数据分析 — Pandas 数据加载、存储和清洗
目录
- 一、文件读取
-
- 1、常见文件读取函数
- 2、read_csv()
- 3、read_table()
- 4、read_excel()
- 5、read_json()
- 6、read_html()
- 7、大文件读取
- 二、数据保存
-
- 1、csv
- 2、excel
- 3、json
- 4、html
- 5、MySQL
-
- 1、连接数据库
- 2、MySQL 存储到本地
- 3、本地存储到 MySQL
- 三、数据清洗
-
- 1、处理缺失值
-
- 1、判断数据是否为 NAN
- 2、删除缺失值
- 3、填充缺失值
- 2、处理异常值
- 3、处理重复值
-
- 1、判断是否重复
- 2、默认保留第一个出现的重复行,后续的重复行将被删除
- 3、对某列进行去重
- 4、数据转换
- 5、数据离散化
-
- 1、按指定边界值切分
- 2、等距分箱
- 3、等频分箱
- 四、应用
一、文件读取
1、常见文件读取函数
| 函数 | 说明 |
|---|---|
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为逗号。 |
| read_table | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为制表符(‘\t’)。 |
| read_excel | 从 Excel XLS 或 XLSX file 读取表格数据。 |
| read_json | 读取 JSON(JavaScript Object Notation)字符串中的数据。 |
| read_sql | (使用 SQLAlchemy)读取 SQL 查询结果为 pandas 的 DataFrame。 |
| read_html | 读取 HTML 文档中的所有表格。 |
| read_hdf | 读取 pandas 写的 HDF5 文件。 |
| read_clipboard | 读取剪贴板中的数据,可以看做 read_table 的剪贴板版。在将网页转换为表格时很有用。 |
| read_msgpack | 二进制格式编码的 pandas 数据。 |
| read_pickle | 读取 Python pickle 格式中存储的任意对象。 |
| read_sas | 读取存储于 SAS 系统自定义存储格式的 SAS 数据集。 |
| read_fwf | 读取定宽列格式数据(也就是说,没有分隔符)。 |
| read_stata | 读取 Stata 文件格式的数据集。 |
| read_feather | 读取 Feather 二进制文件格式。 |
2、read_csv()
read_csv() 是 Pandas 库中的函数,用于从 CSV 文件中读取数据并创建一个 DataFrame。
CSV 格式比 Excel 能存储更多数据,CSV 读取性能比 Excel 会高很多。
参数:
-
filepath_or_buffer:这是必选参数,指定要读取的 CSV 文件的路径或 URL。可以是一个字符串,也可以是类似文件对象的可迭代对象(例如文件句柄)。
-
sep:指定 CSV 文件中的字段分隔符。默认值是逗号(,),但可以根据文件的实际分隔符来设置这个参数,例如制表符(\t)或分号(;)。
-
delimiter:sep 的别名,用于指定字段分隔符。
-
header:指定用作列名的行号。通常为整数,如果没有列名行,可以设置为 None。默认值为 0,表示第一行包含列名。
-
names:如果没有列名行,可以通过此参数提供列名的列表。与 header=None 一起使用。
-
index_col:用于指定哪一列作为 DataFrame 的索引列。可以是列名、列号或多列的组合。
-
usecols:指定要读取的列,可以是列名的列表或列号的列表。用于仅读取感兴趣的列,而不是整个文件。
-
skiprows:指定要跳过的行数,通常用于跳过文件中的标题或注释行。
-
nrows:指定要读取的行数,可以用于限制读取的数据量。
-
dtype:用于指定列的数据类型的字典,可以帮助优化内存使用和数据类型转换。
-
encoding:指定 CSV 文件的字符编码,常见的编码包括 “utf-8”、“ISO8859-1” 等。
-
parse_dates:指定要解析为日期时间的列,可以是列名或列号的列表。
-
date_parser:自定义日期时间解析函数,用于将字符串解析为日期时间对象。
-
na_values:指定要视为缺失值的标记值列表,例如 “NA”、“N/A”、“null” 等。
-
skipinitialspace:指定是否跳过字段值前的空白字符,默认为 False。
-
skip_blank_lines:指定是否跳过空白行,默认为 True。
-
quotechar:指定用于引用字段值的字符,通常为双引号或单引号。
-
compression:指定文件的压缩格式,例如 “gzip”、“bz2”、“xz” 等。
-
thousands:用于指定千位分隔符的字符。
常用参数案例:
1、文件路径 path 和编码方式 encoding
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,encoding='ANSI')
print(data)
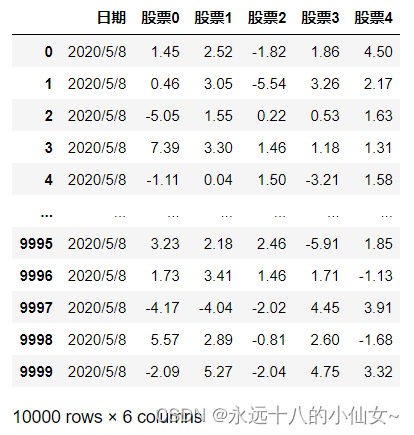
查看编码方式 encoding
将文件选择记事本方式打开,另存为时有编码方式
2、设置表头 header
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
# header=0 表示物理的第一行设置为表头
data = pd.read_csv(path,header=0,encoding='ANSI')
print(data)
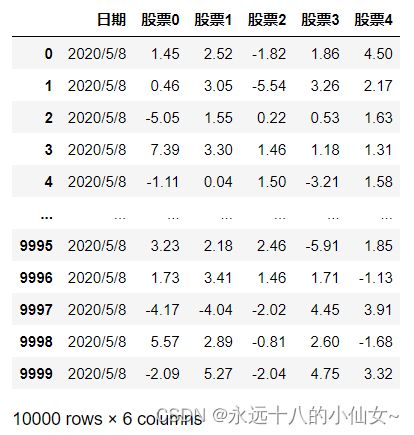
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
# header=1 表示物理的第二行设置为表头
data = pd.read_csv(path,header=1,encoding='ANSI')
print(data)

import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
