会进行swap了呢?这个答案也是否定的。
首先是内存真的不够用的时候,该swap的话还是要swap。
其次在内核中还有一个逻辑会导致直接使用swap, 内核代码 是这样处理的:
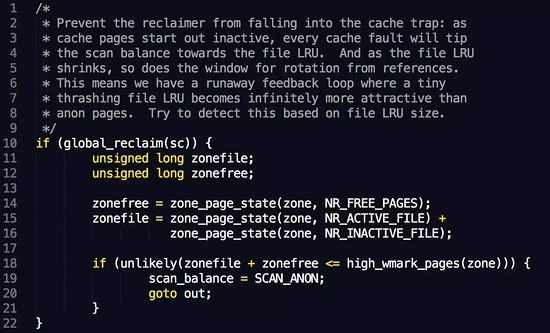
这里的逻辑是说,如果触发的是全局回收,并且zonefile + zonefree <= high_wmark_pages(zone)条件成立时,就将scan_balance这个标记置为SCAN_ANON。
后续处理scan_balance的时候,如果它的值是SCAN_ANON,则一定会进行针对匿名页的swap操作。
要理解这个行为,我们首先要搞清楚什么是高水位标记(high_wmark_pages)。
3、kswapd什么时候会进行swap操作?
我们回到kswapd周期检查和直接内存回收的两种内存回收机制。
直接内存回收比较好理解,当申请的内存大于剩余内存的时候,就会触发直接回收。
那么kswapd进程在周期检查的时候触发回收的条件是什么呢?
还是从设计角度来看,kswapd进程要周期对内存进行检测,达到一定阈值的时候开始进行内存回收。
这个所谓的阈值可以理解为内存目前的使用压力,就是说,虽然我们还有剩余内存,但是当剩余内存比较小的时候,就是内存压力较大的时候,就应该开始试图回收些内存了,这样才能保证系统尽可能的有足够的内存给突发的内存申请所使用。
4、什么是内存水位标记?(watermark)
那么如何描述内存使用的压力呢?
Linux内核使用水位标记(watermark)的概念来描述这个压力情况。
Linux为内存的使用设置了三种内存水位标记:high、low、min。他们 所标记的含义分别为:
-
剩余内存在high以上表示内存剩余较多,目前内存使用压力不大;
-
high-low的范围表示目前剩余内存存在一定压力;
-
low-min表示内存开始有较大使用压力,剩余内存不多了;
-
min是最小的水位标记,当剩余内存达到这个状态时,就说明内存面临很大压力。
-
小于min这部分内存,内核是保留给特定情况下使用的,一般不会分配。
内存回收行为就是基于剩余内存的水位标记进行决策的:
当系统剩余内存低于watermark[low]的时候,内核的kswapd开始起作用,进行内存回收。直到剩余内存达到watermark[high]的时候停止。
如果内存消耗导致剩余内存达到了或超过了watermark[min]时,就会触发直接回收(direct reclaim)。
明白了水位标记的概念之后,zonefile + zonefree <= high_wmark_pages(zone)这个公式就能理解了。
这里的zonefile相当于内存中文件映射的总量,zonefree相当于剩余内存的总量。
内核一般认为,如果zonefile还有的话,就可以尽量通过清空文件缓存获得部分内存,而不必只使用swap方式对anon的内存进行交换。
整个判断的概念是说,在全局回收的状态下(有global_reclaim(sc)标记),如果当前的文件映射内存总量+剩余内存总量的值评估小于等于watermark[high]标记的时候,就可以进行直接swap了。
这样是为了防止进入cache陷阱,具体描述可以见代码注释。
这个判断对系统的影响是, swappiness设置为0时,有剩余内存的情况下也可能发生交换。
那么watermark相关值是如何计算的呢?
