Shell脚本之正则表达式详解
目录
一.正则表达式
1.正则表达式的概念
2.正则表达式工具grep
案列
3.常见元字符(支持的工具:find、grep、egrep、sed和awk)
4.扩展正则表达式
5.位置锚定
二.常见的管道命令
1.sort命令
2.uniq命令
3.tr命令
4.cut命令
5.实例
1.统计当前主机连接状态
2.统计当前连接主机数
一.正则表达式
1.正则表达式的概念
正则表达式,又称规则表达式(英语:Regular Expression),在代码中常简写为regex、 regexp或RE),是计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式不只有一种,而且 LINUX中不同的程序可能会使用不同的正则表达式,如:工具: grep sed awk egrep
LINUX 中常用的有两种正则表达式引擎砖础:正则表达式:BRE 扩展正则表达式:ERE
LINUX 中文本处理工具:grep、egrep、sed、awk
2.正则表达式工具grep
grep [选项]… 查找条件 目标文件
-E :开启扩展(Extend)的正则表达式
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-o :只显示被模式匹配到的字符串
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!(反向查找,输出与查找条件不相符的行)
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
-n :顺便输出行号
案列
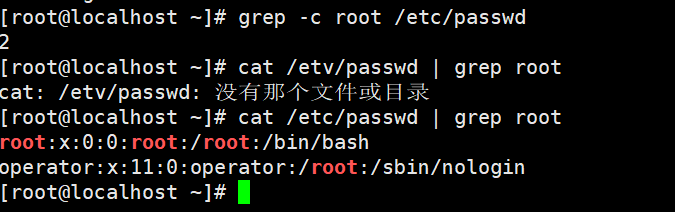
①统计root字符总行数;再用cat /etc/passwd | grep root 进行查看是否正确。
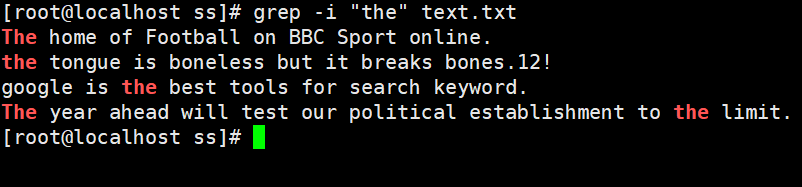
②不区分大小写查找the所有的行。
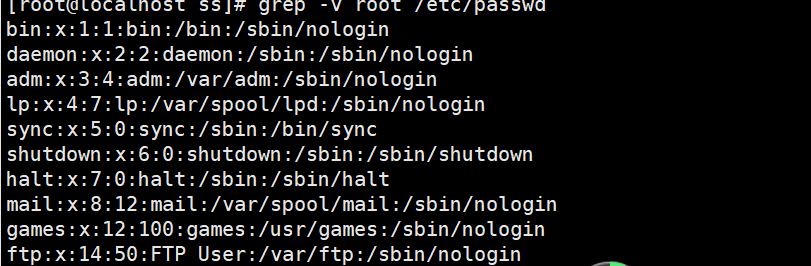
③将/etc/passwd,将没有出现 root 的行取出来。
④将web.sh文件中的非空行写入到test.txt文件中。
cat web.sh | grep -v '^$' > test.txt
⑤过滤本机ip地址。
![]()
3.常见元字符(支持的工具:find、grep、egrep、sed和awk)
| 元字符 | 作用 |
| \ | 转义字符,用于取消特殊符号的含义 例: \!,\n,\$等 |
| ^ |
匹配字符串开始的位置 例: ^a, "the,^#,^[a-z] |
| $ | 匹配字符串结束的位置 例: word$,^$匹配空行 |
| . | 匹配出\n之外的任意的一个字符 例: go.d.g..d |
| * | 匹配前面子表达式o次或者多次 例:goo*d,go.*d |
| [list] | 匹配list列表中的一个字符 例: go[loa]d,[a-z],[o-9]匹配任意一位数字 |
| [^list] | 匹配任意非list列表中的一个字符 例:[^0-9].[^a-z]匹配任意一位非小写字母 |
| \{n\} | 匹配前面子表达式n次 例:gol{2}d.’[0-9]\{2}’匹配两位数字 |
| \{n,\} | 匹配前面子表达式不少于n次 例: gol {2,}d,’[O-9] \{2,好’匹配两位及两位以上数字 |
| \{n,m\} | 匹配前面子表达式n到m次 例: go\{2,3\}d,'[o-9] \ {2,3\}’匹配两位到三位数字 |
| 注: egrep,awk使用{n]}, {n,}, {n, m}匹配时“{}”前面不用加“”“\” | |