# header=None 表示源数据不设置表头
data = pd.read_csv(path,header=None,encoding='ANSI')
print(data)

3、设置索引列 index_col
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,index_col=1,encoding='ANSI')
print(data)
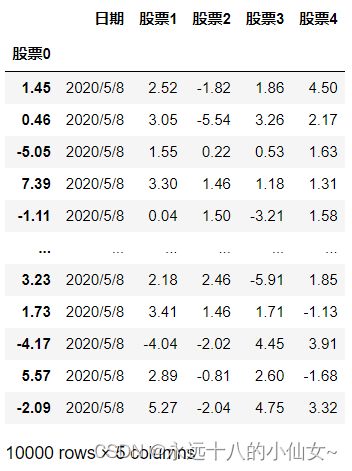
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,index_col='日期',encoding='ANSI')
print(data)

4、取部分列 usecols
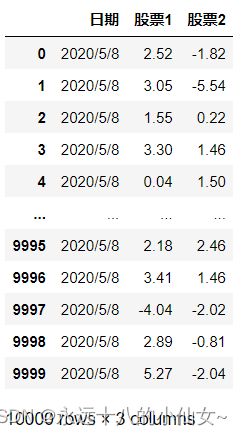
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,usecols=[0,2,3],encoding='ANSI')
print(data)
5、元素的类型 dtype
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,encoding='ANSI')
# 查看类型
print(type(data)) # 6、设置某列为日期格式 parse_dates
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\exa5.csv'
data = pd.read_csv(path,parse_dates=['日期'],encoding='ANSI')
print(data.info())
# 7、把指定值变成空值 na_values
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data1.csv'
data = pd.read_csv(path,na_values=[2.52],encoding='ANSI')
print(data)

3、read_table()
参数同 read_csv(), read_csv() 和 read_table() 之间的区别主要是函数名称,默认分隔符的历史设置。
在当前版本的 Pandas 中,它们几乎可以互相替代,只需根据实际数据文件的分隔符来设置 sep 参数即可。
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data1.csv'
data = pd.read_table(path,encoding='ANSI')
print(data)
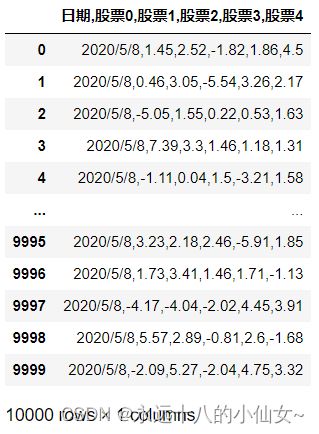
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data1.csv'
# 可以读取 csv 文件
data = pd.read_table(path,encoding='ANSI',sep=',')
print(data)
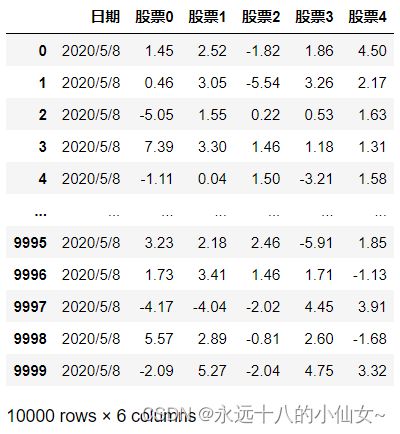
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data2.txt'
data = pd.read_table(path)
print(data)

import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data2.txt'
# 如果分裂空格个数不一致,可使用正则方式进行匹配
data = pd.read_table(path,sep='\s+')
print(data)

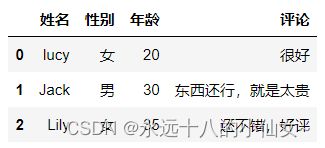
4、read_excel()
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data3.xlsx'
# 读取表格指定工作表数据
# sheet_name='评论' 或 sheet_name=1
data = pd.read_excel(path,sheet_name='评论')
print(data)
5、read_json()
// F:\data\data4.json
[
{
"id": "A001",
"name": "百度",
"url": "www.baidu.com"
},
{
"id": "A002",
"name": "谷歌",
"url": "www.google.com"
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com"
}
]
import pandas as pd # 导入 Pandas 库并使用别名 pd
path = r'F:\data\data4.json'
data = pd.read_json(path,encoding='utf-8')
print(data)
print(type(data)) # 
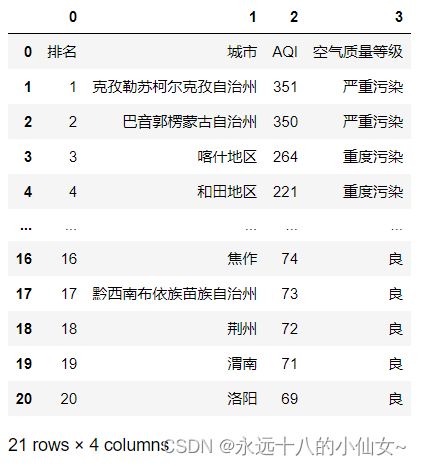
6、read_html()
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.read_html('https://www.air-level.com/rank')
print(data)

import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.read_html('https://www.air-level.com/rank')[0]
print(data)
7、大文件读取
import pandas as pd # 导入 Pandas 库并使用别名 pd
# 设置文件路径
path = r'F:\data\data1.csv'
# 使用 Pandas 的 read_csv 函数读取 CSV 文件,chunksize=1000 表示每次读取1000行数据,encoding='ANSI' 指定编码方式为ANSI
data = pd.read_csv(path, chunksize=1000, encoding='ANSI')
# 创建一个空列表用于存储分块数据
chunks = []
# 遍历每个数据块
for chunk in data:
# 将每个数据块转换为 Pandas DataFrame
chunk = pd.DataFrame(chunk)
# 将 DataFrame 添加到 chunks 列表中
chunks.append(chunk)
# 使用 concat 函数将所有数据块连接成一个完整的数据集
dataCount = pd.concat(chunks)
# 打印合并后的数据集
print(dataCount)
二、数据保存
1、csv
data.to_csv('数据.csv',header=True,index=True,mode='w')
2、excel
data.to_excel('./数据.xlsx',sheet_name='详细数据',index=True,header=True)
3、json
data.to_json('数据.json')
4、html
data.to_html('./haha.html',encoding='utf-8')
5、MySQL
1、连接数据库
方式一
import pymysql # 导入 pymysql 模块,用于连接 MySQL 数据库
import pandas as pd # 导入 Pandas 库并使用别名 pd
# 使用 pymysql.connect() 函数建立 MySQL 数据库连接,提供主机名、用户名、密码、数据库名、端口号和字符集等信息
conn = pymysql.connect(
host='localhost', # 数据库主机名
user='root', # 数据库用户名
password='123456', # 数据库密码
db='shop', # 要连接的数据库名
port=3306, # 数据库端口号,默认为3306
charset='utf8' # 字符集设置为utf8,确保支持中文字符
)
# 定义 SQL 查询语句,从名为 "custom" 的表中选取所有数据
sql = """select * from custom"""
# 使用 pandas 的 read_sql() 函数从数据库中读取数据,并存储在 DataFrame 中
data = pd.read_sql(sql, conn)
# 打印 DataFrame 中的数据
print(data)
方式二
import sqlalchemy # 导入 sqlalchemy 模块,用于数据库连接
import pandas as pd # 导入 Pandas 库并使用别名 pd
# 使用 sqlalchemy.create_engine() 函数创建 MySQL 数据库引擎对象,提供数据库连接信息
engine = sqlalchemy.create_engine('mysql+pymysql://root:123456@localhost:3306/shop?charset=utf8')
# 打印数据库引擎对象,这里主要是为了确认数据库连接信息是否正确
print(engine)
# 定义 SQL 查询语句,从名为 "custom" 的表中选取所有数据
sql = """select * from custom"""
# 使用 pandas 的 read_sql() 函数从数据库中读取数据,并存储在 DataFrame 中
data = pd.read_sql(sql, engine)
# 打印 DataFrame 中的数据
print(data)
2、MySQL 存储到本地
data.to_excel('./shop.xlsx')
3、本地存储到 MySQL
data.to_sql(name='custom2',con='mysql+pymysql://root:123456@localhost:3306/shop?charset=utf8',if_exists='replace',index=False)
三、数据清洗
1、处理缺失值
1、判断数据是否为 NAN
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
data = pd.Series(['one','two',np.nan,'four',np.nan])
print(data)
# 0 one
# 1 two
# 2 NaN
# 3 four
# 4 NaN
# dtype: object
# 返回哪些值是缺失值的布尔值
print(pd.isnull(data))
# 0 False
# 1 False
# 2 True
# 3 False
# 4 True
# dtype: bool
# 返回值是 isnull 的反集
print(pd.notnull(data))
# 0 True
# 1 True
# 2 False
# 3 True
# 4 False
# dtype: bool
2、删除缺失值
dropna() 是 Pandas 库中的一个函数,用于从数据框(DataFrame)或者 Series 中删除包含缺失值(NaN 或 None)的行或列。
参数:
-
axis(可选参数):指定要删除的轴,可以是 0(默认值)表示删除行,或者 1 表示删除列。
-
axis=0(默认值):删除包含缺失值的行。
-
axis=1:删除包含缺失值的列。
-
-
how(可选参数):指定删除的方式。
- how=‘any’(默认值):只要某行或列中存在任何缺失值,就删除该行或列。
- how=‘all’:只有当某行或列中所有元素都是缺失值时,才删除该行或列。
-
thresh(可选参数):指定在删除行或列之前必须满足的非缺失值数量的阈值。默认值为 None,表示不考虑阈值。
- 示例:thresh=2:要求至少有 2 个非缺失值才能保留行或列。
-
subset(可选参数):指定要考虑的特定行或列的标签(label),默认值为 None。这个参数可以用来针对部分行或列执行 dropna() 操作。
- 示例:subset=[‘column1’, ‘column2’]:只在指定的列中删除包含缺失值的行。
-
inplace(可选参数):默认值为 False,表示返回一个新的数据框,不修改原始数据。如果设置为 True,则在原始数据上进行就地修改,并且不返回新的数据框。
1、删除包含缺失值的行
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'A': [1, 2, None, 4],'B': [5, None, 7, 8]})
print(data)
# A B
# 0 1.0 5.0
# 1 2.0 NaN
# 2 NaN 7.0
# 3 4.0 8.0
# 删除包含缺失值的行
result = data.dropna()