所有的内存watermark标记都是根据当前内存总大小和一个可调参数进行运算得来的,这个参数是: /proc/sys/vm/min_free_kbytes
-
首先这个参数本身决定了系统中每个zone的watermark[min]的值大小。
-
然后内核根据min的大小并参考每个zone的内存大小分别算出每个zone的low水位和high水位值。
想了解具体逻辑可以参见源代码目录下的该文件:
mm/page_alloc.c
在系统中可以从/proc/zoneinfo文件中查看当前系统的相关的信息和使用情况。
我们会发现以上内存管理的相关逻辑都是以zone为单位的,这里zone的含义是指内存的分区管理。
Linux将内存分成多个区,主要有:
-
直接访问区(DMA)
-
一般区(Normal)
-
高端内存区(HighMemory)
内核对内存不同区域的访问因为硬件结构因素会有寻址和效率上的差别。如果在NUMA架构上,不同CPU所管理的内存也是不同的zone。
相关参数设置
zone_reclaim_mode:
zone_reclaim_mode模式是在2.6版本后期开始加入内核的一种模式,可以用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项,我们可以通过 /proc/sys/vm/zone_reclaim_mode 文件对这个参数进行调整。
在申请内存时(内核的get_page_from_freelist()方法中),内核在当前zone内没有足够内存可用的情况下,会根据zone_reclaim_mode的设置来决策是从下一个zone找空闲内存还是在zone内部进行回收。这个值为0时表示可以从下一个zone找可用内存,非0表示在本地回收。
这个文件可以设置的值及其含义如下:
-
echo 0 > /proc/sys/vm/zone_reclaim_mode:意味着关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存。
-
echo 1 > /proc/sys/vm/zone_reclaim_mode:表示打开zone_reclaim模式,这样内存回收只会发生在本地节点内。
-
echo 2 > /proc/sys/vm/zone_reclaim_mode:在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存。
-
echo 4 > /proc/sys/vm/zone_reclaim_mode:可以用swap方式回收内存。
不同的参数配置会在NUMA环境中对其他内存节点的内存使用产生不同的影响,大家可以根据自己的情况进行设置以优化你的应用。
默认情况下,zone_reclaim模式是关闭的。这在很多应用场景下可以提高效率,比如文件服务器,或者依赖内存中cache比较多的应用场景。
这样的场景对内存cache速度的依赖要高于进程进程本身对内存速度的依赖,所以我们宁可让内存从其他zone申请使用,也不愿意清本地cache。
如果确定应用场景是内存需求大于缓存,而且尽量要避免内存访问跨越NUMA节点造成的性能下降的话,则可以打开zone_reclaim模式。
此时页分配器会优先回收容易回收的可回收内存(主要是当前不用的page cache页),然后再回收其他内存。
打开本地回收模式的写回可能会引发其他内存节点上的大量的脏数据写回处理。如果一个内存zone已经满了,那么脏数据的写回也会导致进程处理速度收到影响,产生处理瓶颈。
这会降低某个内存节点相关的进程的性能,因为进程不再能够使用其他节点上的内存。但是会增加节点之间的隔离性,其他节点的相关进程运行将不会因为另一个节点上的内存回收导致性能下降。
除非针对本地节点的内存限制策略或者cpuset配置有变化,对swap的限制会有效约束交换只发生在本地内存节点所管理的区域上。
min_unmapped_ratio:
这个参数只在NUMA架构的内核上生效。这个值表示NUMA上每个内存区域的pages总数的百分比。
在zone_reclaim_mode模式下,只有当相关区域的内存使用达到这个百分比,才会发生区域内存回收。
在zone_reclaim_mode设置为4的时候,内核会比较所有的file-backed和匿名映射页,包括swapcache占用的页以及tmpfs文件的总内存使用是否超过这个百分比。
其他设置的情况下,只比较基于一般文件的未映射页,不考虑其他相关页。
page-cluster:
page-cluster是用来控制从swap空间换入数据的时候,一次连续读取的页数,这相当于对交换空间的预读。这里的连续是指在swap空间上的连续,而不是在内存地址上的连续。
因为swap空间一般是在硬盘上,对硬盘设备的连续读取将减少磁头的寻址,提高读取效率。
这个文件中设置的值是2的指数。就是说,如果设置为0,预读的swap页数是2的0次方,等于1页。如果设置为3,就是2的3次方,等于8页。
同时,设置为0也意味着关闭预读功能。文件默认值为3。我们可以根据我们的系统负载状态来设置预读的页数大小。
swap的相关操纵命令
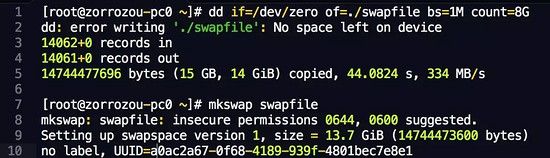
可以使用mkswap将一个分区或者文件创建成swap空间。swapon可以查看当前的swap空间和启用一个swap分区或者文件。swapoff可以关闭swap空间。
我们使用一个文件的例子来演示一下整个操作过程:
制作swap文件:
启用swap文件:

关闭swap空间:

5、swap分区的优先级(priority)有啥用?
