Java集合篇之深入解析LinkedList
写在开头
作为ArrayList的同门师兄弟,LinkedList的师门地位逊色不少,除了在做算法题的时候我们会用到它之外,在实际的开发工作中我们极少使用它,就连它的创造者都说:“I wrote it,and I never use it”,想想颇有点好笑,但这并不影响我们去学习它,个人认为它底层的链表逻辑对于我们代码思想的培养还是挺有帮助的。

源码解析
看过build哥文章的同学应该都知道,俺喜欢通过源码去学习和分析对象或代码逻辑,因此,话不多说,直接上源码!
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{
//...
} 如上为JDK8中LinkedList的继承实现关系,通过这些关系我们可以大致分析出它所具备的特性:
-
实现List接口 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问;
-
Deque继承自 Queue 接口,具有双端队列的特性,支持从两端插入和删除元素,方便实现栈和队列等数据结构;
-
Cloneable :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作;
-
Serializable : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
LinkedList提供了非常多的方法供我们使用,继续阅读源码可以看到
// 在链表尾部插入元素
public boolean add(E e) {
linkLast(e);
return true;
}
// 在链表指定位置插入元素
public void add(int index, E element) {
// 下标越界检查
checkPositionIndex(index);
// 判断 index 是不是链表尾部位置
if (index == size)
// 如果是就直接调用 linkLast 方法将元素节点插入链表尾部即可
linkLast(element);
else
// 如果不是则调用 linkBefore 方法将其插入指定元素之前
linkBefore(element, node(index));
}
// 将元素节点插入到链表尾部
void linkLast(E e) {
// 将最后一个元素赋值(引用传递)给节点 l
final Node l = last;
// 创建节点,并指定节点前驱为链表尾节点 last,后继引用为空
final Node newNode = new Node<>(l, e, null);
// 将 last 引用指向新节点
last = newNode;
// 判断尾节点是否为空
// 如果 l 是null 意味着这是第一次添加元素
if (l == null)
// 如果是第一次添加,将first赋值为新节点,此时链表只有一个元素
first = newNode;
else
// 如果不是第一次添加,将新节点赋值给l(添加前的最后一个元素)的next
l.next = newNode;
size++;
modCount++;
}
// 在指定元素之前插入元素
void linkBefore(E e, Node succ) {
// assert succ != null;断言 succ不为 null
// 定义一个节点元素保存 succ 的 prev 引用,也就是它的前一节点信息
final Node pred = succ.prev;
// 初始化节点,并指明前驱和后继节点
final Node newNode = new Node<>(pred, e, succ);
// 将 succ 节点前驱引用 prev 指向新节点
succ.prev = newNode;
// 判断尾节点是否为空,为空表示当前链表还没有节点
if (pred == null)
first = newNode;
else
// succ 节点前驱的后继引用指向新节点
pred.next = newNode;
size++;
modCount++;
}
// 获取链表的第一个元素
public E getFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// 获取链表的最后一个元素
public E getLast() {
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
// 获取链表指定位置的元素
public E get(int index) {
// 下标越界检查,如果越界就抛异常
checkElementIndex(index);
// 返回链表中对应下标的元素
return node(index).item;
} 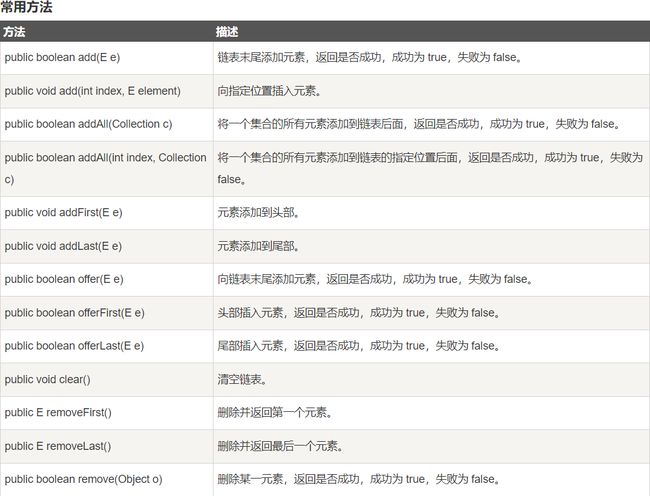
更多的API方法可以参考:LinkedList全量方法
使用LinkedList
在Java中我们写一个小测试代码来用一下LinkedList的增删改查
【代码示例1】
// 创建LinkedList集合
LinkedList link = new LinkedList();
// 1、添加元素
link.add("happy");
link.add("new");
link.offer("year"); // 向集合尾部追加元素
link.push("javabuild"); // 向集合头部添加元素
System.out.println(link); // 输出集合中的元素
// 2、获取元素
Object object = link.peek(); //获取集合第一个元素
System.out.println(object); // 输出集合中的元素
// 3、删除元素
link.removeFirst(); // 删除集合第一个元素
link.pollLast(); // 删除集合最后一个元素
System.out.println(link);输出:
[javabuild, happy, new, year]
javabuild
[happy, new]对比ArrayList
-
ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
ArrayList 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构;
-
LinkedList 不支持高效的随机元素访问,而 ArrayList(实现了 RandomAccess 接口) 支持。
-
ArrayList存在扩容问题,LinkedList不存在,直接放在集合尾部,修改指针即可;
提问:为什么LinkedList不支持高效的随机访问,或者说为什么不去实现RandomAccess 接口?
我们看过RandomAccess 接口的底层的同学知道,这个接口也是个标识性接口,只要实现了这个接口就意味着支持通过索引访问元素。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。但是!在LinkedList中依旧提供了get(int index):获取链表指定位置的元素。
// 获取链表指定位置的元素
public E get(int index) {
// 下标越界检查,如果越界就抛异常
checkElementIndex(index);
// 返回链表中对应下标的元素
return node(index).item;
}源码中get方法实现通过位置获取元素的核心是node(index)方法,我们跟进去继续看一下!
// 返回指定下标的非空节点
Node node(int index) {
// 断言下标未越界
// assert isElementIndex(index);
// 如果index小于size的二分之一 从前开始查找(向后查找) 反之向前查找
if (index < (size >> 1)) {
Node x = first;
// 遍历,循环向后查找,直至 i == index
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} 该方法中通过传入的index参数和size的1/2进行比较,小于则从链表头向后查找,否则从链表尾向前遍历查找,这与ArrayList中的get(index)方法还是有本质上的区别!
文章转载自:https://www.cnblogs.com/JavaBuild/p/18018733
原文链接:JavaBuild
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构