print(result)
# A B
# 0 1.0 5.0
# 3 4.0 8.0
2、删除包含缺失值的列
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[NA,8,8],[NA,NA,8],
[NA,4,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 NaN 8.0 8
# 1 NaN NaN 8
# 2 NaN 4.0 5
# 3 NaN 7.0 8
# 删除包含缺失值的列
result = data.dropna(axis=1)
print(result)
# 2
# 0 8
# 1 8
# 2 5
# 3 8
3、删除所有值为 NaN 的行
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,4,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN 4.0 5.0
# 3 NaN 7.0 8.0
# 删除所有值为 NaN 的行
result = data.dropna(how='all')
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 2 NaN 4.0 5.0
# 3 NaN 7.0 8.0
4、至少有 2 个非缺失值才能保留行或列
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 至少有 2 个非缺失值才能保留行或列
result = data.dropna(thresh=2)
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 3 NaN 7.0 8.0
3、填充缺失值
fillna() 是 Pandas 库中的一个函数,用于在数据框(DataFrame)或者 Series 中填充缺失值(NaN 或 None)。
参数:
- value(可选参数):用于填充缺失值的具体数值或字典,可以是标量(单个数值)、字典(列名与填充值的映射关系)、Series 或者 DataFrame。
- method(可选参数):指定填充缺失值的方法,可以是前向填充(‘ffill’),后向填充(‘bfill’)等。
- method=‘ffill’(默认值):前向填充。
- method=‘bfill’:后向填充。
- axis(可选参数):指定填充的轴,可以是 0(按列填充)或 1(按行填充)。
- axis=0(默认值):删除包含缺失值的行。
- axis=1:删除包含缺失值的列。
- inplace(可选参数):是否在原地修改数据框,默认值为 False,表示返回一个新的数据框,不修改原始数据。如果设为 True,将不返回新的数据框,而是直接在原有数据框上进行修改。
- limit(可选参数):用于限制填充的数量,比如设为2,表示每列或每行最多只填充两个缺失值。
- downcast(可选参数):控制数据类型的转换,可以是 ‘integer’、‘signed’、‘unsigned’ 等。
1、填充为0
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 填充为0
result = data.fillna(0)
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 0.0 0.0 0.0
# 2 0.0 0.0 5.0
# 3 0.0 7.0 8.0
2、不同列填充不值
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 不同列填充不值
result = data.fillna({0:100,1:200,2:300})
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 100.0 200.0 300.0
# 2 100.0 200.0 5.0
# 3 100.0 7.0 8.0
3、填充平均值
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 填充平均值
result = data.fillna(data.mean())
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 8.0 7.5 7.0
# 2 8.0 7.5 5.0
# 3 8.0 7.0 8.0
4、向上填充
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 向上填充
result = data.fillna(method='ffill')
# 高版本写法
# result = data.ffill()
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 8.0 8.0 8.0
# 2 8.0 8.0 5.0
# 3 8.0 7.0 8.0
5、向下填充
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN NaN NaN
# 2 NaN NaN 5.0
# 3 NaN 7.0 8.0
# 向下填充
result = data.fillna(method='bfill')
# 高版本写法
# result = data.bfill()
print(result)
# 0 1 2
# 0 8.0 8.0 8.0
# 1 NaN 7.0 5.0
# 2 NaN 7.0 5.0
# 3 NaN 7.0 8.0
6、把下标为1的列转成字符串
import pandas as pd # 导入 Pandas 库并使用别名 pd
from numpy import nan as NA # 将NumPy库中的NaN(Not a Number)定义为NA
data = pd.DataFrame([[8,8,8],[NA,NA,NA],
[NA,NA,5],[NA,7,8]])
print(data.info())
# 2、处理异常值
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
data = pd.DataFrame(np.random.randn(1000,4))
print(data)