在使用多个swap分区或者文件的时候,还有一个优先级的概念(Priority)。
在swapon的时候,我们可以使用-p参数指定相关swap空间的优先级, 值越大优先级越高 ,可以指定的数字范围是-1到32767。
内核在使用swap空间的时候总是先使用优先级高的空间,后使用优先级低的。
当然如果把多个swap空间的优先级设置成一样的,那么两个swap空间将会以轮询方式并行进行使用。
如果两个swap放在两个不同的硬盘上,相同的优先级可以起到类似RAID0的效果,增大swap的读写效率。
另外,编程时使用mlock()也可以将指定的内存标记为不会换出,具体帮助可以参考man 2 mlock。
最后
关于swap的使用建议,针对不同负载状态的系统是不一样的。有时我们希望swap大一些,可以在内存不够用的时候不至于触发oom-killer导致某些关键进程被杀掉,比如数据库业务。
也有时候我们希望不要swap,因为当大量进程爆发增长导致内存爆掉之后,会因为swap导致IO跑死,整个系统都卡住,无法登录,无法处理。
这时候我们就希望不要swap,即使出现oom-killer也造成不了太大影响,但是不能允许服务器因为IO卡死像多米诺骨牌一样全部死机,而且无法登陆。跑cpu运算的无状态的apache就是类似这样的进程池架构的程序。
所以:
-
swap到底怎么用?
-
要还是不要?
-
设置大还是小?
-
相关参数应该如何配置?
是要根据我们自己的生产环境的情况而定的。
阅读完本文后希望大家可以明白一些swap的深层次知识。
Q&A:
-
一个内存剩余还比较大的系统中,是否有可能使用swap?
A: 有可能,如果运行中的某个阶段出发了这个条件”zonefile+zonefree<=high_wmark_pages(zone) “,就可能会swap。
-
swappiness设置为0就相当于关闭swap么?
A: 不是的,关闭swap要使用swapoff命令。swappiness只是在内存发生回收操作的时候用来平衡cache回收和swap交换的一个参数,调整为0意味着,尽量通过清缓存来回收内存。
-
A: swappiness设置为100代表系统会尽量少用剩余内存而多使用swap么?
不是的,这个值设置为100表示内存发生回收时,从cache回收内存和swap交换的优先级一样。就是说,如果目前需求100M内存,那么较大机率会从cache中清除50M内存,再将匿名页换出50M,把回收到的内存给应用程序使用。但是这还要看cache中是否能有空间,以及swap是否可以交换50m。内核只是试图对它们平衡一些而已。
-
kswapd进程什么时候开始内存回收?
A: kswapd根据内存水位标记决定是否开始回收内存,如果标记达到low就开始回收,回收到剩余内存达到high标记为止。
-
如何查看当前系统的内存水位标记?
A: cat /proc/zoneinfo。