springboot第56集:微服务框架,物联网IOT,SQL数据库MySQL底层,AOP收集业务操作日志架构周刊...
单点登录
1.配置代理信息
/*请求登陆的方法*/
"/modelLogin": {
//本地服务接口地址,这是测试环境,正式环境需要更改下地址
target: "http://127.0.0.1:6776/xxx-auth/",
changeOrigin: true,
pathRewrite: {
"^/modelLogin": "",
},
},
//异步进行登录
this.$store.dispatch("LoginPrammeSystem", loginForm).then(() => {
//跳转到指定连接(正式环境需要更改地址)
window.open("http://localhost:1889/");
}); image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png
MySQL对于千万级的大表如何优化
优化你的sql、索引
B+树
sql优化
避免多表联合查询,优化难度大
设置合理的查询字段,避免多次回表
索引
建立合适的索引
避免索引失效
优点
解决读的性能瓶颈
缺点
缓存数据库一致性
缓存穿透
缓存雪崩
缓存击穿
架构复杂(高可用)
客户端直接连接 客户端直连方案,因为少了一层 proxy 转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。中间件:ShardingSphere
带proxy 带 proxy 的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由 proxy 完成的。但这样的话,对后端维护团队的要求会更高。而且,proxy 也需要有高可用架构。因此,带 proxy 架构的整体就相对比较复杂。中间件:ShardingSphere 、Atlas 、mycat
优点
分担主库的压力
缺点
从延迟,导致往主库写入的数据跟从库读出来的数据不一致
优点
优化单一表数据量过大而产生的性能问题
避免IO争抢并减少锁表的几率
缺点
主键避免重复(分布式Id)
跨节点分页、排序函数
数据多次扩展难度跟维护量极大
 image.png
image.png 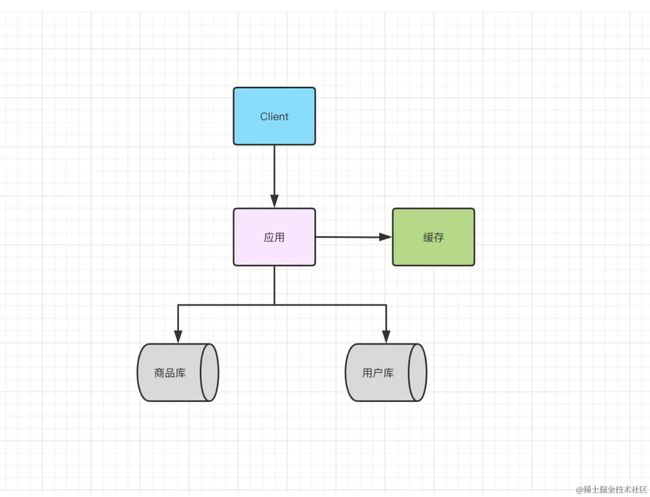 image.png
image.png  image.png
image.png 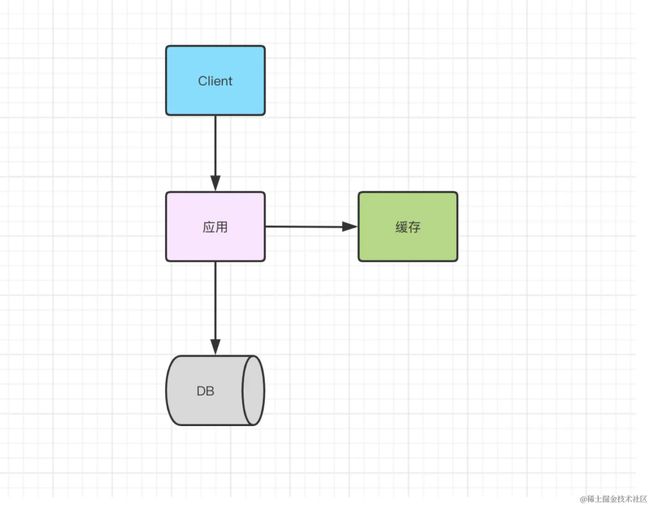 image.png
image.png  image.png
image.png
mac安装Elasticsearch
使用的是2.3.2版本 下载的是tar版本的,然后解压。
cd elasticsearch-2.3.2
bin/elasticsearch
这时可能会报一个logs文件夹权限问题的错误
sudo chown -R dalaoHang logs
重启es
在页面访问http://localhost:9200/
安装一个可视化插件,elasticsearch-head
sudo bin/plugin install mobz/elasticsearch-head
安装成功后,重启es,访问http://localhost:9200/_plugin/head/
Linux文件结构与文件权限
d:代表当前文件为文件夹
l:代表当前文件为超连接文件
b:该文件提供为提供给系统存取的设备,例如你计算机的硬盘所存储的数据内容,可能都会保存在这个类型文件中
c:代表着连接到你计算机的一些硬件设备,例如鼠标、键盘等配置文件开头都是以c开头的
一个b打头的文件,这个文件是提供系统存储的数据且可能硬盘也可能是其他存储设备的
ll /dev/sda
c打头的文件则是硬件设备
而c打头的文件则是硬件设备,我们不妨键入 ll /dev查看一下 BUS总线,以及CPU等这些都是硬件设备
在Linux中隐藏文件大多以.开头
ls -al查看
1. /:根目录,与开机系统有关
2. /usr(unix software resource):与软件的安装和执行有关
3. /var(variable):与系统的运作有关根目录下有个bin文件夹,我们日常使用Linux的时候都会用到ls、cat、touch、mkdir等基本操作命令都存放于bin目录下
接下来是/boot,这个目录存放的基本都是Linux开机会用到配置文件,像Linux kerner常用到的文件名 vmlinuz就会存放在这个文件夹下
接下来是/dev,这个文件夹基本存放的都是硬件设备,我们都知道Linux主张一切皆文件,所以所有的鼠标、键盘、硬盘的设备信息都是存放在这个文件夹下
/etc目录则是存放配置文件的地方,常见我们的用户文件/etc/passwd,以及密码文件/etc/shadow,还有系统文件/etc/rc等都会存放在这个目录下。
mnt存放挂载相关。
lib存放库函数相关、
sbin存放开机、系统还原、修复等众多指令。
tmp存储临时文件习惯。
/usr/lib与根目录的lib功能相同,存放的基本是lib目录下的软链接。
/usr/local/则是FHS希望用户将下载的软件都放到这个目录下统一管理
/usr/sbin同样也是将根目录的sbin目录下的指令软链接到此。
/var/lock存放的则是被某个程序锁定的文件,已确保其他程序不会同时使用到这个文件
/var/lib存放的则是会临时改变的库文件
文件权限