定位符
^ 匹配输入字符串开始的位置
$ 匹配输入字符串结尾的位置
非打印字符
\n 匹配一个换行符
\r 匹配一个回车符
\t 匹配一个制表符注: egrep、awk使用{n}、{n,}、{n,m}匹配时“}"前不用加"\"
egrep -E -n 'wo{2}d' test.txt1/-E用于显示文件中符合条件的字符
egrep -E -n 'wo{2,3}d' test.txt
示例1:[^ ]:表示否定括号中出现字符类中的字符,取反
[root@yxp opt]#ls |grep "[^yxp].txt"
0.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt
7.txt
8.txt
9.txt
a.txt
.........后面省略
[root@yxp opt]#echo 12txt|grep "[^az].txt"
12txt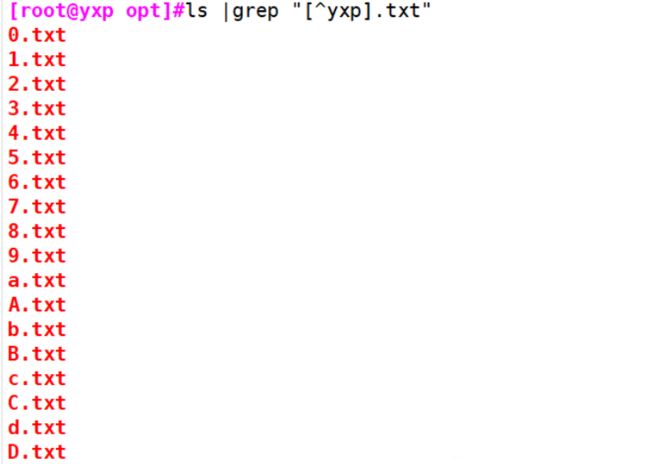

示例2:[ ] 匹配括号中的一个字符
#[yxp]
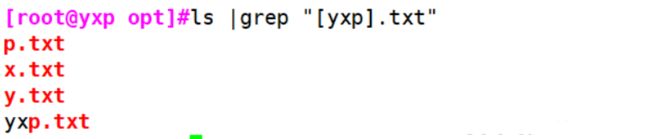
[root@yxp opt]#ls |grep "[yxp].txt"
p.txt
x.txt
y.txt
yxp.txt
#[0-9]
[root@yxp opt]#ls |grep "[0-9].txt"
0.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt
7.txt
8.txt
9.txt
#{a..d}
[root@yxp aa]#touch {a..z}.txt
[root@yxp aa]#ls
a.txt e.txt i.txt m.txt q.txt u.txt y.txt
b.txt f.txt j.txt n.txt r.txt v.txt z.txt
c.txt g.txt k.txt o.txt s.txt w.txt
d.txt h.txt l.txt p.txt t.txt x.txt
#{A..Z}
[root@yxp bb]#touch {A..Z}.txt
[root@yxp bb]#ls
A.txt E.txt I.txt M.txt Q.txt U.txt Y.txt
B.txt F.txt J.txt N.txt R.txt V.txt Z.txt
C.txt G.txt K.txt O.txt S.txt W.txt
D.txt H.txt L.txt P.txt T.txt X.txt
#[a-d]:包括小a到小d,还有大写的,除了D
[root@yxp opt]#ls [a-d].txt
a.txt A.txt b.txt B.txt c.txt C.txt d.txt
##只想匹配小写(需要结合grep)
[root@yxp opt]#ls |grep '[a-d].txt'
a.txt
b.txt
c.txt
d.txt
#[A-D]:不包括小a
[root@yxp opt]#ls [A-D].txt
A.txt b.txt B.txt c.txt C.txt d.txt D.txt
##[A-D]只想匹配大写
[root@yxp opt]#ls |grep '[A-D].txt'
A.txt
B.txt
C.txt
D.txt



示例3:. 表示任意一个字符
#表示任意一个字符
[root@yxp data]#echo abc|grep "a.c"
abc
#原来的点需要加\转义
[root@yxp data]#echo abc|grep "a\.c"
#标准格式需要加'' 或者""
[root@yxp data]#echo abc a.c|grep "a\.c"