# 0 1 2 3
# 0 1.593943 -0.044275 1.657758 0.771481
# 1 -0.747987 -1.225241 -0.306258 -0.457629
# 2 0.902807 0.783800 0.914563 -0.929200
# 3 -1.516675 -0.361840 0.067688 -0.323513
# 4 -0.162813 0.075606 0.828714 -1.907542
# .. ... ... ... ...
# 995 -0.760415 1.091292 0.453288 -0.072843
# 996 -0.644722 -3.389364 0.462951 1.742291
# 997 -2.130310 -0.406691 0.656790 -1.790120
# 998 0.079858 -1.282808 1.425582 0.118225
# 999 -1.201616 -0.747731 -0.566635 0.396431
#
# [1000 rows x 4 columns]
# 查看大概
# count:非空计数个数,mean:平均值,std:标准差,min:最小值,max:最大值
# 25%:表示25%分位,50%:表示50%分位,75%:表示75%分位
print(data.describe())
# 0 1 2 3
# count 1000.000000 1000.000000 1000.000000 1000.000000
# mean 0.033990 0.079743 -0.025394 -0.037519
# std 0.987878 0.994122 1.024085 1.017784
# min -3.422642 -3.389364 -3.218303 -3.292692
# 25% -0.619548 -0.609269 -0.743909 -0.711874
# 50% 0.048188 0.090974 0.012549 -0.029922
# 75% 0.713032 0.770695 0.682448 0.658831
# max 3.029603 3.100089 3.340088 3.041642
data.iloc[1,1] = 10000
print(data.describe())
# 0 1 2 3
# count 1000.000000 1000.000000 1000.000000 1000.000000
# mean -0.014753 10.010379 0.018077 -0.023255
# std 1.021477 316.228973 1.028808 0.994172
# min -2.811835 -3.671985 -3.021773 -2.878964
# 25% -0.698100 -0.665801 -0.695405 -0.686040
# 50% -0.011187 -0.007452 -0.006795 0.008633
# 75% 0.706559 0.708378 0.694225 0.630325
# max 2.966771 10000.000000 3.183331 3.617062
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'A': [1, 2, 3, -999, 5],'B': [-1, 7, -999, 9, 10]})
print(data)
# A B
# 0 1 -1
# 1 2 7
# 2 3 -999
# 3 -999 9
# 4 5 10
# 将异常值-999替换为 NaN
data.replace(-999, float('nan'), inplace=True)
# 输出替换后的数据框
print(data)
# A B
# 0 1.0 -1.0
# 1 2.0 7.0
# 2 3.0 NaN
# 3 NaN 9.0
# 4 5.0 10.0
# 定义替换规则,将-999替换为 NaN,将-1替换为0
replace_dict = {-999: float('nan'), -1: 0}
# 应用替换规则到数据框
data.replace(replace_dict, inplace=True)
# 输出替换后的数据框
print(data)
# A B
# 0 1.0 0.0
# 1 2.0 7.0
# 2 3.0 NaN
# 3 NaN 9.0
# 4 5.0 10.0
Series.replace() 是 Pandas 库中用于替换 Series 中元素值的函数。它允许用户根据指定的规则,将 Series 中的某个值替换为另一个值或一组值。
参数:
-
to_replace(可选参数):指定要替换的值。
- 示例:to_replace=5,表示要将 Series 中的所有值为 5 的元素进行替换。
-
value(可选参数):用于替换 to_replace 中指定值的具体数值或字典。
- 示例:value=10,表示将 to_replace 中的值为 5 的元素替换为 10。
-
inplace(可选参数):是否在原地修改 Series,默认值为 False。如果设为 True,将不返回新的 Series,而是直接在原有 Series 上进行修改。
