回顾过去一年 CloudWeGo Rust Team 所做的工作,如果要用两个关键词来总结一下的话,那就是性能优化和生态建设。本文主要分为三点来介绍,第一点是大致总结和回顾下 Volo 这一年的发展,第二点是重点介绍一下 Volo 里的性能优化,第三点是未来我们的工作重点将聚焦在哪些方面。
1. Volo 这一年
在 2022 年 8 月,我们曾发表了一篇名为「国内首个基于 Rust 语言的 RPC 框架 — Volo 正式开源」的官宣文章,在里面详细介绍了 Volo 的一些特性以及围绕 Volo 所同步开源的 Pilota、Motore、Metainfo 等组件。时隔一年,Volo 及其相关组件已有不少变更,简单来总结一下的话,那将会分别是 Volo - 功能补全 & 性能优化、 Pilota - 能力升级、Motore - 趋于稳定、Metainfo - 易于使用。
特别的,我们还想带大家一起回顾下 Volo 在这一年中的一些关键节点和技术更新。
- 在开源后的不久,我们就收到了来自社区同学 @anwentec 的第一个 PR,该 PR 主要是支持用户在 Windows 上也能使用 Volo 来进行开发,大大补全了框架的多平台支持性。
- 紧接着,我们迎来了自发布以来的第一个重大性能优化 —— 编解码重构,该优化灵感最初起源于社区同学 @ii64 在 Pilota 中提出的一个新增 Thrift 协议支持的 PR,在一些探讨交流过后,我们发现 Volo 现有能力不能很好的支持用户传入自定义的编解码,于是才有了现在的 Volo 编解码重构和优化。
- 值得一提的是,在这个过程中,我们还发布了 linkedbytes 和 faststr 这两个 crate,在辅助优化进行的同时,也丰富了 Rust 开源的相关生态。
- 最后,在编解码这块,我们还通过 unsafe 代码绕过了一些边界检查,使得辅助编译器生成了更高效的 SIMD 并行操作指令,大大提升性能。如果大家还想了解 Volo 更多详细的进展,可以在 CloudWeGo 官网查看我们的 Release Note。

2. 性能优化
在 RPC 框架中,最消耗性能的无非就是序列化和网络通信这两点,我们做性能优化也主要是围绕这两点进行。下图展示了一次完整的 RPC 调用链路,我们优化的工作也基本集中在这些 CPU 密集型和 IO 密集型任务中,下面要详细介绍的编解码重构优化和 unsafe 编解码优化则主要是集中在序列化 encode、decode 部分,大家如果想参与进来一起做深度性能优化,那么这将会是一个不错的参考。
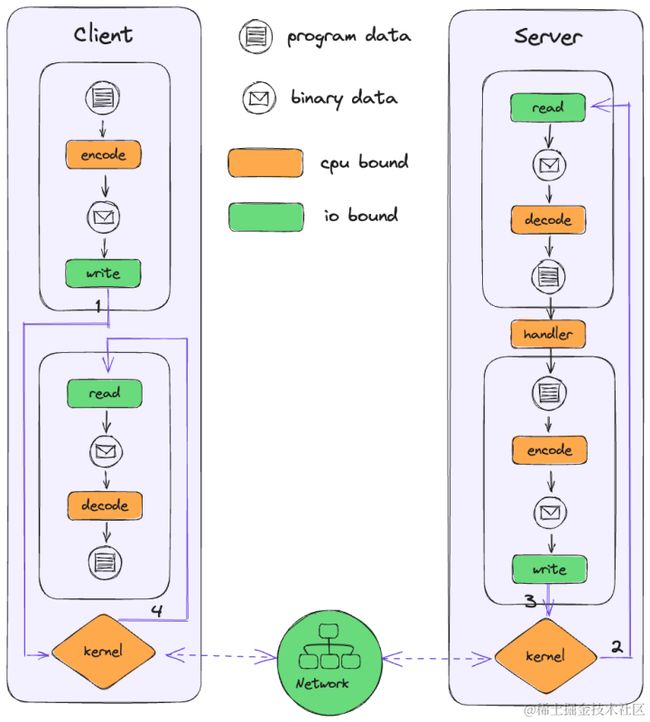
2.1 编解码重构优化
这一块的优化主要是内存的零拷贝操作。我们知道,在 RPC 调用时,需要先将用户请求结构体序列化成二进制字节流存入用户态内存,再通过 write 系统调用写入到内核态内存中进行发送,我们所优化的零拷贝部分就是在第一步存入用户态内存中。在大部分的实现中,对于 String 和 Vec 这些类型的序列化,在这里都会有一个拷贝的开销,因为在 write 系统调用中所写入的需要是一块连续的内存。那么问题来了,如果不要求是连续内存写入,是不是就可以省掉这里的拷贝了?答案是显而易见的可以,我们完全可以通过复用用户请求结构体中的内存,然后再以链表的形式把内存串起来进行写入,就可以省下这儿的拷贝开销了。