r代表读权限。
w代表写权限。
x代表执行权限。
# 进入tmp目录
cd /tmp/
# 创建testDir文件夹
mkdir testDir
# 设置这个文件夹 所属者有所有权限 所属组和其他用户只有读和写权限
chmod 766 testDir/MySQL 并不是跳过 OFFSET 行,而是取 OFFSET+N 行,然后放弃前 OFFSET 行,最后返回 N 行,当 OFFSET 特别大的时候,效率就非常的低下
spring security支持的oauth resource server自带BearerTokenAuthenticationFilter去校验jwt,所以简单配置一个jwtDecoder就可以实现完全相同的功能
整合SpringSecurity和JWT实现登录认证和授权
SpringSecurity是一个强大的可高度定制的认证和授权框架,对于Spring应用来说它是一套Web安全标准。SpringSecurity注重于为Java应用提供认证和授权功能,像所有的Spring项目一样,它对自定义需求具有强大的扩展性。
其核心就是一组过滤器链,在spring security中一种过滤器处理一种认证方式,项目启动后将会自动配置
JWT是JSON WEB TOKEN的缩写,它是基于 RFC 7519 标准定义的一种可以安全传输的的JSON对象,由于使用了数字签名,所以是可信任和安全的。总结来说,JWT只是一个生成token的机制。
JWT的组成
JWT token的格式:header.payload.signature 可以在该网站上获得解析结果:jwt.io/
header中用于存放签名的生成算法
payload中用于存放用户名、token的生成时间和过期时间
signature为以header和payload生成的签名,一旦header和payload被篡改,验证将失败
JWT实现认证和授权的原理
用户调用登录接口,登录成功后获取到JWT的token;
之后用户每次调用接口都在http的header中添加一个叫Authorization的头,值为JWT的token;
后台程序通过对Authorization头中信息的解码及数字签名校验来获取其中的用户信息,从而实现认证和授权。
org.springframework.boot
spring-boot-starter-security
io.jsonwebtoken
jjwt
0.9.0
jwt:
tokenHeader: X-Token #JWT存储的请求头
tokenHead: Bearer #令牌前缀
secret: xx-admin-secret #JWT加解密使用的密钥
expiration: 604800 #JWT的超期限时间秒(60*60*24)@Slf4j
@Component
public class JwtTokenUtil {
private static final String CLAIM_KEY_USERNAME = "sub";
private static final String CLAIM_KEY_CREATED = "created";
@Value("${jwt.secret}")
private String secret;
@Value("${jwt.expiration}")
private Long expire;
/**
* 从token中获取登录用户名
*/
public String getUserNameFromToken(String token) {
String username;
try {
Claims claims = getClaimsFromToken(token);
username = claims.getSubject();
} catch (Exception e) {
username = null;
}
return username;
}
/**
* 校验token
*/
public boolean validateToken(String token, UserDetails userDetails) {
String username = getUserNameFromToken(token);
return username.equals(userDetails.getUsername()) && !isTokenExpired(token);
}
/**
* 根据用户信息生成token
*/
public String generateToken(UserDetails userDetails) {
Map claims = new HashMap<>();
claims.put(CLAIM_KEY_USERNAME, userDetails.getUsername());
claims.put(CLAIM_KEY_CREATED, new Date());
return generateToken(claims);
}
/**
* 判断token是否已经失效
*/
private boolean isTokenExpired(String token) {
Date expiredDate = getClaimsFromToken(token).getExpiration();
return expiredDate.before(new Date());
}
private String generateToken(Map claims) {
return Jwts.builder()
.setClaims(claims)