- 示例:inplace=True,在原始 Series 上就地进行值的替换,不返回新的 Series。
-
limit(可选参数):用于限制替换的数量,比如设为2,表示最多只替换两次。默认值为 False。
- 示例:limit=2,最多替换两次。
-
regex(可选参数):是否启用正则表达式进行匹配,默认值为 False。如果设为 True,to_replace 可以是正则表达式。
- 示例:regex=True,使用正则表达式进行匹配。
-
method(可选参数):指定替换的方法,可选值为 ‘pad’、‘ffill’(前向填充)或 ‘bfill’(后向填充)。
-
method=‘pad’:前向填充,也被称为 forward fill,使用该值之前的最近的非缺失值来替换缺失值。
-
method=‘ffill’:前向填充,ffill 是 forward fill 的缩写。与 ‘pad’ 相同,使用该值之前的最近的非缺失值来替换缺失值。
-
method=‘bfill’:后向填充,也被称为 backward fill。使用该值之后的最近的非缺失值来替换缺失值。
-
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.Series([4000,5000,9000,900000,-1000])
data = data.replace(-1000,6000)
print(data)
# 0 4000
# 1 5000
# 2 9000
# 3 900000
# 4 6000
# dtype: int64
data = data.replace({900000:9000,-1000:6000})
print(data)
# 0 4000
# 1 5000
# 2 9000
# 3 9000
# 4 6000
# dtype: int64
3、处理重复值
drop_duplicates() 是 Pandas 库中用于删除 DataFrame 或 Series 中重复行的函数。该函数默认根据所有列的数值进行比较,并删除相同的行,保留第一次出现的行。
参数:
- subset(可选参数):指定要考虑的特定列或列的标签,用于确定重复性。只考虑这些列的数值,而不是整行。默认值为 False。
- 示例:subset=[‘column1’, ‘column2’],只在指定的列中判断重复性。
- keep(可选参数):确定保留哪个重复的实例。
- keep= ‘first’(默认值):保留第一次出现的实例。
- keep=‘last’:保留最后一次出现的实例。
- keep=False:删除所有重复的实例。
- inplace(可选参数):是否在原地修改 DataFrame 或 Series,如果设为 True,将不返回新的对象,而是直接在原有对象上进行修改。默认值为 False。
- 示例:inplace=True,在原始 DataFrame 或 Series 上就地删除重复行,不返回新的对象。
1、判断是否重复
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'k1':list('abababaa'),'k2':[1,1,2,2,3,3,4,4]})
print(data)
# k1 k2
# 0 a 1
# 1 b 1
# 2 a 2
# 3 b 2
# 4 a 3
# 5 b 3
# 6 a 4
# 7 a 4
# 判断是否重复
print(data.duplicated().sum()) # 1
2、默认保留第一个出现的重复行,后续的重复行将被删除
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'k1':list('abababaa'),'k2':[1,1,2,2,3,3,4,4]})
print(data)
# k1 k2
# 0 a 1
# 1 b 1
# 2 a 2
# 3 b 2
# 4 a 3
# 5 b 3
# 6 a 4
# 7 a 4
# 默认保留第一个出现的重复行,后续的重复行将被删除
print(data.drop_duplicates())
# k1 k2
# 0 a 1
# 1 b 1
# 2 a 2
# 3 b 2
# 4 a 3
# 5 b 3
# 6 a 4
3、对某列进行去重
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'k1':list('abababaa'),'k2':[1,1,2,2,3,3,4,4]})
print(data)
# k1 k2
# 0 a 1
# 1 b 1
# 2 a 2
# 3 b 2
# 4 a 3
# 5 b 3
# 6 a 4
# 7 a 4
# 对某列进行去重
print(data.drop_duplicates(['k1']))
# k1 k2
# 0 a 1
# 1 b 1
4、数据转换
需求:data 加一列 “animal”
1、对 food 处理,把它全部变成小写
2、使用 map 对字典映射
3、加入到原数据里