如果要对内存进行复用,那就不可避免需要引入引用计数,用来决定这块内存何时才能被释放。如此一来,原有的 String 和 Vec 这两个类型就不满足需求了,我们需要类似 Arc 和 Arc 这样的类型。所幸的是,对于 Vec,在开源社区中已经有 bytes 这个库中的 Bytes 结构可以进行替代。但 String 却没有一个很好的替代,而这也是 faststr 这个库诞生的一个原因。
faststr 这个库主要是提供了一个 FastStr 结构,结构里面的表示如下图,实际上它就是一个各种字符串类型的集合,用户在使用的时候可以减少许多如何选择字符串类型的心智负担。它除了满足上面对于复用内存的需求外,还对小字符串有一定的优化,比如直接在栈上分配内存。当然,这儿有人会有疑问了,&str 不是就可以满足需求了吗,为什么还需要 faststr?其实不然,在某些场景下我们无法表达出它的生命周期,这一部分详细的解释大家可以看 faststr 的文档。
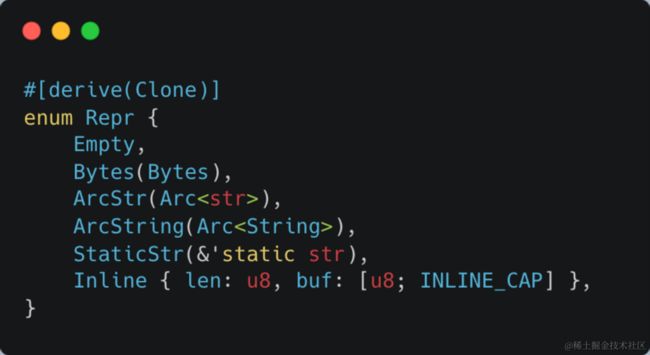
linkedbytes 这个库则主要是借鉴链表的思想,把我们上面复用的 String 和 Vec 内存通过 writev 系统调用进行写入即可。LinkedBytes 里主要是两块,一块是暂存非 String 和 Vec 内存的 bytes 字段,另一块则是把内存串起来的 list 字段。可以简单看一下 insert 的逻辑,在插入 Bytes 时,先把当前暂存的连续内存 split 出来插入到 list 中,再把传入的 Bytes 插入进去就完成了。

2.2 Unsafe 编解码优化
这一块的优化则主要是辅助编译器帮助我们生成出来高效的汇编代码。以 encode 为例,正常情况下我们给内存中写入 Vec,会很容易写出如下图的代码,也就是直接遍历这个 Vec,然后调用 put_i64() 方法去写入。
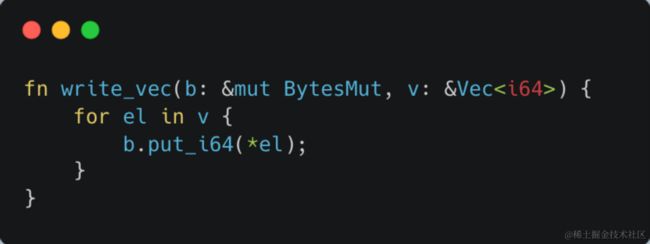
但如果我们再去仔细看 put_i64() 方法的实现,就会发现每次在写入时它会先判断内存够不够用,不够的话则会扩充内存再写入。那如果一开始我们就已经分配了足够多的内存,是不是就完全可以省掉这儿的边界检查,于是乎我们可以稍微改造一下,写出如下图的代码。

写完代码后那紧接着就是性能测试了,简单写个 bench 跑一下,不跑不知道,一跑吓一跳。可能你现在也和我们之前所认为的一样,只是去掉边界检查,性能提升应该不会有多少,但实际上看下图,它竟然有 7~8 倍的收益。

那么这就不得不好好深究一下为什么了?常言说得好,要想优化做的深,汇编代码跑不了。我们把二者都转换成汇编代码再来看,下面两张图截取了写入过程的部分汇编代码。

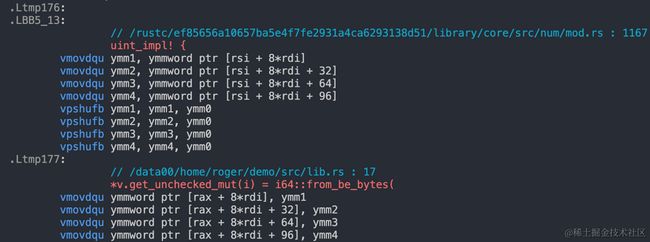
看完我相信熟悉 SIMD 指令的同学已经幡然醒悟了,在去掉边界检查后的汇编代码中,采用了 SIMD 指令去加速内存的写入,也就是一条指令可以写入多个数据,其性能收益也显得合理起来了。
3. 未来展望
最后给大家剧透一下我们目前正在尝试的一些项目以及后续要重点优化的部分。
1. 新的项目
第一个是 Shmipc-rs 这个项目,熟悉 CloudWeGo 的同学可能知道 Shmipc 现在已经是开源项目了,不过那只是 Spec 和 Go 语言版本的实现,Shmipc-rs 则是 Rust 语言版本的实现,届时也会集成到 Volo 中用以提升性能。Shmipc 是基于共享内存的进程间通信,主要适用于大包、高吞吐的场景。
第二个是 Volo-http 这个项目,提供了和社区广泛使用的 Axum 框架一致的开发体验,并且在中间件部分是基于我们自己开源的 Motore 进行实现的,会带来一部分的性能提升,在日后也有望和 Volo-gRPC 项目结合起来提供 Gateway 等功能。目前已经是可用状态,非常欢迎大家来体验和共建。
2. 易用性优化
第一个是文档这一部分,目前 Volo 中的功能特性比较多,但大部分都缺少一些文档加以说明,以至于用户不能很好的进行使用和体验,后续我们会把文档补充类的工作放在 issue 中进行跟进,也欢迎大家参与进来。
第二个是最佳实践这一部分,目前 Volo 中只有一些简易的 example demo 供用户学习使用,而没有一些中小项目给到用户去借鉴以及理解 Volo 框架,这一块也是后续要加强的部分,如果大家有什么项目推荐实现的话,也欢迎开 issue 一起讨论。

以上是在 CloudWeGo 两周年之际,关于 Volo 开源一周年的回顾和展望,希望对大家有帮助。
项目地址
GitHub:https://github.com/cloudwego