Linux_文件系统
假定外部存储设备为磁盘,文件如果没有被使用,那么它静静躺在磁盘上,如果它被使用,则文件将被加载进内存中。故此,可以将文件分为内存文件和磁盘文件。
- 内存文件
- 磁盘文件
- 软、硬链接
一.内存文件
1.1 c语言的文件接口
- fopen:FILE *fopen(const char *path, const char *mode);
- mode:
- r :读方式
- w:写,打开即清空文件
- a:追加方式
- mode:
- fclose:int fclose(FILE *fp);
- fwrite:size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
- fgets:char *fgets(char *s, int size, FILE *stream);
- fputs:int fputs(const char *s, FILE *stream);
- snprintf:int snprintf(char *str, size_t size, const char *format, …);

1.2 系统接口
1.2.1 open

- 返回值:返回一个文件描述符(下文讨论)
- pathname:指定文件路径
- flags:位图,可以用宏来指定打开方式
- O_RDONLY:读方式
- O_WRONLY: 写方式
- O_CREAT: 不存在则创建
- O_TRUNC: 打开后会清空文件
- O_APPEND:追加方式打开,不清空文件
- mode :指定创建文件时的起始权限
// 1.读时的open写法
int fd = open("log.txt", O_RDONLY);
// 2.清空写时的open写法
int fd1 = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC);
//3.追加写时的open写法
int fd2 = open("log.txt", O_WRONLY | O_CREAT | O_APPEND);
当一个进程要打开文件时,操作系统将文件的属性加载到内存中,根据这些属性创建一个struct file结构体,并且将该结构体与进程控制块task_struct建立联系。
1.2.2 close

- fd : 文件描述符,open返回值。
1.2.3 write

- count:写入字节数
1.2.4 read

1.3 文件描述符-file descriptor
操作系统将文件加载进内存,创建对应的struct file 结构体,并且与struct task_struct建立联系。在Linux中,task_struct 内部有一个 struct files_struct 字段,这个结构体里面有struct file* fd_array[]数组,file descriptor就是这个数组的下标。如图:
1.3.2 文件描述符本质
文件描述符的本质就是struct file*fd_array 数组中的下标,当操作系统创建文件结构体struct file时,将该结构体地址填入数组中,至此进程与文件建立了联系。
-
操作系统从开始扫描数组,遇到空位置,则填入地址,给调用进程返回数组下标,即文件描述符。

观察上面代码,发现文件描述符是从3开始的,这是因为c语言中默认打开三个文件,标准输入-stdin,标准输出-stdout,标准错误-stderr,它们对应数组的 0 1 2,stdout和stderr默认都指向显示器。
1.4 struct file 与 struct FILE
struct file是内核级别的结构体,而struct FILE是c语言库中定义的结构体,这两者之间没有任何关系。
struct FILE内部有一个文件描述符int fd; 字段。当进程读写文件时,os会根据文件描述符找到对应的struct file结构体,然后进行读写操作。
1.5 重定向
重定向有三种:输出重定向,追加重定向,输入重定向
- 输出重定向:我们可以在命令行中输入命令
ls . > text,这样原本打印在显示器上的消息就打印到文本text中了,这叫做输出重定向。 - 追加重定向:输出重定向会先清空文件,然后写入内容,追加重定向不清空文件,在文件末尾追加内容
- 输入重定向:在命令行中输入
cat < text,原本是从键盘读取字符,然后重定向到从text中读取字符 ,这就是输入重定向。
为什么ls . > text可以将打印到显示器上的数据打印到text中的呢?在Linux中,命令ls是一个程序,它也是用c语言编写的,所以是用printf来进行打印的,而printf默认会打印到stdout对应的文件中,stdout中的fd为1,如果我们将数组下标为1的元素内容从显示器改变为目标文件,那么这样就做到了将打印到显示器上的数据打印到text中。输入重定向也是同理,改变文件描述符的指向即可。即:重定向的原理就是改变数组元素的指向。这种改变是上层无法获知的,所以stdout依旧认为它对应的文件是显示器。
1.5.1 重定向的三种方式
- 命令行
./test > text 2>&1 : 将test的执行结果输出到text中,并且将1号文件描述符的内容靠别到2号文件描述符中,即,stderr也会输出到text中./test 1>log 2>err :将标准输出改变为log,标准错误改变为err
- dup2(int oldfd, int newfd);
- 例如dup2(3, 2); 将3号文件描述符的内容拷贝到2号文件描述符中
- 先关闭1号文件描述符,然后调用open
close(1);
int fd = open("log.txt", O_WRONLY|O_CREAT|_TRUNC); // 1
1.6 内核级缓冲区和用户级缓冲区
c语言库中struct FILE结构体中有一个缓冲区,用来暂存数据,这个缓冲区叫做用户级缓冲区。内核结构体struct file 中有一个缓冲区,用来暂存数据,这个缓冲区叫做内核级缓冲区。缓冲区的目的是为了提高IO效率。
用户级缓冲区的刷新策略:‘
- 无缓冲
- 行缓冲(显示器) :遇到换行符将数据刷新到内核级缓冲区
- 全缓存(普通文件):当缓冲区满了才将数据刷新到内核级缓冲区
内核级缓冲区的刷新策略由os系统决定,当然我们可以调用fsync()强制刷新。
1.6.1 数据流动方式
当程序调用printf函数时,先将字符串拷贝到用户缓冲区,然后结合相关刷新策略,调用write函数将字符串从用户缓冲区拷贝到内核缓冲区,最后os结合刷新策略将数据刷新到外设中,这就是数据的流动方式。共经历三次拷贝。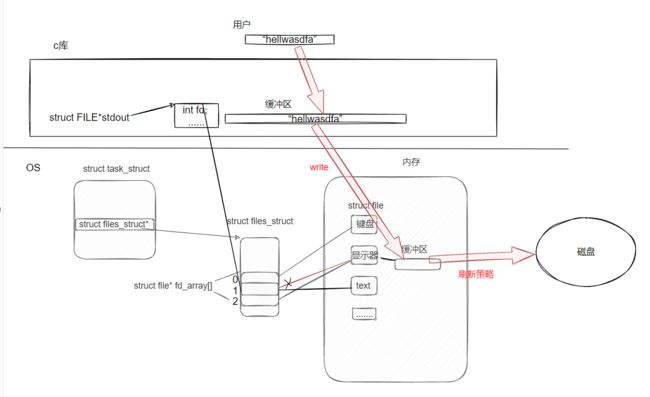
1.6.2 代码示例-缓冲区
#include- 情况1:输出结果:

- 情况2:输出结果:

为什么会有这样奇怪的结果呢?这与缓冲区的刷新策略有关?因为printf默认输出到显示器,而显示器的刷新策略是行刷新,所以情况1正确执行。而情况2中,没有换行符,所以数据留在用户缓冲区中,没有刷新到内核缓冲区,等调用fork的时候,创建子进程,子进程又继承了父进程的代码和数据,故此就有了两份数据“hello world!”当父子进程退出时,都会刷新用户缓冲区,于是内核缓冲区中就有两份hello world。
二.磁盘文件
2.1 磁盘
磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘([Hard disk](https://baike.baidu.com/item/Hard disk/2806058?fromModule=lemma_inlink),简称硬盘)。现在的pc大部分都用的是SSD固态硬盘(电)。
2.2 磁盘的物理结构

- 磁盘中有许多盘片,每一个盘片都有两个盘面,盘面上有若干磁道,磁道由若干扇区组成,磁盘的基本存储单元是扇区(512字节),多个盘片同半径的所有磁道构成一个柱面
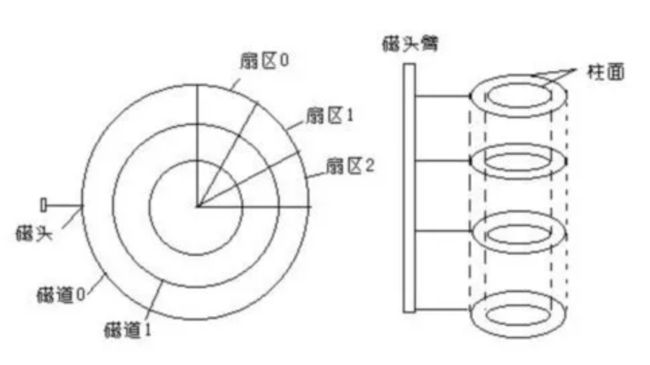
2.3 硬件寻址方法-CHS
确定一个扇区的方式:先定位在哪个盘面上(磁头head),然后在定义哪个柱面cylinder(磁道),最后根据扇区(sector)编号即可定位某一个扇区。这种寻址方法也叫做CHS定位法。
2.4 操作系统寻址方式-LBA
操作系统的寻址方式和硬件的寻址方式需要解耦合,所以操作系统需要有一套新的地址。os将盘面逻辑抽象成线性的(类似以前的那种磁带全部展开后)。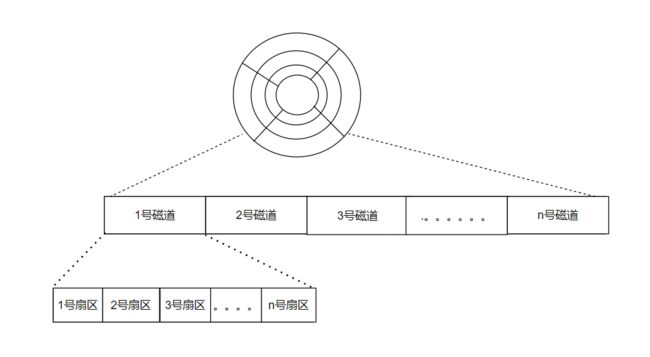
将这样的结构看作一个数组,每一个扇区占一个数组下标,这样就可以轻易的获取每个扇区的地址。但是操作系统一次IO的基本单位是块(4KB),所以将8个扇区看作一个块,然后重新抽象得到下图。下面这样的地址叫做LBA-逻辑块地址。磁盘也叫做块设备,以块为单位进行IO。
2.5 磁盘分区管理
我们电脑上只带有一块盘,但是为了更好的管理,所以将盘分为若干区,为了更好的管理一个区(区等同于c盘,d盘),又将区分为若干组。每个组内有许多字段。
Linux是将文件内容和属性分开存储的。
- Boot Block:存储了OS系统镜像以及开机启动的一些程序。
- Super Block(SB):存储了当前区的文件系统相关的属性,如文件系统名字,整个分区的情况,非常重要,损坏的话一个分区全部不能用,因此要在每个分组内做备份。Linux用的Ext系列的文件系统。
- Group Descriptor Table(GDT):存储了整个分组的情况
- Block Bitmap:位图结构,分别对应Data Blocks中的块是否可用