.setExpiration(generateExpirationDate())
//签名算法
.signWith(SignatureAlgorithm.HS512, secret)
.compact();
}
/**
* 生成token的过期时间
*/
private Date generateExpirationDate() {
return new Date(System.currentTimeMillis() + expire * 1000);
}
private Claims getClaimsFromToken(String token) {
Claims claims = null;
try {
claims = Jwts.parser()
.setSigningKey(secret)
.parseClaimsJws(token)
.getBody();
} catch (Exception e) {
log.info("JWT格式验证失败:{}",token);
}
return claims;
}
} @Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled=true)
public class SpringSecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private CustomAccessDeniedHandler customAccessDeniedHandler;
@Autowired
private CustomAuthenticationEntryPoint customAuthenticationEntryPoint;
@Autowired
private XlUserService xlUserService;
@Override
protected void configure(HttpSecurity httpSecurity) throws Exception {
httpSecurity.csrf().disable()// 由于使用的是JWT,我们这里不需要csrf
.sessionManagement()// 基于token,所以不需要session
.sessionCreationPolicy(SessionCreationPolicy.STATELESS)
.and()
.authorizeRequests()
// 允许对于网站静态资源的无授权访问
.antMatchers(HttpMethod.GET,
"/",
"/*.html",
"/favicon.ico",
"/**/*.html",
"/**/*.css",
"/**/*.js",
"/swagger-resources/**",
"/v2/api-docs/**"
)
.permitAll()
// 对登录注册要允许匿名访问
.antMatchers("/ucenter/xl-user/login", "/ucenter/xl-user/register")
.permitAll()
//跨域请求会先进行一次options请求
.antMatchers(HttpMethod.OPTIONS)
.permitAll()
.anyRequest()// 除上面外的所有请求全部需要鉴权认证
.authenticated();
// 禁用缓存
httpSecurity.headers().cacheControl();
// 添加JWT filter
httpSecurity.addFilterBefore(jwtAuthenticationTokenFilter(), UsernamePasswordAuthenticationFilter.class);
//添加自定义未授权和未登录结果返回
httpSecurity.exceptionHandling()
.accessDeniedHandler(customAccessDeniedHandler)
.authenticationEntryPoint(customAuthenticationEntryPoint);
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.userDetailsService(userDetailsService())
.passwordEncoder(passwordEncoder());
}
@Bean
@Override
public UserDetailsService userDetailsService() {
//获取登录用户信息
return username -> {
XlUser user = xlUserService.getUserByCode(username);
if (user != null) {
List permissionList = xlUserService.getResourceList(user.getUserId());
return new JwtUser(user,permissionList);
}
throw new UsernameNotFoundException("用户名或密码错误");
};
}
/**
* 装载BCrypt密码编码器
*/
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
/**
* JWT filter
*/
@Bean