abc a.c
[root@yxp data]#echo abc adc|grep "a.c"
abc adc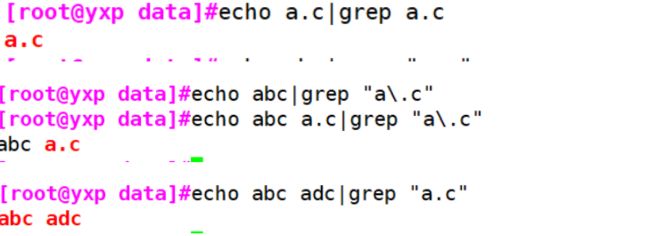
示例4:[:alnum:]匹配任意字母和数字
##注意:一定要在外面再套一个[ ]
[root@yxp opt]#ls |grep '[[:alnum:]].txt'
0.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt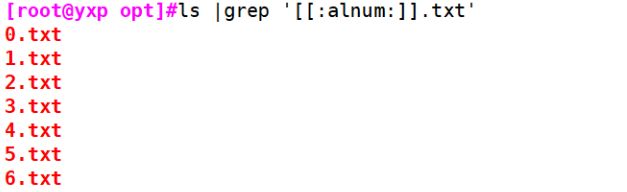
示例5:元字符:(.)
#//表示rc. rc0 ... rc6
[root@yxp opt]#ls /etc/ |grep 'rc[.0-6]'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
#r..t ..表示任意两个字符
[root@yxp opt]#grep "r..t" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin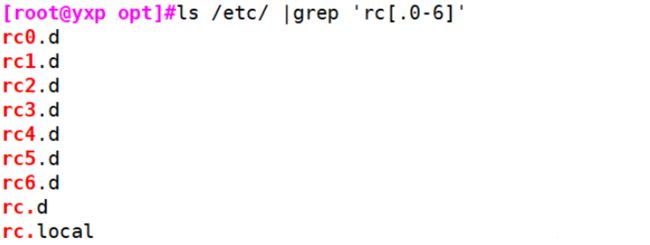

4.扩展正则表达式
支持的工具:egrep、awk 或 grep -E 和 sed -r

示例1:*匹配前面子表达式0次或者多次
[root@yxp opt]#echo google ggle|grep "go*gle"
google ggle
[root@yxp opt]#echo google ggle gggle|grep "go*gle"
google ggle gggle示例2:{n,m}匹配前面的子表达式n到m次
[root@yxp opt]#echo goooogle goole gggle|egrep "go{3,5}gle"
goooogle goole gggle示例3:{n,} 匹配前面的子表达式不少于n次 >=n
[root@yxp opt]#echo goooogle gooogle gggle|egrep "go{3,}gle"
goooogle gooogle gggle示例4:{,n} 匹配前面的子表达式最多n次,<=n
[root@yxp opt]#echo goooogle gooogle gggle|egrep "go{,3}gle"
goooogle gooogle gggle示例5:* 匹配前面子表达式0次或者多次
[root@yxp opt]#echo gggggggggggdadasgle|grep 'g*gle'
gggggggggggdadasgle示例6:.*任意长度的任意字符
[root@yxp opt]#echo gggggggggggdadasgle|grep '.*gle'
gggggggggggdadasgle示例7:?匹配前面子表达式0次或者1次,即:可有可无
[root@yxp opt]#echo goole gogle ggle|egrep "go?gle"
goole gogle ggle示例8:+与星号相似,表示其前面字符出现一次或多次,但必须出现一次,>=1
[root@yxp opt]#echo google gogle ggle gooogle|egrep "go+gle"
google gogle ggle gooogle示例9:| 逻辑OR(或)方式指定正则表达式要是用的模式
[root@yxp opt]#echo 1ee 1abc 2abc|egrep "1|2abc"
1ee 1abc 2abc示例10:() 字符串分组,将括号中的字符串作为一个整体。
