云原生之容器编排实践-基于CentOS7搭建三个节点的Kubernetes集群
背景
前面采用 minikube 作为 Kubernetes 环境来体验学习 Kubernetes 基本概念与操作,这样避免了初学者在裸金属主机上搭建 Kubernetes 集群的复杂度,但是随着产品功能的逐渐完善,我们需要过渡到生产环境中的 K8S 集群模式;而在实际上生产环境之前,我们先在本地虚拟机上进行了环境搭建与流程验证,作为新的起点,今天就先搭建一个3节点的 Kubernetes 集群。
虚机资源
共用到了三台虚机,1台作为 Master 节点,2台 Worker 节点。
| 主机名 | IP | 说明 |
|---|---|---|
| k8s-master | 172.16.201.25 | 主节点 |
| k8s-node1 | 172.16.201.26 | 工作节点 |
| k8s-node2 | 172.16.201.27 | 工作节点 |
系统环境
[root@k8s-master ~]# uname -a
Linux k8s-master 3.10.0-1160.71.1.el7.x86_64 #1 SMP Tue Jun 28 15:37:28 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
[root@k8s-master ~]# cat /proc/version
Linux version 3.10.0-1160.71.1.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Tue Jun 28 15:37:28 UTC 2022
[root@k8s-master ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
基本环境
Note:
- 前提是先在三台主机上安装好Docker。
- 每个机器使用内网ip互通,且可以连接到互联网。
- 每个机器配置自己的hostname,不能用localhost。
#设置每个机器自己的hostname
hostnamectl set-hostname 自己定义主机名
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#允许 iptables 检查桥接流量
cat <<EOF | tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
安装三大组件
kubeadm 、 kubelet 和 kubectl 是 Kubernetes 集群中的三个核心组件,它们各自承担着不同的角色和职责:
-
kubeadm
-
kubeadm是一个工具,旨在提供kubeadm init和kubeadm join这样的快速的、简单的方式来创建和管理Kubernetes集群的生命周期。它用于初始化集群的控制平面节点、配置网络插件、设置集群的安全选项等。简而言之,kubeadm帮助你启动一个符合最佳实践的Kubernetes集群。
-
kubelet
-
kubelet是运行在所有集群节点上的代理,它确保容器都运行在Pod中。kubelet接收一组通过各种机制提供给它的PodSpecs(指定的Pod描述信息),并确保这些PodSpecs中描述的容器正常运行。它不管理不是由Kubernetes创建的容器。
-
kubectl
-
kubectl是一个命令行工具,用于与Kubernetes集群交互。它允许用户部署应用、检查和管理集群资源以及查看日志等。kubectl是Kubernetes集群的主要接口工具,通过它可以执行各种操作,如创建服务、查看Pod状态等。
这三个组件共同工作,为用户提供了一个强大、灵活和易于管理的容器化环境。
#配置k8s的yum源地址
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#安装组件
yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9
#启动kubelet
systemctl enable --now kubelet
#所有机器配置master域名
echo "172.16.201.25 k8s-master" >> /etc/hosts
下载各个主机需要的镜像
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.20.9
kube-proxy:v1.20.9
kube-controller-manager:v1.20.9
kube-scheduler:v1.20.9
coredns:1.7.0
etcd:3.4.13-0
pause:3.2
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName
done
EOF
chmod +x ./images.sh && ./images.sh
初始化master节点
kubeadm init \
--apiserver-advertise-address=172.16.201.25 \
--control-plane-endpoint=k8s-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
记录 master 执行完成后的日志,后面 worker 节点加入时需要用到。
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-master:6443 --token b29onk.0b46jzznm14tqgnv \
--discovery-token-ca-cert-hash sha256:9307b7fb928b2042e1fc5ad6e88fa6a319d86476c6967d07595a571402456fb4 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-master:6443 --token b29onk.0b46jzznm14tqgnv \
--discovery-token-ca-cert-hash sha256:9307b7fb928b2042e1fc5ad6e88fa6a319d86476c6967d07595a571402456fb4
安装Calico网络插件
curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O
vi calico.yaml
# 编辑calico.yaml,在
- name: CLUSTER_TYPE
value: "k8s,bgp"
# 下面的env环境变量中加入如下参数:
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0"
kubectl apply -f calico.yaml

加入worker节点
kubeadm join k8s-master:6443 --token b29onk.0b46jzznm14tqgnv \
--discovery-token-ca-cert-hash sha256:9307b7fb928b2042e1fc5ad6e88fa6a319d86476c6967d07595a571402456fb4 \
--control-plane
成功~
[root@k8s-master ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-577f77cb5c-hv29w 1/1 Running 0 59s
kube-system calico-node-4fkrs 1/1 Running 0 60s
kube-system calico-node-d4tqq 1/1 Running 0 60s
kube-system calico-node-sdmm6 1/1 Running 0 60s