public JwtAuthenticationTokenFilter jwtAuthenticationTokenFilter(){
return new JwtAuthenticationTokenFilter();
}
} 编写service实现:
@Slf4j
@Service
public class XlUserServiceImpl extends ServiceImpl implements XlUserService {
@Autowired
private PasswordEncoder passwordEncoder;
@Autowired
private UserDetailsService userDetailsService;
@Autowired
private JwtTokenUtil jwtTokenUtil;
@Override
public XlUser register(XlUser user) {
XlUser newXlUser = new XlUser();
BeanUtils.copyProperties(user, newXlUser);
//查询是否有相同用户名的用户
List xlUsers = this.baseMapper.selectList(new LambdaQueryWrapper().eq(XlUser::getUserCode,newXlUser.getUserCode()));
if (CollectionUtil.isNotEmpty(xlUsers)) {
return null;
}
//将密码进行加密操作
String encodePassword = passwordEncoder.encode(user.getPassWord());
newXlUser.setPassWord(encodePassword);
this.baseMapper.insert(newXlUser);
return newXlUser;
}
@Override
public String login(String username, String password) {
String token = null;
try {
UserDetails userDetails = userDetailsService.loadUserByUsername(username);
if (!passwordEncoder.matches(password, userDetails.getPassword())) {
throw new BadCredentialsException("密码不正确");
}
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(userDetails, null, userDetails.getAuthorities());
SecurityContextHolder.getContext().setAuthentication(authentication);
token = jwtTokenUtil.generateToken(userDetails);
} catch (AuthenticationException e) {
log.warn("登录异常:{}", e.getMessage());
}
return token;
}
@Override
public List getResourceList(Long userId) {
return this.baseMapper.getResourceList(userId);
} 测试访问需要权限的接口
@PreAuthorize("hasAuthority('read')")
@ApiOperation("获取用户所有可访问的资源")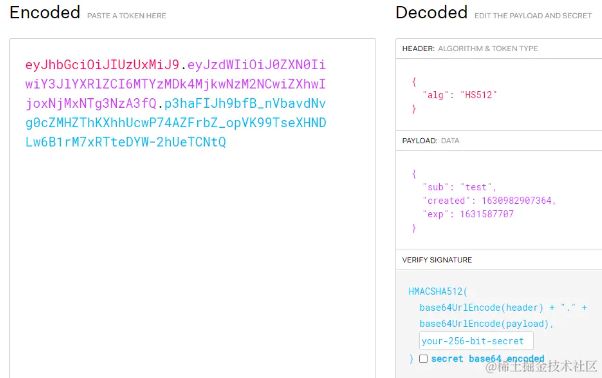 image.png
image.png
mysql优化 | 存储引擎,建表,索引,sql的优化建议
存储引擎
mysql中查看支持的引擎的sql:
show engines;
日常工作中使用较多的存储引擎对比:InnoDB,MyISAM
InnoDB 存储限制 64T 支持事务 支持索引 支持数据缓存 支持外键
MyISAM 存储限制 256T 支持索引 支持全文索引
从MySQL5.6版本开始InnoDB已经支持创建全文索引了
innodb
支持提交、回滚和崩溃恢复能力的事物安全(ACID),支持行锁,支持外键完整性约束
适合场景
需要事务处理
表数据量大,高并发操作
MyISAM
MyISAM存储引擎提供了高速检索和存储的能力,支持全文索引
适合场景
很多count计算的
查询非常频繁的
建表原则
在建表的时候尽量遵循以下原则
尽量选择小的数据类型,数据类型选择上尽量tinyint(1字节)>smallint(2字节)>int(4字节)>bigint(8字节),比如逻辑删除yn字段上(1代表可用,0代表)就可以选择tinyint(1字节)类型
尽量保证字段数据类型长度固定
尽量避免使用null,使用null的字段查询很难优化,影响索引,可以使用0或''代替
避免宽表,能拆分就拆分,一个表往往跟一个实体域对应,就像设计对象的时候一样,保持单一原则
尽量避免使用text和blob,如果非使用不可,将类型为text和blob的字段在独立成一张新表,然后使用主键对应原表