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'food':['Banana','bone','Grass','fish','worm'],'calorie':[10,20,30,40,50]})
print(data)
# food calorie
# 0 Banana 10
# 1 bone 20
# 2 Grass 30
# 3 fish 40
# 4 worm 50
eat_animal = {
'grass':'cattle',
'banana':'monkey',
'fish':'cat',
'worm':'frog' ,
'bone':'dog'
}
data["animal"] = data['food'].str.lower().map(eat_animal)
print(data)
# food calorie animal
# 0 Banana 10 monkey
# 1 bone 20 dog
# 2 Grass 30 cattle
# 3 fish 40 cat
# 4 worm 50 frog
5、数据离散化
pd.cut() 是 Pandas 中用于将连续数据分割成离散区间的函数,通常用于数据的离散化或分箱处理。
参数:
-
x(必需参数):要分割的数据,可以是 Series 或数组。
-
bins(必需参数):用于指定分割区间的边界值,可以是一个整数、序列(例如列表或数组),或者一个区间数。如果是整数,表示分成的等宽区间数;如果是序列,表示自定义的分割点;如果是区间数,表示区间范围。
-
labels(可选参数):用于指定每个区间的标签,通常是字符串或者其他可哈希的对象。如果未指定,结果将包含区间的标签。
-
right(可选参数,默认为 True):指定区间的开闭,如果为 True,区间右侧是闭区间,如果为 False,区间右侧是开区间。
-
include_lowest(可选参数,默认为 False):指定最左侧的区间是否包含在分箱中。
-
retbins(可选参数,默认为 False):如果为 True,则返回划分的区间。
-
precision(可选参数):区间精度,用于四舍五入区间边界值。
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
# 创建一个示例的一维数组
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 定义区间的方式
bins = [0, 3, 6, 9, 12]
# 使用 pd.cut() 进行离散化
data = pd.cut(data, bins, right=True, labels=['Category 1', 'Category 2', 'Category 3', 'Category 4'])
# 输出离散化后的数据
print(data)
# ['Category 1', 'Category 1', 'Category 1', 'Category 2', 'Category 2', 'Category 2', 'Category 3', 'Category 3', 'Category 3', 'Category 4']
# Categories (4, object): ['Category 1' < 'Category 2' < 'Category 3' < 'Category 4']
1、按指定边界值切分
import pandas as pd # 导入 Pandas 库并使用别名 pd
data = pd.DataFrame({'Scores': [85, 92, 78, 60, 72, 88, 92, 98, 55, 75]})
print(data)
# Scores
# 0 85
# 1 92
# 2 78
# 3 60
# 4 72
# 5 88
# 6 92
# 7 98
# 8 55
# 9 75
# 按指定边界值切分
bins = [0,60,70,80,90,100]
# 使用 right=False 表示右边不包含 [0,60) [60,70) [70,80)... labels 给分段打标签
data['Level']=pd.cut(data['Scores'],bins,labels=['E','D','C','B','A'],right=False)
print(data)
# Scores Level
# 0 85 B
# 1 92 A
# 2 78 C
# 3 60 D
# 4 72 C
# 5 88 B
# 6 92 A
# 7 98 A
# 8 55 E
# 9 75 C
2、等距分箱
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
# 等距分箱 --- 区间相等或近似相等
data = np.random.randint(1,30,30)
print(data)
# [10 17 6 17 13 29 14 21 27 2 1 5 20 13 18 3 28 1 20 5 4 23 17 22 16 26 8 18 18 23]
dd = pd.cut(data,5)
# 统计值的个数
print(dd.value_counts())