kube-system etcd-k8s-master 1/1 Running 6 35h
kube-system kube-apiserver-k8s-master 1/1 Running 6 35h
kube-system kube-controller-manager-k8s-master 1/1 Running 6 35h
kube-system kube-proxy-4789z 1/1 Running 0 35h
kube-system kube-proxy-7mt7k 1/1 Running 2 35h
kube-system kube-proxy-lqtpz 1/1 Running 0 35h
kube-system kube-scheduler-k8s-master 1/1 Running 7 35h
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 37h v1.20.9
k8s-node1 Ready <none> 35h v1.20.9
k8s-node2 Ready <none> 35h v1.20.9
部署Dashboard
部署Kubernetes官方提供的可视化界面
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
创建访问账号
#创建访问账号,准备一个yaml文件; vi auth-dashboard.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
kubectl apply -f auth-dashboard.yaml
获取访问令牌
#获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
K8S Dashboard秘钥: eyJhbGciOiJSUzI1NiIsImtpZCI6ImN6S1ZHcFUxcW85dG5jYlRyWnc5eGFNTE5oaVd0cC02SGczWExVUTVJNG8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXh0a21sIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmNzA1MjVkYy1lMTMwLTQ5M2MtODk4MC1kZjc4NzNhM2MzN2MiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9. SngBc3PRyCmJRXp7sDycS50NshGma5wO78BtWAH7zAUagp2KVb2pDQi1hXf2EbyElOYTrNDBAZ8QdIt7ZnxbL9y3Bzm6hKxHyti7BhtGfWK-CEXnz6IIrDQKbh2GUhldoLtfxe2OqE7RA8TT0lPweWHlqmr2MpFOsgJhfSAr2kCBwT9Urc5VTGwsq7H2F0o1eE0Niu3q2jSt3WjQWstRLPhQWB82nRHCZ6ZLHERzRzU15fiIT9skReqmMBy0revjUJf1FqVneptUlhqRagJ-frZfnr75f2Ku_3h5sDU73Bu10I_9Nuup-7cnwrLrmsHn32lSnFcq-u43ln5Ovd8LJw
浏览器打开界面
键入上面得到的令牌。
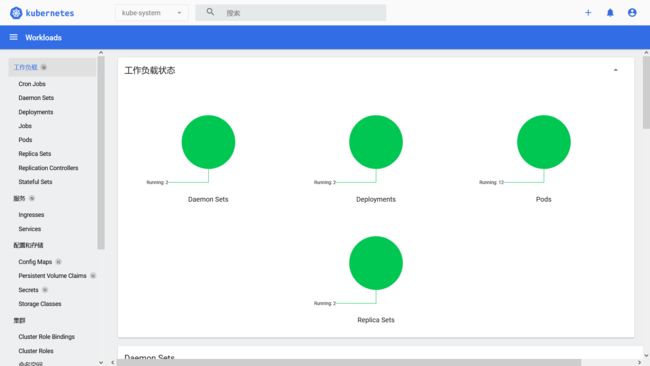
监控总览
可能遇到的问题
error: unable to recognize “calico.yaml”: no matches for kind “PodDisruptionBudget” in version “policy/v1”
- 原因:
Calico与K8S版本不一致导致,改用以下版本的Calico - 解决:
curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O
Work节点一直NotReady
先查看下日志 journalctl -f -u kubelet.service ,如果依然有问题,可以尝试清除集群中的节点。
- 解决方法
[root@k8s-master ~]# kubectl drain k8s-node1 k8s-node2 --delete-local-data --force --ignore-daemonsets
Flag --delete-local-data has been deprecated, This option is deprecated and will be deleted. Use --delete-emptydir-data.
node/k8s-node1 cordoned
node/k8s-node2 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-lxxsx, kube-system/kube-proxy-cbfgb
node/k8s-node1 drained
WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-bgt7n, kube-system/kube-proxy-629cs
node/k8s-node2 drained
[root@k8s-master ~]# kubectl delete node k8s-node1 k8s-node2
node "k8s-node1" deleted
node "k8s-node2" deleted
calico running 但是0/1:calico/node is not ready: BIRD is not ready: BGP not established with
尝试重新删除再安装一下calico
kubectl delete -f calico.yaml
kubectl apply -f calico.yaml
依然是上述问题。。
看下 calico 的状态信息。
kubectl describe pod calico-node-t4mrf -n kube-system
calico/node is not ready: BIRD is not ready: BGP not established with
-
原因分析
修改calicao网络插件的网卡发现机制,即IP_AUTODETECTION_METHOD对应的value值。官方提供的yaml文件中,IP识别策略(IP DETECTMETHOD)没有配置,即默认为first-found,这会导致一个网络异常的IP作为nodeIP被注册,从而影响node-to-node mesh。我们可以修改成can-reach或者interface的策略,尝试连接某一个Ready的node的IP,以此选择出正确的IP。 -
解决方法
编辑calico.yaml,在
- name: CLUSTER_TYPE
value: "k8s,bgp"
下面的env环境变量中加入如下参数:
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0"
重启K8S集群
如果觉得需要重启 K8S 集群,可以通过以下命令实现。
systemctl restart kubelet && systemctl restart docker
小总结
以上记录了基于 kubeadmin 搭建3节点的 Kubernetes 集群的过程,并总结了可能遇到的问题。
Reference
- https://www.yuque.com/leifengyang/oncloud/ghnb83#SDlhV
If you have any questions or any bugs are found, please feel free to contact me.
Your comments and suggestions are welcome!