禁止使用float或double类型,这个坑超大,float或double存在精度问题,在进行比较或者加减操作的时候会丢失精度导致数据异常,凡是使用float或double类型的时候考虑下可不可使用int或bigint代替。比如金额,以元为单位使用float或double类型的时候,可以考虑以分为单位使用int,bigint类型代替,然后由业务代码进行单位的转换。
每张表都加上createUser,createTime.updateUser,updateTime字段
起名字要规范,包括:库名,表名,字段名,索引名
查询频繁使用的字段记得加索引
尽量避免使用外键,不用外键约束,性能更高,然后数据的完整性有程序进行管理
如果表的数量可以预测到非常大,最好在建表的时候,就进行分表,不至于一时间数据量非常大导致效率问题
索引
索引是为来加速对表中数据行中的检索而创建的一种分散的数据结果,是针对表而建立的,它是由数据页面以外的索引页面组成,每个索引页中的行都含有逻辑指针,以便加速检索物理数据,创建索引的目的在于提高查询效率,innodb的索引都是基于b tree实现的
索引类型
普通索引:最基本的索引,无限制
//1
create index idx_username on sys_user(user_name(32));
// 2
alter table sys_user add index idx_username(user_name(32));主键索引:一个表只能有一个主键索引,且不能为空
一般建表时同时创建了主键索引
create table `sys_user` (
`id` int(11) not null auto_increment,
`user_name` varchar(32) default null,
`pass_word` varchar(32) default null,
`token` varchar(32) default null,
`yn` smalliint(6) default null,
primary key (`id`)
) engine=InnoDB auto_increment=348007 default charset=utf8;唯一索引:与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
CREATE UNIQUE INDEX idx_token ON sys_user(token_expire)
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
alter table sys_user add index idx_un_te (user_name(32), token_expire);全文索引:用来查找文本中的关键字,而不是直接与索引中的值相比较。只有char、varchar,text 列上可以创建全文索引
CREATE FULLTEXT INDEX idx_ ON sys_user(pass_word)总之使用索引的时候,需要考虑的地方比较多,但是归根结底就是查询尽量走索引,走索引尽量避免回表或减少回表次数
创建使用索引的原则
索引的字段尽量要小,根据索引查询数据的快慢取决于b tree的高度,当数据量恒定的时候,字节越少,存的索引的数量就越多,树的高度就越会越低
比如:设置varchar(10),则这个索引建立的时候只会存字段前10个字节,字段设置的字节数比较小可能会导致索引查出来的数据多,进而进行回表,导致性能下降,所以字段设置为多少还是要自己斟酌一下
遵循索引的最左匹配原则
注意使用like的时候尽量不要使用“%a%”,这样的不走索引,可以使用“a%”,走索引
不要在索引的列上进行计算,比如 select * from sys_user where token_expire+1 = 10000,这样的语句 不会走有索引
什么样的字段建索引,就是那种频繁在where,group by,order by中出现的列,最好加上索引
使用联合索引的时候尽量考虑到索引下推优化
对于使用or的条件,需要or左右的条件都是索引才会走索引,否则走全表扫描,可以考虑使用union代替
避免使用select *,对于只需要查询主键或者where 条件中只有索引的字段, 这时会走覆盖索引建少回表次数
sql语句中避免隐式转换,在MySQL中,字符串和数字做比较的话,是将字符串转换成数字,如字段是varchar类型,但是入参是int类型,即便字段有索引也不会走,因为这里会进行一次隐式转换
索引的缺点
虽然索引的可以提高查询的效率,但是在进行insert,update,和delete的时候会降低效率,因为在保存数据的同时也会去保存索引。
不要在一个表里建过多的索引,问题跟上面一样,在操作数据的时候效率降低,而且数据量少的表要看情况建索引,如果建索引跟没建索引的效果差不多少的情况下就不要建索引了,如果是数据量大的表,就需要建索引去优化查询效率。
explain分析sql
可以使用explain去分析sql的执行情况,比如
explain select * from sys_user where token_expire = 10000;在阿里的开发手册中提到过,sql性能优化的标准:至少要达到range,要求ref级别,如果可以是consts最好
consts 是指单表中最多只有一个匹配行(主键或唯一索引)
ref 指的是使用普通索引
range 是指对索引进行范围查询
sql优化
关于sql语句的优化主要是两方面,一个是在建sql的时候需要注意的问题,另一个就是在发现有慢sql的时候可以根据不同情况进行分析,然后优化sql
现在innodb已经支持全文索引了!