# (0.972, 6.6] 9
# (6.6, 12.2] 9
# (12.2, 17.8] 2
# (17.8, 23.4] 5
# (23.4, 29.0] 5
# Name: count, dtype: int64
3、等频分箱
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
# 等频分箱---落在每个区间的数据点的个数相等或近似相等
data = np.random.randint(1,100,50) # 取1-100之间的随机整数,取50个
print(data)
# [55 2 7 57 82 62 78 13 5 31 82 98 26 50 72 92 34 49 72 26 16 21 9 21 6 47 57 12 53 48 99 95 11 43 91 19 39 50 54 82 51 45 59 90 54 25 18 67 53 62]
# 分为4个区间
dd = pd.qcut(data,4)
print(dd.value_counts())
# (1.999, 22.0] 13
# (22.0, 50.0] 13
# (50.0, 65.75] 11
# (65.75, 99.0] 13
# Name: count, dtype: int64
四、应用
按需求清洗数据
import pandas as pd # 导入 Pandas 库并使用别名 pd
import numpy as np # 导入 NumPy 库并使用别名 np
# 读取 CSV 文件到 DataFrame,设置第一列为索引
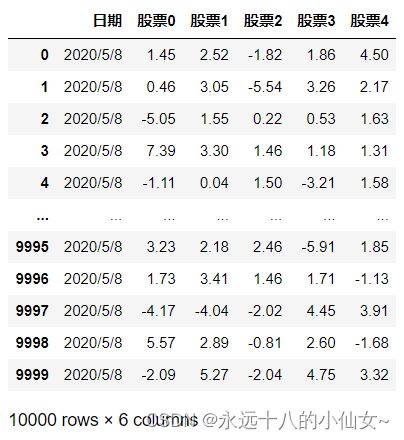
data = pd.read_csv(r'F:\data\电子产品销售分析.csv', index_col=0)
# 显示数据集的前几行
data.head()

# 查看数据集的概览信息
data.info()

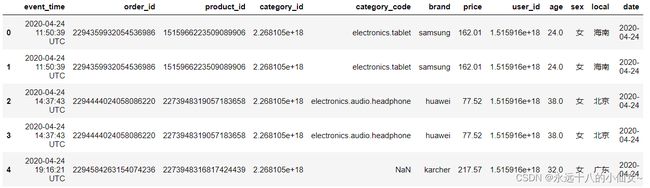
# 处理 'event_time' 列,提取日期和时间
f = lambda x: x.split(' ')[0] # 定义匿名函数提取日期
data['date'] = data['event_time'].map(f) # 创建新的 'date' 列存储日期
# 显示数据集的前几行
data.head()
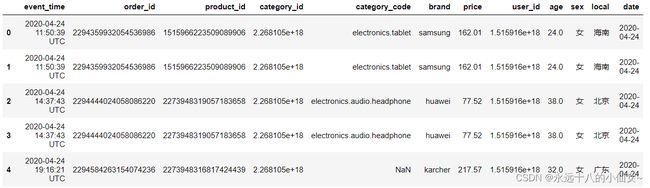
f = lambda x: x.split(' ')[1] # 定义匿名函数提取时间
data['time'] = data['event_time'].map(f) # 创建新的 'time' 列存储时间
# 显示数据集的前几行
data.head()
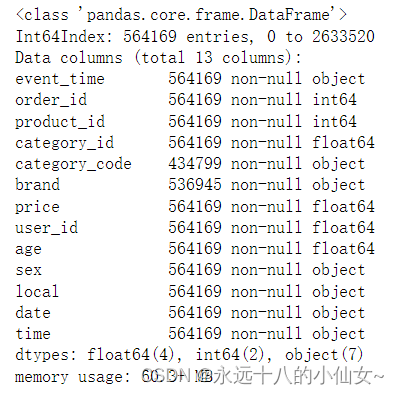
# 查看数据集的概览信息
data.info()
# 将 'date' 列转换为日期格式
data['date'] = pd.to_datetime(data['date'])
# 查看数据集的概览信息
data.info()

# 提取日期中的月份,年份和季度
data['month'] = data['date'].dt.month
data['year'] = data['date'].dt.year
data['quarter'] = data['date'].dt.quarter
# 显示数据集的前几行
data.head()
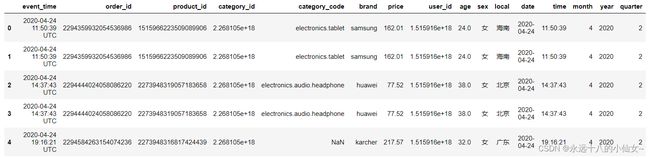
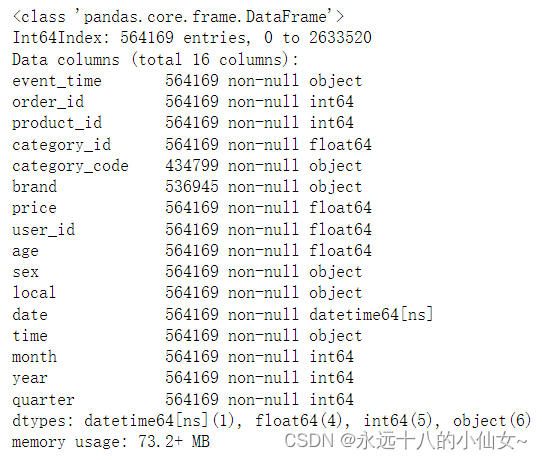
# 查看数据集的概览信息
data.info()
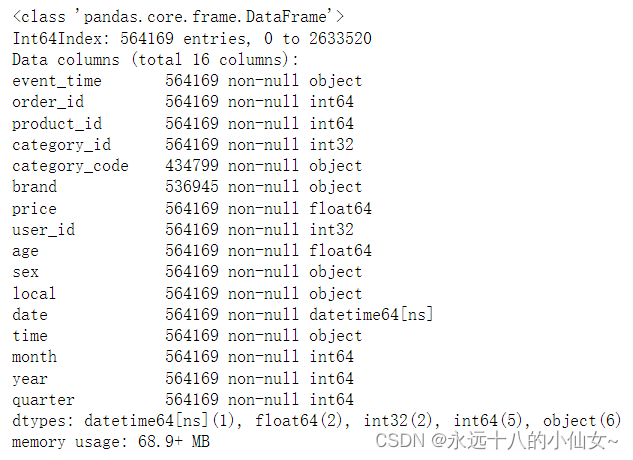
# 将 'user_id' 和 'category_id' 列转换为整数类型
data['user_id'] = data['user_id'].astype('int')
data['category_id'] = data['category_id'].astype('int')
# 查看数据集的概览信息
data.info()
# 检查数据集中的缺失值
data.isnull().sum()
# 将 'category_code' 列的空值填充为 'N'
data['category_code'].fillna('N', inplace=True)
# 查看数据集的概览信息
data.info()

# 删除数据集中的重复值
data.drop_duplicates(inplace=True)
# 检查数据集中的异常值,使用 describe() 默认只统计数值数据
data.describe(include='all')
# 按条件筛选数据集,保留 'date' 大于等于 '2020-01-01' 的行
data2 = data[data['date'] >= '2020-01-01']
# 显示数据集的前几行
data2.head()

# 打印筛选后的数据集的形状
data2.shape # (562188, 16)
记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~