[root@yxp opt]#echo 1ee 1abc 2abc|egrep "(1|2)abc"
1ee 1abc 2abc示例11:提取ip地址
#法一
[root@yxp opt]#ifconfig ens33|grep "netmask"|grep -o -E "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}"|head -1
192.168.59.102
#法二:使用了分组
[root@yxp opt]#ifconfig ens33|grep "netmask"|egrep -o '([0-9]{1,3}.){3}[0-9]{1,3}'|head -1
192.168.59.102
5.位置锚定

示例1:行尾锚定,用于模式的最右侧
[root@yxp opt]#grep "bash$" /etc/passwd
root:x:0:0:root:/root:/bin/bash
yxp:x:1000:1000:yxp:/home/yxp:/bin/bash示例2:行首锚定,用于模式的最左侧
[root@yxp opt]#grep "^root" /etc/passwd
root:x:0:0:root:/root:/bin/bash示例3:用于模式匹配整行,匹配的内容单独在一行
[root@yxp opt]#echo root|grep "^root$"
root示例4:\< :只匹配右侧的单词
[root@yxp opt]#echo hello-123|grep "\<123"
hello-123示例5:\>:只匹配左侧的单词
[root@yxp opt]#echo hello-123 222|grep "hello\>"
hello-123 222示例6:过滤出不是以#开头的非空行
[root@yxp opt]#grep "^[^#]" /etc/fstab
/dev/mapper/centos-root / xfs defaults 0 0
UUID=183ca7c7-1989-4f43-9e81-d2676192f5a4 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
/dev/sdb1 /mnt xfs defaults 0 0
二.常见的管道命令
1.sort命令
sort命令可针对文本文件的内容,以行为单位来排序。
格式:sort [选项] 参数
常用选项:

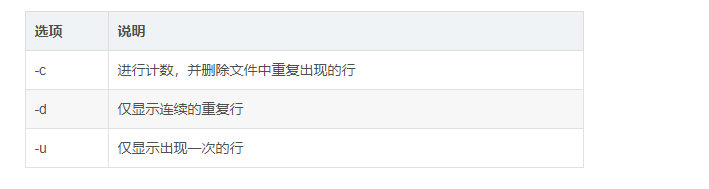
2.uniq命令
uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
格式:uniq [选项] 参数
常用选项:
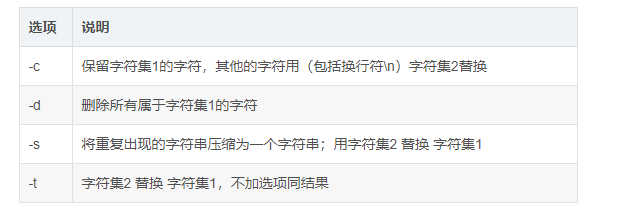
3.tr命令
常用来对来自标准输入的字符进行替换、压缩和删除。
常用选项
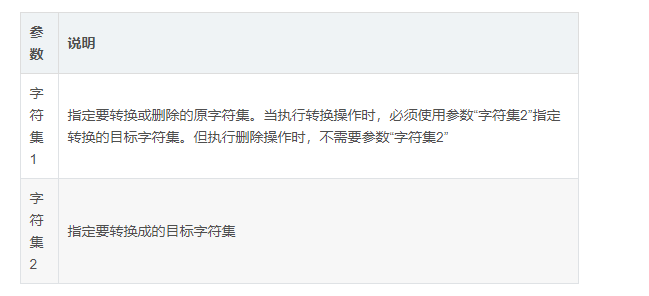
常用选项
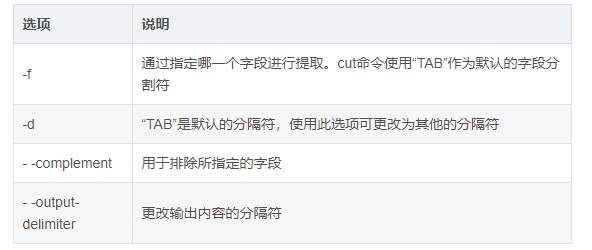
4.cut命令
显示行中的指定部分,删除文件中指定字段
格式:cut [选项] 参数
常用选项
5.实例
1.统计当前主机连接状态
[root@yxp data]#ss -ant|cut -d " " -f1|sort -n|uniq -c|head -2
2 ESTAB
13 LISTEN2.统计当前连接主机数
[root@yxp opt]#ss -ant|tr -s " "|cut -d" " -f5|cut -d":" -f1|sort|uniq -c|tail -n +3
3 192.168.59.1
1 192.168.59.118
1 Address