从MySQL5.6版本开始InnoDB支持创建全文索引
优化的建议
查询的时候一定要记得使用limit进行限制
对于结果只需要一条数据的查询用limit 1进行限制
使用count(*)或count(1)来统计行数来查询,使用count(列)的时候,需要在查看列中这个是否为null,不会统计此列为null的情况,而且mysql已经对count(*)做了优化
不要使用select * 来查数据,使用select 需要的列名,这样的方式去查询
使用join链接代替子查询
不要使用外键,外键的约束可以放在程序里解决
控制一下in操作的集合数量,不要太大了
针对慢查询使用explain去分析原因,然后优化sql,让其尽量走索引
 image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png 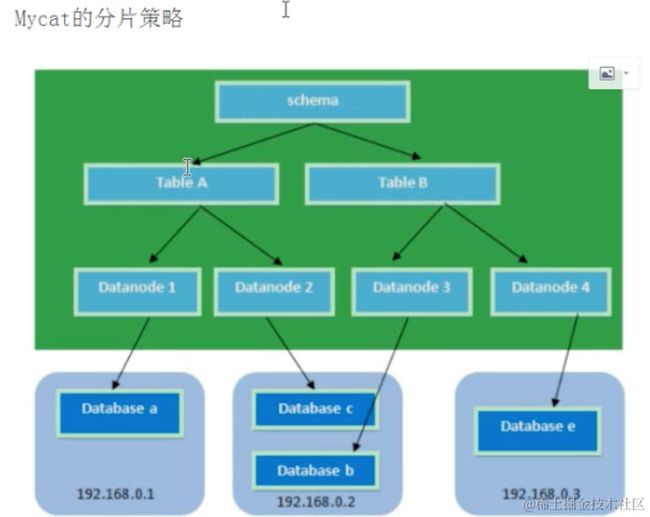 image.png
image.png  image.png
image.png  image.png
image.png 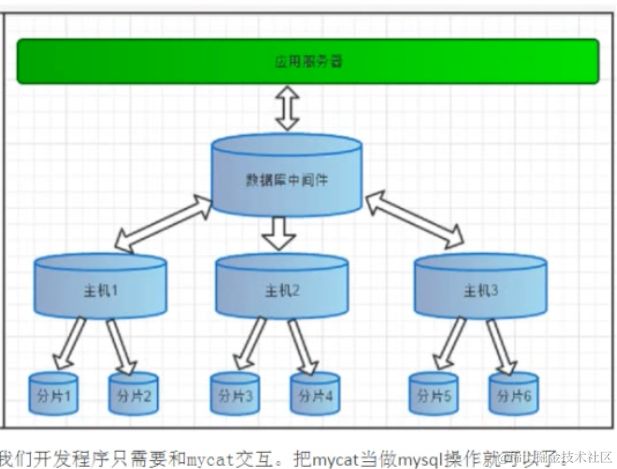 image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png  image.png
image.png
spring boot集成mqtt协议发送和订阅数据
@Autowired
private MqttGatewayComponent mqttGatewayComponent;
//发送字符串或json字符串,到指定的topic
mqttGatewayComponent.sendToMqtt("json string", "data/abcd");
/**
* @desc MQTT发送网关
*/
@Component
@MessagingGateway(defaultRequestChannel = "mqttOutboundChannel")
public interface MqttGatewayComponent {
void sendToMqtt(String data);
void sendToMqtt(String payload, @Header(MqttHeaders.TOPIC) String topic);
void sendToMqtt(@Header(MqttHeaders.TOPIC) String topic, @Header(MqttHeaders.QOS) int qos, String payload);
}
// 通过通道获取数据 订阅的数据
// 配置监听的 topic 支持通配符
// 发送通道配置 默认主题
@Bean
public MqttConnectOptions getMqttConnectOptions(){
// MQTT的连接设置
MqttConnectOptions mqttConnectOptions = new MqttConnectOptions();
// 设置连接的用户名
mqttConnectOptions.setUserName(username);
// 设置连接的密码
mqttConnectOptions.setPassword(password.toCharArray());
// 设置是否清空session,这里如果设置为false表示服务器会保留客户端的连接记录,
// 把配置里的 cleanSession 设为false,客户端掉线后 服务器端不会清除session,
// 当重连后可以接收之前订阅主题的消息。当客户端上线后会接受到它离线的这段时间的消息
mqttConnectOptions.setCleanSession(true);
// 设置发布端地址,多个用逗号分隔, 如:tcp://111:1883,tcp://222:1883
// 当第一个111连接上后,222不会在连,如果111挂掉后,重试连111几次失败后,会自动去连接222
mqttConnectOptions.setServerURIs(hostUrl.split(","));
// 设置会话心跳时间 单位为秒 服务器会每隔1.5*20秒的时间向客户端发送个消息判断客户端是否在线,但这个方法并没有重连的机制
mqttConnectOptions.setKeepAliveInterval(20);
mqttConnectOptions.setAutomaticReconnect(true);
// 设置“遗嘱”消息的话题,若客户端与服务器之间的连接意外中断,服务器将发布客户端的“遗嘱”消息。
mqttConnectOptions.setWill(willTopic, willContent.getBytes(), 2, false);
mqttConnectOptions.setMaxInflight(1000000);
return mqttConnectOptions;
}说明:由于测试机的端口限制,单机最多也就65553个端口了,所以理论上jmeter最大也就可以模拟6万个连接(系统本身也会有很多服务占用端口)
使用虚拟机理论上是可以让测试机端口无限的,前提性能跟得上。但实际中我们发现,单台测试机跑jmeter到3万个连接,其实已经是极限了(内存和cpu性能问题)
netty的大型响应式分布式物联网智能家电系统,十万长连接
压测效果 单机下压测效果 稳定6万连接(自身配置限制 i5 6300hq+16G)
压测效果 集群模式下(两节点)压测效果 达成12万连接