- Inode Bitmap:位图结构,对应Inode Table中的Inode是否有效
- Inode Table:存储文件属性。文件属性的集合叫做Inode节点,每一个Inode节点都有一个Inode编号(文件id)。
struct Inode{ int inode_num ; int block[NUM];///....}; - Data Blocks:存储文件内容,为了建立文件属性和内容的联系,故此每个Inode节点里面都有一个数组,指明哪个块是属于本文件,可用建立直接映射,二级映射,三级映射。
os查找文件:
ls -li:查看当前目录下所有文件的inode编号
- 先找到文件对应的Inode编号
- 在Inode Table中找到Inode节点
- 根据Inode节点获得其内容块的地址、
2.6 Inode节点
struct inode
{
int inode_number; //inode 编号
int ref_count; // 硬链接数
int modes; //权限
size_t uid;
size_t size;
//....
int databloacks[NUM]; //内容
};
- inode里面并没有文件名,因为操作系统并不需要文件名来标识文件,而是通过inode_编号来标识文件的。文件名只是给用户看的。
- 我们用
touch命令的时候,是os先遍历访问InodeBitmap寻找空闲的Inode Table,创建Inode,然后在当前目录下用Inode编号和文件名建立一个映射关系。目录也是一个文件,目录里面存储的是文件名和Inode编号的映射关系 - 增删查改文件都是先根据文件名找到Inode编号
三.软、硬链接
3.1 软链接
ln -s myfile myfile-soft
- myfile-soft为myfile的链接文件,这个链接文件的内容为myfile的路径。
- 软链接的作用:便于执行程序,类似于Windows中的桌面快捷方式

3.2 硬链接
ln myfile myfile-hard
- 给myfile建立一个硬链接文件myfile-hard

功能:
Linux下,每一个目录下都有两个特殊目录. 和.. ,一个点代表当前路径,两个点代表上级路径,为什么呢?因为一个点是当前路径的硬链接,两个点是上级路径的硬链接。这两个特殊路径使得路径切换更加容易。
- Linux下,不容许用户给目录建立硬链接,防止出现环路问题,而
.和..是操作系统可用识别的特殊路径。
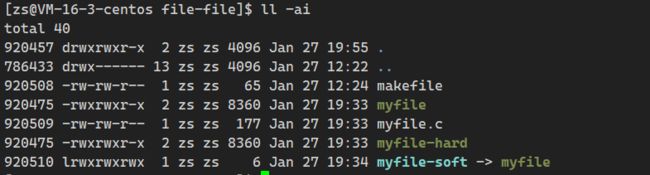
3.3软硬链接的区别
- 通过观察创建的文件inode编号,可用知道硬链接并没有新建inode节点,而是和myfile指向同一个节点
- 软链接新建了一个文件,其有自己的inode节点和内容
- 硬链接数:类似于引用计数,当值为0的时候,就会释放inode节点。