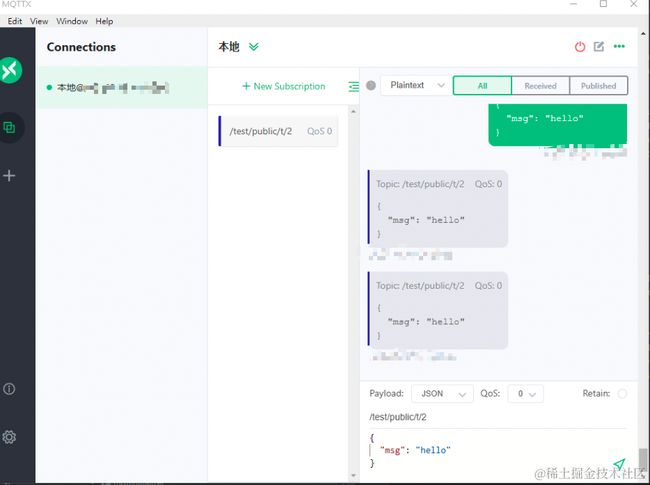 image.png
image.png
不想再用AOP收集业务操作日志
业务操作日志是软件系统中用于记录和跟踪用户对业务数据执行的操作的日志。这些日志提供了对系统活动的见解,有助于审计、监控、分析和重构业务流程。
作为一名对Spring重度使用者,基于上面的需求目标马上想到了基于AOP切面+注解的传统方案,AOP切面和注解来设计业务操作日志是一种非常自然和高效的方法,我们基于AOP切面和注解的方法来实现我们系统中的业务操作日志记录,这种方案允许我们以最小的侵入性来捕获核心业务操作,并在执行前后自动记录相关数据。通过定义注解,我们可以轻松地标记那些需要记录日志的业务方法。
1.1 定义日志注解
首先,你需要定义一个或多个注解,用于标记哪些方法需要记录业务操作日志。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Loggable {
String value() default "";
// 可以添加更多的配置属性,如操作类型、级别等
}1.2 创建AOP切面
接下来,创建一个切面类来处理带有@Loggable注解的方法。
@Aspect
@Component
public class LoggingAspect {
@Around("@annotation(loggable)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint, Loggable loggable) throws Throwable {
long start = System.currentTimeMillis();
Object proceed = joinPoint.proceed(); // 执行目标方法
long executionTime = System.currentTimeMillis() - start;
// 记录日志的逻辑
logger.info(joinPoint.getSignature() + " executed in " + executionTime + "ms");
return proceed;
}
}1.3 配置Spring AOP+标记注解
@Configuration
@EnableAspectJAutoProxy
public class AopConfig {
// 可能还需要其他的配置或Bean定义
}
public class SomeService {
@Loggable
public void someBusinessMethod(Object someParam) {
// 业务逻辑
}
}1.4 定义日志记录逻辑
在切面中,我们就可以自定义日志记录逻辑,可以记录更多的上下文信息,如方法参数、返回值、执行时间、异常信息等。
@Autowired
private Logger logger; // 例如,通过SLF4J获取的Logger
@Around("@annotation(loggable)")
public Object logBusinessOperation(ProceedingJoinPoint joinPoint, Loggable loggable) throws Throwable {
// 方法执行前的逻辑,例如记录开始时间、方法参数等
long start = System.currentTimeMillis();
try {
Object result = joinPoint.proceed(); // 执行目标方法
// 方法执行后的逻辑,例如记录结束时间、返回值等
return result;
} catch (Exception e) {
// 异常处理逻辑,如记录异常信息
throw e;
} finally {
long executionTime = System.currentTimeMillis() - start;
// 构建日志信息并记录
logger.info("{} executed in {} ms", joinPoint.getSignature(), executionTime);
}
}•业务操作场景划分:切面的定义和使用都是非业务化的,所以无法感知到新的业务操作范围和业务的定义划分边界是如何处理;
•级联操作断档:当业务操作是设计多表或者多个服务间的调用串联时,切面只能单独记录每个服务方法级别的数据信息,无法对调用链的部分进行业务串联;
@Repeatable(LogRecords.class)
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface LogRecord {
String success();
String fail() default "";
String operator() default ""; //业务操作场景人
String type(); // 业务场景 模块范围
String subType() default ""; //业务子场景,主要是模块下的功能范围
String bizNo(); //业务场景的业务编号,
String extra() default "";//一些操作的扩展操作
String actionType(); //业务操作类型,比如编辑、新增、删除
}Binlog大家都不陌生,是数据库中二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里。那么Binlog能用来记录业务层面的数据变化内容吗?
3.1 Binlog
Binlog大家都不陌生,是数据库中二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里。那么Binlog能用来记录业务层面的数据变化内容吗?
•问题1:无法对多表存在级联保存和更新的数据进行非常好的兼容支持,因为本身binlog数据是无序的,并且如果上游数据的操作不是包裹在一个事务中,也很难处理
•问题2:关于更新人的问题,系统进行更新时如果未手动更新对应操作人,则系统无法识别,需要上游做对应场景的统一改造,但从系统承接来看,本身系统的操作人就是要跟着业务操作一起进行联动的
MVCC
MVCC最大的好处是读不加锁,读写不冲突,在读多写少的系统应用中,读写不冲突是非常重要的,可极大提升系统的并发性能,这也是为什么现阶段几乎所有的关系型数据库都支持 MVCC 的原因,目前MVCC只在 Read Commited 和 Repeatable Read 两种隔离级别下工作。它是通过在每行记录的后面保存两个隐藏列来实现的,这两个列, 一个保存了行的创建时间,一个保存了行的过期时间, 存储的并不是实际的时间值,而是系统版本号。MVCC在mysql中的实现依赖的是undo log与read view。
read view
在 MVCC 并发控制中,读操作可以分为两类: 快照读(Snapshot Read)与当前读 (Current Read)。
•快照读:读取的是记录的快照版本(有可能是历史版本)不用加锁(select)。
•当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录(select… for update 、lock或insert/delete/update)。
redo log
redo log叫做重做日志。mysql 为了提升性能不会把每次的修改都实时同步到磁盘,而是会先存到Buffer Pool(缓冲池)里,当作缓存来用以提升性能,使用后台线程去做缓冲池和磁盘之间的同步。那么问题来了,如果还没来及的同步的时候宕机或断电了怎么办?这样会导致丢部分已提交事务的修改信息!所以引入了redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后再读取redo log恢复最新数据。redo log是用来恢复数据的,保障已提交事务的持久化特性。
undo log
undo log 叫做回滚日志,用于记录数据被修改前的信息。他正好跟前面所说的重做日志所记录的相反,重做日志记录数据被修改后的信息。undo log主要记录的是数据的逻辑变化。为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。undo log 记录事务修改之前版本的数据信息,假如由于系统错误或者rollback操作而回滚的话可以根据undo log的信息来进行回滚到没被修改前的状态。undo log是用来回滚数据的,保障未提交事务的原子性。
假设 F1~F6 是表中字段的名字,1~6 是其对应的数据。后面三个隐含字段分别对应该行的隐含ID、事务号和回滚指针
具体的更新过程如下:
假如一条数据是刚 INSERT 的,DB_ROW_ID 为 1,其他两个字段为空。当事务 1 更改该行的数据值时,会进行如下操作
•用排他锁锁定该行,记录 Redo log;
•把该行修改前的值复制到 Undo log
•修改当前行的值,填写事务编号,并回滚指针指向 Undo log 中修改前的行。
如果再有事务2操作,过程与事务 1 相同,此时 Undo log 中会有两行记录,并且通过回滚指针连在一起,通过当前记录的回滚指针回溯到该行创建时的初始内容 这里的undolog不会一直增加,purge thread在后面会进行undo page的回收,也就是清理undo log。
JDBC->jre system library -> rt.jar(sql,Connection.class, Driver.class,)
// 创建数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/easyflow", "root", "12345678");
// 自动提交设置
connection.setAutoCommit(false);
// 只读设置
connection.setReadOnly(false);
// 事务隔离级别设置
connection.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
// 创建查询语句
PreparedStatement statement = connection.prepareStatement("update config set cfg_value='1' where id=11111");
// 执行SQL
int num = statement.executeUpdate();
System.out.println("更新行数:" + num);
// 事务提交
connection.commit();Mybatis事务相关
Mybatis核心是提供了sql查询方法、结果集与应用方法及对象之间的映射关系,便于开发人员进行数据库操作。
事务transaction
JDBC对接
数据源datasource
反射reflection
IO封装
游标cursor
异常exceptions
字节码处理javassist
会话session
执行器executor
映射mapping
映射binding
构建器builder
模版引擎ognl
解析器parsing
脚本处理scripting
缓存cache
日志logging
插件plugin
类型type
注解annotation
java版本lang
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview